 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
نسل دوم اوسينت (OSINT) به عنوان نظام اطلاعاتی و دفاعي
اگرچه جامعه اطلاعاتی بیش از 50 سال است که درگیر در برنامه منبع باز (OSINT) است ، اما تعریف OSINT و نحوه توصیف آن به عنوان یک رشته اطلاعاتی هنوز هم مورد بحث است. در سندی که در سال 2011 توسط دفتر مدیر اطلاعات ملی صادر شده است ، “OSINT” به عنوان “اطلاعات تولید شده از اطلاعات عمومی که جمع آوری ، بهره برداری می شود ، و به موقع برای مخاطبان مناسب به منظور پرداختن به یک هوش خاص تولید می شود ، تعریف شده است. اینترنت و ظهور رسانه های اجتماعی OSINT را از نظر منابع و روشها پیچیده تر کرده است. این تحول در OSINT به حدی قابل توجه است که این گزارش استدلال می کند که باید آن را به عنوان نسل دوم OSINT مشاهده کرد. این گزارش تعریفی را برای نسل دوم OSINT ارائه می دهد و در مورد چگونگی تفاوت آن با عملکرد تاریخی OSINT ، به ویژه در رابطه با شرکت دفاعی ، بحث می کند. این سیستم عامل OSINT را به عنوان یک رشته اطلاعاتی تعریف می کند و زیر مجموعه هایی از OSINT مخصوص نسل دوم OSINT را در اختیار شما قرار می دهد.
عناوين مطالب: '
چکيده :
سپس متدولوژی OSINT و چرخه عملیات اختصاصی برای هر یک از زیرگروه های آن را تجزیه می کند و برخی از مشکلات رایج در هر کدام و کارآیی های پیشرفتهای جدید فن آوری را ارائه می دهد. در ادامه این گزارش ، اطلاعاتی در مورد ابزارها و روشهای استفاده شده برای تجزیه و تحلیل OSINT – خصوصاً در رسانه های اجتماعی – ارائه شده و اصطلاحات مربوط به واژگان ، شبکه های اجتماعی و تجزیه و تحلیل زمین شناسی را تعریف می کند. همچنین برخی از چالش های استفاده از فناوری خارج از قفسه تجاری (COTS) برای تجزیه و تحلیل OSINT مورد بحث قرار می گیرد
در ایالات متحده آمریکا. سرانجام ، نتیجه گیری های کلی ارائه می شود ، همراه با بحث در مورد زمینه های جدید توسعه مربوط به OSINT و فرصت ها و موانعی که آنها می توانند برای عملیات منبع باز ارائه دهند.
ماهیت همپوشانی OSINT با سایر رشته های اطلاعاتی – از جمله اطلاعاتی از منابع انسانی و ارتباطات متوقف شده – منحصر به فرد نیست و از وضعیت OSINT به عنوان یک رشته اطلاعاتی مستقل کم نمی کند. تقسیم OSINT به زیرگروه ها ، در درجه اول بر اساس اینکه آیا این امر به صورت نهادی و یا فردی هدایت می شود ، مفید است. این زیرگروهها توصیف بهتری از این امکان را دارند روش OSINT و چرخه هوش ، به عنوان الزامات و مشکلات این فرایند در بین زیرگروه ها به طرز چشمگیری متفاوت است. چرخه اطلاعاتی OSINT شامل جمع آوری ، پردازش ، بهره برداری و تولید است. مجموعه کسب اطلاعات منبع باز است؛ پردازش روشی است برای تأیید آن اطلاعات. x تعریف اطلاعات منبع باز نسل دوم (OSINT) برای بهره برداری سازمان دفاع ، ارزش اطلاعات این اطلاعات را مشخص می کند. و تولید آن ارزش را برای مشتریان آی سی انتقال می دهد.
بخش عمده ای از تجزیه و تحلیل OSINT از ابزارهای COTS استفاده می کند ، به خصوص برای تجزیه و تحلیل داده های رسانه های اجتماعی. با این حال ، ابزارهای COTS اغلب برای نیازهای صنعت بازرگانی به جای آی سی تنظیم می شوند. خود ابزارها و شرکتهایی که آنها را تولید می کنند نیز به سرعت تغییر می کنند ، زیرا تجزیه و تحلیل رسانه های اجتماعی هنوز یک صنعت جدید و به سرعت در حال تحول است. اگرچه اطلاعات مربوط به ابزارهای فعلی COTS به IC کمک می کند تا از قابلیت های دقیق آن ها بفهمد ، اما این اطلاعات به سرعت از بین می روند. درعوض ، تمرکز بر روشهایی که در آنالیز رسانه های اجتماعی استفاده می شود ، چارچوبی را فراهم می کند برای سنجش ابزارهای نوظهور فناوری ابزارهای COTS معمولاً تجزیه و تحلیل واژگانی ، آنالیز شبکه ، تجزیه و تحلیل موقعیت مکانی یا ترکیبی از این قابلیت ها را ارائه می دهند.
OSINT به دلیل دشواری در درک منابع و روشهای پویا OSINT ، به ویژه سیستم عاملهای رسانه های اجتماعی ، مورد استفاده قرار نمی گیرد. همچنین چالش های جدیدی از جمله نحوه محافظت از افراد آمریکایی ، مدیریت مقادیر گسترده داده ها و استفاده از ابزارها و اشخاص بخش خصوصی را در حد امکان ممکن ارائه می دهد.
range.1 تعاریف بهبود یافته از روشها و روشهای مجموعه استفاده شده برای پردازش ، بهره برداری و تجزیه و تحلیل OSINT که در این گزارش ارائه شده است برای کمک به متخصصان اطلاعاتی سیستماتیک کردن اقدامات مختلف مجموعه منبع باز در سراسر آی سی و به طور کامل از ارزش اطلاعات OSINT استفاده می کند. مطالعه روندهای نوظهور در OSINT و قابلیت های فنی ، موقعیت های IC را برای پرورش این منابع و روش ها متناسب با نیازهای اطلاعاتی قرار می دهد.
تقدیرنامه ها
نویسندگان می خواهند از رهبران مرکز سیاست گذاری اطلاعات که امکان انجام این تحقیق را داشتند ، تشکر کنند. ما از محققان RAND که در زمینه تجزیه و تحلیل منبع باز از جمله الیزابت بدین بارون ، ویلیام مارچینینو ، مایکل دککر ، مادلین مگنوسون و زو وینکلمن کار می کنند تشکر می کنیم که در درک روش ها و سیستم عامل ها به آنها کمک کردند. تشکر های بیشتر به خاطر سارا سلیمان ومری کوین به دلیل نظرات خلاقانه و سازنده خود در بررسی تضمین کیفیت. به طور خاص ، ما به خاطر کمبود وقت و تخصص وی در زمینه تحقیق و بررسی و ارائه تابلوی آماده صدایی آماده برای ایده ها ، به کامرون کلوخون بدهی قدردانی داریم.سرانجام ، ما از دوری واکر بخاطر کمکش در زمینه گرافیک و هالی جانسون بخاطر کمکش در طول تهیه این گزارش تشکر می کنیم.
اختصارات
|
CIA |
Central Intelligence Agency |
سازمان اطلاعات مرکزی |
|
COTS |
commercial off-the-shelf |
تجاری غیر از بسته |
|
DDI |
Directorate for Digital Innovation |
مدیر نوآوری دیجیتال |
|
DIA |
Defense Intelligence Agency |
آژانس اطلاعات دفاعی |
|
DNI |
Director of National Intelligence |
مدیر اطلاعات ملی |
|
DoD |
U.S. Department of Defense |
وزارت دفاع آمریكا |
|
DOSC |
Defense Open Source Council |
شورای منبع باز دفاعی |
|
ELINT |
electronics intelligence |
هوش الکترونیکی |
|
FBIS |
Foreign Broadcast Information Service |
سرویس اطلاعات پخش خارجی |
|
FBMS |
Foreign Broadcast Monitoring Service |
سرویس نظارت بر پخش خارجی |
|
geospatial intelligence |
هوش جغرافیایی |
|
|
GPS |
Global Positioning System |
سیستم موقعیت یاب جهانی |
|
HUMINT |
human intelligence |
هوش انسانی |
|
IC |
Intelligence Community |
جامعه اطلاعاتی |
|
IMINT |
imagery intelligence |
هوش تصویری |
|
INT |
intelligence discipline |
رشته اطلاعاتی |
|
IP |
individual protocol |
پروتکل فردی |
|
ISIS |
Islamic State of Iraq and al-Sham |
دولت اسلامی عراق و الشام |
xiv Defining Second Generation Open Source Intelligence (OSINT) for the Defense Enterprise
xiv تعریف نسل دوم اطلاعات منبع باز (OSINT) برای شرکت دفاعی
|
MASINT |
measurement and signature intelligence |
اندازه گیری و هوش امضا |
|
NGA |
National Geospatial-Intelligence Agency |
آژانس اطلاعات ملی جغرافیایی و اطلاعاتی |
|
NSA |
National Security Agency |
آژانس امنیت ملی |
|
ODNI |
Office of the Director of National Intelligence |
دفتر مدیر اطلاعات ملی |
|
OSC |
Open Source Center |
مرکز منبع باز |
|
OSE |
Enterprise |
شرکت، پروژه |
|
OSIF |
open source information |
اطلاعات منبع باز |
|
OSINT |
open source intelligence |
هوش منبع باز |
|
OUSD-I |
Office of the Under Secretary of Defense for Intelligence |
دفتر معاون وزیر دفاع وزارت اطلاعات |
|
PAI |
publicly available information |
اطلاعات در دسترس عموم |
|
signals intelligence |
سیگنال هوش |
فصل اول
مقدمه: اهداف این تحقیق
ارزش اطلاعات منبع باز (OSIF) برای تکمیل اطلاعات طبقه بندی شده از مدت ها قبل شناخته شده است ، اما رواج روزافزون اینترنت و ظهور رسانه های اجتماعی و تجزیه و تحلیل داده های بزرگ در دو دهه گذشته باعث تحول در هوش منبع باز (OSINT) شده است.تلاش های جدید مجموعه و فعالیت های بهره برداری ، منابع اطلاعاتی با ارزش و اصلی را به انجمن اطلاعات (IC) و شرکت دفاعی می آورد. منابع آزاد همچنین قدرت جایگزینی و / یا تکمیل دسترسی هایی را دارند که زمانی فقط از طریق سیستم عامل های سنتی تر جمع آوری اطلاعات خطرناک و پرهزینه تر به دست می آمدند.
اگرچه آی سی بیش از 50 سال در OSINT درگیر بوده است ، اما تعریف OSINT و نحوه توصیف آن به عنوان یک رشته اطلاعاتی هنوز هم مورد بحث است. در سندی که در سال 2011 توسط دفتر مدیر اطلاعات ملی صادر شده است ، “OSINT” به عنوان “اطلاعات تولید شده از اطلاعات عمومی که جمع آوری ، بهره برداری می شود ، و به موقع برای مخاطبان مناسب به منظور پرداختن به یک هوش خاص تولید می شود ، تعریف شده است. 1) اینترنت و ظهور رسانه های اجتماعی این مسئله را پیچیده تر کرده است. OSINT از نظر منابع و روشها پیچیده تر می شود. افراد به روشهایی که قبلاً هرگز وجود نداشت ، از جمله بیان آنلاین احساسات شخصی ، عکس از مکانها و اتفاقات محلی و شبکه های اجتماعی و حرفه ای را به اطلاع عموم می رسانند. تلفیق قدرت رایانه و تکنیک های دانش داده امکان حفظ و پردازش مقادیر انبوه داده های در دسترس عموم را فراهم می آورد. یادگیری ماشین ، الگوریتم های رایانه ای و استدلال خودکار ظرفیت پردازش این اطلاعات و یافتن پیامدهای با ارزش هوش را بیشتر می کند.
این روش ها و سیستم های جدید همچنین به سطح بالایی از دانش فنی برای جمع آوری و تحلیلگران پردازش اطلاعات در دسترس عموم نیاز دارند.تجارت تاریخی OSINT در درجه اول ترجمه بود – ساخت مقالات خبری خارجی برای تحلیلگران اطلاعات منبع در دسترس. هنگامی که یک منبع باز عمدتاً اصلی باشد گزارش ترجمه شده است ، تحلیلگران همه منبع می توانند آن را در یک محصول اطلاعاتی نهایی به کار گیرند. تجارت مدرن OSINT غالباً به تولید ، پردازش و بهره برداری گسترده تر نیاز دارد تا بتواند محصولی با منبع آزاد را تولید کند سپس در یک کالای تمام منبع تمام شده ادغام شوید.علاوه بر این ، اطلاعات اغلب از طرف افراد حاصل می شود که پیچیدگی های جدیدی را برای محافظت از حریم شخصی افراد آمریکایی ایجاد می کند.همه این تغییرات نیاز به یک تعریف مستحکم تر از OSINT دارند ، زیرا داده های منبع آزاد می توانند به اشکال مختلفی ارائه شوند.
با توجه به تغییر ماهیت اطلاعات در دسترس عموم ، پیشنهاد می کنیم دوره فعلی را نسل دوم OSINT در نظر بگیریم. پزشکان تشخیص دادند كه ظهور محاسبات شخصی در دهه 1990 – همچنین دوره ای كه مخفف اختصاری OSINT- اختراع شده است – تأثیر زیادی خواهد داشت. حوادثی مانند انقلاب سبز ایران در سال 2009 نمونه بارز چگونگی استفاده از جدید را نشان داد
اشکال رسانه های اجتماعی می توانند یک تصویر اطلاعاتی در زمان واقعی را در محیطی محروم ارائه دهند. 2 با این وجود ، ما توصیه می کنیم که این تغییر را به نسل دوم OSINT به 2005 اختصاص دهید. در سال 2005 بود که IC مرکز منبع باز را ایجاد کرد .3. اینترنت. همچنین در این دوره با تغییر بخش عمده محتوای آنلاین به صفحات وب پویا ، محتوای تولید شده توسط کاربر و رسانه های اجتماعی در حال تغییر است. این انتقال اغلب به عنوان ظهور وب 2.0 توصیف می شود ، اصطلاحی که در اواخر سال 2004 در کنفرانس وب 2.0 مشهور شد. Facebook.com و YouTube.com در سال 2005 راه اندازی شدند و توییتر در اوایل 2006 تاسیس شد.
این گزارش تعاریفی از OSINT نسل دوم و فرآیند OSINT را ارائه می دهد. این اطلاعات باید به مصرف کنندگان اطلاعات کمک کند که بهتر بتوانند مجموعه OSINT و روشهای تحلیلی را درک کنند ، به سازماندهی تلاشهای OSINT کمک کنند و واژگان عملی را که توسط متخصصان منبع باز استفاده می شود رمزگذاری کنند. این گزارش همچنین برخی از ابزارهای در حال تغییر سریع را برای تجزیه و تحلیل مواد آنلاین ، به ویژه محتوای رسانه های اجتماعی ، توضیح می دهد.
در انجام این تحقیق ، ما ادبیات مربوط به عملکرد OSINT را مرور کردیم و تعاریف مورد استفاده در حوزه های دیگر توسط IC در زمینه منابع مدرن OSIF را مورد بررسی قرار دادیم. این تلاش به مواد رمزگشایی شده در وب سایت آژانس اطلاعات مرکزی (سیا) متکی بود. مقالات غیر طبقه بندی شده در مطالعات در اطلاعات ، یک مجله منتشر شده توسط آی سی
برای متخصصان اطلاعات و کتاب های درسی در مورد اطلاعاتی که اعضای و دانش آموزان IC استفاده می کنند. با توجه به اینکه قصد داریم این مطالعه را طبقهبندی نشده نگه داریم ، ما تحقیقات خود را به مستندات در دسترس عموم محدود کردیم که این زیرمجموعه کوچکی از اطلاعات در دسترس است آی سی مطالعه جامع تر این موضوع می تواند از تلاش گسترده جهت جمع آوری داده ها با پزشکان و متخصصان OSINT بهره مند شود.
