 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
معماری لامبدا در مقابل معماری کاپا برای بیگ دیتا و پردازش سريع درData Lake
تولید بیوقفه دادهها در دنیای امروز، نیاز به پایش لحظهای و سریع اطلاعات در کنار ذخیره آنها برای پردازشهای تحلیلی، ما را به سمت ساختاری هدایت میکند که بتواند هر دو وجه از این نیازمندی یعنی پردازش جریانهای داده به صورت لحظهای و بدون تاخیر وپردازشهای انبوه و زمانمند را پاسخگو باشد.
عناوين مطالب: '
معماری لامبدا
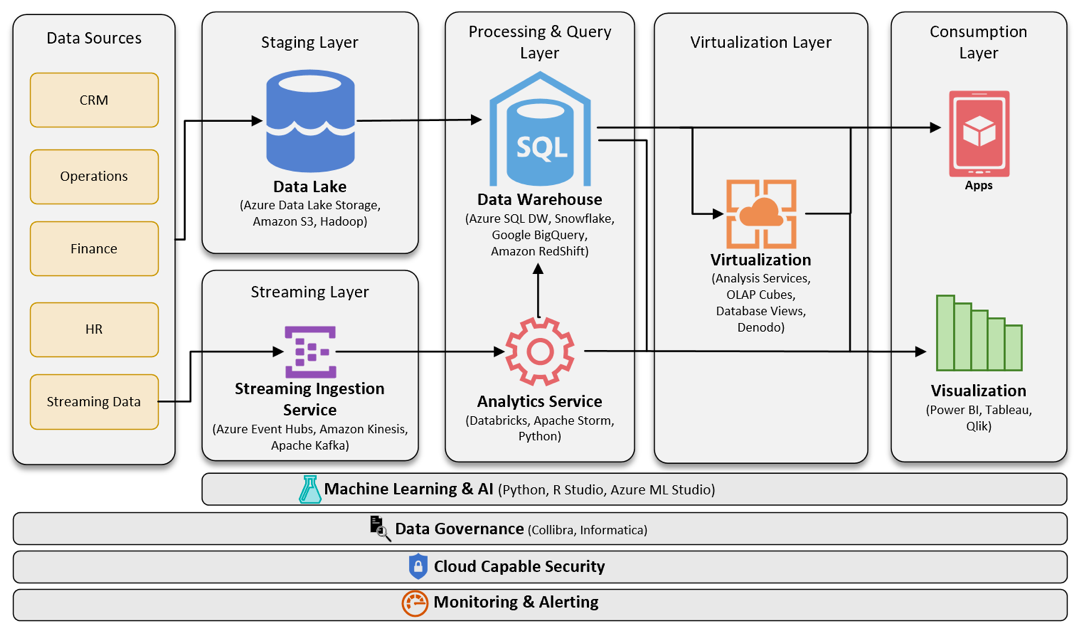
توییتر مثال خوبی از معماری لامبدا است. در این معماری دادهها به دو مسیر تقسیم میشوند. گروهی از دادهها بهمنظور تغذیه لایه سرعت بهمنظور ارائه بینش سریع مورد استفاده قرار میگیرند، در حالی که گروه دیگری از دادهها به لایه “سرویسدهی” انتقال داده میشوند. در این معماری، دادههای جریانی واردشونده به سیستم بهمنظور تغذیه دولایه batch و speed مورد استفاده قرار میگیرند. معماری لامبدا دقیقاً با همین پیشزمینه توسط Nathan Marz از متخصصین داده شرکت توئیتر پیشنهاد شد. شکل زیر ساختار این معماری سه لایه را نشان میدهد.
