ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
5,687 تعداد نمایش
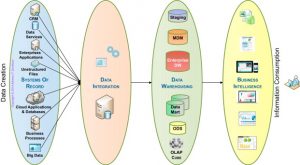
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي مي شوند که منجر به بوجود آمدن اصطلاحات تخصصي در اين مورد شده است. که هر کدام بار معنايي خودش را به همراه دارد. واژه هايي مثل ديتا ليک، دیتا ورهاس، دیتا مارت، دیتا کیوب، دیتا بیس و …
انبار داده مجموعه ای از دادههای مختلف است که برای گزارشگیری و تحلیل داده به کار میرود و بعنوان هسته اصلی یک سیستم BI به شمار میآید. به عبارت دیگر انبار داده یک مخزن داده مرکزی از دادههای تجمیع شده است که از سیستمها و منابع مختلف سازمان جمعآوری شده است. انبار داده یک بانک اطلاعاتی غیرنرمال ولي ساختار سافته است که دادههای حال و گذشته را در یک مکان واحد تجمیع کرده است و هدف اصلی آن پوشش گزارشگیری و نیازهای تحلیلی یک سازمان به کار گرفته میشود.
دریاچه داده (Data Lake) چيست؟
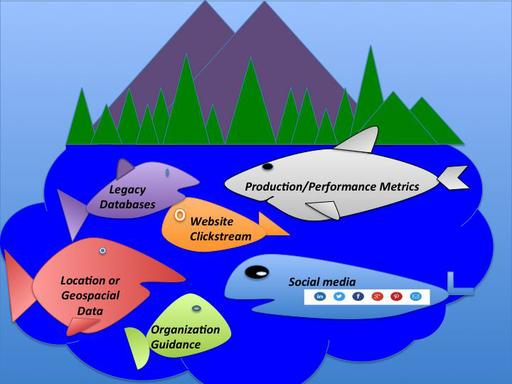
یک دریاچه را در نظر بگیرید که رودخانههای مختلف به آن وارد میشوند. در واقع هر رودخانه مقداری آب در این دریاچه خواهد ریخت و آبهای موجود در این دریاچه حاصل مجموعه این رودها است. دریاچه داده یا همان Data Lake نیز به همین صورت است. یک مخزن عظیم که دادههای مختلف از طُرق متفاوت وارد این دریاچه میشوند و در آن ذخیره میگردند.
دریاچه داده
تفاوت انبارداده (Data Warehouse) و دریاچه داده (Data Lake)
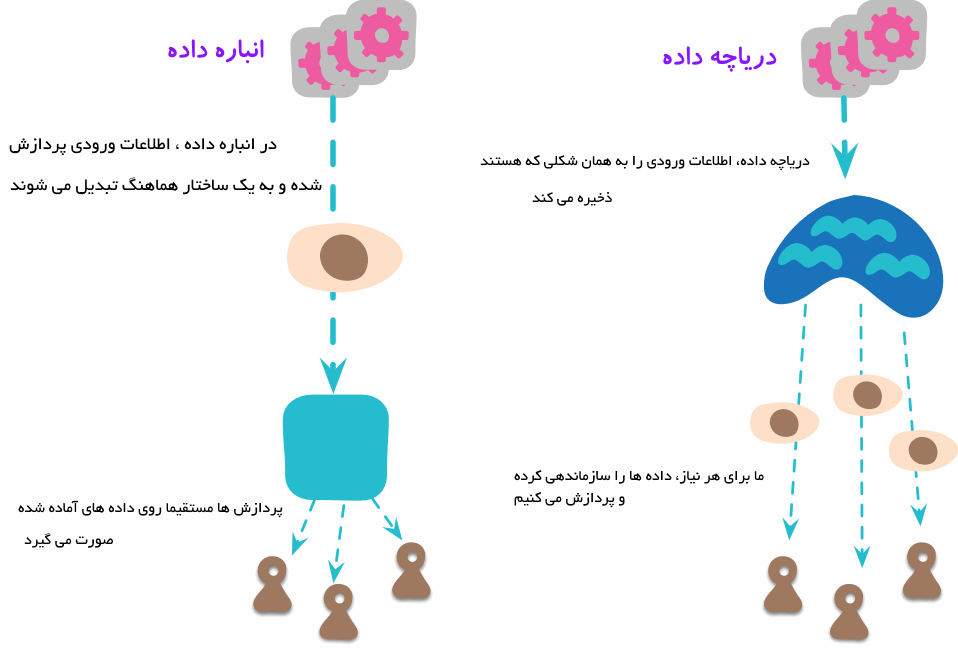
دریاچه داده محلی برای نگهداری بیگ دیتا است. با بیان ساده، مفهوم دریاچه داده را میتوان اینگونه توضیح داد که اگر انبار داده را مشابه یک بطری آب تصفیهشده، بستهبندی شده و آماده مصرف در نظر بگیریم، دریاچه داده (همانند نام آن) دریاچهای است که آب از منابع مختلف ( آب باران، چشمهها، رودها یا منابع دیگر) در آن سرازیر شده و افراد میتوانند از آب دریاچه برای شنا، آشامیدن یا حتی نمونهبرداری! استفاده کنند. در یک شرکت، ما باید همیشه بر اساس داده ها تصمیم بگیریم. ما به داده های کل گروه نیاز داریم تا تصویری جامع داشته باشیم و تصمیمات تجاری درستی بگیریم، هدف حاکمیت داده. اطلاعات بیشتر در مورد حاکمیت داده را اینجا بخوانید.
