 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خصوصیات بیگ دیتا یا کلان داده چیست؟ و جایگاه هدوپ کجاست
کلانداده (Big Data) اصطلاحی است که برای تعریف دادهها در حجم انبوه استفاده میشود: حجم بزرگ یا پیچیدهای از دادهها که ابزارهای متداول پردازش دادهها برای تحلیل و کاوش آن ناتوان باشد. «کلانداده داراییهای اطلاعاتی را شامل میشود که ویژگیهایی همچون حجم بسیار زیاد و سرعت و تنوع دارد و نیازمند روشهای متمایز دادهکاوی برای حصول به ارزش است.» (گارتنر)
عناوين مطالب: '
تعریف کلان داده
متداول شدن استفاده از اینترنت و تسلط فناوری اطلاعات و ارتباطات در دو دهه اخیر باعث شده امکان جمعآوری اطلاعات و ذخیرهسازی آن در حجم شگفتآوری افزایش یابد. همچنین امکان تولید اطلاعات و به اشتراک گذاشتن آن بسیار بیشتر شده است. آنچه اکنون اهمیت یافته این است که دادهی درست، در زمان درست، در اختیار افراد مناسب قرار گیرد. بدین ترتیب «دانش کلانداده» یک الگوی عملگرایانه از مطالعات ترکیبی در فضای سیاست، کسب و کار، ورزش و… است که به ویژه از ابزارهای فناورانه استفاده میکند و در نهایت این هدف را دنبال میکند که «چه اطلاعاتی را در زمان مناسب در اختیار چه کسی قرار دهیم تا درستترین تصمیم را بگیرد» (Stanier,2017).
خصوصیات کلان داده
تعاریف متعددی در رابطه با کلان داده وجود دارد ولی جامع ترین تعریف را موسسه گارتنر از داده های حجیم ارائه داده است . این تعریف میگوید که داده های حجیم باید سه شرط داشته باشند که به تئوری سه V معروف است. (البته تئوری چهار V یا اصل 4V و 8V هم وجود دارد که اهمیتی ندارد و در اصل لوس بازی های دانشمندان علم داده است. ضمنا به علت اینکه اکثر افراد کلمه 4V را جستجو میکنند، برای عنوان مطب عبارت 3V انتخاب نشده است)
- Volume (حجم خیلی زیاد داده)
- Variety (تنوع داده و عدم ساختار)
- Velocity (شتاب ذخیره و بازیابی داده)
نکته با اهمیت: برخی از NOSQL ها هر سه V را پشتیبانی نمی کنند. به عنوان مثال MongoDB شرط Variety را به خوبی پشتیبانی میکند و شرط Volume را ناقص و شرط Velocity را اصلا پشتیبانی نمیکند و پایگاه داده Neo4j فقط شرط Variety را پشتیبانی میکند و پایگاه داده کاساندرا هر سه شرط را به خوبی پشتیبانی میکند.

Volume یا حجم داده ها: از سال 2012، تقریبا روزانه 2.5 اگزابایت داده تولید میشود و این مقدار، هر 40ماه، دوبرابر میشود. این امر سبب میشود تا شرکتها با چندین پتابایت داده در یک مجموعه دادهای واحد سروکار داشته باشند. برای نمونه، تخمین زده میشود که والمارت، هر ساعت 2.5 پتابایت داده از تراکنشهای مشتریانش، جمعآوری میکند. همچنین، موفقیت شبکههای اجتماعی، موجب تولید حجم عظیمی از محتوا شده است؛ برای نمونه، توییتر، روزانه به تنهایی 12ترابایت داده تولید میکند.
Variety یا تنوع داده ها: (دوره دادههای غیرساخت یافته)– منابع دادههای عظیم میتواند از چندین مبدا و در شکلهای ناهمگون مانند، پیامها، بهنگامسازیها و تصاویر ارسالشده در شبکههای اجتماعی، سیگنالهای GPS از گوشیهای سلولی و غیره باشد. بعلاوه این دادهها فاقد شِما هستند .
Velocity یا سرعت رشد داده ها: در بسیاری از کاربردها، سرعت تولید دادهها، از حجم دادهها مهمتر است. اطلاعات بیدرنگ یا نزدیک به بیدرنگ، موجب میشود تا سرعت عمل، عامل سوددهی یک شرکت و سبقت از شرکتهای رقیب باشد. بدین منظور، تمرکز از مجموعه های داده ای(دسته ای) به داده های جریانی سوق پیدا میکند .عبارت جریان، به معنای پردازش برخط و ادامه دار است که دو رویکرد جهت پیادسازی تحلیل داده های جریانی وجود دارد:
- شکستن داده جریانی ورودی به دسته های کوچکی از داده ورودی که در کتابخانه Spark Streaming این تکنیک استفاده میشود.