تعریف بهینه از روشها و روشهای مجموعه مورد استفاده برای پردازش ، بهره برداری و تجزیه و تحلیل OSINT می تواند به متخصصین اطلاعاتی کمک کند تا سیستم های مختلف تلاش برای جمع آوری متن منبع از طریق IC را یکپارچه سازی ، ارزیابی OSIF و ادغام OSINT در محصولات اطلاعاتی تمام منبع. OSINT اغلب توسط IC مورد استفاده قرار نمی گیرد به دلیل مشکل در درک منابع و روشهای OSINT در حال ظهور ، به خصوص سیستم عاملهای رسانه های اجتماعی. تحلیلگران تمام منبع گاهی اوقات به دلیل عدم اطمینان در مورد چگونگی ارزیابی اعتبار و قابلیت اطمینان اطلاعات و تمایل آنها برای محافظت از اطلاعات شخصی و اطلاعات افراد آمریکایی ، از سوء استفاده از این منابع داده به بهترین وجه عمل نمی کنند. تحلیلگران همچنین ممکن است نسبت به پذیرش کامل رسانه های اجتماعی با توجه به ناآشنایی شخصی با سیستم عامل ها ، تردید کنند ، زیرا متخصصان اطلاعاتی غالباً توصیه می کنند که از رسانه های اجتماعی کم برخوردار باشند. سرانجام ، انتقال مواد منبع به سیستم های IC باعث افزایش برخی منابع منبع باز می شود فقط یک قدم اضافی که ممکن است دستیابی و تحلیل را کند کند. در مقابل ، ارزش بالای تولید برخی از تحلیل های رسانه های اجتماعی ممکن است منجر به ارائه آن به عنوان یک اطلاعات مستقل برای مشتریان شود ، هنگامی که یک زمینه تمام منبع می توانست تصویر اطلاعاتی جامع تری را ارائه دهد.
برخی از تلاشهای قبلی برای تعریف OSINT بر چگونگی تعریف OSIF و اطلاعات در دسترس عموم (PAI) – ماده منبع متمرکز شده است. تعاریف به دست آمده در توصیف اطلاعات خام جمع آوری شده بدون در نظر گرفتن استفاده از روش های طبقه بندی شده و ابزار فنی متمرکز شده است. در فصل دوم ، ما به طور جامع به OSINT به عنوان یک رشته اطلاعاتی نگاه می کنیم که شامل روش های دستیابی ، پردازش ، بهره برداری و تجزیه و تحلیل اطلاعات است. در فصل سوم ، ما به روشهای متمرکز شده ایم تجزیه و تحلیل منبع باز ، به ویژه در حوزه داده های رسانه های اجتماعی. سرانجام ، فصل چهارم به طور خلاصه در مورد برخی از چالش ها و فرصت های نوظهور ارائه شده توسط OSINT بحث می کند.
برای پزشکان IC که در دنیای OSINT غوطه ور هستند ، ممکن است مطالب ارائه شده جدیدی نباشد. با این حال ، هدف ما ارائه زمینه و تعاریفی است که سایر اعضای IC را قادر می سازد تا کار همتایان محور OSINT و ارزش آن را برای پشتیبانی اطلاعاتی از سیاستگذاران محقق کنند. ما امیدواریم چنین پایه ای به تلاش آنها برای ادغام مواد OSINT در محصولات اطلاعاتی کمک خواهد کرد و مهارتهای فنی در اختیار متخصصین OSINT را بیشتر می کند. علاوه بر این ، می تواند قدردانی آنها از هوش بالقوه را تقویت کند مقدار OSIF. این گزارش همچنین باید برای افراد خارج از IC که ممکن است مایل به کسب اطلاعات بیشتر در مورد OSINT ، چگونگی استفاده از آن در جهت ارتقاء محصولات اطلاعاتی و چالش ها و شکاف های حرفه ای در این زمینه باشند ، مفید باشد.
تاریخچه مختصری از OSINT و ارتباط آن با شرکت دفاعی
OSINTبه عنوان یک شرکت دفاع گرا آغاز شد. ایالات متحده سرویس نظارت بر پخش بی سیم خارجی (FBMS) را در 26 فوریه 1941 تأسیس کرد تا برنامه های تبلیغاتی قدرت های محور را محاسبه و تجزیه و تحلیل کند . در ابتدا توسط کمسیون ارتباطات فدرال اداره می شد – تنها سازمانی که توانایی انجام مأموریت را دارد. این بودجه با بودجه ویژه دفاع مالی شد. در تاریخ 26 ژوئیه سال 1942 ، FBMS به خدمات اطلاعات فدرال پخش (FBIS) تغییر نام یافت ، تا حدودی برای اینکه صدا و سیمای آن بیشتر شبیه یک آژانس جنگ شود. تقریباً در پایان جنگ جهانی دوم بسته شد ، FBIS در تاریخ 1 ژانویه 1946 توسط وزارت جنگ به تصویب رسید. یک سال بعد طبق قانون امنیت ملی سال 1947 به CIA منتقل شد و در این زمان
این یک سازمان “تقریباً بالغ ، آموزش دیده و منضبط” از تجربه جنگ بود. بیست سال بعد ، تاریخ رسمی CBIS در CIA “سازمان و مسئولیت های اساسی آن” را توصیف کرد. . . عمل و روش های اساسی “تا حد زیادی بدون تغییر است.
از زمان ایجاد FBIS تا دهه 1990 ، تفسیر تجزیه و تحلیل منبع باز در IC عمدتا نظارت و ترجمه منابع مطبوعات خارجی بود. تفاوتهای مهمی بین این شخصیت تاریخی OSINT- نسل اول OSINT- و نسل دوم امروز وجود دارد. جمع آوری مواد تأکید قابل توجهی در تلاش OSINT نسل اول بود. FBIS 20 دبیرخانه سراسر جهان را اداره کرد تا به آن اجازه دهد تا از لحاظ جسمی مواد را برای بهره برداری جمع کند. سفارتخانه ها همچنین بستر جمع آوری مطالب را فراهم کردند. علاوه بر افسران دیپلماتیک ، پیوست های دفاعی به عنوان گردآورندگان آشکار فعالیت می کردند. سیستم Attaché Defense در سال تلفیق شد 1964-1965تحت مقامات آژانس اطلاعات دفاعی (DIA). برخی از کارکردهای مأموریت به منظور تمرکز روی مطالب با اولویت بالا کاهش یافت ، اما نیاز اصلی برای پردازش این ماده در درجه اول ترجمه بود. اگرچه ، باید توجه داشت كه FBIS از زمان تأسیس تاكنون برخی از كاركردهای تحلیلی (در درجه اول تحلیل روند) را انجام داده است.
کار FBIS بینش های مهمی و تصمیم گیری هایی را برای ارتش در طول جنگ سرد ارائه داد ، از جمله اولین نشانه های حذف موشک های اتحاد جماهیر شوروی از کوبا ، هشدار زود هنگام خروج اتحاد جماهیر شوروی از افغانستان ، و زمینه در مورد بحران در مجارستان و چکسلواکی. هشتاد درصد از اطلاعات مورد استفاده برای نظارت فروپاشی اتحاد جماهیر شوروی به منابع آزاد منسوب است . پایان جنگ سرد منجر به كاهش بودجه برای بیشتر مؤسسات IC شد ، اما برای FBIS و مأموریت منبع باز بحران خاصی ایجاد كرد. در همان زمان حجم OSIF بود با افزایش چشمگیر ، FBIS به سرعت منابع خود را از دست می داد. در سال 1997 ، FBIS به عنوان بخشی از کاهش بودجه سیا در معرض خطر انحلال قرار گرفت ، اما توسط یک کارزار عمومی توسط فدراسیون دانشمندان آمریکایی ذخیره شد. FBISدر همان زمان توسط دانشگاهیان توصیف شد
“بزرگترین انفجار در جامعه اطلاعاتی آمریکا”.
رهبران آی سی تصدیق کردند که چالش ها و پویایی قرن بیست و یکم باعث افزایش تقاضای بیشتر برای OSINT ، نه کمتر. معاون مدیر FBIS ، جی.نیلز ریدل ، در اولین سمپوزیوم بین المللی منبع آزاد در سال 1992 ، تغییرات در OSINT را ناشی از افزایش محاسبات شخصی ، ذخیره سازی دیجیتال با ظرفیت زیاد ، موتورهای جستجوگر توانمند و شبکه های ارتباطی پهن باند دانست. وی معتقد بود كه همه این عوامل منجر به رشد نمایی در تجاری سازی اطلاعات خواهد شد. در همان روزی ، معاون دریاسالار ویلیام استودمن ، معاون سیا ، خواستار “تغییر انقلابی در رویكرد جامعه اطلاعاتی برای مدیریت منابع ، جمع آوری ، پردازش و انتشار” شد.رهبران آی سی دیدند که منبع آزاد در حال تبدیل شدن به یک رشته اطلاعاتی ناخوشایند است. دریاسالار Studeman سایر رشته های مجموعه را به عنوان “بسیار ساختار یافته” توصیف کرد اما اظهار داشت که “منبع آزاد یک نظم و انضباط کاملاً یکپارچه نیست” و اینکه “گردآورندگان اطلاعات منبع آزاد ، پردازنده ها و کاربران متنوع بوده اند و گروههای غیر متمرکز در وسعت و عمق آن گسترش یافته اند. جامعه. “آی سی آی سی از دارایی ها و قابلیت های غیر طبقه بندی نشده خود خبر نداشت ، و هیچ ابزاری برای به اشتراک گذاری OSIF نداشت.
این مشکلات بخصوص در شرکت دفاعی حاد بود. یک کارگروه در دفتر وزیر دفاع وزارت اطلاعات (OUSD-I) در سال 2004 نواقصی در سیاست های منبع باز و آموزه ها ، آموزش ها و مدیریت پیدا کرد. علاوه بر این ، الزامات منبع باز وزارت دفاع آمریكا (وزارت دفاع وزارت دفاع) كمتر از موارد ارائه شده و كمكهای لازم در زمینه IC ارائه نمی شود. این یافته ها باعث ایجاد شورای دفاع از منبع باز (DOSC) شد كه از طریق دستورالعمل وزارت دفاع به عنوان سازوكار اصلی دولت برای وزارت امور خارجه منصوب شد. 3115.12. این دستورالعمل DoD در حال به روزرسانی است تا تعدادی از روندها و چالش های شرح داده شده در این گزارش را در نظر بگیرد.
در اول نوامبر 2005 ، مدیر اطلاعات ملی (DNI) مرکز منبع آزاد (OSC) را ایجاد کرد و سیا را به عنوان عامل اجرایی خود تعیین کرد ، بعداً آن را به عنوان “مدیر عملکردی” مجدداً طراحی کرد. مستقر در CIA و جایگزین FBIS ، نام تجاری OSC به تمرین کنندگان OSINT مجوز بیشتری برای گسترش فراتر از نظارت و ترجمه خبر داد. ایجاد OSC یک شرط قانون اصلاحات اطلاعاتی و پیشگیری از تروریسم در سال 2004 را برآورده کرد ، که به طور خاص خواستار ایجاد یک مرکز اطلاعاتی اختصاص داده شده به “جمع آوری ، تجزیه و تحلیل ، تولید و انتشار اطلاعات منبع باز” بود. DNI با اطمینان از استفاده مؤثر و مؤثر OSIF و تجزیه و تحلیل از IC استفاده می شود. بعلاوه
تولید OSINT ، اهداف OSC شامل آموزش بهره برداری از منبع باز و تجزیه و تحلیل ، توسعه ابزار و آزمایش فناوری های جدید است.
در اکتبر سال 2015 ، OSC به شرکت منبع باز (OSE) تغییر نام داد و تحت یک اداره تازه تاسیس برای نوآوری دیجیتال (DDI) در CIA آورده شد. گنجاندن OSE در دبیرخانه ای با محوریت تهدیدات سایبر و فناوری دیجیتال می تواند استقبال این موسسه از فناوری و تحلیلی را تقویت کند
ابزار؛ با این حال ، برخی نگران هستند که این امر همچنین می تواند جهت گیری بیرونی مأموریت جمع آوری و تجزیه و تحلیل سازمان را در حمایت از کل آی سی مانع کند. علاوه بر این ، دفتر مدیر اطلاعات ملی ملی (ODNI) اذعان می کند که “مسئولیت های جمع آوری openource بطور گسترده از طریق IC توزیع می شود ،” OSC را به عنوان یک جمع کننده اصلی ، اما نه تنها مجموعه OSIF توصیف می کند.
فصل دوم
ODNI (دفتر مدیریت اطلاعات ملی) شش رشته مجموعه یا شش منبع اطلاعاتی اساسی را تعریف می کند. 1 OSINT در رده های ODNI گنجانده شده است ، اما منابع دیگر حضور آن را به عنوان یک نظام اطلاعاتی (INT) عنوان میکنند. برخی OSINT را رد می کنند زیرا اطلاعات از منابع آزاد به صورت مخفی جمع آوری نمی شود. از طرف دیگر ، مارک لولنتال ، معاون سابق شورای اطلاعات ملی ، استدلال می کند که OSINT یک رشته اطلاعاتی جداگانه نیست بلکه جنبه ای از سایر رشته های اطلاعاتی مختلف دیگر است.
لولنتال به جای تمرکز سنتی روی شیوه کسب اطلاعات، تعاریف بین المللی را به سمت نوع اطلاعات جمع آوری شده سوق می دهد. استفان مركادو به طور مشابه “نسخه های باز هنرهای پنهان ، تصاویر هوشمند (IMINT) و سیگنال های هوشمند (SIGINT) را توصیف می كند”. چگونگی تعریف رشته های اطلاعاتی از اهمیت بالایی برخوردار است ، زیرا تعاریف اغلب ،چگونگی رفتار داده های اطلاعاتی توسط تحلیلگران اطلاعاتی منابع کلی ، به ویژه چگونگی ارزیابی آن برای ارزش و اعتبار را اثبات می کند. همچنین آنها اینکه آیا یک محصول اطلاعاتی تک منبع یا تمام منبع عرضه شده است را میسنجند ، که این موضوع بر ارزیابی های جامعه اطلاعاتی در مورد قابلیت اطمینان محصول تأثیر می گذارد. علاوه بر این ، اولویت بندی تلاش های مجموعه در نحوه طبقه بندی اطلاعات (به اشتراک گذاشته شده و انتشاریافته) غالباً تعاریف رشته های اطلاعاتی را دنبال می کند ، و تأکید می کند که توصیفOSINT چقدر مهم است. مسائل مربوط به آخرین تعریف با این واقعیت پیچیده می شوند که برخی از متخصصان اطلاعاتی تمایل دارند جوامع اطلاعاتی را بی مانندو متمایز از یکدیگر بدانند. چارچوب کارآمد تر تفکر به این نظامات، مانند چارچوب های تعریف لولنتال و مرکادو است. رشته های اطلاعاتی به ندرت، کاملاً مستقل از یکدیگر هستند و تعاریف آنها گاه توسط مقامات بی نظیر نظارتی سازمانهای جمع آوری اطلاعات بیش از تفاوتهای مشخص بین روشهای جمع آوری یا اجزای خودش، بیان می شود.
