خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
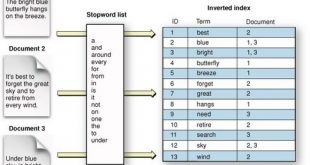
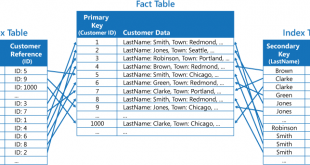
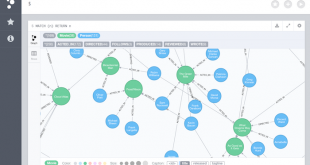
در قسمت های قبل روشهای شاخص گذاری بر روی داده ها را بررسی نمودیم. اکنون در بخش ایندکس معکوس (inverted index) مورد مطالعه قرار میدهیم. شاخص گذاري معکوس، يک مکانيزم مبتني بر کلمه است که براي جستجوي سريع اسناد شامل يک کلمه خاص به کار …
ادامه مطلبایندکس معکوس (inverted index) چیست؟