 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خزشگر crawler4j و مقایسه با دیگر خزشگرها
در این نوشتار سعی داریم راه اندازی یک خزشگر وب قدرتمند را به همراه امکان جستجوی واژگان در صفحات و URLهای وب توسط خزشگر crawler4j را به شما بیاموزیم
عناوين مطالب: '
مقدمه بر خزشگر:
- Crawl
crawl در لغت به معنای “خزیدن” می باشد. بررسی و جمع آوری اطلاعات کامل یک وب سایت اعم از مطالب و لینک های درون وب سایت را که توسط ربات های موتور های جستجو انجام می شود،crawl می گویند.
- Crawler
بررسی و خواندن کلیه مطالب و محتوای یک سایت اولین اقدامی است که موتور های جستجو انجام می دهند. این مجموعه عملیات توسط نرم افزارهایی به نام خزشگر (Crawler)یا عنکبوت (spider) انجام می شود. استفاده های بسیاری از خزشگرهای تحت وب می شود اما اساسا این خزشگرها برای جمع آوری اطلاعات از درون اینترنت ساخته شده اند. بیشتر موتور های جست و جو از این کراولرها استفاده می کنند تا از نظر اطلاعاتی همیشه بروز باشند و هر اطلاعاتی که بر روی وب یا وب سایت ها قرار می گیرند را شاخص گذاری (ایندکس) کنند.
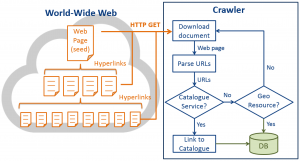
کمپانی های تحلیل کننده و محققان از خزشگر ها برای تعیین ضوابط و ترند اطلاعاتی بازار استفاده می کنند. در ادامه سعی ما بر این بوده است تا ۵۰ خزشگر متن باز و موجود برتر در فضای وب و برای داده کاوی را به شما معرفی کنیم تا بتوانید از بین خزشگرهای موجود بهترین ها را انتخاب کنید.
انواع خزشگرها :
|
Name |
Language |
Platform |
|
Java |
Linux |
|
|
Java |
Cross-platform |
|
|
Python |
Cross-platform |
|
|
C++ |
Cross-platform |
|
|
C |
Linux |
|
|
C#, C, Python, Perl |
Cross-platform |
|
|
ht://Dig |
C++ |
Unix |
|
C/C++ |
Cross-platform |
|
|
ICDL Crawler |
C++ |
Cross-platform |
|
mnoGoSearch |
C |
Windows |
|
Java |
Cross-platform |
|
|
C/C++, Java PHP |
Cross-platform |
|
|
PHP |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Spindle |
Java |
Cross-platform |
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
SimpleSpider |
Java |
Cross-platform |
|
Grunk |
Java |
Cross-platform |
|
CAPEK |
Java |
Cross-platform |
|
Java |
Cross-platform |
|
|
Smart and Simple Web Crawler |
Java |
Cross-platform |
|
Java |
Cross-platform |
|
|
C++ |
Linux |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Erland |
Linux |
|
|
Java |
Cross-platform |
|
|
C/C++ |
Cross-platform |
|
|
C#, PHP |
Cross-platform |
|
|
C |
Lunix |
|
|
PHP |
Cross-platform |
|
|
C++ |
Cross-platform |
|
|
C# |
Windows |
|
|
C++ |
Java |
|
|
C, Java, Python |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
|
|
C++ |
Linux |
|
|
Java |
|
|
|
C# |
Windows |
|
|
Java |
Cross-platform |
|
|
Java |
Cross-platform |
در ادامه به بررسی تعدادی از خزشگرهای معرفی شده در بالا میپردازیم:
Heritrix
Heritrix یک خزنده وب است که برای آرشیو وب طراحی شده است و با زبان برنامه نویسی Java نوشته شده است و تحت یک مجوز نرم افزاری رایگان می باشد. رابط اصلی با استفاده از یک مرورگر وب قابل دسترسی است و یک ابزار خط فرمان است که می تواند به صورت انتخابی برای شروع خزش استفاده شود. جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید:
https://github.com/internetarchive/heritrix3
Apache Nutch
