 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
بخشی عمده ای از مطالب این قسمت را از وبلاگ دوست محترمم آقای نعمت پور با کمی ا اصلاح و تغییر در این پست کپی نموده ام. نصب اسپارک در ویندوز: 1. نصب جاوا-برای نصب اسپارک در ویندوز باید ابتدا نسخه 7 یا 8(ترجیحا) …
ادامه مطلبداده های حجیم (کلان داده)
نصب، راه اندازی و پیکربندی اسپارک (Spark) در لینوکس
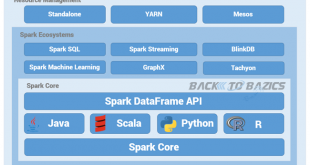
بخشی عمده ای از مطالب این قسمت را از وبلاگ دوست محترمم آقای نعمت پور با کمی ا اصلاح و تغییر در این پست کپی نموده ام. بازدیدها: 2759
ادامه مطلبدرآمدی بر اسپارک (Spark) و بررسی معماری و اجزای آن
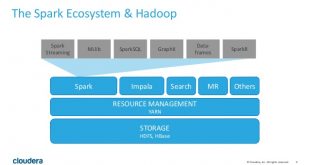
معماری اسپارک (Spark): این تکنولوژی، چارچوبی با کاربرد همه منظوره است و میتوان از آن برای انواع کاربردهای کلان داده، بخصوص شرایطی که سرعت عملیات از اهمیت ویژه ای برخوردار باشد، استفاده کرد. دو مثال از این کاربردها، تحلیل تعاملی و اجرای الگوریتم های …
ادامه مطلبانواع ایندکس یا اندیس در پايگاه داده (Index)
انواع ایندکس: از اندیسها میتوان برای بهبود عملکرد پایگاهداده استفاده کرد. اندیسها به سرویسدهنده پایگاهداده اجازه میدهد تا سطرهای خاص را سریعتر از حالت بدون اندیس بیابد. در مباحث قبل به ایندکس معکوس و ایندکس ثانویه اشاره شده است. اکنون انواع اصلی که مبانی …
ادامه مطلبمقایسه OrientDB با Neo4j
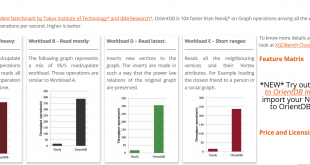
مقدمه ای بر گراف دیتابیس یک نوع از این پایگاه داده های NOSQL، پایگاه داده های گراف محور یا Graph Based هستند. در مطالب گذشته انواع پایگاه داده های NOSQL را بررسی کردیم. در این مبحث به مقایسه OrientDB با Neo4j می پردازیم. از …
ادامه مطلبمقایسه داکر (Docker) با VServer و OpenVZ و LXC
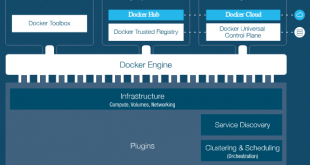
این روزها، توسعه دهندگان نرم افزار، شاهد ارز اندام مقتدرانه تکنولوژی کانتینرها هستند. در این بخش، ابتدا مجازی سازی مبتنی بر کانتینر و پیاده سازی های آن شرح داده میشود و سپس، سکوی محبوب داکر (Docker) بصورت ویژه مورد توجه قرار میگیرد تا بتوانیم …
ادامه مطلبآموزش کامل نصب و راه اندازی و پیکربندی داکر (Docker) در ویندوز و لینوکس
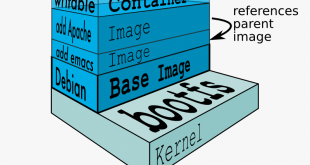
داکر یک ابزار اوپن سورس برای طراحی و ساخت برنامهها به کمک Container است. Container به برنامه نویس کمک میکند که پروژه خود را با تمام بخش هایی که دارد (مثل کتابخانه ها، وابستگیها و غیره) به صورت یک پکیج دربیاورد. به لطف این …
ادامه مطلبمرور و بررسی داکر (Docker) پلت فرم اجرای نرم افزارهای توزیع شده با بهره گیری از ایده کانتینر ها
معرفی داکر داکر (Docker) یک پروژه متنباز است که فرایند استقرار نرمافزارها و سرویسها رو با معرفی مفهوم “Container”ها سرعت میبخشد. داکر پروژهٔ متنبازی است که توسعه های نرمافزارهای کاربردی را درون کانتینر نرمافزاری به وسیلهٔ فراهم کردن لایهٔ انتزاعی اضافهای فراهم میکند.بعضی از …
ادامه مطلبنحوه کار و پرسوجو با Neo4j
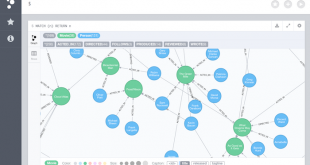
در این بخش به نحوه کار و پرسوجو با بانک اطلاعات مبتنی بر گراف Neo4j میپردازیم. بعد از اجرا Neo4j در ویندوز یا در سیستم عامل لینوکس، در کاوشگر خود آدرس http://localhost:7474 را وارد میکنیم تا رابط کاربری برنامه نمایش داده شود. برای کاربرانی …
ادامه مطلبنصب و راه اندازی Neo4j (پایگاه داده مبتنی بر گراف ) در سیستم عامل های دبین و ابونتو
نحوه نصب و راه اندازی Neo4j همانطوره که در پست های قبل اشاره کردم neo4j یک پایگاه داده غیر رابطه ای مبتنی برگراف، برای انجام امور گراف کاوی و داده کاوی است. در این پست به روش نصب و راه اندازی Neo4j خواهیم پرداخت. …
ادامه مطلبمعیار ماژولاریتیmodularity یا پیمانگی با روش Louvain جهت خوشه بندی گراف
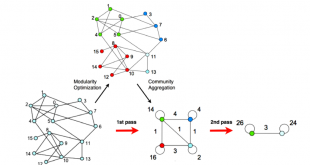
پیمانگی Louvain جهت خوشه بندی: پیمانگی (modularity) ابتدا به عنوان معیاری جهت تعیین مرحله توقف الگوریتم گیروان و نیومن مورد توجه بود، ولی به سرعت به جزء پر اهمیت تعداد زیادی از الگوریتمهای تشخیص انجمن تبدیل شد. این معیار فرمولی برای محاسبه کیفیت تقسیم …
ادامه مطلبمقایسه کاساندرا با پایگاه داده های غیر رابطه ای HBase, MongoDB, CouchDB, Neo4j

