خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
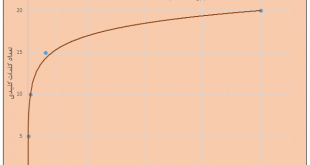
مروری بر کتابخانه های جاوا اسکریپت برای بصری سازی گراف شبکه پیچیده پویا در مباحث قبل به موضوع علمی بازنمایی و بصری سازی گراف پرداختیم. در این مبحث مروری بر کتابخانه های جاوا اسکریپت برای بصری سازی گراف شبکه پیچیده پویا می پردازیم. SigmaJS: …
ادامه مطلبکتابخانه های جاوا اسکریپت برای بصری سازی گراف در وب