Apache Nutchیک برنامه نرم افزاری خزنده وب بسیار پیشرفته و مقیاس پذیر است. Nutch به طور کامل در زبان برنامه نویسی جاوا نوشته شده است، اما داده ها در فرمت های مستقل زبان نوشته شده اند. این معماری بسیار مدولار است و به توسعه دهندگان اجازه می دهد که افزونه هایی را برای تجزیه و تحلیل نوع رسانه ای، بازیابی داده ها، پرس و جو و خوشه بندی ایجاد کنند. محرک (“ربات” یا “خزنده وب”) از ابتدا به طور خاص برای این پروژه نوشته شده است. جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: nutch.apache.org
Scrapy
scarpy یک چارچوب وب خزنده رایگان و متن باز است که در پایتون نوشته شده است. در ابتدا برای scrap وب طراحی شده بود، همچنین می تواند برای استخراج داده ها با استفاده از API ها یا به عنوان یک خزنده وب عمومی استفاده شود. جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://scrapy.org/
HTTrack
HTTrack یک خزشگر وب سایت و مرورگر آفلاین رایگان و متن باز است که توسط Xavier Roche توسعه داده شده و تحت مجوز GNU General Public License Version 3کار میکند. جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://www.httrack.com
webmagic
یک خزشگر مقیاس پذیر با قابلیت های زیر :
هسته ساده با انعطاف پذیری بالا
API ساده برای استخراج HTML
حاشیه نویسی با POJO برای سفارشی کردن خزنده، بدون تنظیمات.
Multi-thread و پشتیبانی از توزیع شدگی
آسان برای یکپارچه سازی
جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://github.com/code4craft/webmagic
Pholcus
یک خزشگر نوشته شده با زبان بزنامه نویسی Go می باشد که هدف آن جمع آوری داده های اینترنتی می باشد. سه حالت عملیاتی را پشتیبانی می کند: مستقل، سرور و مشتری. سه اینترفیس عملیاتی دارد: وب، GUI و خط فرمان. قوانین آن ساده و انعطاف پذیر هستند.
ویژگی ها :
طراحی شده برای کاربران یک برنامه خاص Go یا JS، و اینکه ابزارهای خزنده ای را ارائه می دهد که فقط نیاز به توجه به قوانین و عملکردهای سفارشی دارند.
پشتیبانی از سه حالت عملیات: مستقل، سرور و مشتری؛
پشتیبانی همزمان چندین وظیفه
پشتیبانی پروکسی
پشتیبانی از پروسه جمع آوری برای متوقف کردن به طور تصادفی و شبیه سازی رفتار مصنوعی.
پنج حالت خروجی وجود دارد mysql، mongodb، kafka، csv،excel و download file اصلی.
پشتیبانی خروجی دسته ای، و مقدار هر دسته قابل کنترل است.
جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://github.com/henrylee2cn/pholcus
File System Crawler for Elasticsearch
این خزنده به ایندکس کردن اسناد باینری مانند PDFو Open Office وMS Office کمک می کند.
ویژگی های اصلی:
- خزش فایل سیستم محلی (یا یک درایو نصب شده) و فهرست کردن فایل های جدید، به روز رسانی فایل های موجود و حذف آن هایی که قدیمی هستند.
- سیستم فایل از راه دور برای خزش روی SSH.
- رابط REST به شما اجازه “آپلود” اسناد باینری خود را به elasticsearchمی دهد.
جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://github.com/dadoonet/fscrawler
Java web crawler
Java web crawler یک خزنده برای خزش صفحات وب در یک دامنه مشابه می باشد، اگر صفحه شما به دامنه دیگری هدایت شود، آن صفحه برداشت نمی شود مگر آنکه اولین نشانی اینترنتی مورد آزمایش باشد. اساسا شما می توانید با این خزشگر کارهای زیر را انجام دهید:
- خزیدن از نقطه شروع، تعریف عمق خزش و تصمیم به خزش فقط یک مسیر خاص.
- خروجی گرفتن از تمام URL های در حال خزش.
- خروجی داده ها به صورت یک فایل CSV.
- داده ها را به دو فایل متنی ارسال می کند، یکی شامل آدرس های فعال و دیگری غیرفعال.
- هر URL در یک خط جدید قرار خواهد گرفت.
- خروجی urlهایی که شامل یک کلمه کلیدی می باشند.
جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید: https://github.com/soulgalore/crawler
SchemaCrawler
SchemaCrawler یک ابزار رایگان کشف و بهینه سازی پایگاه داده است. SchemaCrawler ترکیب خوبی از ویژگی های مفید برای مدیریت داده ها است. با استفاده از آن می توان اشیاء پایگاه داده را با استفاده از عبارات منظم جستجو کرد و خروجی شیء و داده ها را در فرمت متن قابل خواندن کرد. خروجی برای مستندات پایگاه داده کار می کند و طراحی شده است که در مقابل سایر طرح های پایگاه داده متفاوت باشد. SchemaCrawler همچنین نمودارهای طرح را تولید می کند. شما می توانید اسکریپت ها را در هر زبان اسکریپتی استاندارد در پایگاه داده خود اجرا کنید.
SchemaCrawler تقریباً هر پایگاه اطلاعاتی که درایورJDBC دارد را پشتیبانی کرده و با هر سیستم اجرایی که از جاوا ۸ پشتیبانی میکند، کار میکند. SchemaCrawler یک API جاوا است که کار با متادیتای پایگاه داده را آسان می کند، مانند کار با اشیاء ساده جاوا قدیمی. از طریق GitHub می توانید آنرا دانلود کنید و اینکه همه jarهای SchemaCrawler در مخزن مرکزی قرار دارند که می توانند به عنوان وابستگی ها در پروژه Gradle یا Apache Maven یا با هر سیستم ساخت دیگری که از مخزن مرکزی پشتیبانی می کنند استفاده شوند. جهت مطالعهی بیشتر می توانید به لینک زیر مراجعه کنید:
https://github.com/schemacrawler/SchemaCrawler
خزشگر crawler4j
crawler4j یک خزنده وب نوشته شده توسط زبان برنامه نویسی جاوا است که یک رابط ساده برای خزیدن وب را فراهم می کند. با استفاده از آن می توانید چندین دقیقه یک خزنده وب multi-thread را راه اندازی کنید. در این پروژه ما از ساختار خزشگر Crawler4J که توسط Java توسعه یافته است، استفاده کردهایم اما به خاطر اهداف پروژه و سادگی بیشتر به منظور تفهیم ماهیت خزشگر تغییراتی نیز اعمال شده است.

مزایای خزشگر مورد استفاده :
- قابلیت افزایش تعداد خزشگرها
- قابلیت مشخص نمودن سطح خزش
- بهینگی
- رعایت ادب در هنگام خزش (Politeness)
- امکان تعیین حداکثر عمق خزش
- امکان مشخص نمودن حداکثر تعداد صفحات برای Fetch
- قابلیت یافتن کلمات فارسی و انگلیسی
- سادگی
- مناسب و قابل فهم جهت آموزش
روند اجرای برنامهی خزشگر URL:
- تنظیم مشخصات مورد نظر خزشگر همچون حداکثر عمق خزش، حداکثر تعداد صفحات برای Fetch، زمان تاخیر بازدید برای رعایت کردن Politeness خزشگر و… .
- افزودن Seedها یا URLهای مورد نظر برای شروع خزش.
- در این مرحله ابتدا از یک آرایه بعنوان صف URLها، برای خزش استفاده میکنیم؛
- سپس با استفاده از یک تابع به نام Visit به بررسی آنها میپردازیم. عمل decode نمودن متن URL در این تابع انجام میگردد.
- افزودن URL به صف بازدید نیز در تابع Visit انجام میگیرد.
- تابعی دیگر با استفاده از Threadها به اجرای تابع سوم (که در آن مشخصات و دستورات اجرایی بر روی URLها نوشته میشود) میپردازد.
- دستورات و کدهای مربوط به یافتن کلمه، ریشه و مترادفهای واژه مورد نظر در تابع سوم نوشته خواهند شد.
نمایی از اجرای کد برای یافتن کلمه در URL، که با خزش سایت www.Aviny.com بدست آمده در زیر قابل مشاهده میباشد. در این مثال ما با جستجوی “AV” در آدرس صفحات، خروجی زیر را دریافت کردیم.