مقایسه کاساندرا با HBase, MongoDB, CouchDB, Neo4j در این مطالعه در دانشگاه Coimbra پایگاه دادههای Neo4j، Cassandra، Hbase، MongoDB، OrientDB، و Redis مورد ارزیابی قرار گرفتهاند. همچنین محققان دانشگاه تورنتو مطالعهای در جهت بررسی عمکرد چندین پایگاه داده NoSQL یک سری آزمایش انجام داده …
ادامه مطلبقضیه CAP (ویژگیهایConsistency,Partition tolerance,Availability)
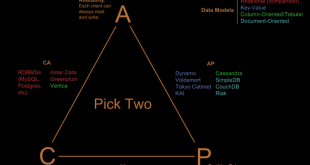
قضیه CAP : عبارت CAP ترکیب سرنام مفاهیم زیر است: سازگاری (Consistency): در هنگام توزیع شدگی، بخشها اطلاعات یکسانی را در لحظه داشته باشند. دسترسیپذیری (Availability): هر درخواست خواندن و نوشتنی همیشه بدون پاسخ نباشد. تحمل بخشها(Partition tolerance): در هنگام توزیع شدگی هر بخشی …
ادامه مطلبدرآمدی بر بانک های اطلاعاتی غیر رابطه ای (NoSql)

پایگاه داده های NoSQL ها در واقع همان بانک های اطلاعاتی غیر رابطه ای و توزیع شده هستند که لزوما برای نگهداری داده ها نیازی به ساختار جدول ندارد و میتواند به سادگی عملیات Replication را انجام دهد. البته ایده پایگاه داده NoSQL تقریبا بیش …
ادامه مطلبخصوصیات سیستم های مدیریت پایگاه داده غیر رابطه ای یا بانک های اطلاعاتی NoSQL
در سالهای اخیر سیستم های نوینی تحت اصطلاح سیستم های مدیریت پایگاه داده غیر رابطه ای یا NoSQL به معنی “Not Only SQL” یا ” نه تنها SQL” جهت ارائه مقیاسپذیری افقی برای عملیات توزیعشدهی خواندن/نوشتن پایگاه داده برروی چند سرویسدهنده، طراحی شده است. …
ادامه مطلببخشبندی داده یا partitioning در پایگاه داده غیر رابطه ای کاساندرا
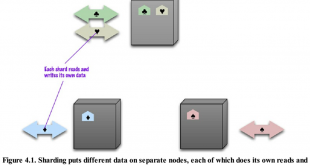
بخشبندی در پایگاه داده : در این مبحث در مورد قسمتبند یا بخش بندی (partitioning) کسندرا صحبت خواهیم کرد. قبل از شروع به توضیحات، اشاره ای به مبحث بخش بندی خواهیم نمود. به طور خلاصه وظیفه بخش بند، تقسیم داده ها به صورت تقریبا …
ادامه مطلبسلام دنیا!

به سایت آموزش پایگاه داده های غیر رابطه ای و کلان داده خوش آمدید. فعالیت ما در رابطه با برگزاری دوره های توانمند سازی و کارگاه های آموزشی در زمینه داده های حجیم یا کلان داده خواهد بود. با ما همراه باشید تا در …
ادامه مطلب