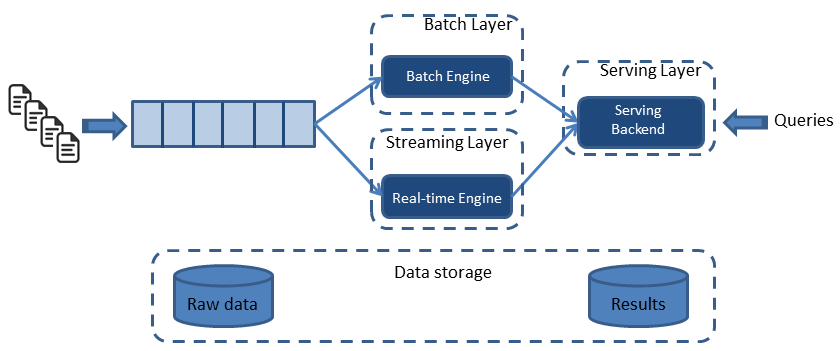
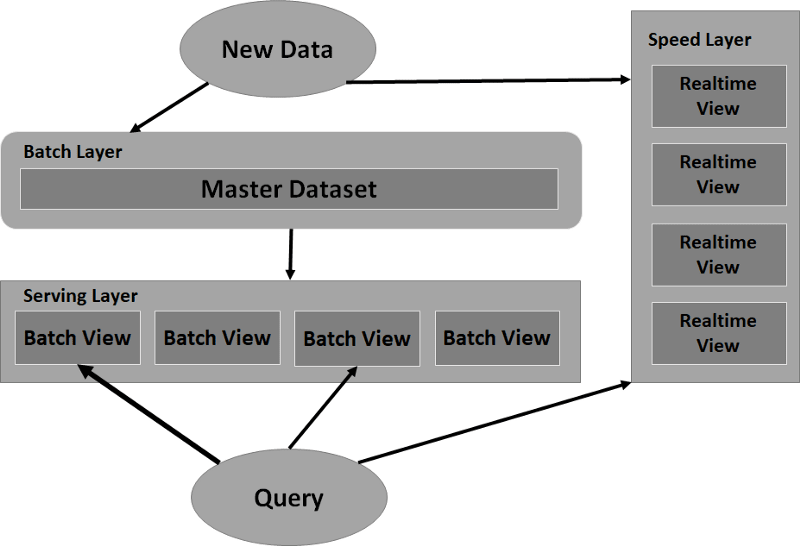
لایه پردازش زمانمند(یا پردازش انبوه – Batch Layer)
که بسته به نیاز کاربربه صورت موردی ویا در زمان های مشخص اقدام به پردازش انبوه داده های ذخیره شده کرده و نتایج مورد نظر کاربر را تولید میکند. استخراج آمار روزانه خرید و فروش یا اجرای یک جستجوی خاص بر روی داده ها از جمله موارد کاربرد این لایه است.
لایه پردازش سریع (Speed Layer):
تمام پردازش هایی که باید به صورت لحظه ای روی داده ها صورت بگیرند، در این لایه پیاده سازی میشوند. محاسبه آمار لحظه ای یک سایت، پیشنهاد سریع یک مطلب جدید به کاربر بر اساس سابقه و سلایق او، بررسی خطاهای رخداده در سرورها و اتخاذ تصمیم مناسب از جمله مثالهایی است که میتوان برای کاربردهای لایه پردازش سریع زد.
لایه کاربست و کاربرد (Serving Layer):
این لایه، وظیفه سرویس دهی به کاربر، اجرای پرس و جوهای مختلف (کوئری) و آماده سازی داده در شکل های مورد نیاز او را برعهده دارد. داده هایی که در دولایه پردازش سریع و پردازش زمانمند قبلاً ذخیره شده اند، توسط سرویسهایی که در این لایه ایجاد میشوند، در اختیار کاربران مختلف که هرکدام قالب و شکل خاصی از داده ها و گزارشات را نیاز دارند، قرار میگیرد.
این سه لایه، حداقل نیازمندی هایی است که یک سامانه پردازش اطلاعات باید داشته باشد. در ادامه سایر مولفه هایی که میتواند باعث بهبود این این چارچوب و تطبیق بیشتر آن با دنیای معاصر باشد را معرفی خواهیم کرد.