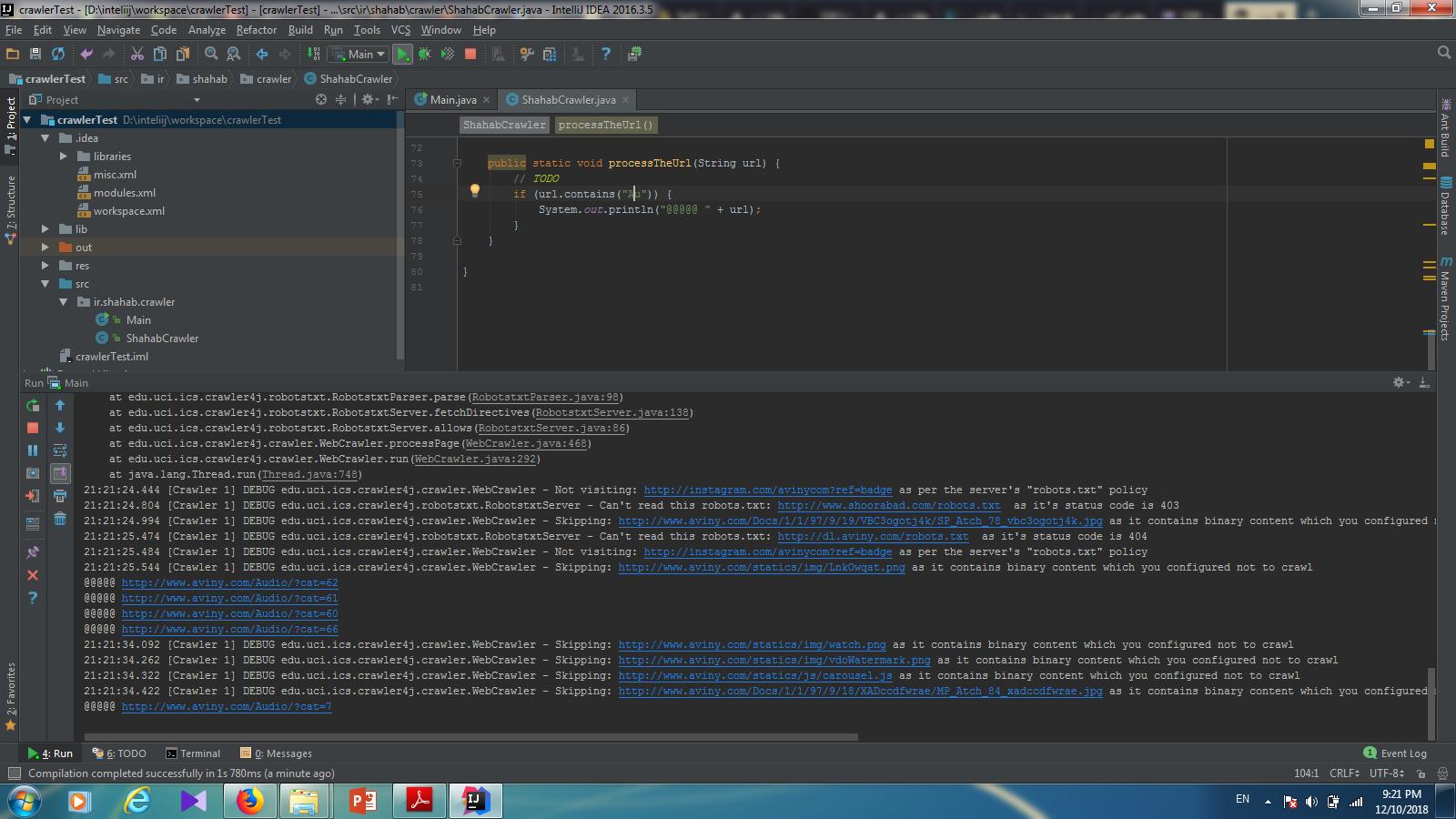
قسمتی از کدهای استفاده شده:
public void visit(Page page) {
String url = page.getWebURL().getURL();
try {
url = URLDecoder.decode(url, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
synchronized (urlQueue) {
boolean notifySwitch = false;
if (urlQueue.isEmpty()) {
notifySwitch = true;
}
urlQueue.add(url);
if (notifySwitch) {
urlQueue.notify();
}
}
}
public static void urlConsumer() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
synchronized (urlQueue) {
if (!urlQueue.isEmpty()) {
String url = urlQueue.poll();
processTheUrl(url);
} else {
try {
urlQueue.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
});
thread.start();
}
public static void processTheUrl(String url) {
// TODO
try{
Scanner scan = new Scanner(new File("D:\\inteliij\\workspace\\crawlerTest\\src\\ir\\shahab\\crawler\\data.txt"));
int lenght=0;
String[] line = new String[20000];
String[][] data= new String[20000][50];
while(scan.hasNextLine())
{
line[lenght] = scan.nextLine();
String[] Splite2 = line[lenght].split("،");
for(int i=0;i<Splite2.length;i++)
{
data[lenght][i] = Splite2[i];
}
lenght++;
}
String Word="گراف";
int index=-1;
for(int i=0;i<line.length;i++)
{
if(line[i].contains(Word))
{
index=i;
break;
}
}
if(index != -1)
{
for (int j=0; data[index][j]!=null;j++)
{
System.out.println("\n------------------------------------------**Test**------------------------------------------");
System.out.println(data[index][j]);
