خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
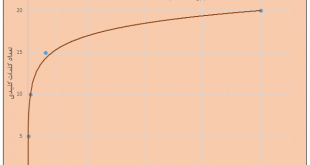
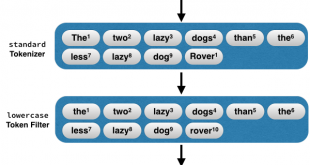
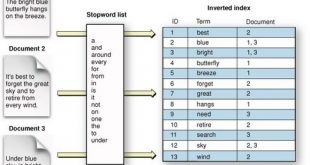
محاسبه تعداد کلمات کلیدی در اسناد متنی بر حسب تعداد کل کلمات هر سند محاسبه تعداد کلمات کلیدی در مطالب قبل به برخی از تکنیک های پردازش متن اشاره کردیم . در این مبحث به روش انتخاب تعداد کلمات کلیدی در اسناد متنی میپردازیم. …
ادامه مطلبروش محاسبه تعداد کلمات کلیدی (key word) در اسناد متنی