به عنوان مثال ، خط مابین اطلاعات سرزمینی (GEOINT) و هوش حسابی (MASINT) غالباً مبهم است و با تکنیک های پیشرفته ذهنی افزایش می یابد. به طور مشابه ، اطلاعات الکترونیکی (ELINT) گاهی اوقات اطلاعات حسابی (MASINT) در نظر گرفته می شود و بعضی مواقع جزء اطلاعات سیگنالی (SIGINT) محسوب می شود.جمع آوری اطلاعات ( HUMINT) برخی اوقات به روش های مشابه به (SIGINT) مشخص می شود. OSINT ممکن است پیچیده ترین و مکرر ترین نمونه های این نوع همپوشانی های انضباطی را ارائه دهد ، اما در این زمینه بین رشته های اطلاعاتی منحصر به فرد نیست. به طور فزاینده ای ، GEOINT نیز OSINT است ، زیرا ماهواره های تجاری اکنون قادر به ارائه تصویر از اماکن روباز هستند و این امکان را دارند که از نظر تاریخی فقط توسط سیستم عامل های مجموعه طبقه بندی شده ارائه شوند. OSINT برگرفته از رسانه های اجتماعی می تواند نوعی HUMINT و SIGINT محسوب شود. مشابه HUMINT ، جمع آوری داده های رسانه های اجتماعی بینش ها و دیدگاه های یک فرد را ارائه می دهد – شخصی که یا دسترسی منحصر به فردی دارد یا ممکن است دیدگاه نمایندگی برای یک جامعه یا یک جمعیت خاص ملی را فراهم کند. مشابه SIGINT ، جمع آوری داده های رسانه های اجتماعی ممکن است شامل جمع آوری تعداد زیادی از سوابق باشد که با استفاده از وسایل فنی برای شناسایی تعامل یا ارتباطات مورد علاقه منتخب می شوند. دلایل مهم این روند این است که دستیابی به منابع باز فیسبوک (OSIF) از طریق روشهای جمع آوری منبع آزاد دشوارتر است. شکل 2.1 نمایش بصری از این رشته های اطلاعاتی همپوشان را ارائه می دهد این به معنای مشخص کردن تمام روشهایی نیست که رشته های اطلاعاتی به طور بالقوه می توانند با هم همپوشانی داشته باشند. در عوض ، خطوط مبهم بین مناطق مختلف اطلاعاتی را نشان می دهد.
تعریف منبع باز و OSINT
ما OSINT را به عنوان اطلاعات در دسترس عموم که مشخصا از ارزش اطلاعاتي برخوردار است و توسط عضوی از جامعه اطلاعاتی کشف شده است،تعريف مي كنيم. این با تعریف ایالات متحده در بخش 931 قانون مدنی شماره 109-163 مطابقت دارد که OSINT را “اطلاعاتی تعریف میکند که برگرفته از اطلاعات عمومی در دسترس مردم است که جمع آوری و بهره برداری می شود و درزمانی معین ،جهت رفع نیاز خاص اطلاعاتی بین مخاطبان ویژه توزیع می شود. OSIF صرفاً داده های طبقه بندی نشده در دسترس عموم است ، بطوریکه OSINT از اعمال پردازش و سوء استفاده از اطلاعات برای اعتبارسنجی آن به منظور واسط ارتباطی ، دقت سنجی و عملگر جهت استفاده ی مصرف کنندگان نتیجه می گیرد.
 به عنوان یک نظام دفاعي")
آنچه OSINT و OSIF را تشکیل می دهد ، جهانی تعریف نشده است. به عنوان مثال ، کتاب دستی مطالعات اطلاعاتی ، یک کتاب درسی محبوب ، چهار دسته مجزا از OSIF و OSINT را مشخص می کند. داده های منبع آزاد به عنوان چاپ خام ، پخش گسترده ، تفسیر شفاهی یا سایر اشکال اطلاعات از منبع اصلی تعریف می شوند. OSIF به عنوان داده هایی توصیف می شود که می تواند از اطلاعات عمومی که معمولاً به طور گسترده پخش می شود ، جمع شود. منابع شامل روزنامه ها ، کتاب ها ، بردکستها(پخش همگانی) و گزارش های عمومی روزانه هستند. . OSINT به عنوان اطلاعاتی تعریف شده است که “مورد بحث ، کشف ، تبعیض ، تقطیر و انتشار برای مخاطبان منتخب قرار گرفته است5”. یک OSINT معتبر، بابررسی درجه اطمینان ازآن OSINT تشخیص داده می شود اما این تعاریف به تنهایی ،برای ابزارهای اطلاعاتی کاربرد محدودی دارند.. به عنوان مثال ، آیا یک مقاله خبری Associated Press را می توان داده های منبع باز (چون چاپ خام است) یا OSIF (از آنجا که می تواند در یک روزنامه چاپ شود) در نظر گرفت؟ ما این تعاریف را تهیه ونشر کردیم تا بهتر بتوانیم بین این گونه ها تمایز قایل شویم و مستقیماً به برخی از تعاریف ارائه شده توسط جامعه اطلاعاتی بپردازیم. ما همچنین از استفاده از اصطلاح OSINT معتبر خودداری کرده ایم ، زیرا اعتبار داده های اطلاعاتی بهتر از یک طیف)منظر) است و نه به عنوان یک اندازه باینری.
ما گونه شناسی زیر را پیشنهاد می کنیم:
• داده های منابع آزاد، عناصری هستند که بصورت تک از ارزش کمی برخوردارند اما بطورجمعی از ارزش اطلاعاتی برخوردارند. به عنوان مثال ، یک توییت از توییتر که نمایانگر یک فرد تصادفی از دولت اسلامی عراق و الشام (داعش) باشد ، تقریباً هیچ ارزش اطلاعاتی ندارد. با این حال ، ترکیب همه توییتها ی نمایشی درباره داعش در یک منطقه جغرافیایی ، از ارزش اطلاعاتی بالایی برخوردار است. به طور مشابه ، آدرس های پروتکل اختصاصی (IP) هیچ ارزش اطلاعاتی ندارند ، اما نقشه برداری از4.3میلیارد آدرس های IP جهان ، تصویری جهانی از استفاده ی اینترنت ارائه می دهد.6 داده های منبع آزاد شامل مطالب عمومی است که به صراحت منتشر نشده اما هنوز به صورت عمومی یا تجاری در دسترس است مثلا از جمله آن، تصاویر ماهواره ای تجاری میباشد.
• OSIF عنصری است که می تواند از طریق درخواست ، خرید یا مشاهده توسط یک عضو عمومی به طور قانونی بدست آید.این شامل داده های منابع بازاست اما همچنین شامل مطالب با محتوای اصلی تر میباشد. بنابراین OSIF گسترده ترین گروه بندی ازاطلاعات عمومی یا تجاری دردسترس است.
زیرگروه های OSINT
یکی از چالشها در تعریف OSIF این واقعیت است که تعداد کمی اززیرگروههای شناخته شده برای تمایز بین انواع اطلاعات وجود دارد و تعاریف موجود ماهیت متغیر اطلاعات عمومی را به درستی توجیه نمی کند . بعنوان مثال تعریف ادبیات خاکستری با ظهور اینترت پیچیده شده است. کارگروه ادبیات خاکستری در وزارت امور خارجه در سال 1995 ، ادبیات خاکستری را به عنوان “عنصر منبع باز خارجی یا داخلی که معمولاً از طریق کانالهای تخصصی در دسترس است و ممکن است وارد کانالها یا سیستمهای انتشار ، توزیع ، کنترل کتابشناسی یا دستیابی به آن نشود ، تعریف نمود یا عنصری که توسط فروشندگان یا نمایندگان مشترکین کسب میشود. “این تعریف می تواند شامل طیف گسترده ای از انواع اطلاعات باشد : مقالات کنفرانس ، اسناد شرکت ها ، پایان نامه ها ، گزارش های دولت ، خبرنامه ها ، سوالات تجاری ، گزارش های سفر – که معمولاً توسط موسسات تحقیقاتی ، دولت های ملی ، ناشران خصوصی ، شرکت ها ، انجمن های صنفی. و اتحادیه ها و اتاق های فکر و دانشگاه که منتشر می شود. دشوارترین وجه مقابله با ادبیات خاکستری در گذشته ، دستیابی به آن بود و دسترسی به آن همچنان بر پایه تعریف های فعلی از آن است.9 با این وجود ، بسیاری از این مطالب اکنون به صورت آنلاین در دسترس هستند. بنابراین ، تمرکز روی دسترسی، دیگر معیاری مؤثر برای تعریف ادبیات خاکستری نیست. خدمات تحقیقاتی کنگره در سال 2007 چهار دسته از OSIF را شرح داد: “داده ها و اطلاعات گسترده ای در دسترس؛ داده های تجاری هدفمند؛ کارشناسان فردی؛ و ادبیات “خاکستری”. “10 با این حال ، مقولات داستانی مطابق با تصورجامعه اطلاعاتی از منبع آزاد سازگار نیستند ، و همچنین به طور مؤثر محتوای رسانه های اجتماعی را ضبط نمی کنند با توجه به ماهیت به سرعت در حال تغییر منابع و سیستم عامل های آنلاین ، تهدیدی آشکار در تعریف OSIF وجوددارد . با این حال ، بدون چارچوبی برای تمایز بین دامنه توزیع OSIF وچرخه اطلاعاتی OSINT بدلیل اختلاف چشمگیر در پردازش و بهره برداری از انواع مختلف OSIF ، نمی توان آن را به طور دقیق تعریف کرد.ما پیشنهاد می کنیم OSIF را به چهار دسته تقسیم کنیم – دو دسته اصلی ، هر یک سطحی بیشتر را تقسیم می کنند. این بخش ها به این دلیل انتخاب شدند که در مورد نیازمندی ها برای جمع آوری ، پردازش و بهره برداری از اطلاعات ،سازگاری کافی دارند. تمایز ابتدا توسط تولید کننده محتوا تعیین می شود:
تولید محتوا در مقابل محتوای تولید شده به صورت جداگانه صورت گیردو از نظر محتوای مضامین رسانه ای خبری و سایر محتوای نهادی ، که بخش اعظم آن ممکن است قبلاً به عنوان ادبیات خاکستری تعریف شده باشد ، تولید می شود. . محتوا به صورت جداگانه و یا محتوای رسانه های اجتماعی بین فرم بلند و کوتاه شکل تقسیم می شود که تفاوت های مهمی برای پردازش و استفاده دارند.
محتوای رسانه های خبری
محتوای پنجم رسانه های خبری به عنوان یک ژورنالیسم و به صورت عمومی شناخته می شود. منابع آن عبارتند از: روزنامه ها ، مجلات (چاپی و آنلاین) ، تلویزیون و رادیو. سایت های جمع آوری خبر نیز شامل رسانه های خبری می شوند که ممکن است محتوای اصلی را منتشرکرده یا نکنند. محتوای رسانه های خبری شامل محتوای تولید شده دولتی است که بطور اختصاصی توسط یک رسانه توزیع می شود.
ادبیات خاکستری
ادبیات خاکستری محتوایی است که از سوی مؤسسات و سازمانهای غیر رسانه ای ، چه دولتی و چه خصوصی به دست می آید. . این مطالب شامل مؤسسات تحقیقاتی ، دولتهای ملی ، ناشران خصوصی ، شرکتها ، انجمنهای صنفی و اتحادیه ها ، اتاقهای فکر و دانشگاه است. یک فرض کلی این است که بیشتر محتوای نهادی فقط در فضای مجازی وجود ندارد ، بلکه به طور کلی خشت وگل آن وانسجام نهادی آن درفضای مجازی موجوداست. علیرغم تلاشهایی که ده ها سال پیش برای سازماندهی بهتر خرید ، ذخیره طولانی مدت و توزیع ادبیات خاکستری آغاز شده بود ، هنوز هم اغلب به شیوه ای موقت جمع آوری و مورد استفاده قرار می گیرد.
محتوای رسانه های فرم طولانی
محتوای مصرف کنندگان حقیقی فرم طولانی ، مطالب دارای متن سنگین از اشخاص حقیقی یا گروه های کوچک است که شامل مطالبی از وبلاگ ها و سایت هایی مانند Reddit و Tumblr است.بسیاری از تحلیل محتوای رسانه های اجتماعی بر محتوی فرم کوتاه متمرکز شده اند و محتوای فرم های طولانی را غالباً مورد استفاده قرار نمی دهند.
محتوای رسانه های فرم کوتاه
در محتوای کاربر با فرم کوتاه ، از سیستم عامل هایی مانند Facebook ، Twitter و LinkedIn استفاده می شود. برخلاف محتوای طولانی ، محتوای فرم کوتاه به طور جداگانه ارزش اطلاعاتی کمی دارد. اطلاعات ارزشمند به طور کلی از جمع آوری چنین اطلاعاتی بدست می آید. . استثنا هم وجود دارد ، هرچند که محتوای رسانه های اجتماعی با فرم کوتاه از حساب های خاص مورد علاقه بالا به دست می آید ، به عنوان مثال ، حساب افراد مشهور مانند شخصیت های ارشد دولت ، رهبران فکر و روزنامه نگار برجسته. حجم بالایی از محتوای کوتاه همچنین می تواند شامل حساب های افرادی شود که بخشی از یک گروه هستند که توسط جامعه اطلاعاتی موردهدف قرارگرفته می شوند ، مانند یک واحد ویژه نظامی یا یک گروه شبه نظامی.
چرخه عملیات OSINT
تنها بخشی از حجم گسترده OSIF که به صورت روزانه منتشر و به اشتراک گذاشته می شود ، واجد شرایطی می باشد که برای یک تحلیلگر OSINT ،مرتبط ، به موقع و قابل استفاده باشد.11تعیین آنچه کم و بیش به آن مربوط می شود ، نیازمند به تلاش عظیم در کل طیف اطلاعاتی است ، از جمع آوری اولیه از طریق انتشار یافته ها تا سیاست گذار دریافت کننده ی آنها. تبدیل اطلاعات به اطلاعات خام شامل مراحل مهمی است که در تهیه متن برای ارزیابی اعتبار و ارزش یک گزارش موجود است. OSINT ، با این حال ، هنوز نیاز به یک روش شناسی پویا دارد.12 چند مدل موجود برای توصیف روششناسی اطلاعاتی وجود دارد. چرخه اطلاعاتی سیا این روند را به عنوان برنامه ریزی و جهت ، جمع آوری ، پردازش ، تجزیه و تحلیل و تولید و انتشار توصیف می کند. کتاب راهنمای مطالعات اطلاعاتی ، این مراحل را به عنوان جمع آوری ، پردازش ، تجزیه و تحلیل و تولید ، طبقه بندی و انتشار توصیف می کند.
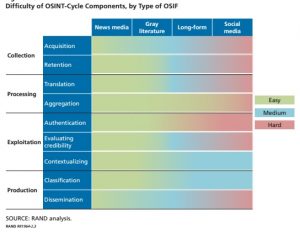
در زمینه OSINT ، ما بر چهار مرحله اصلی تمرکز می کنیم: جمع آوری ، پردازش ، بهره برداری و تولید ، همانطور که در شکل 2.2نشان داده شده است.13 (پردازش و بهره برداری ممکن است به طور متوالی اتفاق نیفتد ، بلکه به صورت موازی یا به طور هماهنگ انجام می شود.) با ساده ترین شرایط ، این مراحل را می توان به عنوان دستیابی به اطلاعات ، اعتبارسنجی آن اطلاعات ، شناسایی ارزش اطلاعات و ارائه اطلاعات به مشتریان توصیف کرد. در بخش های زیر ، هریک از این قسمت ها را به اجزای تشکیل دهنده تقسیم می کنیم. ما به جای تعمیم مرحله برای انواع مطالب منبع باز ، این کار را برای هر یک از انواع OSINT انجام خواهیم داد. تقریباً مشکل هر یک از اجزای چرخه روش شناسی را برای هر یک از زیرگروه های OSINT آسان ، متوسط یا سخت توصیف می کنیم (شکل 2.3 را ببینید) در توصیف دشواری ، عواملی را در نظر گرفتیم که در سطح دشواری نقش دارند ، مانند ساعت کار ، محاسبه منابع مورد نیاز و دسترسی به اهداف سخت. با این حال ، ما منابع لازم برای ایجاد یک روش کامل و مقایسه سیستماتیک این عوامل را نداشتیم. خصوصیات نادرست ما تقریباً یا مطمئناً باعث بحث و گفتگو در بین متخصصان منبع باز خواهد شد.به عنوان مثال ، برخی از تحلیلگران ممکن است استدلال کنند که دستیابی به محتوای رسانه های اجتماعی با توجه به دسترسی آسان به داده های توییتر ، بسیار آسان است. با این حال ، بسیاری از اهداف سخت جامعه اطلاعاتی از سیستم عامل های ملی استفاده می کنند ، و استفاده از توییتر ممنوع یا محدود است ، بنابراین بیرون کشیدن محتوای رسانه های اجتماعی از این پلتفرم ، پاسخگوی بسیاری از شرایط جامعه اطلاعاتی نیست. برای جامعه اطلاعاتی مفید خواهد بود که بررسی دقیق تری در مورد چگونگی وقت و مهارت هر یک از این مناطق برای هر زیر گروه OSINT داشته باشد ، زیرا این امر می تواند به تقسیم دقیق تر منابع کمک کند و می تواند در ارزیابی ارزش اطلاعاتی نسبت به تلاش صرف شده کمک کند.