در انبارداده، دادههای ساختاریافته (Structured Data) قرار میگیرند در حالی که در دریاچه داده هر نوع دادهای (چه ساختاریافته و چه غیرساختاریافته) میتوانند در دریاچه داده یا همان Data Lake ذخیره شوند. دریاچه داده یک الگوی طراحی مبتنی بر دادههای مدرن است که برای نگهداری طیف گستردهای از انواع دادهها، اعم از قدیمی و جدید، در مقیاس وسیع کاربرد دارد. طبق تعریف، دریاچه داده به منظور ذخیره سریع دادههای خام به همراه پردازش دادهها برای اکتشاف، تجزیه و تحلیل و عملیات بهینهسازی شده است.
تفاوت انبارداده (Data Warehouse) و دریاچه داده (Data Lake)
مزایای دریاچه داده
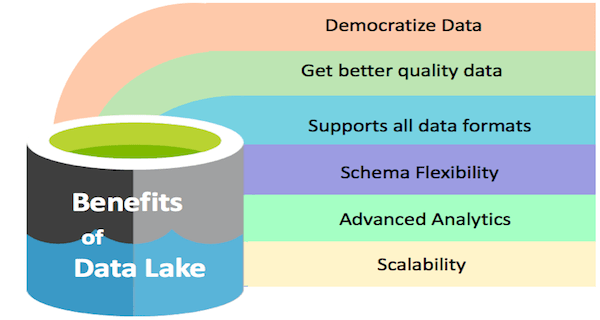
دمکراتیک کردن داده ها
یک دریاچه داده می تواند داده ها را در اختیار کل سازمان قرار دهد. این همان چیزی است که ما آن را دموکراتیزاسیون داده ها می نامیم. در حال حاضر، فقط مدیران ارشد این تجمل را دارند که از بخشهای مختلف گزارش بخواهند، چیزهایی را از آنها دریافت کنند و سپس تصمیم بگیرند. سایر مزایای دریاچه داده را در شکل زیر بررسی کنید:
مزایای دریاچه داده.
Ingestion Data
این مفهوم به اتصالات اجازه میدهد تا دادهها را از منابع مختلف داده دریافت کرده و در دریاچه اطلاعات بارگیری کنند. مفهوم Ingestion Data با موارد زیر سر و کار دارد:
انواع مختلف منابع داده مانند پایگاه داده، وب سرورها، ایمیلها، اینترنت اشیا و FTP
استفاده از دادهها به دفعات زیاد مانند مصرف دستهای یا مصرف لحظهای
انواع داده های ساختار یافته، داده های نیمه ساختار یافته و ساختار نیافته
حاکمیت دادهها
این مفهوم برای کنترل در دسترس بودن، قابلیت استفاده، امنیت و یکپارچگی دادههای مورد استفاده در سازمان مورد استفاده قرار میگیرد.
مقیاس پذیر
ذخیره داده یک مفهوم مقیاس پذیر است. این مفهوم، با ارائه یک ذخیره سازی به صرفه، دسترسی سریع به اکتشاف داده را امکانپذیر میکند. همچنین مفهوم «ذخیره داده» باید از قالبهای مختلف داده پشتیبانی و حمایت کند.
معماری دریاچه داده به چه صورت است؟
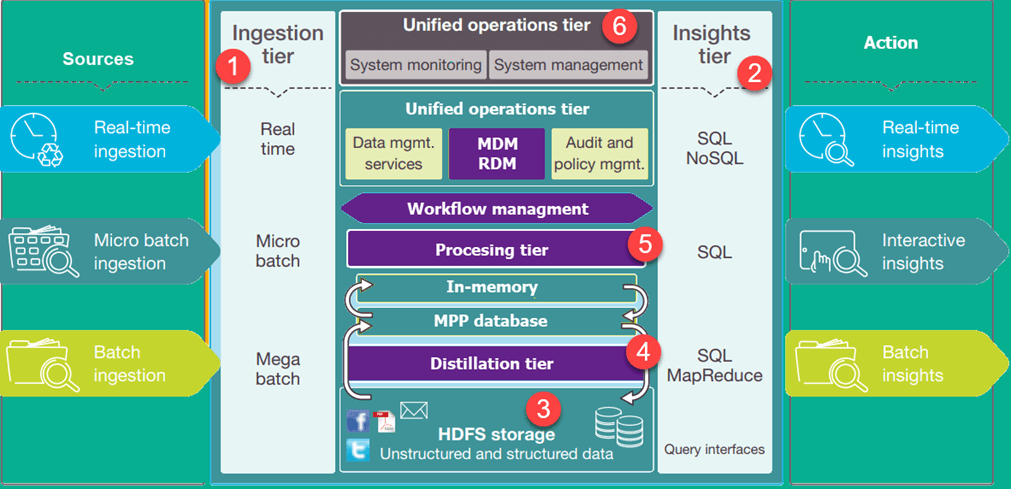
تصویر بالا، معماری دریاچه دادههای یک کسب و کار را نشان میدهد. سطوح پایین نشان دهنده دادههایی است که بیشتر در حالت استراحت هستند در حالی که سطوح بالاتر دادههای معاملاتی در زمان واقعی را نشان میدهند. این دادهها بدون تأخیر یا با کمی تأخیر، از طریق سیستم جریان مییابند. در ادامه طبقات مهم در معماری دریاچه داده را در نظر خواهیم داشت که عبارتند از:
معماری دریاچه داده
Ingestion Tier: ردیفهای سمت چپ منابع داده را به تصویر میکشند. دادهها میتوانند به صورت دستهای یا در زمان واقعی در دریاچه داده بارگیری شوند.
