خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
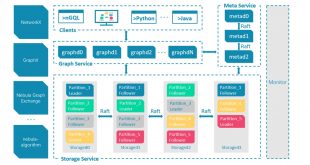
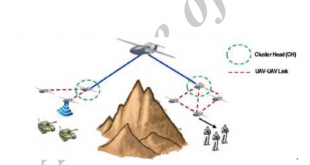
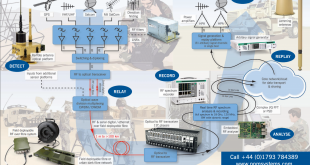
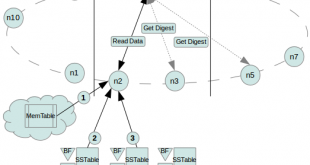
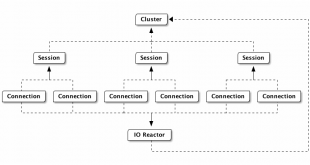
پایگاه داده Nebula Graph یک دیتا بیس مبتنی بر گراف است که میتواندصدها میلیارد رأس و تریلیون ها یال را میزبانی کند و پرس و جوهایی را با تأخیر میلی ثانیه ارائه دهد. با این فناوری امکان پردازش گراف به صورت ابری فراهم است. …
ادامه مطلبپایگاه داده Nebula Graph برای گراف های بزرگ