System.out.println("\n------------------------------------------**-Test-**------------------------------------------");
if(url.contains(data[index][j]))
{
System.out.println("\n------------------------------------------**Shahab**------------------------------------------");
System.out.println("Url for ------> \""+data[index][j]+"\":");
System.out.println("This Url:"+url);
}
if(url.contains(Word))
{
System.out.println("\n------------------------------------------**Shahab**------------------------------------------");
System.out.println("Url for ------> \""+Word+"\":");
System.out.println("This Url:"+url);
}
}
}
}catch (FileNotFoundException e)
{
System.out.println("\n------------------------------------------**_Shahab_**------------------------------------------");
e.printStackTrace();
}
}
قسمتی از تابع Main برنامه:
int numberOfCrawlers = 1;
CrawlConfig config = new CrawlConfig();
config.setCrawlStorageFolder(crawlStorageFolder);
config.setPolitenessDelay(50);
config.setMaxDepthOfCrawling(100);
config.setMaxPagesToFetch(1000);
config.setIncludeBinaryContentInCrawling(false);
config.setResumableCrawling(false);
PageFetcher pageFetcher = new PageFetcher(config);
RobotstxtConfig robotstxtConfig = new RobotstxtConfig();
RobotstxtServer robotstxtServer = new RobotstxtServer(robotstxtConfig, pageFetcher);
CrawlController controller = new CrawlController(config, pageFetcher, robotstxtServer);
controller.addSeed("https://bigdata-ir.com/");
controller.start(ShahabCrawler.class, numberOfCrawlers);