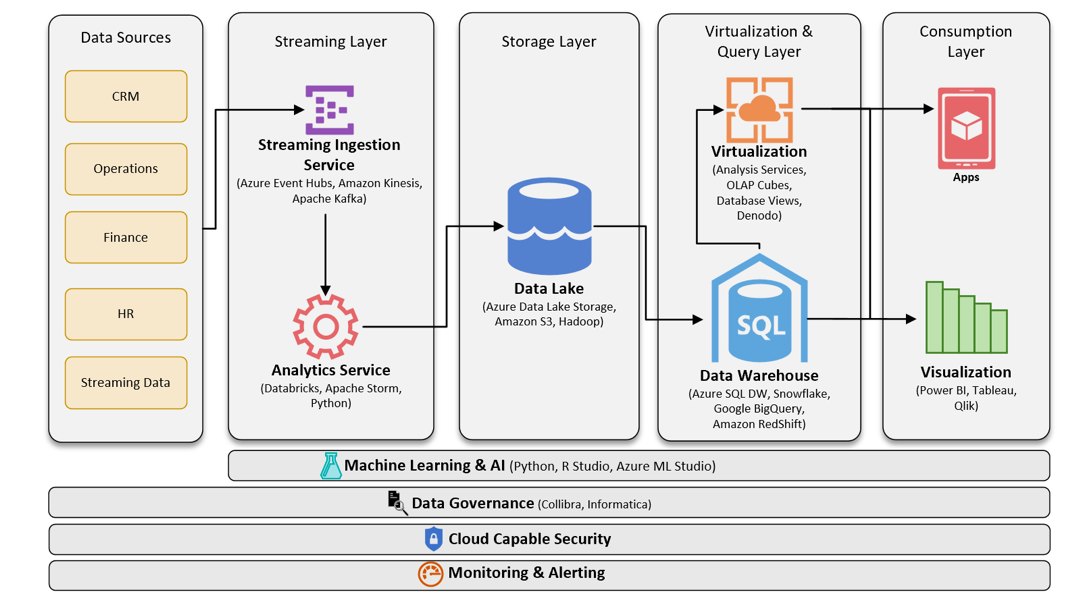
معماری کاپا
مینتون میگوید: «مدل فوق به یک سازمان اجازه میدهد به هر دو رویکرد بینش جریانی و انبوه دسترسی پیدا کند و در نتیجه میان استریمها تعادل برقرار میکند. چالشی که در ارتباط با این معماری وجود دارد این است که شما همزمان دو نوع کدنویسی و دو برنامه را باید مدیریت کنید.» معماری کاپا همه چیز را در قالب یک جریان نشان میدهد، اما جریانی است که هدفش حفظ اعتبار دادهها و ارائه پردازش بیدرنگ است. همه دادهها به یک ورودی تغییرناپذیر نوشته میشوند و در ادامه تغییرات با این دادههای تغییرناپذیر مورد ارزیابی قرار میگیرند. این رویکرد مؤثر است، بهواسطه آنکه به کدنویسی کمتری احتیاج دارد و همچنین مدلی را ارائه میکند که به اعتقاد مینتون برای سازمانی که تازه کار خود را با بزرگ دادهها آغاز کرده مناسب است.
در حقیقت شکل خلاصه شده ای از معماری لامبدا با حذف لایه پردازش زمانمند به وجود آمده است که به معماری کاپا معروف شده است. در این ساختار برای ساده تر شدن مدیریت سامانه و عدم نیاز به دو بخش جداگانه پردازشی، تمام پردازش ها در لایه پردازش سریع انجام میگیرد و هرکاری که قرار است روی داده ورودی انجام شود، به صورت لحظه ای و بلادرنگ صورت خواهد پذیرفت. در نتیجه، معماری کاپا تنها در کاربردهایی به عنوان جایگزین لامدا مطرح میشود، که نیازی به زمان نگهداری نامحدود نباشد و یا اجازه متراکم کردن مؤثر وجود داشته باشد (به عنوان مثال، زمانیکه منطقی است تنها جدیدترین مقدار برای هر کلید و یا موجودیت در برنامه نگهداری شود).