- بارِکاری رویدادگرا که در Storm این تکنیک بکارگرفته میشود.
Value یا ارزش داده: پیش از تصمیمگیری برای ذخیره دادهه ای عظیم، باید مشخص گردد که آیا این داده ها ارزشمند هستند و پردازش، تحلیل یا حتی فروش آنها بصورت خام، موجب درآمدزایی برای شرکت میشود یا خیر.
نکته مهم: البته این V و سایر Vهای بعد از آن از اهمیت سه V اول برخوردار نیست و صرفا بر اساس سلقه اشخاص مختلف اضافه شده است. برای همین تعریف گارتنر از 3V همچنان در سطح وسیعی مورد استفاده قرار میگیرد، و در توافقات یک تعریف پذیرفته شده وجود دارد که بیانگر این است که ” کلانداده بیانگر داراییهای اطلاعاتی است که دارای خصوصیاتی از قبیل حجم بالا، فناوری و سرعت و تنوع نیاز به روشهای آناکاویی مخصوص برای اطلاعات مربوط به ارزش، میباشد.

گاهی از V پنجمی و بیشتری نام برده میشود که در ادامه به توضح آن ها میپردازیم و البته گاهی این خاصیت به عنوان خاصیت قبلی یعنی ارزش مطرح می شود.
Veracity یا صحت داد ها: با رشد سریع دادهها از نظر حجم و تنوع، احتمال وجود دادههای نادرست در آنها نیز افزایش مییابد. در نتیجه اگر ورودی قابل اعتماد نباشد، نمیتوان به اطلاعات استخراج شده از آن اعتماد کرد. در دنیای کسب وکار نیز، مدیران بطور کامل به اطلاعات اسخراج شده از دادههای عظیم، اعتماد نمیکنند.
اعتبار (Validity): با فرض اینکه دیتا صحیح باشد، ممکن است برای برخی کاربردها مناسب نباشد یا به عبارت دیگر از اعتبار کافی برای استفاده در برخی از کاربردها برخوردار نباشد.
نوسان (Volatility): سرعت تغییر ارزش داده های مختلف در طول زمان میتواند متفاوت باشد. در یک سیستم معمولی تجارت الکترونیک، سرعت نوسان داده ها زیاد نیست و ممکن است داده های موجود مثلا برای یک سال ارزش خود را حفظ کنند، اما در کاربردهایی نظیر تحلیل ارز و بورس، داده با نوسان زیادی مواجه هستند و داده ها به سرعت ارزش خود را از دست میدهند و مقادیر جدیدی به خود می گیرند. اگرچه نگهداری اطلاعات در زمان طولانی به منظور تحلیل تغییرات و نوسان داده ها حائز اهمیت است. افزایش دوره نگهداری اطلاعات، مسلما هزینه های پیاده سازی زیادی را دربر خواهد داشت که باید در نظر گرفته شود.
نمایش (Visualization): یکی از کارهای مشکل در حوزه کلان داده، نمایش اطلاعات است. اینکه بخواهیم کاری کنیم که حجم عظیم اطلاعات با ارتباطات پیچیده، به خوبی قابل فهم و قابل مطالعه باشد از طریق روش های تحلیلی و بصری سازی مناسب اطلاعات امکان پذیری است.

چالش های حوزه کلان داده
در بحث کلان داده، ما نیاز داریم که داده ها را به منظور استخراج اطلاعات، کشف دانش و در نهایت تصمیم گیری در خصوص مسائل مختلف کاربردی به صورت صحیح مدیریت کنیم. مدیریت داده ها عموما شامل 5 فعالیت اصلی میباشد.
- جمع آوری
- ذخیره سازی
- جستجو
- به اشتراک گذاری
- تحلیل
تا کنون چالشهای زیادی در حوزه کلان داده مطرح شده است که تا حدودی از جنبه تئوری ابعاد مختلفی از مشکلات این حوزه را بیان میکنند.
انواع داده در حوزه کلان داده
دادههای موجود در دنیای امروز را میتوان به ۳ بخش تقسیم کرد:
- دادههای ساختاریافته
- دادههای نیمه ساختیافته
- دادههای بدون ساختار
دادههای ساختاریافته: دادهها میتوانند در فرمت ثابتی که “دادههای ساختاریافته” نامیده میشوند، ذخیره و پردازش شوند. یک نمونه از دادههای ساختاریافته، دادههایی هستند که در سیستم مدیریت پایگاه داده رابطهای (RDBMS)، ذخیره میشوند. پردازش دادههای ساختاریافته آسان است، چرا که این نوع دادهها دارای شِمای ثابتی هستند. اغلب اوقات از زبان پرس و جوی SQL برای مدیریت این نوع دادهها استفاده میشود.
