خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
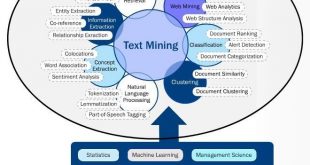
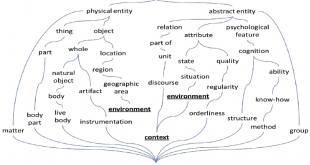
مقدمه ای بر مراحل متن کاوی امروزه بخش وسیعی از دانش بهصورت متن، مستندات و دیگر صورتهای رسانهای نگهداری میشوند که همه آنها بهصورت غیر ساختاریافته هستند. یکی از کاربردهای دادهکاوی، متنکاوی است. ﺑـﺮاي درﻳﺎﻓﺖ داﻧﺶ از اﻃﻼﻋﺎت ﻳﻚ ﻣﺘﻦ، ﻻزم اﺳﺖ اﺑﺘﺪا آن …
ادامه مطلبمراحل متن کاوی و پردازش متن به زبان خلاصه