خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
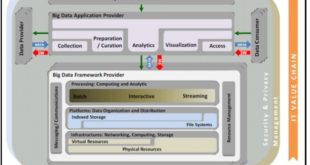
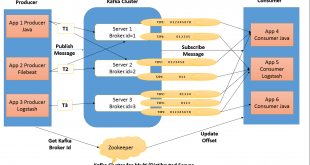
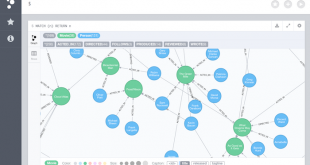
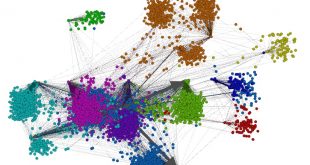
توسعه و اجرای استراتژی کلان داده برای سازمان ها کار آسانی نیست، به خصوص اگر فرهنگ داده محور نداشته باشند. چنین فرهنگی یک پیش نیاز برای اجرای موفقیت آمیز یک استراتژی کلان داده است. ایجاد نقشه راه Big Data برای رسیدن چنین فرهنگی ناگزیر …
ادامه مطلبسطح بلوغ بیگ دیتا یا کلان داده حرکتی به سمت شرکت های داده محور