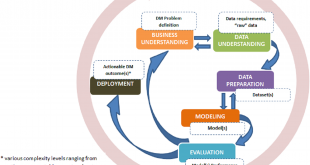
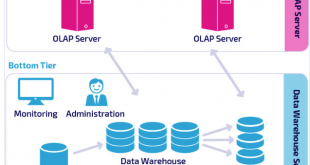
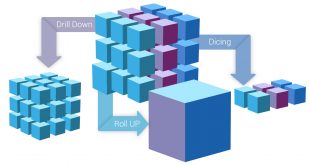
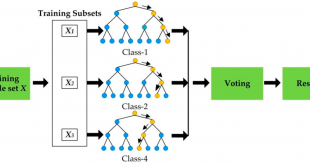
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
نسل زد (Gen Z) که به طور کلی به افرادی که بین سالهای ۱۹۹۷ تا ۲۰۱۲ میلادی به دنیا آمده اند اطلاق میشود، به عنوان “تکزادگان” یا “بومیان دیجیتال” شناخته میشوند. این نامگذاری به دلیل رشد و پرورش این نسل در دنیای دیجیتال و …
ادامه مطلباصطلاحات و کلمات مورد استفاده نسل z (نسل جدید)