Insights Tier: طبقات سمت راست، نشان دهنده سطح تحقیق است که در آن بینش از سیستم استفاده میشود. برای تجزیه و تحلیل دادهها میتوان از SQL ،NoSQL query یا حتی excel استفاده کرد.
HDFS: یک راهحل مقرون بهصرفه برای دادههای ساختاریافته و بدون ساختار است. این بخش، یک منطقه فرود (Landing Zone) برای تمام دادههایی است که در سیستم در حالت استراحت هستند.
Distillation tier: دادهها را از حلقه ذخیرهسازی گرفته و برای تجزیه و تحلیل آسانتر به دادههای ساختاری تبدیل میکند.
Processing tier: پردازش ردیف الگوریتمهای تحلیلی و پرس و جوهای کاربران با زمان واقعی متفاوت، تعاملی و دستهای برای تولید دادههای ساختار یافته به جهت تجزیه و تحلیل آسانتر.
Unified operations tier: این ردیف عملیات واحد، حاکم بر مدیریت و نظارت بر سیستم است. این بخش شامل حسابرسی و مدیریت مهارت، مدیریت دادهها، مدیریت گردش کار میباشد.
بازار داده یا دیتا مارت (Data Mart) چيست؟
ساخت یک بازار داده (Data Mart) به مراتب سادهتر و کمهزینهتر از ساخت یک انبار داده است و در زمان نیز صرفهجوبی میشود. بسیاری از سازمانها یا شرکتهای بزرگ که به واحدهای کوچکتر تقسیمبندی میشوند، میتوانند از بازار داده به جای انبار داده برای طراحیهای خود استفاده کنند.
انواع بازارهای داده
سه نوع بازار داده وجود دارد که براساس رابطه آنها با انبار داده و منابع داده مربوطه هر سیستم متفاوت هستند.
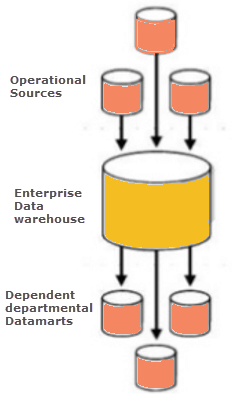
بازارهای داده وابسته، بخشهای تقسیم شده در انبار دادههای سازمانی هستند. این روش از بالا به پایین با ذخیرهسازی تمام دادههای کسب و کار در یک مکان مرکزی آغاز میشود. دادههای جدید ایجاد شده هر زمان که برای تجزیه و تحلیل مورد نیاز باشد، یک زیرمجموعه مشخص از دادههای اصلی را استخراج میکنند.
دیتا ماررت وابسته
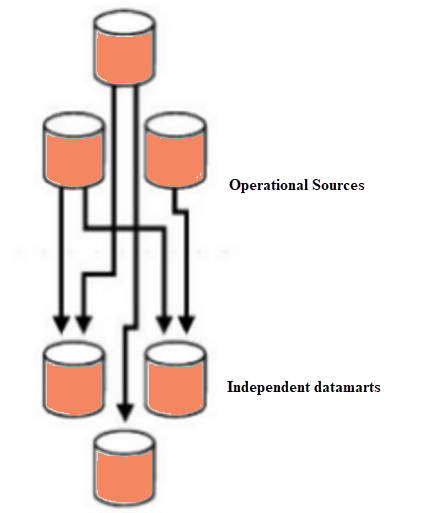
بازارهای داده مستقل، مانند یک سیستم مستقل عمل میکنند که بر انبار داده تکیه ندارند. تحلیلگران میتوانند دادههای مربوط به یک موضوع خاص یا فرآیند کسب و کار را از منابع داده داخلی یا خارجی استخراج، پردازش کرده و سپس در مخزن بازار داده ذخیره کنند تا زمانی که تیم به آنها نیاز پیدا کند.
دیتا مارت مستقل
بازارهای داده ترکیبی، دادههای موجود در انبارهای داده و سایر منابع عملیاتی را ترکیب میکنند. این رویکرد واحد از سرعت و رابط کاربرپسند یک رویکرد از بالا به پایین استفاده میکند و همچنین یکپارچهسازی روش مستقل را در سطح شرکت ارائه میدهد.
دیتا مارت ترکیبی
تفاوت بازار داده (Data Mart) با انبار داده (Data Warehouse)
اگر شما بخواهید یک بسته آدامس بخرید، طبیعتا به انبار آدامس رجوع نمیکنید و به سراغ بازار (همان سوپر مارکتها) رفته و از آنجا خرید خود را انجام میدهید. انبار داده (Data Warehouse) و بازار داده (Data Mart) نیز این چنین تفاوتی نسبت به یکدیگر دارند. در یک تعریف ساده، بازار داده یک نمونه کوچکتر و یا یک زیر مجموعه از انبار داده است.
سازمانها انبارهای داده و مارتهای دیتا را ایجاد می کنند زیرا اطلاعات موجود در دیتابیس به گونه ای سازماندهی نشده است که باعث می شود آن را به راحتی در دسترس قرار دهد ، به سؤالات بسیار پیچیده ای نیاز دارد و دسترسی به آنها یا مصرف منابع بسیار دشوار است .