نمایی از خروجی این برنامه:
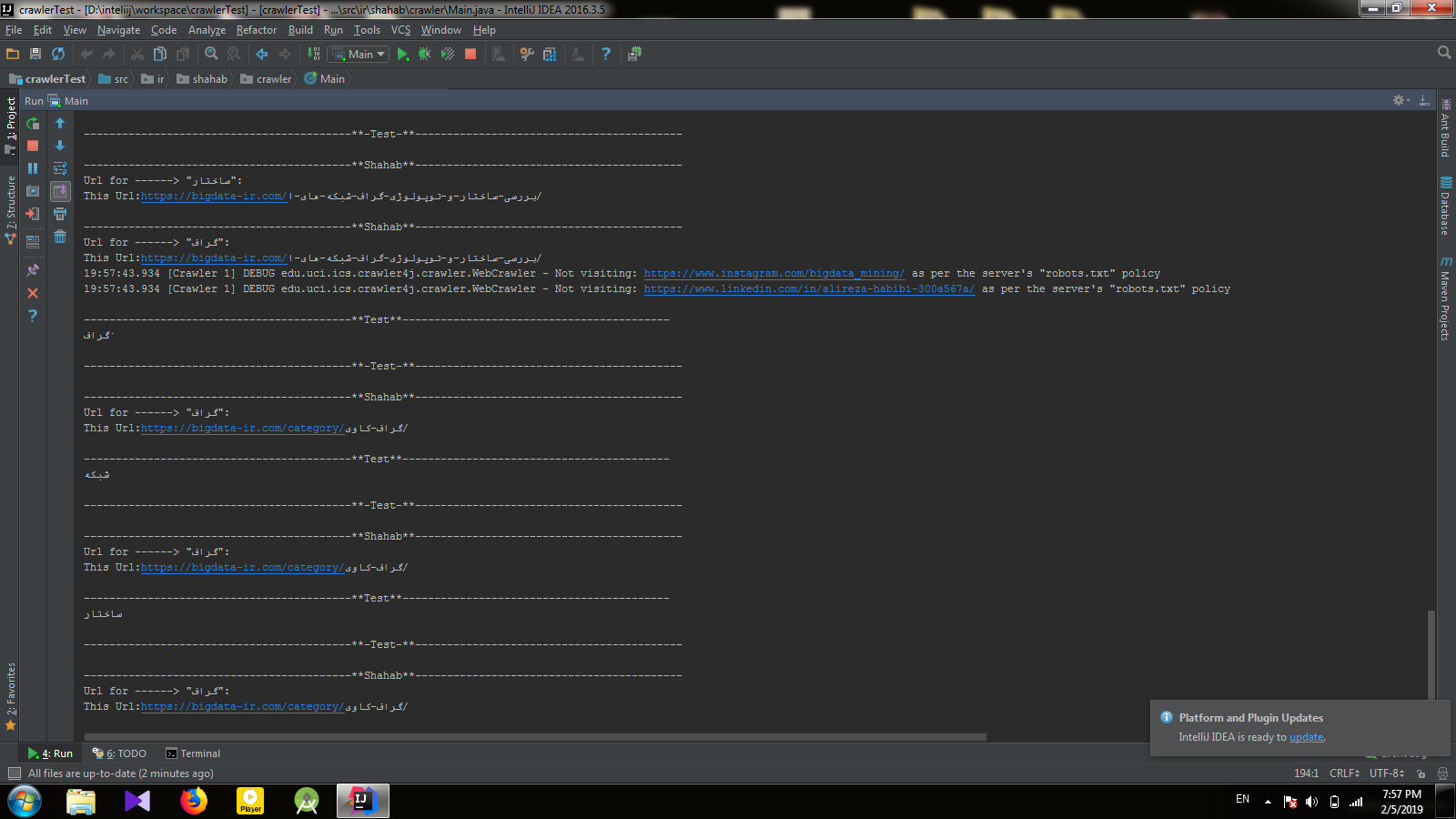
روند اجرای برنامهی خزشگر متن:
تنظیمات اولیه برنامه، همانند خزشگر URL انجام میشود. ما در این برنامه، در تابع Visit عمل خواندن تمام متن صفحه را که از Parse کردن html صفحه بدست میآید، انجام میدهیم. سپس با کمک متد split، متن موجود را بصورت کلمهکلمه در یک آرایه میریزیم. اکنون به سادگی و با استفاده از یک شرط کلمه مورد نظر را جستجو میکنیم. ما برای مشخص بودن مکان واژه مورد نظر در صفحه از یک حلقه و یک متغیر استفاده کردهایم که اندیس آن واژه را برای ما نمایش میدهد. ضمنا این برنامه قادر به نمایش تمام متن موجود در صفحه نیز میباشد. در این برنامه علاوه بر جستجوی کلمه مورد نظر، کلمات مترادف آن نیز جستجو میگردند. برای این منظور از یک پایگاه داده لغات فارسی با حدود 150 هزار واژه مترادف استفاده شده است.
قسمتی از کدهای استفاده شده:
public void visit(Page page) {
String url = page.getWebURL().getURL();
try {
Scanner scan = new Scanner(new File("C:\\Users\\Pouya\\Desktop\\del\\pouyaCrawler\\src\\main\\resources\\Data.txt"));//Data.txt
int length = 0;
String[] line = new String[20000];
String[][] data = new String[20000][50];
while (scan.hasNextLine()) {
line[length] = scan.nextLine();
String[] Splite2 = line[length].split("،");
for (int i = 0; i < Splite2.length; i++) {
data[length][i] = Splite2[i];
}
length++;
}
String word="تحلیل";
int index=-1;
for(int i=0;i<line.length;i++)
{
if(line[i].contains(word)) {
index = i;
break;
}
}
if (page.getParseData() instanceof HtmlParseData) {