شکل 2-2
Figure 2.2
 به عنوان یک نظام دفاعي")
RAND RR1964-2.2
|
Processing |
|||
|
Easy |
|||
|
Aggregation |
|||
|
Medium |
|||
|
Authentication |
Hard |
||
|
Exploitation |
Evaluating credibility |
||
|
Contextualizing |
|||
|
Classification |
|||
|
Production |
|||
|
Dissemination |
گردآوری کردن(جمع آوری)
مرحله اول ، مجموعه ، شامل شناسایی اطلاعات بالقوه مفید و نگهداری از آن می باشد. در این مرحله نیاز به راهنمایی – صریح یا عمومی – برای جمع آوری کنندگان منبع آزاد است تا انواع اطلاعاتی را که باید جمع آوری شوند شناسایی کنند و اولویت بندی اقدامات مجموعه را برای منعکس کردن الزامات IC انجام دهند. اکتساب ، مجموعه فیزیکی یا الکترونیکی این اطلاعات است. نگهداري ادامه نگهداري OSIF اكتسابي است. از چهار نوع OSIF که در اینجا مورد توجه قرار گرفته است ، محتوای رسانه خبری ساده ترین جمع آوری است. برای OSINT نسل اول ، کسب فیزیکی داده های رسانه خبری منتقل شده چالش های لجستیکی را نشان می داد که FBIS را ملزم به پراکنده شدن در چندین مکان جغرافیایی برای رهگیری برنامه ها می کرد. مجموعه مواد چاپی وابسته به حضور یک افسر دیپلماتیک یا جمع آوری کننده مخفی برای بدست آوردن مطالب منتشر شده از نظر فیزیکی.
اما امروز ، با وجود اکثر اطلاعات رسانه ای خبری که بصورت آنلاین در دسترس است ، چالش های لجستیک از پردازش به مدیریت اطلاعات تغییر کرده است. حفظ اطلاعات رسانه های خبری کاملاً ساده است. حجم چنین اطلاعاتی قابل مدیریت است ، و اطلاعات به طور کلی در قالب استاندارد و متن محور قرار می گیرد. ادبیات خاکستری ، مانند محتوای رسانه های خبری ، به دلایل مشابه جمع آوری آسانتر می شود. سازندگان ادبیات خاکستری در انتقال به محتوای آنلاین کندتر از رسانه های خبری بوده اند ، بنابراین هنوز مواردی وجود دارد که یک مجموعه گرآوری کننده موظف است اطلاعات فیزیکی را به صورت کپی سخت به خصوص در کشورهای در حال توسعه بدست آورد ، جایی که ممکن است استفاده از اینترنت توسط موسسات گسترده نباشد.
همانطور که در مورد محتوای رسانه های خبری نیز وجود دارد ، حفظ ادبیات خاکستری بسیار دشوار نیست. در عوض ، اطلاعات رسانه های اجتماعی چالش های منحصر به فرد بسیاری را در مرحله جمع آوری ، هم برای محتوای کوتاه و هم برای فرم های طولانی نشان می دهد. در ابتدا ، دستیابی به تصویر کامل از داده های خام می تواند دشوار باشد. در مرحله شروع تحلیل رسانه های اجتماعی ، تجزیه و تحلیل رسانه های اجتماعی به راحتی در دسترس و حتی گاهی استفاده از آنها رایگان بود. به عنوان مثال ، یک شرکت ، تاپسی ، از زمان شروع توئیتر در سال 2006 ، دسترسی کامل به فهرستی کامل از مطالب توییتر را فراهم کرده است. با این حال ، به عنوان تجزیه و تحلیل رسانه های اجتماعی به یک صنعت تاسیس تبدیل شده است ، سیستم عامل هایی مانند تاپسی توسط شرکتهای بزرگتری برای کسب درآمد از این بازارها خریداری شده و بسته شده اند. شرکت های جمع آوری رسانه های اجتماعی که داده های رسانه های اجتماعی را بازاریابی می کنند ، اغلب فقط بخشی از داده های یک بستر رسانه یا مجموعه داده های رسانه های اجتماعی را تنها دریک برهه زمانی خاص ،ارائه می دهند. علاوه بر این ، این ارائه دهندگان همچنان تمایل دارند که روی داده های رسانه های اجتماعی از سیستم عامل های مستقر در ایالات متحده ، مخصوصاً توییتر و فیس بوک متمرکز شوند ، اگرچه سیستم عامل های بومی برای برخی از منافع اصلی IC مرتبط هستند. علاوه بر این ، حتی اگر جامعه ی اطلاعاتی توانایی بدست آوردن مجموعه کاملی از داده های رسانه های اجتماعی را به جای یک زیر مجموعه رادارد، داده ها نمونه ای از جمعیت را ارائه نمی دهند. گروه های جمعیتشناسی از رسانه های اجتماعی به طور برابر استفاده نمی کنند و در بسیاری از مناطق مورد علاقه جامعه اطلاعاتی ، استفاده از طبقه بندی اجتماعی- اقتصادی می تواند بسیار تأثیرگذارباشد. جمع آوری داده های رسانه های اجتماعی همچنین موضوعات حقوقی مربوط به حمایت از افراد آمریکایی را مطرح می کند ، که به ویژه برای نگهداری اهمیت دارد. چنین موضوعاتی با ادبیات خاکستری کم و بیش در رسانه های خبری موجود نیست. از آنجا که داده های رسانه های اجتماعی به راحتی می توانند داده های مربوط به افراد آمریکایی را در بر گیرند ، جامعه اطلاعاتی باید رویه های سختگیرانه مربوط به جمع آوری و نگهداری اطلاعات را دنبال کند. این رویه ها در انواع مقررات ، از جمله دستورالعمل 12333 و دستورالعمل وزارت دفاع 5240.01 به تفصیل شرح داده شده است. علاوه بر این ، هر دو محتوای رسانه های بلندفرم و کوتاه فرم، پویاتر از محتوای رسانه های خبری یا ادبیات خاکستری هستند. مقاله خبری (به استثناء اصلاحات) عموماً یک سند زنده نیست – اگر داستانی تغییر کرده است ، یک مقاله جداگانه و جدید تولید می شود. در مقابل ، یک روند بحث و گفتگو ممکن است برای چند روز یا چند هفته مورد توجه و بروز رسانی قرار بگیرد ، یا ممکن است برای سالها ادامه یابد. به طور خاص ، دستیابی و نگهداری از محتوای رسانه های اجتماعی باید بصورت بلادرنگ و ثابت باشد ، زیرا در صورت تحریک بحث و گفتگو یا آشکار کردن موارد حساس اطلاعاتی که می توانند مورد توجه ویژه قرار بگیرند ، ممکن است در یک بازه زمانی کوتاه محتوای تأثیرگذاری برای جامعه اطلاعاتی ارسال و حذف شود. سرانجام ، محتوای رسانه های اجتماعی با فرم طولانی و کوتاه به طور فزاینده در قالب هایی غیر از متن ارائه می شود. فیلم های YouTube نمونه ای از محتوای رسانه های اجتماعی طولانی با فرمت متفاوت است و داده های رسانه های اجتماعی با فرم کوتاه در قالب nontext شامل تصاویر بر روی پلتفورمهایی مانند Flickr و فیلم های “زنده” در پلتفورمهایی مانند Facebook و Twitter عرضه می شوند.
پردازش کردن مرحله دوم:
پردازش شامل اعتبارسنجی اطلاعات وقابل استفاده کردن آن می باشد. پردازش می تواند اشکال مختلفی داشته باشد ، از جمله ترجمه مطالب منبع از زبان اصلی آنها به انگلیسی و یاتبدیل فیلم یا عکس جهت استفاده اطلاعاتی. پردازش در نسل دوم OSINT یک دریایی ازتغییرات را در مقایسه با پردازش در OSINT نسل اول ، هم در تغییر روشهای موجود و هم در الزامات روشهای جدید ارائه می دهد. بسیاری از وظایف انجام شده در پردازش ممکن است با استفاده از برنامه های نرم افزاری ، از جمله نسخه های حرفه ای Google Translate ، با سرعت بیشتری و با هزینه کمتری انجام شوند. در عین حال، اکنون OSINT تعداد زیادی از اطلاعات موجود را با فرمت کم ساختار در اختیار دارد ، که باعث می شود پردازش بسیار بیشتر کارایی داشته باشد. ما دو مؤلفه پردازش را شناسایی می کنیم: ترجمه و تجمیع. این مؤلفه ها لزوماً در یک دنباله مشخص اتفاق نمی افتند ، اگرچه در موارد خاص یکی می تواند به دیگری کمک کند. پردازش داده های رسانه های خبری در درجه اول مستلزم ترجمه به انگلیسی است. هنگامی که بخش عمده ای از تلاش FBI ، ترجمه را تحت تأثیر قرار داده
است پیشرفت سریع ماشین ترجمه ، حداقل برای زبان هایی که در آنها نحو و جنس مشترک است مستند شده است. در حالی که زبان شناسان OSC هنوز نقش اساسی دارند (OSC=OPEN SOURCE CONTROL)
دانشمندان دیتا درجامعه اطلاعاتی
افزایش روز افزون داده های منبع آزاد و نیاز به مهارت های کمی _تحلیلی در پردازش و بهره برداری از داده های رسانه های اجتماعی، بحثی را در مورد نیاز دانشمندان حرفه ای داده ها در IC ایجاد کرده است. به عنوان مثال ، DIA(آژانس اطلاعات دفاعی) در سال 2013 ، تا حدودی برنامه ای را برای مدرن سازی تجزیه و تحلیل اطلاعات دفاعی با افزایش ظرفیت آن برای تجزیه و تحلیل داده ها ، آغاز کرد و قابلیت ونحوه ی ایجاد علوم دیتا را مورد بررسی قرار داد. یک مطالعه RAND (دسترسی سریع به کشف منابع)به سفارش DIA تعیین نقش ها ، مسئولیت ها و وظایف مربوط به علوم داده در آژانس اطلاعات دفاعی ، توصیه هایی را برای ساختن این نیروی کار علمی دیتا،ارائه داد. نیاز دانشمندان داده منحصرا، فقط برای متخصصان منابع باز نیست. این حالت عموماً نشان دهنده ی طیف گسترده و متنوع حسگرها و سهولت فنی در گرفتن و ذخیره ی داده های بزرگ است. با این وجود ، ورود تعداد بیشتری از دانشمندان داده در دستگاه اطلاعاتی ، می تواند تأثیر مثبتی بر توانایی های جامعه اطلاعاتی برای انجام پردازش پیشرفته و بهره برداری از داده های منبع آزاد داشته باشد.
استثمار (بهره برداری)
بهرهبرداری به دنبال تعیین این است که آیا اطلاعات آن چیزی است که ادعا میکند و اینکه چه ارزشی برای ic دارد. بهرهبرداری نیز گاهی به نام تحلیل گفته میشود. یکی از مهمترین چالشهای مرتبط با استفاده از این محصولات, حجم خالص اطلاعاتی است که در دسترس عموم قرار می گیرد و درجه اطمینان ذاتی آن اطلاعات است.
بنابراین, زمان زیادی برای تجزیه و تحلیل دادهها باید صرف جداسازی اطلاعات ” خوب ” از ” بد ” شود. تحلیلگران پیشرو باید قادر به ” جمعآوری, قضاوت و مرتبسازی اطلاعات, شناخت و کنترل محدودیتها و درک کاربران مختلف, نیازها, وظایف, ترکیب اطلاعات, سازمان, موسسات و قانون باشند.
محصول نهایی باید بتواند نتیجهگیریهای تحلیلی توسط منابع موجود را ارایه دهد.
ما بهره برداری را به سه مرحله تقسیم می کنیم: تأیید اعتبار ، ارزیابی اعتبار و استعاره کردن. تأیید هویت به دنبال تأیید این است که آیا اطلاعات همان چیزی است که می گویند آن است. برای اطلاعاتی که از منابع نهادی حاصل می شود ، این موضوع کاملاً واضح است. در مقالاتی در مورد نیویورک تایمز احتمال بسیار زیادی از انتشار آگاهانه و هدفمند توسط نیویورک تایمز وجود دارد.به همین ترتیب ، ادبیات خاکستری منتشر شده توسط وب سایت های دولتی را می توان با اطمینان بالا فرض کرد که توسط دولت تولید و منتشر شده است. احراز هویت محتوای رسانه های اجتماعی بسیار مشکل تر است. ممکن است کاربران به طور عامدانه هویت واقعی خود را زیر پا بگذارند ، یا ممکن است اطلاعات غلطی را در مورد دندانپزشکی خود ارائه دهند. این فراتر از نام واقعی کاربر است. به عنوان مثال ، یک شخص می تواند نسبت به موقعیت مکانی خود یا خصوصیات شخصی اطلاعات غلط بدهد. اگر IC در تلاش است تا جوی را در داخل یک کشور مشخص کند ، بسیار مهم است که کاربران به جای اعضای یک دیپلماسی در آن کشور باشند. احراز هویت ممکن است نیاز داشته باشد همزمان با توابع تجمیع داده ها اتفاق بیفتد تا اطمینان حاصل شود که یک نمونه داده یا کامپوزیت به اشتباه کاسته نشده است.ارزیابی اعتبار ، مانند تأیید اعتبار ، برای محتوای رسانه های سنتی و ادبیات خاکستری بسیار ساده است ، اما برای محتوای رسانه های اجتماعی بسیار دشوار است. یک اعتبار سنجی می کوشد تا تعیین کند که آیا این اطلاعات قابل اعتماد هستند یا خیر ، این که آیا بدون قصد انکار یا فریب تهیه شده است و آیا منبع آن دسترسی موجه به آن داشته است یا خیر. به عنوان مثال ، نیویورک تایمز ، تقریباً به صورت جهانی مطالبی را با هدف منتشر می کند – قصد دارد محتوای آن دقیق باشد و در مورد منابع آن شفاف باشد. این ممکن است برای منابع رسانه های خارجی به ویژه رسانه های دولتی که قصد نفوذ و یا پیام رسانی به جمعیت آنها را دارند ، کمتر صادق باشد. با این وجود ، احتمالاً تاریخچه مطالبی از این منابع وجود دارد که می تواند برخی از نشانه های مربوط به اعتبار اطلاعات آنها را ارائه دهد.رباتها نمونه هایی از داده های رسانه های اجتماعی هستند که برای جلوگیری از شناخت اهداف اصلی منبع مهم بوده اند. حتی اگر یک منبع اطلاعاتی را درمورد رویدادی که شاهد آن بوده است ، ارائه دهد ، آیا ما به این حساب اعتماد داریم ، با توجه به اینکه ممکن است درباره میزان مواجهه ، سوگیری و تخصص منبع کمی بدانیم؟ این بدان معنا نیست که مردم همیشه به عمد واقعیتها را نادرست نشان می دهند. یک مثال برجسته ، دوربین های بدنه پلیس است که به اعتقاد برخی ، برخوردهای پلیس روشن است ، اما تفسیر آن دشوار است ، و تفسیر می تواند تحت تعصب شناختی باشد. لزوماً اطلاعات سانسور شده منبع را درک نمی کنید. به عنوان مثال ، برخی از افراد هرگز نمی توانند که از فرزندان خود به صورت آنلاین نام ببرند یا نشان دهند. دیگران هرگز درباره کار خود به صورت آنلاین بحث نمی کنند.
زمینه سازی به تحلیلگر منبع باز اجازه می دهد تا تخصص موضوع را به نتیجه نهایی منتقل کند. این ممکن است شامل نظرات در مورد منبع منبع اطلاعات اضافی مانند اطلاعات مربوط به اعتبار باشد. متن سازی نیز می تواند شامل جمع آوری چندین مورد از OSIF از هر محصول قابل تحویل به محصولی باشد که تصویری جامع تر از یک موضوع ارائه می دهد.
