خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
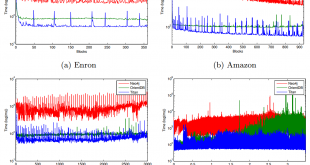
دیتاست گراف ارتباطی بیت کوئین: این مجموعه داده مربوط به گراف افرادی معتمد در شبکه امن است که Bitcoin را در پلتفرم Bitcoin Alpha به کار می برند. از آنجا که کاربران Bitcoin ناشناس هستند، نیاز به حفظ رکورد شهرت کاربران برای جلوگیری از …
ادامه مطلبدیتاست (DataSet) گراف بیت کوئین