دادههای نیمه ساختیافته: دادههای نیمه ساختیافته، دادههایی هستند که ساختار رسمی “مدل داده” را ندارند، یعنی فاقد تعریف جدول در یک پایگاه داده رابطهای هستند. با این وجود، این نوع دادهها از برخی ویژگیهای سازمانی، همچون تگها و برخی نشان گذارهای دیگر که برای جدا کردن عناصر معنایی، که تجزیه و تحلیل دادهها را سادهتر میکند، بهره میبرند. فرمتهای داده XML و مستندات JSON دو نوع از متداولترین دادههای نمیه ساختاریافته هستند
دادههای بدون ساختار: دادههایی هستند که شکل و ساختاری مشخصی ندارند و به همین جهت RDBMSها راهحل مناسبی برای ذخیره، تجزیه و تحلیل این دادهها نیستند. فایلهای متنی و محتویات چندرسانهای همچون تصاویر، فایلهای صوتی و ویدئوها، نمونههایی از دادههای بدون ساختار هستند. سرعت رشد دادههای بدون ساختار بیشتر از دیگر دادهها است و طبق نظر کارشناسان ۸۰% دادههای یک سازمان، بدون ساختار هستند. پایگاه دادههای غیر رابطهایی(NoSql) یکی از دسته ابزارهایی هستند که میتوانند برای ذخیره و پردازش این نوع از دادهها بکار روند.
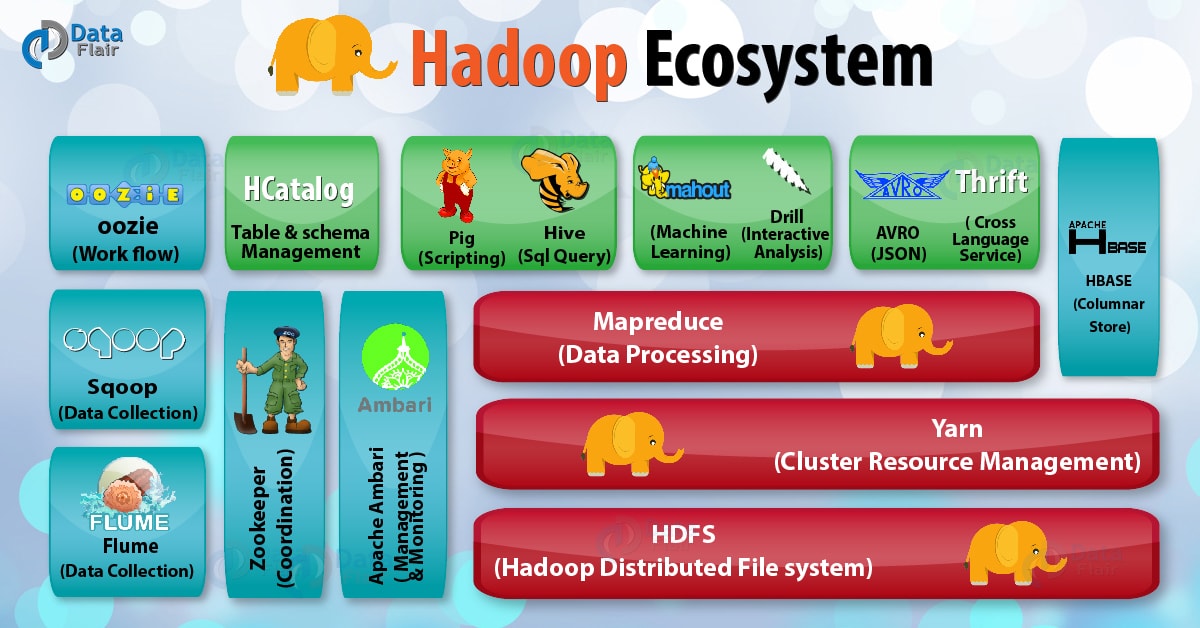
هدوپ به عنوان اولین انتخاب سامانه های عمومی پردازش کلان داده