تولید
در مرحله آخر ، تولید ، اطلاعات به شکلی قابل استفاده به مصرف کننده منتقل می شود.
این مصرف کننده غالباً یک تحلیلگر اطلاعاتی تمام عیار خواهد بود که می تواند آن را در تولید چند هوش بگذارد. با این حال ، یک محصول منبع باز نیز ممکن است دارای اولویت بالایی باشد یا کاملاً کامل باشد که مستقیماً به یک سیاستگذار یا مشتری دیگر اطلاعاتی ارائه شود. این مشابه سایر رشته های اطلاعاتی است ، جایی که معمولاً هوش انسانی ، سیگنال ها یا اطلاعات جغرافیایی در یک محصول تحلیلی همه منبع قرار می گیرند اما در بعضی مواقع به صورت خام آن به طور مستقیم به مشتری اطلاعاتی ارائه می شود.
زمینه سازی به تحلیلگر منبع باز اجازه می دهد تا تخصص موضوع را به نتیجه نهایی منتقل کند. این ممکن است شامل نظرات در مورد منبع منبع اطلاعات اضافی مانند اطلاعات مربوط به اعتبار باشد. متن سازی نیز می تواند شامل جمع آوری چندین مورد از OSIF از هر محصول قابل تحویل به محصولی باشد که تصویری جامع تر از یک موضوع ارائه می دهد.
فصل سه
ابزارها و روشهای OSINT
چالش های استفاده از ابزار قفسه تجاری
IC معمولاً از ابزارهای تجاری غیر قفسه (COTS) برای تجزیه و تحلیل OSINT ، به ویژه تجزیه و تحلیل داده های رسانه های اجتماعی استفاده می کند. این فصل بیشتر درخصوص ابزارهای تحلیل رسانههای اجتماعی موجود متمرکز است. در هنگام استفاده از این ابزارها برای اهداف متخصصان اطلاعات ، باید چندین نکته مهم را در خاطر داشته باشید. مهمتر از همه ، مهمترین ابزار COTS برای اهداف تجاری – برای تبلیغات ، مدیریت برند و تجزیه و تحلیل مصرف کننده است.
شرکت ها می خواهند رفتار خرید مشتری را درک و پیش بینی کنند ، تا موقعیت را در دسترس قرار دهند تا در صورت وجود حساسیت زیاد در مشتری ، در نظر مشتری درباره محصول یا خود شرکت تأثیر بگذارد. این ابزارها غالباً می توانند در خدمت منافع IC باشند ، اما به ندرت مطابقت کاملی دارند و بسیاری از ابزارها برای IC بسیار مفید هستند زیرا برای اهداف آن طراحی نشده اند.
دوم ، بازار در حال توسعه این ابزارها به قدری پویا است که مشکلاتی را برای IC ایجاد می کند. هر دو ابزار COTS و تولیدکنندگان در حال توسعه آنها به طور مداوم در حال تغییر هستند. این مشکل از چند طریق بروز می یابد.
به دلایل گوناگون ، فیدهای داده توسط شرکت صاحب محتوا محدود یا حذف می شوند. ممکن است شرکت ها بخواهند از داده های کاربر محافظت کنند ، یا برعکس ، آنها ممکن است فروش داده های کاربر را که قبلاً به صورت رایگان در دسترس بوده اند ، آغاز کنند.شرکتها ممکن است توانایی لازم را بدست آورند یا یک ویژگی بومی را برای تجزیه و تحلیل محتوای رسانه های اجتماعی ایجاد کرده اند و ممکن است بخواهند با از بین بردن منبع داده خود ، قابلیت های رقابتی را تضعیف کنند.به عنوان مثال ، تاپسی یک سرویس تحلیلی در رسانه های اجتماعی بود که همه توییت های توییتر منتشر شده را فهرست بندی کرده و عملکردهای جستجوی رایگان را ارپس از هشت سال ، این سرویس به طور غیر منتظره در 15 دسامبر 2015 ، دو سال پس از دستیابی توسط اپل ، به صورت آفلاین رفت. این مورد برای خدمات تحلیلی و عملیات IC که در مراحل اولیه دستیابی به داده ها و چرخه تحلیلی به سایر خدمات متکی هستند ، نشانگر است.
اپل و تاپسی اطلاعات کمی را در زمان کسب اطلاعات در مورد این که آیا این منبع اطلاعات همچنان در دسترس خواهد بود ، ارائه می دهند ، و همچنین هشدارهایی را ارائه نداده اند قبل از اینکه پلت فرم تاپسی در نهایت آفلاین شود. IC عادت کرده است دسترسی های داده به طور غیر منتظره ای در دسترس نباشد.
گردآورندگان SIGINT به دلایل مختلفی از جمله تنظیم مجدد سیستم و رمزگذاری جدید ممکن است دسترسی را از دست دهند. گردآورندگان HUMINT با احتمال منبع در معرض خطر بودن یا از دست دادن دسترسی به منابع یا برنامه های حساس گنجانیده می شوند. نقص ماهواره می تواند هنگام تنظیم تعمیرات ، جمع کننده های IMINT را در تاریکی قرار دهد.
مصرف کنندگان اطلاعات ممکن است با از دست دادن یک جریان اطلاعات جمع آوری شده با روش های پنهانی ناامید شوند ، اما از دست دادن می تواند به عنوان یک نتیجه اجتناب ناپذیر از روش های پنهان توضیح داده شود – منبع داده دیگر برای تجزیه و تحلیل در دسترس نیست. یکی از مزایای OSINT این است که قابل اعتماد تر از روش های جمع آوری پنهان است.
از دست رفتن ناگهانی یک منبع داده منبع باز – هنگامی که داده های خام هنوز در دسترس هستند – ممکن است به ناعادلانه تعبیر شود که منعکس کننده منفی در OSINT توسط مصرف کنندگان اطلاعات است که ممکن است نه از روند تبدیل داده های خام به اطلاعات آگاه باشند و نه علاقه مند به دریافت اطلاعات باشند.
وقتی توییتر هنوز آنلاین است و مردم هنوز توییت می کنند ، توضیح دادن برای یک مصرف کننده اطلاعات سخت تر است که چرا یک محصول OSINT به طور ناگهانی دیگر در دسترس نیست.
ماهیت پویا در بازار تجزیه و تحلیل رسانه های اجتماعی با برنامه زمانی IC در بررسی ابزارها و ارائه دهندگان مغایر نیست. شکل 3.1 گزینه های احتمالی موجود در IC برای استفاده از ابزارهای COTS را نشان می دهد. در حالت ایده آل ، IC می تواند هم یک منبع داده و هم یک بستر تحلیلی را به سیستم طبقه بندی شده خود منتقل کند. از طرفی ، آی سی پیش از معرفی آن به سیستم طبقه بندی شده ، می خواهد یک نهاد و بستر آن را کاملاً درک کند. با تکیه بر ابزارهای COTS ، IC به دلیل زمان لازم برای تکمیل این بررسی ، همیشه در زمینه تجزیه و تحلیل رسانه های اجتماعی پشت اقتصاد است.
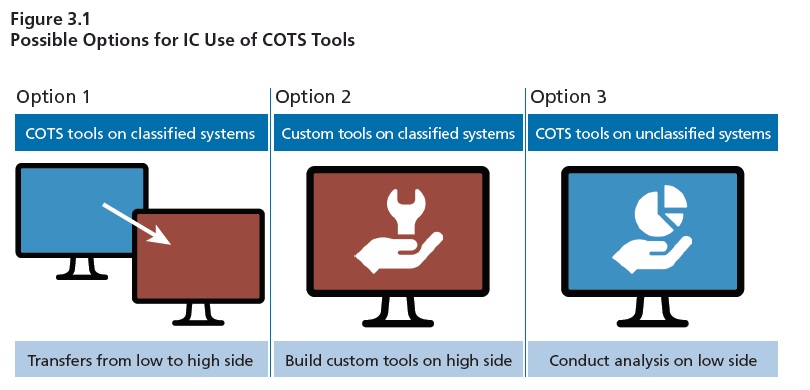
غالب شرکتهای نوپا در این فضا ، توانایی IC را در ایجاد یک رابطه مطمئن با ارائه دهندگان مستقر ، برای ساده تر کردن روند بررسی ، کمتر می کنند. البته آی سی می تواند ابزار بومی را توسعه دهد ، اما این یک جایگزین پرهزینه است. همچنین می تواند از یک ابزار روی یک سیستم غیر طبقه بندی شده بهره ببرد و از عوارض جمع آوری آن با قابلیت ها و اطلاعات حساس تر در شبکه های طبقه بندی شده جلوگیری کند. تجزیه و تحلیل رسانه های اجتماعی همچنین به دلیل پیشرفت های سریع در توان محاسباتی و قابلیت پردازش داده ها ، یک بازار پویا است. ابزارها در پردازش مقادیر زیادی از داده ها توانایی بیشتری پیدا می کنند ، و یادگیری ماشین گام های چشمگیر می گذارد.
به جای اینکه انسان ها به کامپیوترها نحوه انجام کارهای پیچیده را آموزش دهند ، سیستم هایی ساخته می شوند که کامپیوترها را قادر می سازند که خودشان این وظایف پیچیده را انجام دهند.اگرچه ابزارهای جمع آوری OSINT تقریباً روزانه در حال تحول هستند ، اما روشهای مورد استفاده توسط خود ابزارها بطور چشمگیری تغییر می کنند. اکثر ابزارها برای جداسازی ، توصیف و تحلیل داده ها از تجزیه و تحلیل واژگانی ، تجزیه و تحلیل شبکه ، تجزیه و تحلیل موقعیت مکانی یا ترکیبی از این روشها استفاده می کنند. هر سه روش مدت ها قبل از استفاده از آنها بر محتوا مبتنی بر اینترنت وجود داشته است ، اما گسترش گسترده سیستم عامل های رسانه های اجتماعی و سهولت روزافزون دسترسی افراد به اینترنت ، آن محیط را برای جمع آوری اطلاعات غنی می کند. علاوه بر این ، دقیقاً همزمان با انتقال از وب 1.0 به وب 2.0 ، میزان داده های ایجاد شده توسط کاربر برای تجزیه و تحلیل ویژگی های خاص ، به صورت تصاعدی افزایش یافته است ، انتقال به وب 3.0 (جایی که یادگیری ماشین و پردازش زبان طبیعی حاکم است) در حال حاضر است. تغییر کارآیی این روش ها برای مرتب سازی ، ترجمه و تجزیه و تحلیل داده ها برای اهداف اطلاعاتی است.تمایز میان ابزارهای تحلیلی منبع باز در دسترس گسترش می تواند به دلیل فراوانی و توصیفات ضعیف آنها دشوار باشد. با این وجود ، شناسایی مؤلفه های خاص روشهایی که از آنها استفاده می شود ، گزارشی را برای ارزیابی و مقایسه قابلیتها ارائه می دهد. ابزارها را می توان از نظر کمیت روشهای تحلیلی که می توانند بکار گیرند و سرعت ، دقت و ظرفیت آنها برای انجام تجزیه و تحلیلها مقایسه کرد.
تحلیل واژگانی یکی از قدرتمندترین کاربردهای ابزارهای منبع باز در عصر رسانه های اجتماعی ، امکان جمع آوری همزمان اجسام بزرگ متن از سراسر جهان در هر زمان معین از روز از منابع مختلف در سراسر مجموعه ای از زبان ها ، فرهنگ ها و ملیت ها است.تجزیه و تحلیل واژگانی می تواند در ابتدایی ترین سطح خود ، بیشترین جستجوی اصطلاحات جستجو را در Google در هر روز معین نشان دهد یا نشان دهد که کلمات کلیدی اغلب ظاهر می شوند. در سطح بالاتر ، تجزیه و تحلیل واژگانی می تواند معنای پشت زبان را تجزیه کند و اطلاعات مربوط به افرادی را که در رسانه های اجتماعی مشغول به فعالیت هستند از جمله خصوصیات جمعیت شناختی مانند سن ، طبقه اجتماعی ، سوابق اقتصادی و سطح تحصیلات نتیجه بگیرد.علاوه بر قابلیت های تحلیلی ، روش های پیشرفته تحلیلی واژگانی غالباً وابسته به داشتن یک پایگاه پایه برای مرجع هستند. با این کار ، در این زمینه ، منظور ما فقط یک مجموعه بزرگ از متن نیست بلکه یک متن جامع از متن است که پایه و اساس تحلیل توصیفی یک زبان را فراهم می کند. در حالی که شرکتهای تثبیت شده ای برای برخی از زبانها ، از جمله انگلیسی ، ماندارین و روسی وجود دارد ، بسیاری از زبانها فاقد شرکتهای مستقر هستند ، و برخی از ابزارهای تحلیلی واژگانی تا زمان ایجاد چنین شرکتها قابل استفاده نیستند. یادگیری ماشینی ، که بعدا در این فصل با جزئیات بیشتر مورد بحث قرار می گیرد ، در حال حاضر به غلبه بر برخی از نقص های زبان در تحلیل واژگانی کمک می کند و با گذشت زمان به پیشرفت خود ادامه می دهد.اگرچه ابزارهای جمع آوری OSINT تقریباً روزانه در حال تحول هستند ، اما روشهای مورد استفاده توسط خود ابزارها بطور چشمگیری تغییر می کنند. اکثر ابزارها برای جداسازی ، توصیف و تحلیل داده ها از تجزیه و تحلیل واژگانی ، تجزیه و تحلیل شبکه ، تجزیه و تحلیل موقعیت مکانی یا ترکیبی از این روشها استفاده می کنند. هر سه روش مدت ها قبل از استفاده از آنها بر محتوا مبتنی بر اینترنت وجود داشته است ، اما گسترش گسترده سیستم عامل های رسانه های اجتماعی و سهولت روزافزون دسترسی افراد به اینترنت ، آن محیط را برای جمع آوری اطلاعات غنی می کند. علاوه بر این ، دقیقاً همزمان با انتقال از وب 1.0 به وب 2.0 ، میزان داده های ایجاد شده توسط کاربر برای تجزیه و تحلیل ویژگی های خاص ، به صورت تصاعدی افزایش یافته است ، انتقال به وب 3.0 (جایی که یادگیری ماشین و پردازش زبان طبیعی حاکم است) در حال حاضر است. تغییر کارآیی این روش ها برای مرتب سازی ، ترجمه و تجزیه و تحلیل داده ها برای اهداف اطلاعاتی است.تمایز میان ابزارهای تحلیلی منبع باز در دسترس گسترش می تواند به دلیل فراوانی و توصیفات ضعیف آنها دشوار باشد. با این وجود ، شناسایی مؤلفه های خاص روشهایی که از آنها استفاده می شود ، گزارشی را برای ارزیابی و مقایسه قابلیتها ارائه می دهد. ابزارها را می توان از نظر کمیت روشهای تحلیلی که می توانند بکار گیرند و سرعت ، دقت و ظرفیت آنها برای انجام تجزیه و تحلیلها مقایسه کرد.
تحلیل واژگانی
یکی از قدرتمندترین کاربردهای ابزارهای منبع باز در عصر رسانه های اجتماعی ، امکان جمع آوری همزمان اجسام بزرگ متن از سراسر جهان در هر زمان معین از روز از منابع مختلف در سراسر مجموعه ای از زبان ها ، فرهنگ ها و ملیت ها است.تجزیه و تحلیل واژگانی می تواند در ابتدایی ترین سطح خود ، بیشترین جستجوی اصطلاحات جستجو را در Google در هر روز معین نشان دهد یا نشان دهد که کلمات کلیدی اغلب ظاهر می شوند. در سطح بالاتر ، تجزیه و تحلیل واژگانی می تواند معنای پشت زبان را تجزیه کند و اطلاعات مربوط به افرادی را که در رسانه های اجتماعی مشغول به فعالیت هستند از جمله خصوصیات جمعیت شناختی مانند سن ، طبقه اجتماعی ، سوابق اقتصادی و سطح تحصیلات نتیجه بگیرد.علاوه بر قابلیت های تحلیلی ، روش های پیشرفته تحلیلی واژگانی غالباً وابسته به داشتن یک پایگاه پایه برای مرجع هستند. با این کار ، در این زمینه ، منظور ما فقط یک مجموعه بزرگ از متن نیست بلکه یک متن جامع از متن است که پایه و اساس تحلیل توصیفی یک زبان را فراهم می کند. در حالی که شرکتهای تثبیت شده ای برای برخی از زبانها ، از جمله انگلیسی ، ماندارین و روسی وجود دارد ، بسیاری از زبانها فاقد شرکتهای مستقر هستند ، و برخی از ابزارهای تحلیلی واژگانی تا زمان ایجاد چنین شرکتها قابل استفاده نیستند. یادگیری ماشینی ، که بعدا در این فصل با جزئیات بیشتر مورد بحث قرار می گیرد ، در حال حاضر به غلبه بر برخی از نقص های زبان در تحلیل واژگانی کمک می کند و با گذشت زمان به پیشرفت خود ادامه می دهد.
