 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
پارس کردن صفحات وب با کتابخانه beautifulsoup پایتون
معرفی کتابخانه beautifulsoup پایتون : به منظور تجزیه کردن یا پارس کردن صفحات وب با پایتون (فایل های HTML) میتوان از این کتاب خانه استفاده کرد. همچنین از این کتابخانه میتوان برای تجزیه کردن فایل های XML استفاده کرد.
مفاهیم کتابخانه beautifulsoup به منظور تجزیه کردن یا پارس کردن
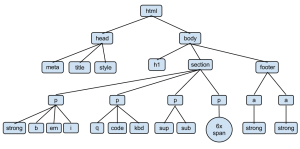
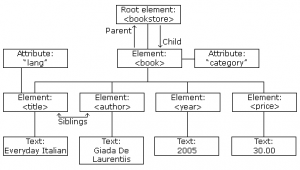
کتابخانه beautifulsoup یک کتابخانه پایتون است که بمنظور استخراج داده از فایلهای html و xml مورد استفاده قرار می گیرد. این کتایخانه صفحات مورد نظر خودرا بصورت یک درخت تجزیه میکند. درخت تجزیه این امکان را برای برنامه ایجاد میکند، که هرگونه دسترسی به عناصر صفحه html با سرعت بیشتری امکانپذیر گردد. بااین روش شرایط مناسبی برای جستجوی اطلاعات مورد نظر فراهم می شود. در زیر نحوه تجزیه عناصر صفحه xml در قالب درخت نمایش داده شده است.
- نصب و راه اندازی
در این مقاله فرض کردهایم که شما آشنایی کامل با کتابخانه اسکرپ پایتون دارید. در غیر اینصورت به مقاله کتابخانه پایتون برای وب اسکرپ (web scraping) مراجعه کنید.
به بکی از دو روش زیر کتابخانه beautifulsoup را نصب می کنیم:
- با استفاده از دستور pip
c:\>pip install beautifulsoup4
- با استفاده از کد کتابخانه
فایل برنامه را ازاین آدرس دانلود و با استفاده از دستور بعدی آن را نصب کنید:
http://www.crummy.com/software/BeautifulSoup/download/4.x/
C:\>python setup.py install
برنامه نمونه پارس کردن صفحات وب با پایتون
در ادامه مقاله براساس یک نمونه برنامه با برخی از توانمندیهای این کتابخانه آشنا می شویم:
- نمونه یک فایل html را که در متغیر html_doc قرار داده شده است درزیر مشاهده می کنید:
"""= html_doc <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """
با استفاده از کتابخانه bs4 یک شیء از کلاس BeautifulSoup با هدف تجزیه متغیر html_doc تعریف می کنیم:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, ‘html.parser’)
تابع prettify نمایش زیبایی از درخت html موجود در متغیر html_doc را در خروجی نمایش می دهد:
print(soup.prettify())
# <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p class="title"> # <b> # The Dormouse's story # </b> # </p> # <p class="story"> # Once upon a time there were three little sisters; and their names were # <a class="sister" href="http://example.com/elsie" id="link1"> # Elsie # </a> # , # <a class="sister" href="http://example.com/lacie" id="link2"> # Lacie # </a> # and # <a class="sister" href="http://example.com/tillie" id="link2"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p class="story"> # ... # </p> # </body> # </html>
جدول زیر شامل اطلاعاتی است که با استفاده از شیء ایجاد شده از کلاس BeautifulSoup میتوان از صفحه مورد نظر استخراج کرد:
| خروجی برنامه | شرح کد | ویژگی شیء | ردیف |
| <title>The Dormouse’s story</title> | تگ عنوان صفحه را بطور کامل نمایش می دهد: | soap.title | 1 |
| u’title’ | نام تگ عنوان صفحه را نمایش می دهد: | soup.title.name | 2 |
| u’The Dormouse’s story’ | محتوای تگ عنوان صفحه را نمایش می دهد: | soup.title.string | 3 |
| u’head’ | نام تگ پدر ، تگ عنوان صفحه را نمایش می دهد: | soup.title.parent.name | 4 |
| <p class=”title”><b>The Dormouse’s story</b></p> | اولین تگ پاراگراف موجود در صفحه را نمایش می دهد: | soup.p | 5 |
| u’title’ | نام کلاس استایل، اولین تگ پاراگراف موجود در صفحه را نمایش می دهد: | soup.p[‘class’] | 6 |
| <a class=”sister” href=”http://example.com/elsie” id=”link1″>Elsie</a> | اولین تگ لینک موجود در صفحه را نمایش می دهد: | soup.a | 7 |
|
[<a class=”sister” href=”http://example.com/elsie” id=”link1″>Elsie</a>,
<a class=”sister” href=”http://example.com/lacie” id=”link2″>Lacie</a> <a class=”sister” href=”http://example.com/tillie” id=”link3″>Tillie</a>] |
تمام تگ های لینک موجود در صفحه را در قالب لیست پایتون نمایش می دهد: | soup.find_all(‘a’) | 8 |
| <a class=”sister” href=”http://example.com/tillie” id=”link3″>Tillie</a> | تگ با شناسه موردنظر را جستجو می کند: | soup.find(id=”link3″) | 9 |
|
http://example.com/elsie http://example.com/lacie http://example.com/tillie |
تمامی لینک های صفحه را استخراج می کند: | for link in soup.find_all(‘a’): print(link.get(‘href’)) | 10 |
|
The Dormouse’s story
The Dormouse’s story
Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well.
…
|
قطعه کد زیر تمام متن صفحه را استخراج می کند: | print(soup.get_text()) | 11 |
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
منبع:
http://web.stanford.edu/~zlotnick/TextAsData/Web_Scraping_with_Beautiful_Soup.html
بازدیدها: 10649
برچسبparser python پارس کردن صفحات وب پارس کردن صفحات وب با پایتون پارس کردن فایل های XML پارسر پارسر پایتون تجزیه کردن صوحات وب با پایتون تجزیه کردن فایل های HTML تجزیه کردن کتابخانه beautifulsoup پایتون کتابخانه beautifulsoup پایتون
نوشته های مرتبط
همچنین ببینید
تجزیه گر یا پارسر متون و تشخیص زبان با آپاچی تیکا (Apache Tika)
آپاچی تیکا: آپاچی تیکا يکي از پروژههاي متن باز Apache است که کلاسي براي شناسايي …