در کل سه نوع مختلف بازار داده (Data Mart) وجود دارد. وابسته (Dependent)، مستقل (Independent) و ترکیبی (Hybrid).
تفاوت انباره داده(DWH) با پایگاه داده(DB) در چیست؟
۱- بانک اطلاعاتی (پایگاه داده) برای ثبت سریع و بیدرنگ تراکنشهای یک سیستم استفاده میشود(OLTP) درصورتیکه از انبارههای داده برای آنالیز و تصمیمگیریهای کلان استفاده میشود (OLAP).
۲- روابط بین جداول در بانکهای اطلاعاتی پیچیده میباشند درحالیکه انبارههای داده روابط پیچیدهای ندا ردند و برای بالا بردن سرعت تقریباً نرمالسازی نمیشوند.
۳- بانک اطلاعاتی موجودیت محور هست یعنی در طراحی آن موجودیتها نقش اصلی را بازی میکنند درحالیکه در انباره داده این مدلهای دادهای هستند که نقش اصلی رو در طراحی ایفا میکنند.
۴- بانکهای اطلاعاتی جهت درج داده طراحی میشوند درحالیکه انبارههای داده بیشترین تمرکز را در سرعت در خواندن داده دارند.
۵-سرعت بانک اطلاعاتی در گزارشهایی جهت آنالیز اطلاعات بسیار پایین است اما سرعت آنالیزها در انباره داده بیشتر هست.
و درنهایت یک انباره داده معمولاً یک بانک اطلاعاتی است و همچنین ممکن است یک انباره داده از چند بانک اطلاعاتی داده دریافت کند.
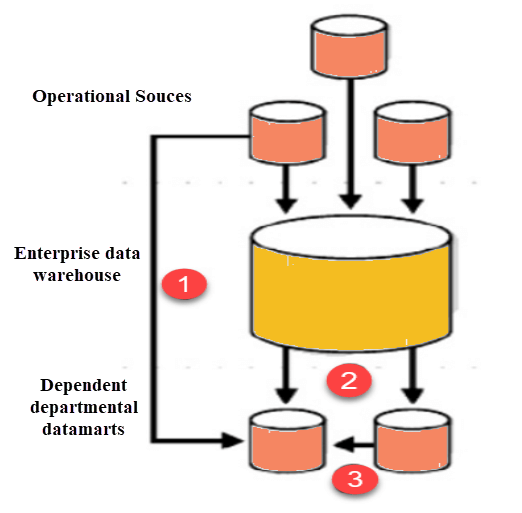
رابطه بازار داده و انبار داده
البته بازار داده لزوما نباید از انبار داده استخراج شود. برای مثال میتوانید بازار داده را از منابع دادهی عملیاتی (Operational Data Sources) مستقیما استخراج کنید. یعنی به جای اینکه اول انبار داده را ساخته و سپس از روی آن بازار داده را بسازید، میتوانید مستقیما بازار داده را از منابع عملیاتی بسازید. مانند این است که برای ایجاد یک بازار واقعی (مثلا سوپر مارکت) لزوما نیاز به یک انبار ندارید.
ساخت یک بازار داده (Data Mart) به مراتب سادهتر و کمهزینهتر از ساخت یک انبار داده است و در زمان نیز صرفهجوبی میشود. بسیاری از سازمانها یا شرکتهای بزرگ که به واحدهای کوچکتر تقسیمبندی میشوند، میتوانند از بازار داده به جای انبار داده برای طراحیهای خود استفاده کنند.
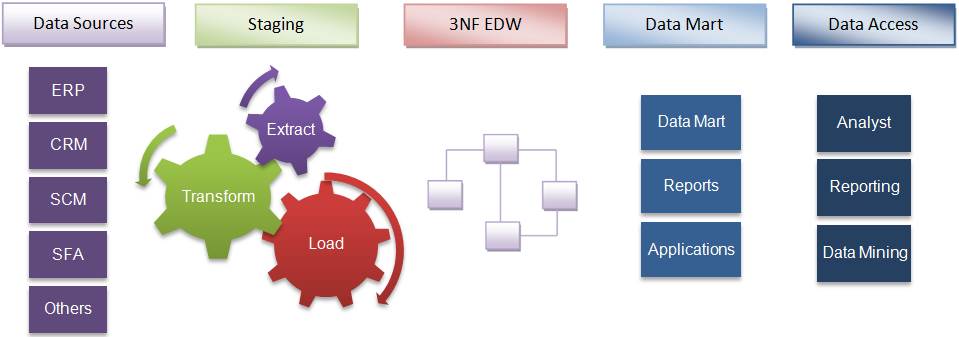
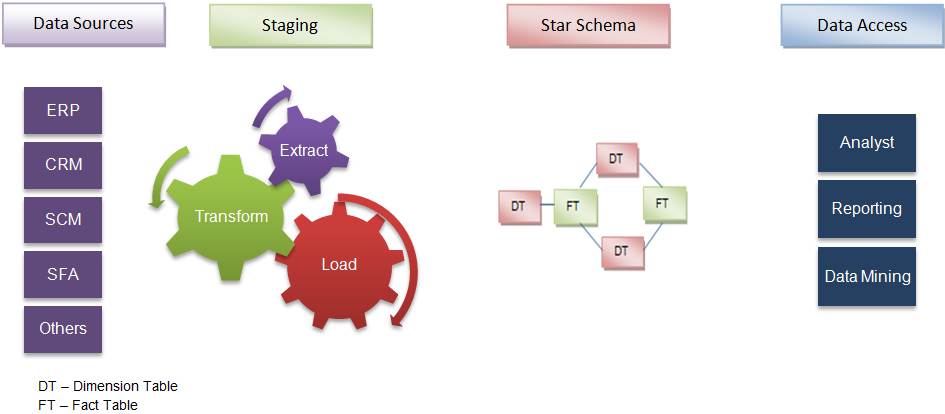
معماری انباره داده سه لایه
لایه پایینی یا لایه دیتا سورس
سرور معماری انبار داده، شامل سرور پایگاه داده رابطهای است که از ابزارهای Back-End و دیگر ابزارهای کاربردی برای انتقال اطلاعات از منابع مختلف دادهای مانند پایگاه دادههای تراکنشی و غیره، به لایه پایینی استفاده میشود. این ابزارهای کاربردی و ابزارهای Back-End عملکردهای Extract، Clean ،Load و Refresh را انجام میدهند.
