خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
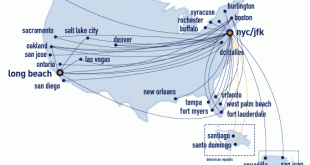
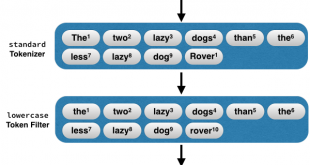
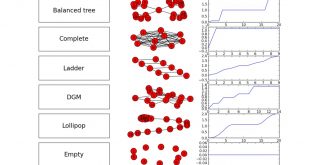
توزیع لینوکس SoNebuntu Light: در دنیای امروز که دادهها و تحلیل آنها نقش کلیدی در تجارت، کسب و کار و انواع پژوهشها دارند، ابزار تحلیل داده نیز باعث تسریع در عملیات تحلیل تاثیر بسزایی دارند. همین مسئله در بحث شبکههای اجتماعی نیز مطرح است. …
ادامه مطلبانتشار SoNebuntu Light نسخه سبک توزیع لینوکس مخصوص تحلیل گران شبکههای اجتماعی