بعد از حدود 20 سال از معرفی هدوپ به عنوان اولین سامانه عمومی پردازش کلان داده، این اکوسیستم به بلوغ رسیده است به گونهای که امروز با معرفی نسخه ۳ هدوپ، بسیاری از اشکالات و نواقص آن برطرف شده است. در این بین، نحوه ذخیره فایلها در اکوسیستم هدوپ هم بسیار متنوع شده است و برای سامانه های تحلیلی امروزی، آشنایی با قالب فایلهای موجود و معایب و مزایای هر کدام، یک ضرورت است. توضیح اینکه برای پردازش انبوه دادهها (batch)، هدوپ از سه مولفه اصلی زیر تشکیل شده است:
- سیستم فایل توزیع شده (HDFS)
- مدیریت تخصیص و پایش مداوم منابع مانند پردازنده، هارد، حافظه و مانند آنکه باید به صورت توزیع شده مدیریت شود (YARN)
- بخش پردازش و تحلیل اطلاعات (توزیع و تجمیع – Map/Reduce)
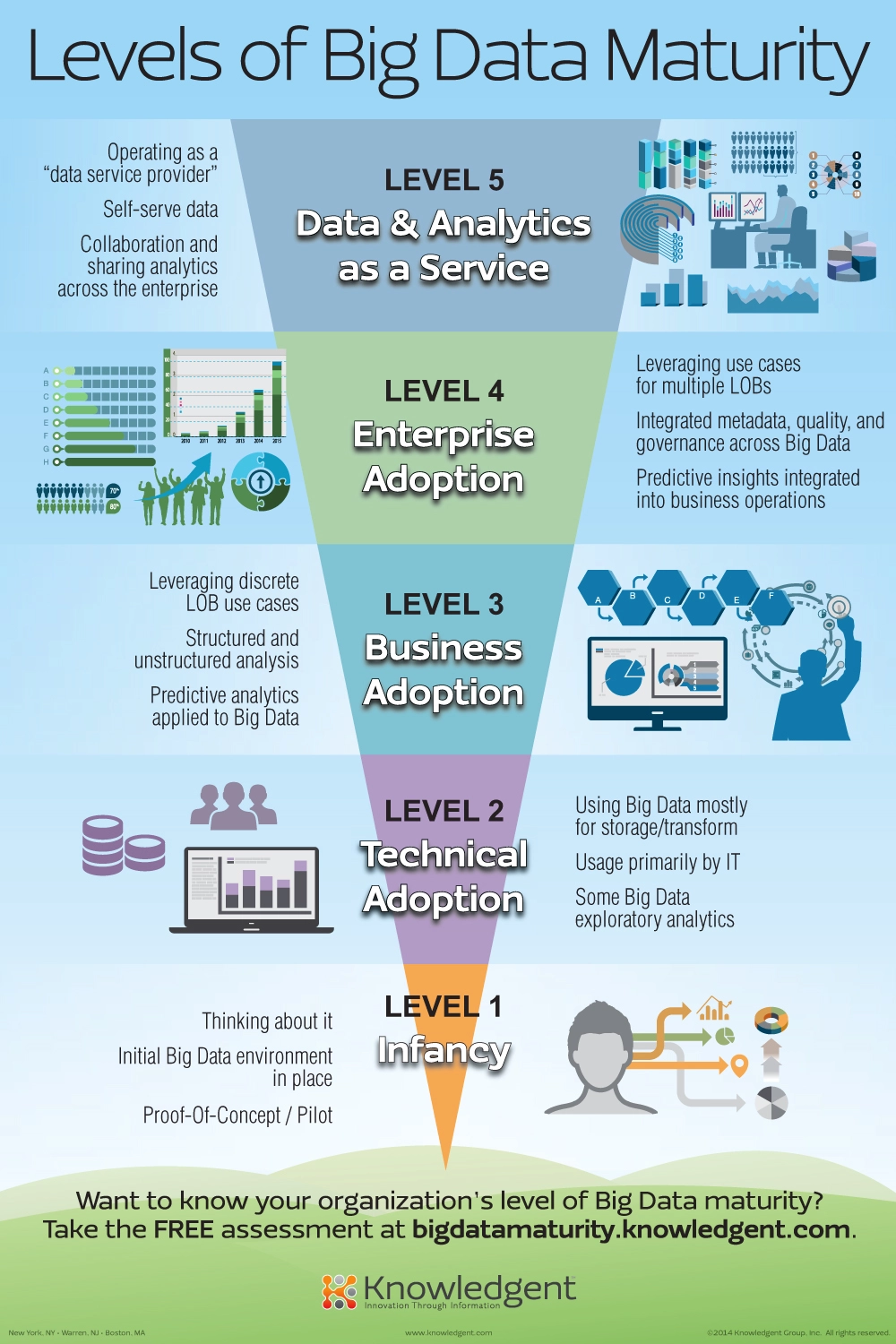
سطوح بلوغ بیگ دیتا
توسعه و اجرای استراتژی کلان داده برای سازمان ها کار آسانی نیست، به خصوص اگر فرهنگ داده محور نداشته باشند. چنین فرهنگی یک پیش نیاز برای اجرای موفقیت آمیز یک استراتژی کلان داده است و قبلاً نقشه راه Big Data را برای رسیدن به چنین فرهنگی به اشتراک گذاشته ام.