لایه میانی یا لایه مدل یا تحلیل
لایهی میانی یک سرور OLAP را در اختیار میگیرد که به وسیلهی آن دادهها را به یک ساختار مناسبتر تبدیل میکند تا بتوان به کوئریهای پیچیده بر روی دادهها و تحلیل آنها دسترسی داشت. این سرور به دو روش میتواند کار کند:
الف) Relational OLAP (ROLAP): یک سیستم مدیریت پایگاه داده رابطهای گسترده است. ROLAP عملیات بر روی دادههای چند بعدی را به عملیاتهای رابطهای استاندارد تبدیل میکند.
ب) Multidimensional OLAP (MOLAP): که به طور مستقیم دادههای چند بعدی و عملیات را اجرا می کند.
لایه بالایی یا لایه کسب و کار
لایه بالایی، لایه client یا front-end است. این لایه، ابزارهایی را برای استفاده در زمینههای تجزیه و تحلیل داده، پرس وجو (کوئری) گزارشگیری و داده کاوی فراهم میآورد. مثل ابزارهای BI
لایه ها در انبار داده
انواع مدل و طراحی انبار داده
در زير دو نمونه از معماري هاي پرکاربرد در شکل آورده شده است.
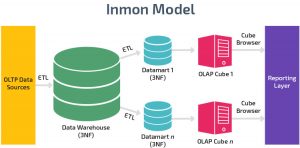
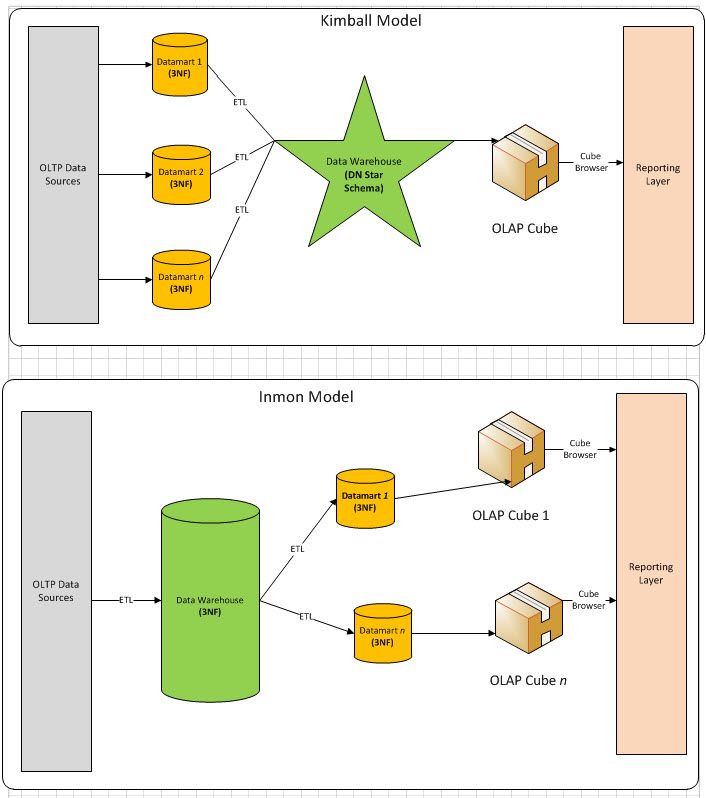
معماري inmon (طراحی پایین به بالا)
این رویکرد در طراحی انبار داده توسط آقای بیل اینمون (Bill Inmon) مطرح شده است. در این رویکرد ابتدا یک انبار داده جامع و کامل طراحی می شود. در واقع در این رویکرد داده از منابع داده ای مختلف استخراج، پاکسازی و در بالاترین سطح ریز دانگی در یک انبار داده جامع ذخیره می شود.
موضوع گرا: داده های موجود در انبار داده ها به گونه ای سازماندهی شده اند که تمام عناصر داده مربوط به یک رویداد یا شیء واقعی مشابه با هم مرتبط هستند.
Time-variant: تغییرات داده های موجود در پایگاه داده ردیابی و ثبت می شوند تا گزارش هایی ایجاد شوند که تغییرات را در طول زمان نشان می دهند.
غیر فرار: داده های موجود در انبار داده هرگز رونویسی یا حذف نمی شوند. پس از انجام تعهد ، داده ها ثابت هستند ، فقط خواندنی هستند و برای گزارش های بعدی حفظ می شوند.