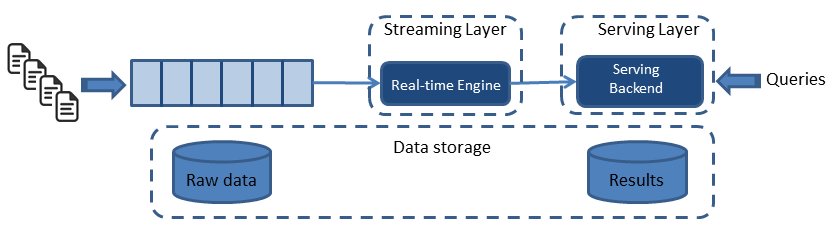
اصول معماري کاپپا
اگر در آینده و بخاطر تغییر در منطق سازمانی و قوانین، نیاز به پردازش جدیدی روی داده ها باشد، این کار به صورت جداگانه و موردی انجام خواهد شد.
برای نیل به این هدف، معماری Kappa بر چهار اصل استوار است:
- هرچیزی، یک جریان است: با این اصل، پردازش زمانمند و انبوه هم جزئی از سامانه پردازش جریان قرار میگیرد با این تفاوت که داده های زمانمند و غیر لحظه ای، جریان های موردی تولید خواهند کرد که نیاز به پردازش دارد.
- تمام داده ها به صورت پایدار ذخیره میشوند: این اصل، تضمین میکند که داده ای از دست نمیرود و می توان در صورت نیاز، تمام محاسبات را از ابتدا بر روی داده ها انجام داد.
- تنها یک چارچوب برای پردازش مورد نیاز است: با توجه به اصل سادهسازی امور (KISS)، در این معماری تنها یک سامانه پردازشی خواهیم داشت که مدیریت و توسعه آن بسیار ساده تر است.
- تکرارپذیری عملیات پردازش داده : محاسبات و نتایج میتواند با ورود دادههای جدید و ترکیب آنها با دادههای قبلی، بهروز شود.
با این وجود، این معماری بیشتر برای کابردهایی مناسب است که منطق سازمانی حاکم بر آنها کاملاً مشخص و تقریباً بدون تغییر است. مثلاً برای بررسی و پردازش خطاهای نرم افزار و همچنین پایش وضعیت سرورها، میتوان از این معماری استفاده کرد چون غالب تصمیمات باید در لحظه گرفته شود و آمار مورد نیاز هم در همان حین دریافت اطلاعات قابل استخراج و ذخیرهسازی است. با این توضیح، معماری کاپا محدودیت بیشتری دارد و شکل خلاصه شده ای از معماری لامبدا است و برای سامانههای عمومی اطلاعاتی، معماری لامبدا که جامعتر بوده و امکان استفاده از ابزارهای بیشتری را فراهم میکند، ترجیح داده میشود. معماری پیشنهادی برای پایش شبکههای اجتماعی هم بر این معماری، متکی خواهد بود.
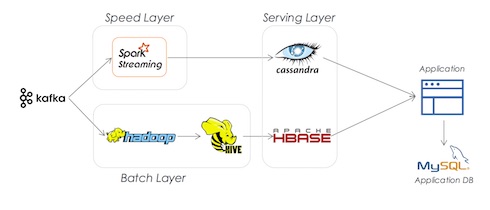
مثالی از تفاوت دو معماری
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
منابع:
https://www.oreilly.com/ideas/applying-the-kappa-architecture-in-the-telco-industry
https://www.shabakeh-mag.com/cover-story/10793/شش-پرسشی-که-هر-کسب-%E2%80%8Cو-کاری-باید-درباره-معماری-بزرگ-داده%E2%80%8Cها-مطرح-کند
www.bigdata.ir.
datastack.ir/big-data/ُstreaming-data/پردازش-داده%E2%80%8Cهای-جریانی-در-محیط%E2%80%8Cهای-ک/
Views: 1968
برچسبLambda architecture استريم بچ بيگ ديتا پردازش جرياني داده هاي حجيم دریاچه داده کلان داده معماري معماری کاپا معماری لامبدا معماری لامبدا در مقابل معماری کاپا
نوشته های مرتبط













همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …

امکانات و ویژگیهای جدید SQL Server در نسخه های مختلف
Microsoft SQL Server یا MSSQL چیست؟ در پاسخ نرم افزار sql server چیست بایستی گفت …