بر اساس این نقشه راه، راه درست برای شروع با Big Data این است که درک روشنی داشته باشید که چیست و چه کاری می تواند برای سازمان شما انجام دهد و از آنجا به بعد شروع به توسعه Proof of Concepts با یک تیم چند رشته ای کنید. این اولین اثبات مفاهیم برای شرکت شما و داده محور شدن حیاتی است و بنابراین باید بین همه کارکنان به اشتراک گذاشته شود. از آنجا به بعد، به آرامی می توانید داده محورتر شوید.
اینفوگرافیک زیر که توسط Knowledgent ایجاد شده است، پنج سطح بلوغ کلان داده را در یک سازمان نشان می دهد. سطح اول را مرحله نوزادی می نامند، مرحله ای که در آن فرد شروع به درک داده های بزرگ و توسعه اثبات مفاهیم می کند. سطح دومی که آنها شناسایی کرده اند، مرحله پذیرش فنی است، به این معنی که شرکت برای پیاده سازی فناوری های مختلف Big Data آماده می شود. این فناوریها، چه در محل و چه در فضای ابری، سازمان را قادر میسازد تا Proof of Concepts / محصولات یا خدمات کلان داده جدید را سریعتر و بهتر توسعه دهد.
هنگامی که بخش فناوری اطلاعات قادر به کار با فناوریهای کلان داده باشد و کسبوکار بفهمد که دادههای بزرگ میتواند برای سازمان انجام دهد، یک سازمان وارد سطح 3 شاخص بلوغ کلان داده میشود. پذیرش کسب و کار منجر به تجزیه و تحلیل عمیق تر داده های ساختاریافته و بدون ساختار موجود در شرکت می شود که منجر به بینش بیشتر و تصمیم گیری بهتر می شود.
سطح 4 پذیرش کلان داده در سراسر سازمان است و منجر به بینش پیش بینی یکپارچه در مورد عملیات تجاری می شود و جایی که تجزیه و تحلیل داده های بزرگ به بخشی جدایی ناپذیر از فرهنگ شرکت تبدیل شده است. این سطح آخرین سطح قبل از یک سازمان کاملاً مبتنی بر داده است که به عنوان “ارائه دهنده خدمات داده” عمل می کند. شرکتهایی که به سطح 5 شاخص بلوغ کلان دادهها رسیدهاند، تجزیه و تحلیل دادههای بزرگ را در تمام سطوح سازمان خود ادغام کردهاند، واقعاً دادهمحور هستند و صرفنظر از محصول یا خدماتی که ارائه میدهند، میتوانند به عنوان «شرکتهای داده» دیده شوند. آنها بر اساس بینش Big Data خود به طور قابل توجهی از رقبای خود بهتر عمل خواهند کرد.
همه شرکت ها باید برای سطح 5 از شاخص بلوغ کلان داده تلاش کنند زیرا این امر منجر به تصمیم گیری بهتر، محصولات بهتر و خدمات بهتر می شود.
منابع:
http://spark.apache.org/docs/latest/streaming-programming-guide.html
bigdata.ir
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 11998
برچسبBig Data Variety Velocity Volume آپاچی اصل 4V اصل چهار 4V بیگ دیتا تئوری 4V تعریف داده های حجیم تعریف کلان داده تنوع داده حجم داده حجم دادها خصوصیات کلان داده خصوصیت 4V داده های حجیم سرعت رشد داده کلان داده کلان داده چیست هدوپ ویژگی 4V ویژگی های کلان داده
نوشته های مرتبط











همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …

تحلیل گراف های بزرگ با آپاچی فلینک (Apache Flink)
تعریف جریان داده: جریان داده ها، داده هایی هستندکه بطور مداوم توسط هزاران منبع داده …
یک دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

عنوان کتاب : داده های بزرگ برای همه
ناشر : ناقوس
سال نشر : 1397
عنوان اصلی :Big Data for Dummies
نویسنده: Judith S. Hurwitz
انتشارات : John Wiley & Sons, Inc