یکپارچه: پایگاه داده حاوی داده های اکثر یا همه برنامه های کاربردی سازمان است و این داده ها سازگار هستند.
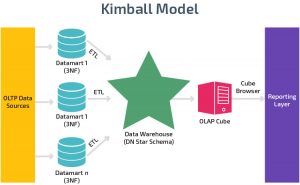
معماري kimball (طراحی بالا به پایین)
این رویکرد توسط آقای رالف کیمبل (Ralph Kimball) معرفی شده است. در واقع در این رویکرد Data Mart های کوچک متناسب با نیاز هر بخش سازمان (فروش، منابع انسانی و …) طراحی می شود و سپس انبار داده جامع سازمان از تجمیع این Data Mart ها به وجود می آید. از مزایای این رویکرد می توان به پیاده سازی سریع این رویکرد اشاره کرد.
رابطه مکعب داده و انبار داده در معماري کيمبال
انتخاب رویکرد معماری:
بیمه: بدست آوردن تصویر کلی نسبت به مشتریان ، گروه ها ، سابقه مطالبات ، گرایش به نرخ مرگ و میر ، جمعیت شناسی ، سودآوری هر طرح و نمایندگان و غیره بسیار مهم است. همه جنبه ها به هم مرتبط هستند و بنابراین برای رویکرد Inmon مناسب هستند. بازاریابی: این یک بخش تخصصی است که نیاز به انبار سازمانی ندارد. فقط داده های مورد نیاز است ، بنابراین رویکرد کیمبال مناسب است. CRM در بانک ها: تمرکز بر پارامترهایی مانند محصولات فروخته شده ، فروش بالا و فروش متقابل در سطح مشتری است. نیازی به تصویر کلی از کسب و کار نیست. به عنوان مثال ، نیازی نیست که اطلاعات مشتری را به بخش خزانه داری مربوط به معاملات و مقررات فارکس متصل کنید. از آنجا که دامنه محدود است ، می توانید از روش Kimball استفاده کنید. با این حال ، اگر قرار باشد تمام فرایندها و تقسیمات موجود در بانک به هم مرتبط شوند ، انتخاب واضح طراحی اینمون در مقابل کیمبال است. تولید: عملکردهای متعددی در اینجا صرف نظر از بودجه موردنظر انجام می شود. بنابراین ، در جایی که وابستگی سیستمیک وجود دارد ، مانند این مورد ، مدل سازمانی مورد نیاز است ، بنابراین روش اینمون ایده آل است.
تقاوت اینمون و کیمبال
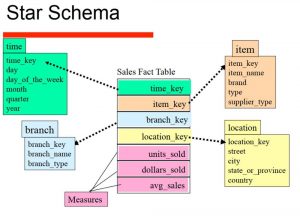
طراحی Star
Star schema سادهترین روش پیاده سازی Data Warehouse، طراحی ستاره ای به طراحی گفته می شود که جدول Fact در مرکز قرار گرفته و توسط جداول Dimension محاصره می شود. در این مدل جداول Dimension با یکدیگر ارتباط ندارند و فقط از طریق کلید با جدول Fact ارتباط دارند. این نوع طراحی برای گزارش گیری بسیار بهینه است.
جدول Fact شامل رویداد هاست و اعداد و ارقامی که آن رویداد را توصیف می کنند. به طور مثال فروش یک کالا یک رویداد است که اتفاق می افتد و اعداد و ارقامی مانند تعداد فروش و مبلغ فروش یا تخفیف اعداد و ارقامی هستند که این رویداد را توصیف می کنند. همچنین برداشت وجه نقد از دستگاه عابر بانک یک روبداد است که اتفاق می افتد و اعداد و ارقامی چون مبلغ برداشتی از حساب اعداد و ارقامی هستند که این رویداد را توصیف می کنند.
جداول Dimension، موجودیت هایی هستند که یک رویداد را شرح می دهند. در واقع مشتری، زمان، کارمند، فروشگاه و … موجودیت هایی هستند که هر کدام به صورت جداگانه در قالب یک جدول ظاهر می شوند و رویداد فروش را شرح می دهند. جداول Fact معمولا شامل اعداد و ارقام هستند در حالی که جداول Dimension معمولا رشته ها را در خود جای می دهند.
از آنجا که در طراحی ستاره ای جدول Fact با Dimension ها در ارتباط است می توان گفت جداول Fact شامل کلید جداول Dimension و اعداد و ارقام مربوط به رویداد است. جداول Fact معمولا شامل اعداد و ارقام هستند در حالی که جداول Dimension معمولا رشته ها را در خود جای می دهند.
کارایی بالای گزارش گیری از داده های تاریخی سالیانه
انعطاف پذیری بالا برای تحلیل داده های چندبعدی
پشتیبانی از بسیاری از سیستم های مدیریت پایگاه داده های رابطه ای
تحلیل ساده تر داده ها نسبت به پایگاه های نرمالیزه شده.
DWH Star
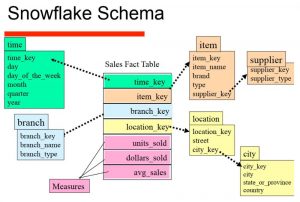
طراحی Snow Flake
طراحی دانه برفی نوعی از طراحی ستاره ای به شمار می رود که در آن درجه نرمال سازی اندکی بیشتر است. در واقع در این نوع طراحی جداول Dimension می توانند در یک جهت با یکدیگر رابطه داشته باشند و زنجیره ای از روابط را ایجاد کنند. به عبارت دیگر در این نوع طراحی با سلسله مراتبی از جداول Dimension روبرو هستیم. این نوع طراحی می تواند باعث کاهش تکرار و هدر رفت مموری شود. این نوع طراحی نسبت به طراحی ستاره ای با کاهش در عملکرد همراه است.
