خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
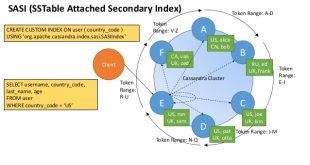
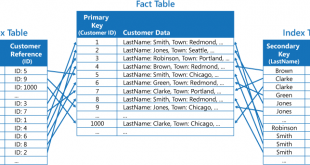
نمایه گذاری ساسی (SASI): از نسخه 3.4، میتوان از پیاده سازی جدیدی از اندیسهای ثانویه SSTable Attached Secondary Index (SASI) بهره برد. برای ستونهایی که توسط پیاده سازی ساسی (SASI)، اندیس ثانویه میشوند، میتوان در پرسوجوها از عملگرهای نامساوی (پرسوجوی محدودهای از مقادیر) و …
ادامه مطلباضافه شدن ویژگی ساسی (SASI) در کاساندرا به منظور Full Search