خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
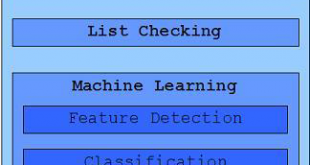
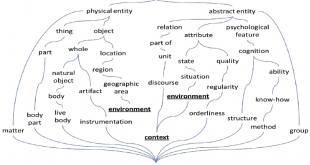
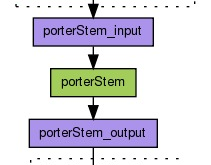
تشخیص رویداد: رصد شبکه های اجتماعی، رویدادهای دنیای واقعی را نشان میدهد و اطلاعات ارزشمندی را استخراج میکند و به افراد و سازمانها اجازه میدهد تا ترند و مسیر رخدادها را به صورت واقعی و زنده درک کنند. زبان شناسان معتقدند “چیزی که به …
ادامه مطلببیش ازصد موجودت اسمی برای تشخیص رویداد (Event Detection)