DWH Snowflake
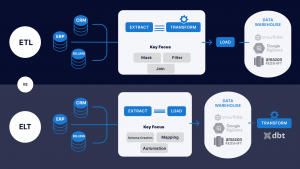
ETL با ELT به روایت تصوير
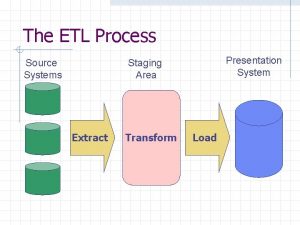
ETL در واقع به جریان انداختن این داده ها با استخراج داده از منابع داده ای مختلف در سازمان یا خارج از آن، پاکسازی و تبدیل به فرمت مورد نیاز و نهایتا ایجاد ساختار مناسب برای پیاده سازی هوش تجاری است. ETL معمولا یک فرآیند تکراری و خودکار است که به صورت روزانه، هفتگی یا ماهانه تکرار می شود.
تفاوت ETL با ELT
تعریف Data Cube (مکعب داده)
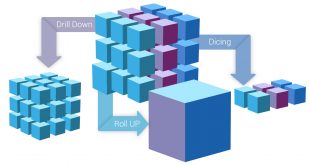
Data Cube یک محدوده سه بعدی یا بالاتر است که معمولا برای توضیح توالی زمان یک داده استفاده می شود. Data Cube ها برای نمایش داده های پیچیده، که توسط جدولی از سطرها و ستون ها توصیف می شود، استفاده می شوند که در آن داده ها به صورت چند بُعدی نمایش داده شده و هر بُعد یک ویژگی از انبار داده را نشان میدهد. به عنوان مثال، فروش روزانه، ماهانه یا سالانه..
Data Cube به راحتی داده ها را تفسیر می کند و هنگامی مفید است که داده ها را با ابعاد به عنوان سنجه های مشخصی از نیازهای کسب و کار ارائه دهید. داده های موجود در داخل Data Cube ها، تقریبا تمام ارقام را برای مشتریان، عوامل فروش، محصولات و خیلی بیشتر،تجزیه و تحلیل می کند. بنابراین، یک Data Cube می تواند به ایجاد روند و تجزیه و تحلیل عملکرد کمک کند.
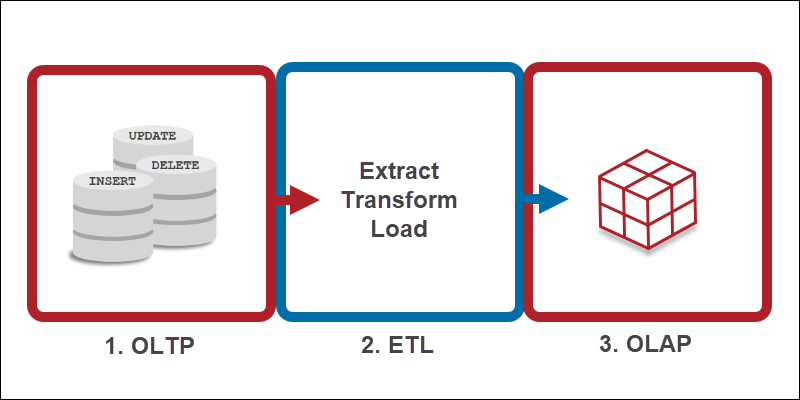
سیستم پردازش تحلیلی برخط OLAP
سیستم های OLAP نام خود را از عبارت (Online Analytical Process) با معنی تحت اللفظی سیستم های پردازش تحلیلی برخط گرفته اند. می توان به جای OLAP از واژه پردازش سریع اطلاعات چند بعدی و یا به عبارت بهتر از ” فن آوری تحلیل داده ها” استفاده کرد. این سیستمها بر اساس تکامل سیستمهای OLTP به معنی پردازش آنلاین تراکنش ها (On Line Transaction Processing ) یا همان پایگاه های داده ایجاد شده اند.
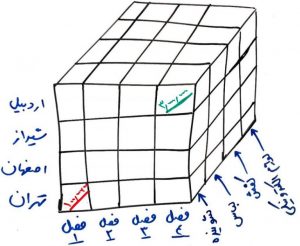
مثالي از کاربرد مکعب داده
فرض کنيد میخواهیم فروش یک سازمان را بررسی کنیم و برای اینکار، سابق بر اين از پایگاهدادها با جداول مختلف، استفاده ميکرديم. مثلا اگر میخواستیم فروش فصل اول در شهر تهران چقدر بوده است براي این کار بدون استفاده از مکعب داده میبایستی برای هر سوال یک پرس و جو (Query) بر روی پایگاه داده مینوشتیم
توجه داشته باشيد که ابعاد اين کوئري خیلی بیشتر از این ۳بُعد است) و این نیازمند Joinهای مختلف و Query سنگین بود که برای پایگاهدادههای بزرگ احتمالا زمان زیادی (حتی در حد چند ساعت) تلف میشد. ولی در مکعب داده و با کمک سیستمهای OLAP میتوان این دادهها را با توجه به موضوع خاصی که به دنبال آن هستیم (در این مثال مقدار فروش) تجمیع و گردآوری کنیم و به سرعت پاسخ پرس و جو (Query)های خود را به دست آوریم.