HtmlParseData htmlParseData = (HtmlParseData) page.getParseData();
String text = htmlParseData.getText();
String[] split = text.split(" ");
if(index!=-1) {
for (int j = 0; data[index][j]!=null; j++) {
int lng = 0;
int flag=0,flg=0;
for (int i = 0; i < split.length; i++) {
lng += split[i].length() + 1;
if (data[index][j].equals(split[i])) {
if(flag==0){
System.out.println("\n--------------------------------**** Pouya ****--------------------------------");
System.out.println("URL for \"" + data[index][j] + "\": " + url);
flag++;
}
System.out.println("---->\"" + data[index][j] + "\" Occurs at index: " + (lng - (split[i].length()) - 1));
}
}
}
}
}
} catch (FileNotFoundException e) {
System.out.println("\n--------------------------------**** Pouya:Not Able to Connect to DB ****--------------------------------");
e.printStackTrace();
}
}
نمایی از خروجی این خزشگر:
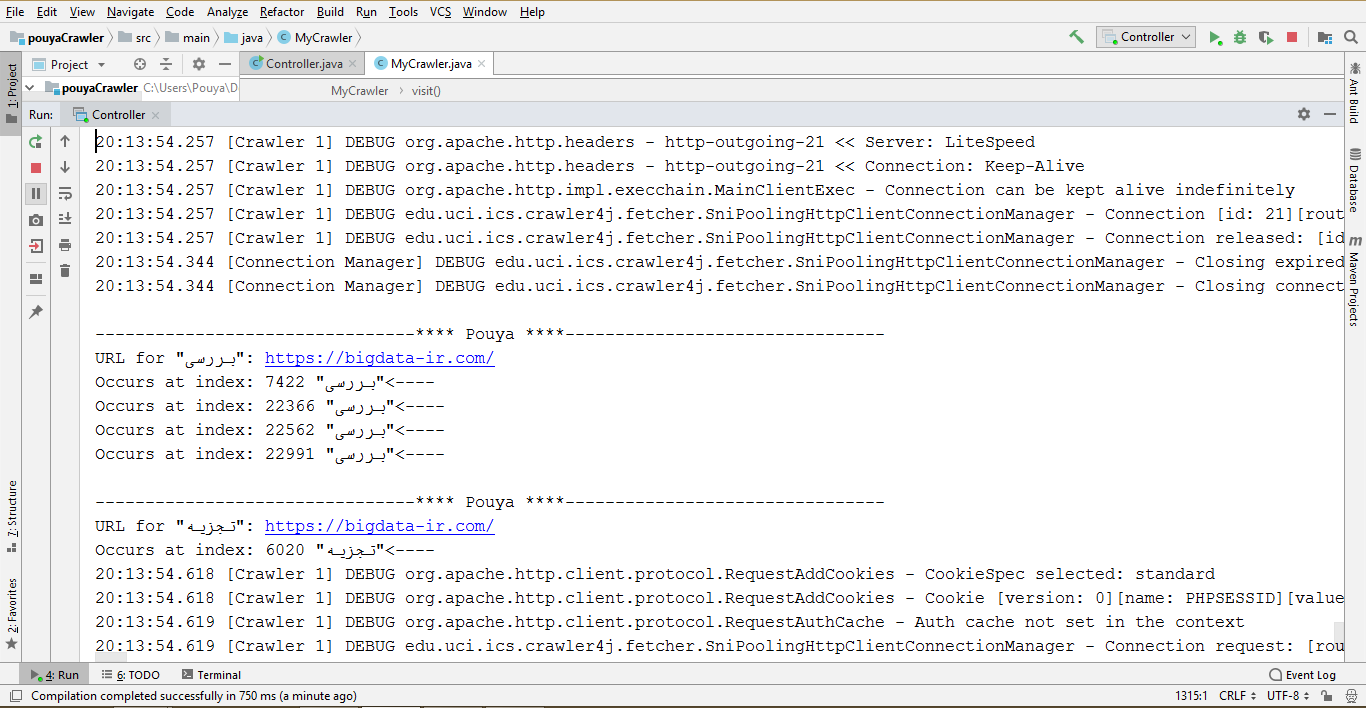
تهیه کنندگان:
مهندس شهاب نوروزی مهندس پویا سروشیان
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 2971
برچسبCrawler crawler4j spider انواع خزشگر اینترنت جمع آوری اطلاعات خزشگر خزشگر crawler4j خزشگر وب خزنده کرالر کراولر مقایسه خزشگرها موتور جستجو وب وب کراولر
نوشته های مرتبط





همچنین ببینید

آموزش کامل مالتگو (Maltego) ابزاری برای جمع آوری اطلاعات و جرم شناسی
ابزارهای زیادی برای استخراج داده ها، مدل سازی داده ها و مشاهده اطلاعات تهدید مانند …

آموزش کامل آپاچی سولار (Solr) همراه با مثال
در مباحث قبل، در این مورد بحث کردیم که چطور کلان داده برای برآورده کردن …