پردازش زبان طبیعی
نسل های قبلی محققان و تحلیلگران اطلاعاتی باید به مترجمان و مترجمان انسانی برای پردازش اجسام بزرگ متن به زبانهای دیگر تکیه می کردند. پیشرفت های فن آوری در تجزیه و تحلیل متن و پردازش زبان طبیعی این بار را به میزان قابل توجهی کاهش داده است ، و اکنون مجموعه ای از منابع برای ترجمه سریع و پردازش مواد خارجی زبان در دسترس است. برخی منابع مانند Google Translate رایگان و منبع آزاد هستند و از کاربران دعوت می كنند ترجمه های بهتری را برای متن تولید شده توسط ماشین ارائه دهند كه به نوبه خود الگوریتم ها را با گذشت زمان بهبود و مرتب می كند. کوهن و همکاران توجه داشته باشید که خدمات ترجمه خودکار به ندرت خوب به نظر می رسد که اگر یک متخصص انسانی محتوای یک وب سایت را ترجمه کرده است ، اما مزیت بزرگ با ترجمه خودکار بدیهی است سرعت با پردازش مقادیر زیادی از داده ها است. »سرعت یک مزیت بارز است. وقتی تحلیلگران اطلاعاتی در آینده تعیین می كنند كه چه میزان از تهدید شخصی كه در وب سایت افراطی قرار می گیرد ، در آینده نزدیک است.
فراگیری ماشین
تمام فرایندها و اصطلاحات تحلیل واژگانی که در بالا توضیح داده شده است ، از محاسبه کلید تا شناسایی کلکسیون ها تا ترجمه مطالب و ارائه تحلیل احساسات ، از طریق یادگیری ماشین کارآمدتر می شوند. یادگیری ماشینی فرآیند آموزش یک برنامه نرم افزاری برای تصمیم گیری مستقل از انسان است که پس از اولین تصمیم گیری مورد نظر برای اولین بار به طور گسترده برای این برنامه مدل سازی شده است. یادگیری ماشینی مستلزم این است که متخصصان در یادگیری ماشین و زبان شناسی محاسباتی در ابتدا پارامترها را طراحی کرده و به طور مناسب به کامپیوتر “آموزش” دهند که چگونه الگوهای مربوط به زبانی را در متن نوشتاری بشناسد.
استفاده از ابزارهای تحلیل واژگانی
با استفاده از ابزارهای گفته شده در بالا ، تجزیه و تحلیل واژگانی می تواند تصاویر غنی از نویسندگان ، و همچنین زمینه بزرگتر آنها – اجتماعاتی را که با آنها مشخص می شود ، افراد یا اجتماعاتی که قصد دارند با کلمات خود به آنها برسند و تغییر مکان های احتمالی در ایدئولوژی یا دیدگاه ها را در طول زمان بکشاند. تجزیه و تحلیل واژگانی به طور فزاینده ای شامل جمع آوری شرکت ها از طریق اینترنت است ، جایی که افراد به اشتراک می گذارند ، پست می کنند ، توییت می کنند و به تعداد بیشماری از روش های دیگر هر روز نظرات خود را ابراز می کنند و افکار خود را به اشتراک می گذارند. استفاده از این روش و کاربرد آن در جمع آوری اطلاعات تقریبا مطمئناً گسترش خواهد یافت زیرا ابزارهایی مانند پردازش زبان طبیعی و یادگیری ماشین برای احساسات و تحلیل موضع همچنان در حال پیشرفت هستند.
تحلیل شبکه های اجتماعی
ده ها سال قبل از ظهور جدیدترین نسل برنامه های مبتنی بر وب ، تجزیه و تحلیل شبکه های اجتماعی سعی در توضیح روابط بین افراد به عنوان یک سری مبادلات داشت که می توان برای توضیح گذشته و پیش بینی تعاملات آینده نقشه و نقشه کشید.
اصول اساسی تحلیل شبکه های اجتماعی به شرح زیر است :
بازیگران به یکدیگر وابسته اند ، نه خودمختار.
پیوندهای ارتباطی بین بازیگران کانالهایی برای انتقال یا “جریان” منابع هستند
(یا مادی یا غیر مادی)
مدل های شبکه ، محیط ساختاری را فرصتی برای محدودیت در عملکرد فرد می دانند.
مدل های شبکه ساختار (اجتماعی ، اقتصادی ، سیاسی و …) را به عنوان الگوهای ماندگار روابط بین بازیگران مفهوم سازی می کنند.
در حالی که تجزیه و تحلیل شبکه های اجتماعی ارتباطات بین افراد را بررسی می کند ، هدف این نیست که افراد را توضیح دهیم بلکه باید شبکه بزرگتر بازیگران متصل را درک کنیم. بنابراین واحد آزمون بزرگتر است (دو بازیگر و رابطه آنها) ، سه گانه (سه بازیگر) ، زیر گروه های بزرگتر افراد یا کل سیستم ها .تجزیه و تحلیل شبکه های اجتماعی در عصر اینترنت ، در نمونههای تعامل شبکه ای ، نمایی از داده های جدید ایجاد کرده است ، در حالی که ابزارهای جدید رسانه های اجتماعی دید بیشتری به شبکه ها می دهند.
عناصر اساسی تجزیه و تحلیل شبکه های اجتماعی در شکل 3.2 ارائه شده است.هر واحد در یک شبکه اجتماعی به عنوان یک گره توصیف می شود. گره ها می توانند افراد خارج از شبکه یا داخل باشند ، اما تجزیه و تحلیل شبکه های اجتماعی در درجه اول روی گره هایی متمرکز است که جزئی از گروه های بزرگتر هستند.
dyad دو گره است که با یکدیگر در تعامل هستند ، همانطور که توسط خط اتصال A به B نشان داده شده است.
یک سه گانه به طور مشابه تعامل بین سه گره A ، B و C است.
از میان این بلوک های ساختمان اصلی ، شبکه های بزرگتر تشکیل می شوند که می توانند راه های تعامل گره ها با یکدیگر را توصیف کنند
کدام گره ها کنترل یا قدرت بیشتری دارند ، 19 استنلی واسرمن و کاترین فاوست،
تجزیه و تحلیل شبکه های اجتماعی: روش ها و کاربردها (تجزیه و تحلیل ساختاری در علوم اجتماعی)،
کمبریج ، انگلیس: انتشارات دانشگاه کمبریج ، 1994.
هانمن و مارک ریدل ، مقدمه ای بر روش های شبکه های اجتماعی ، ریورساید ، کالیفرنیا: دانشگاه کالیفرنیا ، ریورساید ، 2005.
تعریف هوش منبع باز نسل دوم (OSINT) برای شرکت دفاعی و چگونگی پیوند گره ها از طریق اتصالات مشترک به یکدیگر.
شبکه ستاره ، شبکه خط و شبکه دایره ای روش هایی برای تجسم انواع متقابل هستند که با نمونه های زیر توضیح داده شده است.
درجه:
درجه تعداد اتصالات یک گره است. هرچه درجه بزرگتر باشد ، گره ارتباط بیشتری خواهد داشت.
در شکل 3.2 درجه با موقعیت گره G در شبکه ستاره نشان داده شده است: G دارای درجه شش است ، در حالی که تمام گره های دیگر دارای درجه یک هستند ، بدین معنی که G فرصت های بیشتری برای دسترسی به اطلاعات یا توانایی نفوذ بیشتر از همه دارد.
تراکم
تعداد محدودی از خط در هر نمودار وجود دارد و تعداد گره های حداکثر را تعیین می کند.
تراکم عبارت است از نسبت خطوطی که در واقع در نمودار به حداکثر نظری ممکن وجود دارد.
در شکل 3.2 ، شبکه دایره دارای چگالی کم است ، بدین معنی که تعداد گره های کم بین گره ها نسبت به عددی که می تواند وجود داشته باشد (به عنوان مثال ، A و F می توانند به هم وصل شوند ، می توان I و C به هم متصل شدند).
هر چه این نسبت بیشتر باشد ، تعامل بیشتر در یک گروه اتفاق می افتد ، که می تواند به عنوان انسجام اندازه گیری شود. در گروههای بزرگتر از دو نفر ، این نشانگر “میزان تعامل اعضای شبکه با یکدیگر را دارند.”
شکل 3.2
نمودارهای تحلیل شبکه های اجتماعی 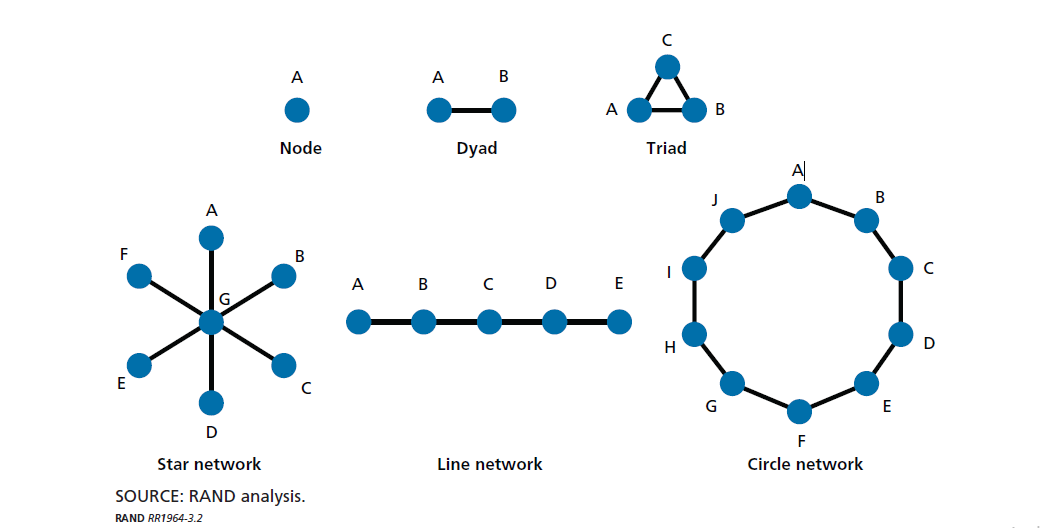
.
بین:
بین بودن نشانه ای از درجه کنترل یک نقطه (یا گره) فرد بر ارتباطات است.
در شبکه خط در شکل 3.2 ، B بین A و C است. بنابراین ، هر اطلاعاتی که A می خواهد به C منتقل شود باید از طریق B حرکت کند ، به این معنی که B می تواند پیامی را که C دریافت می کند کنترل کند ، آن پیام را تغییر دهد یا از رسیدن کامل آن به C جلوگیری کند. تجزیه و تحلیل شبکه های اجتماعی می تواند از معیارهای فاصله برای تعیین افراد به عنوان “تأثیرگذار” در یک شبکه معین استفاده کند ، و ببیند که چگونه زبان بازیگر در تغیی نقش مانند بازی تلفنی ، تغییر می کند.
یک یافته مهم برای IC این است که بین محققان این امکان را می دهد تا محققان بتوانند درباره آنچه تعداد کمی از گره های مهم در مورد بحث صحبت می کنند ، ایده خوبی بدست آورند ، حتی اگر خود کاربران نیز از حضور در رسانه های اجتماعی محافظت های امنیتی بالایی داشته باشند ، اگر محققان بدانند که چقدر کمتر بازیگران بحرانی به آن گره وصل می شوند.
به عبارت دیگر ، در بازی غول پیکر تلفنی ، می توان با تعیین آنچه مردم در هر دو طرف او گفتند ، آنچه را كه شخص در وسط گفته است ، برون داد.
بین مرکزیت
تمرکز بین فاصله ، مرکزیت بین راهی راهی برای تعیین چگونگی ارتباط غیرقابل ارتباط شبکه ها یا افراد با یکدیگر است که ارتباط بین آنها را امکان پذیر می سازد.
در جایی که دو شبکه مختلف باهم ارتباط برقرار می کنند – به عنوان مثال ، اگر شبکه ستاره و شبکه دایره ای دارای یک ارتباط مشترک باشند – اقدامات بین مرکزیت بودن نشان می دهد که چگونه این دو گروه در ارتباط هستند و اطلاعاتی درباره “ناهمگونی یا تغییرپذیری فاصله بین کل مجموعه بازیگران ارائه می دهند. “
نزدیک بودن
فاصله نشان می دهد چگونه افراد در یک گروه خاص می توانند پیام را کنترل کنند ، فاصله میزان ارتباط مستقل یا وابستگی هر یک از افراد از یک گروه از دیگران را اندازه گیری می کند و بنابراین انتقال پیام فرد به دیگران به فاصله آنان از هم بستگی دارد.
در شبکه خط در شکل 3.2 ، بازیگر C به سایر بازیگران این شبکه نزدیکتر است ، در حالی که بازیگران A و E از همه دورتر هستند.
اقدامات مرکزیت
اقدامات مرکزیت اهمیت گره فردی را در یک شبکه بزرگتر توصیف می کند.
افرادی که از مرکزیت بالایی برخوردارند ، معمولاً “درگیر روابط زیادی هستند ، فارغ از جهت گیری ارسال یا دریافت یا میزان فعالیت.
“در زمینه تعامل با توییتر ، یک کاربر با مرکزیت بالا ، غالباً توسط سایر کاربران ، بدون در نظر گرفتن اینکه کاربر مکالمه را شروع کرده است یا خیر ، ذکر می شود ، و همچنین به طور متناوب شروع به تعامل با افراد دیگر در شبکه های خود می کند.
جهت پذیری
با اندازه گیری “outdegree” (یعنی اطلاعات خارج از خانه) یا “indigree” (یعنی اطلاعات وارد شده) ، بازیگرانی که دارای ادعاهای بزرگتر هستند معتبرترین یا مهمترین یک شبکه هستند.
27 جهت گیری ، بر خلاف سایر اقدامات تعریف شده در اینجا ، می بیند که اطلاعات از کجا نشأت گرفته و از کدام جهت جریان می یابد.
به عنوان مثال ، در شبکه خط ، اهمیت یک گره به جهت جریان اطلاعات در آن بستگی دارد. اگر همه اطلاعات به سمت راست جریان داشته باشند ، گره E بیشترین عدم رضایت را خواهد داشت.
در زوج ها، جهت گیری می تواند نشان دهد که آیا هر دو عضو از تأثیر / قدرت مساوی در تعامل مشترک برخوردار هستند یا یک قدرت نابرابر پویا وجود دارد.
استفاده از ابزارهای تحلیل شبکه های اجتماعی احتمالاً برجسته ترین ابزار رسانه های اجتماعی است که توسط تحلیلگران شبکه های اجتماعی برای نشان دادن و بررسی اصول کلاسیک تحلیل شبکه استفاده می شود. توییتر به کاربران نام کاربری منحصر به فرد یا “دسته ها” را می دهد که سپس از آن دسته از دسته ها برای برقراری ارتباط مستقیم با سایر کاربران با پاسخ دادن به یک مکالمه در دسترس عموم یا شروع گفتگو با کاربر شناخته شده دیگر ، فرایندی به نام داشتن “ذکر” در موضوع گفتگو استفاده می کنند. . همه این تعامل ها عمومی هستند. این امر به ناظران این امکان را می دهد تا ببینند چه کسی با آنها تعامل دارد ، چه کسی به چه کسی متصل است – و از طریق چه کسی – و کیفیت و کمیت آن تعامل.
یک نمونه از چگونگی استفاده از تجزیه و تحلیل شبکه های اجتماعی در حال حاضر برای درک یک مسئله – و احتمالاً تأثیر آن بر تکامل آن – پیگیری ایدئولوژی خشونت آمیز افراطی گرایانه است.
تجزیه و تحلیل شبکه تحلیلگران را قادر می سازد تا ببینند که چگونه تأثیرگذارانی چون داعش از رسانه های اجتماعی برای تبلیغ زبان و ایدئولوژی استفاده می کنند ، همچنین برای شناسایی افرادی که ممکن است یک فیلم شخصی YouTube را تماشا کنند یا یک صدای جیر جیر از یک دنبال کننده بخوانند و شروع به درگیر شدن با ایده های ارائه شده کنند.
به عنوان مثال ، یک مطالعه RAND در سال 2016 از داده های رسانه های اجتماعی و تجزیه و تحلیل واژگانی برای مقایسه حامیان داعش با عوامل مخرب و تعیین الگوهای ارائه شده برای فرصت های تأثیرگذاری بر این جوامع استفاده کرد.
با دنبال کردن کلمات کلیدی یا “هشتگ” ، می توان پیشرفت یک کلمه کلیدی جدید را ردیابی کرد و سپس پخش آن را پخش کرد ، ابتدا بین کاربران جداگانه ، سپس به شبکه های بزرگتر ، و سپس در شبکه ها ، احتمالاً معنای جدید یا تعریف را با استفاده از هر سهم جدید
هنگامی که الگوهای ارتباطی و زبان مشترک جامعه متوجه شد ، ممکن است انجام کمپین های متقابل ارزیابی که از همان کلید واژه هایی استفاده می شود که از حساب های طرفدار داعش استفاده می کنند ، برای نشان دادن پیامدهای منفی درگیری با سازمان استفاده کند. در یک نشریه اخیر ، محققان RAND با استفاده از یک رویکرد از بالا به پایین در توییتر ، چندین فرصت را برای ارزیابی موثر داعش در خاورمیانه مورد بررسی قرار دادند.
آنالیز جغرافیایی
مانند تجزیه و تحلیل واژگانی و تجزیه و تحلیل شبکه ، تجزیه و تحلیل موقعیت مکانی اغلب در ترکیب با سایر روشها کار می کند تا تصویری غنی تر از پویایی های اجتماعی ، نظامی و سیاسی که برای جمع آوری اطلاعات مرتبط است ، تولید کند. تجزیه و تحلیل جغرافیایی با ایجاد سیستم عامل های جدید رسانه های اجتماعی که بطور خودکار می تواند یک پیام یا صدای جیر جیر را به یک مکان خاص از طریق آنچه به عنوان “جغرافیایی” شناخته می شود ، پیوند داده است.
جغرافیایی
Geotag ها داده های جاسازی شده ای هستند که طول و عرض جغرافیایی یک پست یا تصویر معین را نشان می دهد ، و دارای دقت و صحت بالاتری هستند. اکثر تلفن های هوشمند با استفاده از داده های مکانی داخلی سیستم موقعیت یابی جهانی (GPS) ، به طور خودکار geotags را برای پست ها تولید می کنند – به عنوان مثال ، روی تصاویر ارسال شده در اینستاگرام — و کاربران سایت ها ممکن است متوجه نشوند که باید این تنظیم پیش فرض را خاموش کنند تا فاش نشوند. محل آنها .
برخی از کاربران عمداً پست های خود را در توییتر ، فیس بوک ، اینستاگرام ، وبلاگ Tumblr و سایر سایت ها نشان می دهند تا حضور خود را در یک رویداد نشان دهند و یا به انتشار اطلاعات در زمان واقعی در یک رویداد آشکار کمک کنند.
Goodchild با اشاره به این نوع جمع آوری و انتشار مکان های محلی فعال به عنوان “جغرافیای داوطلب” ، اظهار داشت که هزینه پایین تلفن های هوشمند مجهز به GPS آستانه برای مشارکت فردی را کاهش داده است. جغرافیای داوطلبانه برای تولید اطلاعات درمورد وقایع در زمان واقعی و نشان دادن حرکت واقعی گروهی از افراد به یک مکان خاص مفید است ، به عنوان مثال حرکت ده ها هزار نفر از معترضین به میدان تحریر در قاهره مصر ، در طول اعتراضات سال 2011
معترضین همچنین فیلم ها و تصاویر برچسب گذاری شده در میدان تحریر را بارگذاری کردند ، که توسط منابع رسانه ای خارج از کشور جمع آوری شدند و از آنها برای گزارش در مورد تظاهرات های مداوم و پاسخ دولت مصر استفاده می کردند.
شکل 3.3 نقشه ای است که هنوز هم قاب هایی دارد که در آن تصاویر جغرافیایی و توییت هایی در اطراف میدان تحریر ارسال شده است. یک سری از تصاویر حرکت افراد به درون مرکز را از مناطق اطراف نشان می دهد ، به عنوان افرادی که در حالی که در حال انتقال به اعتراض یا اعتراض بودند به رسانه های اجتماعی ارسال می کردند. از این اطلاعات می توان برای نشان دادن الگوهای حرکتی و ردیابی مسیرهای مشترک ورود به اعتراضات ، حوادث یا تجمعات استفاده کرد.
توانایی داخلی بسیاری از برنامه های رسانه های اجتماعی برای “برچسب زدن” مکان ها همچنین اطلاعات زیادی را نشان داده است.
در سال 2015 ، یک مرد نیوزلند که برای جنگ با داعش به سوریه سفر کرده بود ، حساب های توئیتر خود را به حالت تعلیق درآورد وقتی که سهواً چندین توییت جغرافیایی را ارسال کرد که به اندازه کافی خاص بودند تا بتوانند مکان او را به خانه ای خاص در التقبه ، یک شهر سوریه ردیابی کنند. سپس ، دیگر مبارزان داعش در سوریه و عراق نیز به طور مشابه از طریق عکس های جغرافیایی که به طور غیر عمدی در اینستاگرام یا توییتر منتشر شده اند ، ردیابی شدند.
شکل 3.3
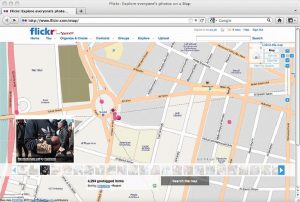
منبع: آنتونی استفانییدیس ، اندرو کروکس ، و ژاکک رادزیکوفسکی ، “برداشت محیط جغرافیایی
اطلاعات در مورد رسانه های اجتماعی ، “ژئوژورنال ، جلد. 78 ، 2013
جغرافیایی
با استفاده از برنامه های منبع باز مانند Google Earth و Google Maps ، تحلیلگران می توانند نشانه های مشخصی را پیدا کنند (به عنوان مثال یک کلیسا) و سپس از وب سایت هایی مانند Panoramio برای ترکیب نقشه ها با عکس هایی که در یک مکان خاص برچسب خورده اند استفاده کنند.
موقعیت جغرافیائی، استنتاج
جغرافیایی استنتاج موقعیت مکانی کاربر را بدون اطلاعات صریح جغرافیایی نشان می دهد.
استنتاج ژئو به روشهای گوناگونی قابل انجام است. برخی از وب سایت ها (به عنوان مثال ، Google و Craigslist) به منظور شخصی سازی تجربه کاربر ، موقعیت مکانی کاربر را ضبط می کنند ، که “محتوای حساس به مکان” را در حافظه مرورگر کاربر ایجاد می کند.
علاقه مندان می توانند با استفاده از “کانالهای جانبی” برای تعیین موقعیت مکانی کاربر ، به طور خاص تا سطح محله ، به جغرافیایی های باقی مانده در حافظه پنهان دسترسی پیدا کنند. 36 در سیستم عامل هایی مانند توییتر ، الگوریتم ها می توانند “اطلاعات مربوط به موقعیت مکانی محیط” را از محتوای وقتی توییت عناصر اختصاصی مکان مانند تیم های ورزشی یا دانشگاه ها را ارجاع می دهد ، توییت خود را نشان می دهد.
نسخه های فعلی این الگوریتم ها هنگامی که به داده های بیشتری از هر کاربر دسترسی پیدا می کنند ، بهبود می یابند و این سیستم را قادر می سازد تخمین خود را از موقعیت کاربر بر اساس استفاده از زبان “تغییر داده” کند. 38
چنگ ، کاورلی و لی یک سیستم الگوریتمی ایجاد کردند که کاربران را با 1000 یا بیشتر توییت بررسی کرده و 51 درصد از کاربران را در فاصله 100 مایل از محل واقعی خود قرار داده است ، نسبت آنها به طور چشمگیری بهبود می یابد زیرا آنها ابزار را با نمونه های داده بیشتر تصفیه می کنند.
جغرافیایی
Georeferencing یک جسم را با مکانهای موجود در فضای فیزیکی مرتبط می کند. این “معمولاً در قسمت سیستمهای اطلاعات جغرافیایی برای توصیف فرایند پیوند نقشه فیزیکی یا تصویر شطرنجی نقشه با مکانهای مکانی استفاده می شود.
وقتی نقشه ها دارای سیستم مختصات جغرافیایی صریح و مرتبط با مکان های نشان داده شده بر روی آنها نیستند ، مختصات مکانی را می توان به یک تصویر اختصاص داد.
این تصویر را می توان با داده های مدرن پوشانده ، که از آن می توان برای ایجاد نقشه های دقیق تر با داده های دانه ای در زیرساخت ها مانند جاده ها و ساختمان ها استفاده کرد. این نقشه ها بعداً می توانند برای اهداف تحقیقاتی یا در جوامع اطلاعاتی و نظامی برای هدف گیری مورد استفاده قرار گیرند.
استفاده از ابزارهای تحلیل موقعیت مکانی یكی از كاربردهای قدرتمند ابزارهای آنالیز جغرافیایی ، زمینه سازی اطلاعات در مورد یك عامل مشخص و تأثیرات آن بر زیرساخت ها و جمعیت در زمان واقعی است.
برنامه های نرم افزاری مانند سیستم اطلاعات جغرافیایی به کاربران این امکان را می دهد تا نقشه های در دسترس عمومی را که توسط پلتفرم Google پشتیبانی می شود بارگیری کنند و عوامل خاص مورد علاقه – مانند منابع آب ، مراکز جمعیت بیش از یا زیر تعداد معین ، و مخازن داده را وارد کنند – در عواملی مانند قومی. و ترکیب مذهبی در منطقه برای نشان دادن تعامل بین جغرافیا و دینداری در یک منطقه.تحلیلگرانی که می توانند مداخلات نظامی مداوم در یک منطقه را عملی کنند ، می توانند از ترکیبی از Google Maps ، Wikimapia ، توییتهای در دسترس عموم ، پست های فیس بوک و فیلم های YouTube استفاده کنند تا مکان دقیق اقدامات نظامی در حال انجام و عواقب مورد نظر و ناخواسته آنها را مشخص کنند.
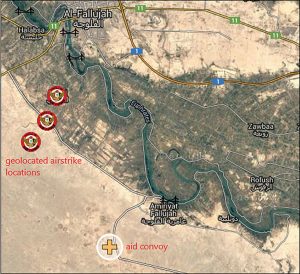
این نوع از تجزیه و تحلیل تقاطع در شکل 3.4 نشان داده شده است ، که نشان می دهد حمله هدفمندی به کاروان وسایل نقلیه ادعا شده داعش در نزدیکی فلوجه ، عراق است.
این تجزیه و تحلیل با اشاره به “جغرافیایی فیلم های منتشر شده توسط ائتلاف بین المللی و وزارت دفاع عراق ، بیانیه های رسمی و گزارش های رسانه ای جمع آوری شده است.
با قرار دادن کلیه اطلاعات موجود بر روی نقشه که می تواند به محض ورود اطلاعات جدید به روز و ویرایش شود ، تجزیه و تحلیل مکانی به ابزاری قدرتمند برای تجسم و تجزیه و تحلیل گزارش های اطلاعاتی تبدیل می شود.
جغرافیایی ، شبکه اجتماعی و تحلیل واژگانی ، هنگامی که با یک لیست فوق العاده از سیستم عامل های نرم افزاری خصوصی و عمومی جفت می شوند ، به طور فزاینده در ایجاد حس مشکلات بزرگ داده ها و جدا کردن سیگنال از سر و صدا کمک می کنند.
امکانات ارائه شده توسط یادگیری ماشین و پردازش زبان طبیعی برای مجموعه OSINT بسیار زیاد است.
در عین حال ، همچنان برای تحلیلگران اطلاعات بسیار مهم خواهد بود كه در تعیین چگونگی اتصال اطلاعات ارائه شده توسط این روشها به روشی كه قانع كننده و قابل اعتماد باشد ، ایفا كنند.
درک نوع داده های جمع آوری شده توسط هر روش همچنین به تحلیلگران اطلاعاتی نیاز دارد تا در خارج از حوزه های خود ، بویژه در زمینه های علوم رایانه ، از جمله کارشناسان شرکتهای فناوری و متخصصان زبانشناسی ، جامعه شناسی و سایر موارد با دانشمندان و متخصصین ارتباط برقرار کنند.
در حالی که یادگیری ماشین به طور فزاینده برخی از کارهای جمع آوری و پردازش وقت گیر را جایگزین می کند ، تحلیلگران ماهر هنوز هم برای ایجاد روایت های قانع کننده از داده هایشان لازم هستند.
فصل چهارم
نتیجه گیری
علیرغم اینكه می دانیم كه اطلاعات بیشتر و بیشتر در مورد ارزش اطلاعات در حوزه عمومی وجود دارد ، IC هنوز هم آهسته عمل كرده است تا به طور كامل پتانسیل نسل دوم OSINT را بپذیرد. انتقال در آژانسها آسانتر بوده است وقتی اطلاعات در حوزه عمومی بسیار شبیه به اطلاعاتی است که قبلاً صرفاً در حوزه طبقه بندی شده زندگی می کردند. به عنوان مثال ، تصاویر ماهواره ای تجاری ممکن است نتایج مشابه با نتایج حاصل از دارایی های طبقه بندی شده را تولید کند. آژانس ملی اطلاعات جغرافیایی و اطلاعاتی (NGA) در حال حاضر به لحاظ نرم افزاری و تخصص – برای یافتن
ارزش اطلاعاتی در این اطلاعات. NGA پتانسیل OSIF را پذیرفته است ، اما تنها در IC نیست. بسته به موضوع ، بسیاری از تحلیلگران منبع با OSINT و سپس لایه بر روی منبع طبقه بندی شده شروع می کنند.
رابرت کاردیلو ، مدیر NGA ، از معماری جدید و مشارکتهای بیشتر با صنعت حمایت کرده است . او می پذیرد که IC دیگر “رسانه ای” از تصاویر ماهواره ای نیست و این در یک محیط با سرعت در حال تغییر اطلاعات بسیار مهم است. پروژه NGA GEOINT Pathfinder محصولات اطلاعاتی را از منابع غیر طبقه بندی چابکی برای فعالیت شده و تصاویر ماهواره ای که از منابع تجاری خریداری شده اند ، ایجاد کرده است. کاردیلو معتقد است که دیگر نباید اطلاعات غیر طبقه بندی شده به عنوان مکمل منابع طبقه بندی شده تلقی شوند ، بلکه باید اینگونه باشد. این است که ، از منابع طبقه بندی شده می توان برای “تکمیل گسترده تر و گسترده تر” استفاده کرد
با این وجود ، دانش غنی تر طبقه بندی نشده ای از دانش وجود ندارد. تجزیه و تحلیل تصاویر همچنین نیاز به یک مجموعه مهارت دارد که از تجزیه و تحلیل متن یا رسانه های دیگر متمایز باشد ، و باعث می شود NGA بتواند از این استدلال که پردازش و بهره برداری از متن باز استفاده می کند دفاع کند.اطلاعات جغرافیایی باید در دامنه آن قرار گیرند.
دانستن اینکه چرا NGA راحت تر از سایر سازمان ها فلسفه منبع آزاد را پذیرفته است ، مستلزم بررسی فرضیات ما در مورد نحوه تعریف انواع هوش است. رشته های اطلاعاتی با توجه به منابع و روشهای به کار رفته در جمع آوری آنها و نه براساس نوع اطلاعات تعریف می شوند
بدست آمده با این روشها GEOINT اما ، در عمل ، به جای منابع و روشها براساس نوع اطلاعات تعریف می شود. به عنوان مثال ، اگر یک درایو سخت که شامل تصاویر ماهواره ای بود از طریق عملیاتی با قابلیت کمک به انسان DIA بازیابی می شد ، تقریباً داده ها به طور قطع برای پردازش و بهره برداری به NGA ارائه می شدند. اگر یک سرویس سایبری آژانس امنیت ملی (NSA) سرور رایانه را به خطر اندازد
تصاویر ماهواره ای مسکن ، نتیجه همان خواهد بود. منابع و روشهایی که ایالات متحده برای به دست آوردن اطلاعات تصویر بکار می برد غیرمادی است – این ویژگی اطلاعات (یعنی عکسبرداری ماهواره ای یا هوایی) و الزامات تبدیل آن به یک محصول اطلاعاتی است که نحوه تعریف آن را نشان می دهد. بنابراین ، هیچ تضادی اساسی در NGA برای به دست آوردن مواد از طریق معنی جدید (یعنی تجاری) وجود ندارد. این به سادگی به یک رهبری با ابتکار عمل و همه کاره برای پیگیری همان کاردستی با تنظیماتی در عملیات نیاز دارد. در مقابل ، همین مکالمه بین سران دولت می تواند از طریق HUMINT و SIGINT ضبط شود (به عنوان مثال ، از یک گزارش انسانی در مورد گفتگو و از دستگاه گوش دادن موجود در صحنه) ، اما نحوه دستیابی به اطلاعات می تواند چه سازمانی را مشخص کند. و چگونه طبقه بندی می شود. یک مقاله آنلاین در مورد مکالمه باعث می شود اطلاعات منبع آزاد باشد ، و از آنجا که مقامات جمع آوری منبع آزاد به طور گسترده بین IC توزیع می شوند ، هیچ یک از آژانس ها به وضوح مسئولیت ضبط و تجزیه و تحلیل داده های OSINT را ندارند.
علاوه بر این ، تلاش برای پوشاندن انواع جدیدی از اطلاعات موجود و قبلاً وجود نداشتن به همان تعریف های موجود در مورد منابع اطلاعاتی می تواند باعث ایجاد مشكلات شود. نه تنها برخی از اطلاعاتی که قبلاً فقط در کانالهای طبقه بندی شده وجود داشتند ، اما آشکارا در دسترس هستند ، بلکه تغییر مسیر ذهن برای تشخیص وجود منابع و روشهای اصلی و منحصر به فرد بسیار مهم است. بخش اعظم تولید محصولات اطلاعاتی تمام منبع بر تجزیه و تحلیل کیفی متمرکز شده است ، در جهانی که اطلاعات کمی به طور فزاینده ای در دسترس است. حتی برای کسانی که ممکن است OSINT نسل دوم را بعنوان مجبور به تغییر در نحوه عملکرد OSC ببینند ، تأثیر آن بر سازمانهای IC دیگر است.
نسبت به NGA تحول کمتری داشته است. سیا قبل از بهره برداری از عصر اطلاعات جدید ، دبیرخانه نوآوری دیجیتال ایجاد کرده است. چالشی پیش از این ریاست جدید ، چگونگی هم ترازی و ادغام قابلیت های آن در مراکز ماموریت خواهد بود.
مدیر پیشین DIA ، LtGen وینسنت استوارت همچنین یک مدافع قوی برای بهره برداری مؤثر از مجموعه منابع جدید داده ای است که در نتیجه انقلاب دیجیتال ظهور کرده اند. او در مورد چالش های اساسی پیش روی IC هشدار داده است اگر به دنبال راه های جدید برای مهار منابع جدید جدید اطلاعات نیست. در سخنرانی در کنفرانس GEOINT 2017 ، استوارت گفت: “معدن بیش از 15 نفر برای اولین بار در هر ثانیه از رسانه های اجتماعی استفاده می کنند. هفت نفر برای اولین بار در هر ثانیه از تلفن همراه استفاده می کنند. امروز یک میلیون نفر برای اولین بار از اینترنت استفاده خواهند کرد. “وی در ادامه با چالش شرکت کنندگان در کنفرانس گفت:” من شما را به چالش می کشم که خودکشی را رد کنید ، پرورش دهید
نوآوری ، و ایجاد محیطی برای فناوری که به IC اجازه می دهد تا تجزیه و تحلیل و تحویل اطلاعات به مشتری مورد نیاز برای مقابله با تغییرات قرن بیست و یکم را ایجاد کند. دانشمندان ، با شناخت واقعی این کادر در حال حاضر در بین نیروی کار آن وجود ندارد. دستورالعمل DoD 3115.12 شورای منبع باز دفاعی را تأسیس كرد و DIA را به عنوان “مكانیزم اصلی حكومت DoD OSINT” تعیین كرد. رئیس كرسی شورای منبع باز دفاعی یك مقام DIA است كه راهنمایی و پشتیبانی شورا را برای فعالیت های وزارت دفاع از فعالیت های DoD OSINT تعیین می كند.
سازمان ها در تلاش هستند تا چگونگی ترکیب و ادغام OSIF را کشف کنند. با این حال ، این ترفندها بیش از تحولات است. تجدید نظر در مورد چگونگی سازماندهی ایده آل امروز در رشته ها ، بدون در نظر گرفتن چارچوب سازمانی فعلی – حتی اگر تغییر شکل جامعه کاملاً منع باشد ، با توجه به فرهنگهای نهادی ، میراثها ، تحمل نیروی کار برای تغییر و ضروریات عملی – هنوز هم می تواند توصیه هایی برای ICروشنگری و جدید باشد
OSINT نسل دوم
از آنجا که IC همچنان به چگونگی مدیریت و بهره برداری کامل از نسل دوم OSINT می پردازد ، مفید است که درباره مکان بعدی وب و روندهایی که می تواند نسل سوم OSINT را تعریف کند ، فکر کنید. نسل دوم OSINT عمدتاً به دلیل تغییر وب 2.0 ایجاد شده است – تغییر در زمینه اینترنت به صفحات وب پویا و محتوای تولید شده توسط کاربر. با این حال ، بیش از یک دهه ، کارشناسان فن آوری در مورد تکامل به وب 3.0 صحبت کرده اند – “وب معنایی” که شامل پردازش مستقیم و غیرمستقیم دستگاه از داده ها ، یادگیری ماشین و استدلال خودکار می شود. در شکل 4.1 برخی از ویژگی های نسل OSINT و امکانات برای موج بعدی از چالش ها و تمرکز را نشان می دهد.
تعریف هویت منبع باز نسل دوم (OSINT) برای شرکت دفاعی
شکل 4.1
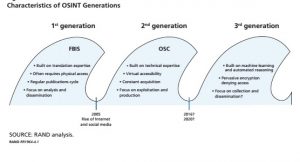
نسل اول FBIS
• ساخته شده در تخصص ترجمه
• اغلب به دسترسی فیزیکی نیاز دارد
• چرخه انتشار منظم
• بر تجزیه و تحلیل و توزیع اطلاعات متمرکز شوید
نسل دوم (2005)OSC
با شيوع اينترنت و شبکه هاي اجتماعي از سال 2005 به بعد رشد پيدا کرد
• ساخته شده بر روی تخصص فنی
• قابلیت دسترسی مجازی
• کسب مداوم
• بر بهره برداری و تولید تمرکز کنید
نسل سوم (سال 2016 تا 2020)
• بر روی یادگیری ماشین و استدلال خودکار ساخته شده است
• رمزگذاری همه جانبه منکر دسترسی است
• روی جمع آوری و انتشار تمرکز کنید؟
اگر IC در چنین موقعیتی مؤثر واقع شود ، می تواند حجم داده های موجود را با قابلیت ذخیره و پردازش داده های جدید جبران کند. به عنوان مثال ، پخش مستقیم فیلم و پخش به طور فزاینده ای رایج می شود. در سال 2011 ، You Tube در مدت 60 روز بیش از آنچه که توسط سه شبکه اصلی تلویزیونی ایالات متحده ایجاد شده بود ، محتوای ویدیویی بیشتری را بارگذاری می کرد. 9 تا سال 2015 ، 300 دقیقه فیلم در هر دقیقه در YouTube بارگذاری می شد 10.سیستم عامل جدید چندگانه امکان پخش ویدیوی زنده را در اختیار کاربران قرار می دهد.
ویدئوی زنده می تواند IC را در زمان واقعی از رویدادهای جاری آگاه کند اما ، بدون استفاده از آنالیز رایانه ، امکان پردازش این حجم گسترده از اطلاعات در زمان واقعی امکان پذیر نیست.
مکالمه در OSINT اغلب بر تجزیه و تحلیل اطلاعات متمرکز است. با این حال ، یک فرصت بالقوه برابر یا بیشتر برای عملیات اطلاعاتی وجود دارد. یک مثال واقعیت افزوده است – جایی که یک لایه دیجیتال واقعیت را تقویت می کند – و فناوری پوشیدنی. نمونه های مشهور واقعیت خودکار Google Glass ، نمایشگر نوری به شکل عینک است که اطلاعات دیجیتالی را نشان می دهد و Pokemon Go ، بازی ای که تصاویر دیجیتالی را در دنیای واقعی با استفاده از تلفن های هوشمند GPS مجهز می کند. فناوری واقعیت افزوده می تواند پتانسیل هایی برای هدف گذاری و استخدام دارایی های انسانی برای عملیات HUMINT داشته باشد.
روان سنجی – یک زیر شاخه از روانشناسی مبتنی بر داده ها- همچنین پتانسیل را دارد که بین OSINT و عملیات روانشناختی و اطلاعاتی تار شود. به عنوان مثال ، شرکت فناوری Cambridge Analytica ادعا می کند که می تواند رفتارهای فردی را بر اساس نقاط داده های عمومی و الگوسازی داده ها پیشگویی کند. مطابق با بررسی National Review ، این شرکت در مبارزات انتخاباتی ریاست جمهوری ایالات متحده در سال 2016 برای ایجاد تبلیغات سیاسی با پیام هایی که برای هدف گیری تعصبات ناخودآگاه ساخته شده بود ، به کار گرفته شد. این فناوری نه تنها پتانسیل انجام عملیات اطلاعاتی را دارد ، بلکه سؤالات جدیدی را در مورد اخلاق و مراجع قانونی برای آی سی ایجاد می کند.
رمزگذاری نیز به احتمال زیاد تبدیل به یک ویژگی شایع تر OSINT نسل سوم می شود ، زیرا نرم افزار رمزنگاری به طور فزاینده ای فراگیر ، در دسترس و قوی می شود. مجله آنلاین Wired ، سال 2016 را “سال رمزگذاری برنده” توصیف کرده است که نشانگر استفاده روز افزون از رمزگذاری نهایی توسط کاربران عادی و یک چالش حقوقی در مورد رمزگذاری بین اپل و دفتر تحقیقات فدرال است. با تبدیل شدن رمزنگاری به جریان اصلی ، مسائل جدید تعریف و تقسیم کار را برای IC مطرح می کند. رمزگشایی اطلاعات برای ارزش بالقوه اطلاعاتی عموماً تحت نظر NSA و دستورالعمل SIGINT آن قرار گرفته است. با این حال ، به طور سنتی ، سازمان های دولتی استفاده کننده از فناوری های رمزگذاری بودند. اگر کاربرانی که اطلاعاتی را تولید می کنند که در حال حاضر OSINT به حساب می آیند ، از رمزگذاری استفاده کنند ، آیا IC اکنون این اطلاعات را SIGINT در نظر می گیرد و مسئولیت بهره برداری از آن را به NSA منتقل می کند؟
نتیجه
فرصتهای بسیاری برای تحقیق بیشتر در مورد روش OSINT ، ابزارهای COTS برای تجزیه و تحلیل منبع باز و روشهای تحلیلی منبع آزاد برای ارایه ارزش اطلاعات بیشتر به IC و فعال کردن عملیات کارآمدتر وجود دارد. به عنوان مثال ، همانطور که در فصل دوم ذکر شد ، ارزیابی دقیق از دشواری چرخه روش شناختی OSINT برای زیرگروه های مختلف OSINT می تواند تقسیم بهتری از منابع و تلاش را در بین منابع مختلف OSINT فراهم کند. این می تواند با مصاحبه با متخصصان منبع آزاد و اندازه گیری زمان و تلاش صرف شده برای تولید نمونه وسیعی از پروژه های OSINT محقق شود. IC همچنین می تواند از کارهای اضافی در مورد روشهای تحلیلی و ابزارهای تحلیلی موجود بهره مند شود ، همانطور که در فصل سوم مورد بحث قرار گرفت. برای مثال ، ابزارهای موجود COTS می توانند با روشهای مشخص شده در فصل سوم ارزیابی شوند. این ابزار همچنین می تواند در اقدامات عملی از جمله هزینه ، سهولت در استفاده ، شفافیت روش ها و درک میزان خروجی برای مصرف کنندگان آی سی ارزیابی شود. یک بانک اطلاعاتی زنده از سیستم عامل های مختلف می تواند به دفاتر IC که عملکرد OSINT دارند کمک کند و به آنها امکان می دهد منابع را عاقلانه خرج کنند و از افزونگی خودداری کنند. علاوه بر این ، تثبیت ابزارهای COTS در تجزیه و تحلیل محتوای کوتاه رسانه های اجتماعی از فرصتهای ارائه شده توسط سوء استفاده از IC در ادبیات خاکستری و محتوای رسانه های اجتماعی شکل طولانی فاصله می گیرد. ارزیابی تخصیص منابع IC بین چهار نوع OSIF تعریف شده در این گزارش مفید است و اکتشاف مناطقی که علم داده ها و ابزارهای تحلیلی می توانند باعث افزایش استفاده IC از انواع OSIF شوند.
سرانجام ، IC می تواند همکاری خود را با صنعت خصوصی و دانشگاه ها گسترش دهد ، که هر دو همیشه در حوزه منبع آزاد فعالیت داشته اند و توانایی های خود را بالغ می کنند ، زیرا انقلاب دیجیتال همچنان در حال تکامل و گسترش است. دسترسی به غیردولتی
نهادها چالش هایی را برای سازمان های IC ایجاد می کنند ، اما این چالش ها قابل کنترل هستند. موانع موجود برای همکاری با مبتکران غیردولتی در جمع آوری داده ها و تجزیه و تحلیل داده های بزرگ باید برطرف شود. اولویت قرار دادن این راه حل از طریق تغییر سیاست ها و تخصیص بودجه ، اولین گام مهم برای پیشبرد مشارکت های موجود ، ایجاد مشاغل جدید و اطمینان از ماندن جریان بین المللی در یک دامنه به سرعت در حال تغییر است.
پایان
استاد راهنما:جناب آقای حبیبی
دانشجویان: 1-مهدی بنار(ویرایش وجمع بندی کلی) 2-رسول شیریان 3-علیرضا رهسپار عباسی 4-محمد عبدالله زاده
5-سجاد شریفی 6-حجت پورسامانی
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 2167
برچسباوسينت ترجمه رويکرد ثانويه به اوسينت (OSINT) نسل هاي اوسينت نظام اطلاعاتی
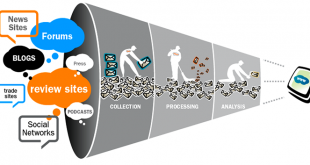







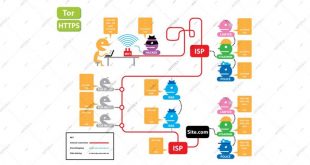




یک دیدگاه
بازتاب ها: اوسینت (OSINT) چیست؟ جاسوسی مؤدبانه