ديتا کيوب يا مکعب داده
تفاوت OLAP با OLTP
پایگاههای داده برای مدل OLTP بهینه سازی شده که براساس مدل داده رابطهای امکان پردازش تعداد زیادی تراکنش همروند_ که اغلب حاوی رکوردهای اندکی هستند_ را دارد. اما در انبارهای داده که برای پردازش تحلیلی آنلاین طراحی شدهاند امکان پردازش تعداد کمی پرس و جو پیچیده برروی تعداد بسیار زیادی رکورد داده فراهم میشود.
سیستم های OLAP برای ارائه پاسخهای سریع به سوالات و جستجوهای تحلیلی روی داده های “چند بعدی” طراحی شده اند. بطور معمول اگر بخواهیم مشابه همین پرس و جوهای تحلیلی را روی سیستم های اطلاعاتی عادی OLTP اجرا کنیم ممکن است نتایج در زمانی طولانی و غیرکاربردی بازگردانده شود در حالیکه استفاده از OLAP تضمین می کند که اطلاعات و گزارشات تحلیلی با زمان پاسخ مناسبی به کاربر تحویل داده شود. کاربردهای معمول OLAP عبارتند از : گزارشات تجاری فروش ، بازاریابی ، گزارشات مالی و مواردی از این قبیل. این سیستم ها داده های خود را به نحوی خاص نگهداری می کنند که از نظر سرعت در برخورد با داده های چند بعدی بهتر از سیستمهای OLTP عمل می کنند و از این رو به آنهابانکهای اطلاعاتی سلسله مراتبی (Hierarchical) هم گفته میشود.
Parameters
OLTP
OLAP
Process
It is an online transactional system. It manages database modification.
OLAP is an online analysis and data retrieving process.
Characteristic
It is characterized by large numbers of short online transactions.
It is characterized by a large volume of data.
Functionality
OLTP is an online database modifying system.
OLAP is an online database query management system.
Method
OLTP uses traditional DBMS.
OLAP uses the data warehouse.
Query
Insert, Update, Delete
Mostly select operations
Table
Tables in OLTP database are normalized.
Tables in OLAP database are not normalized.
Source
OLTP and its transactions are the sources of data.
Different OLTP databases become the source of data for OLAP.
Data Integrity
OLTP database must maintain data integrity constraint.
OLAP database does not get frequently modified. Hence, data integrity is not an issue.
Response time
It’s response time is in millisecond.
Response time in seconds to minutes.
Data quality
The data in the OLTP database is always detailed and organized.
The data in OLAP process might not be organized.
Usefulness
It helps to control and run fundamental business tasks.
It helps with planning, problem-solving, and decision support.
Operation
Allow read/write operations.
Only read and rarely write.
Audience
It is a market orientated process.
It is a customer orientated process.
Query Type
Queries in this process are standardized and simple.
Complex queries involving aggregations.
Back-up
Complete backup of the data combined with incremental backups.
OLAP only need a backup from time to time. Backup is not important compared to OLTP
Design
DB design is application oriented. Example: Database design changes with industry like Retail, Airline, Banking, etc.
DB design is subject oriented. Example: Database design changes with subjects like sales, marketing, purchasing, etc.
User type
It is used by Data critical users like clerk, DBA & Data Base professionals.
Used by Data knowledge users like workers, managers, and CEO.
Purpose
Designed for real time business operations.
Designed for analysis of business measures by category and attributes.
Performance metric
Transaction throughput is the performance metric
Query throughput is the performance metric.
Number of users
This kind of Database users allows thousands of users.
This kind of Database allows only hundreds of users.
Productivity
It helps to Increase user’s self-service and productivity
Help to Increase productivity of the business analysts.
Challenge
Data Warehouses historically have been a development project which may prove costly to build.
An OLAP cube is not an open SQL server data warehouse. Therefore, technical knowledge and experience is essential to manage the OLAP server.
Process
It provides fast result for daily used data.
It ensures that response to the query is quicker consistently.
Characteristic
It is easy to create and maintain.
It lets the user create a view with the help of a spreadsheet.
Style
OLTP is designed to have fast response time, low data redundancy and is normalized.
A data warehouse is created uniquely so that it can integrate different data sources for building a consolidated database
دسته بندی Data Cube یا OLAP
Data Cube ها عمدتا به دو دسته تقسیم می شوند. سرورهای OLAP هم میتوانند رابطهای باشند ( ROLAP ) و هم میتوانند چندبعدی باشند (MOLAP).
Data Cube چند بعدی :
اکثر محصولات OLAP بر اساس ساختاری طراحی شده اند که داده ها را به شکل آرایه های مرتب شده بر اساس ابعاد داده ذخیره می کنند. MOLAP در مقایسه با رویکردهای دیگر و به دلیل ساختار خاص نگهداری اطلاعات، از سرعت بالایی برخوردار است و کارایی را بهبود می بخشد. وقتی که تعداد ابعاد بزرگتر است، مکعب کوچکتر می شود.
OLAP رابطه ای :
OLAP ارتباطی یا ROLAP، از مدل پایگاه داده رابطه ای استفاده می کند. و عملیات OLAP را در قالب استفاده از مدل Relational ساماندهی می کند و لذا از سیستم های MOLAP کندتر عمل می کنند و به فضای بیشتری نیز نیاز دارند.
 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم