 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
مدل داده ای ستون گرا و تعریف شِمای مبتنی بر ستون در کاساندرا
پایگاه داده های ستون گرا به طور بالقوه می توانند به عنوان یک انبار داده استفاده شوند که قادر است به طور طبیعی پرس و جوهای OLAP را اداره کند. این روش در سال 2012 در مطالعات مختلف ارائه شده است و اکنون محبوبیت زیادی پیدا کرده است. تا جایی که منجر به ظهور انبارهای داده ابری ستون محور شد.
Cassandra از دسته پايگاه دادهاي ستون گرا است. این پایگاه داده ها که داده ها را به جای اینکه به صورت سطر به سطر مشاهده کنند، به صورت ستون به ستون مشاهده و ذخیره سازی میکنند، مناسب برای کاربردهایی مانند پردازش داده های بزرگ و BigData هستند.
عناوين مطالب: '
دیدگاه مبتنی بر ستون در برابر مبتنی بر ردیف
پایگاه داده های رابطه ای مانند Sql Server به صورت پیش فرض داده ها را به صورت سطر (Row) ذخیره می کردند. اما در پایگاه داده های مبتنی بر ستون، داده ها ستونی ذخیره می گردند. ستون ها به صورت منتطقی در خانواده ای از ستون ها (Columns Family) ذخیره می شوند. در مقایسه با پایگاه داده های رابطه ای، این پایگاه داده ها برای تجمیع و جستجو در یک ستون خاص، سرعت به مراتب بالاتری دارند.
فرض کنید در یک پایگاه داده رابطه ای میخواهید از جمع شارژ ۱۰میلیون کاربر را داشته باشید. برای هر کاربر، ستون شارژ در مکان های مختلفی از حافظه ذخیره شده است و این مکان ها، پشت سر هم نیستند. ولی در پایگاه داده های مبتنی بر ستون، تمام این ستون ها پشت سره هم در حافظه ذخیره شده و سرعت دسترسی را به صورت ستونی بیشتر می کنند.
بسیاری از پایگاه داده هایی که برای کار با مه داده (Big Data) طراحی شده اند جز این دسته از پایگاه داده ها هستند. برای مثال Big Table از شرکت گوگل و یا HBase و همچنین Cassandra از جمله پایگاه داده های مبتنی بر ستون هستند.
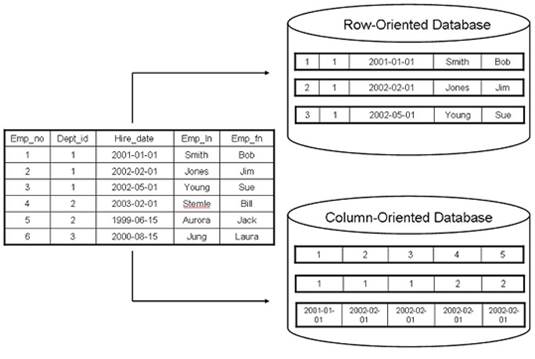
مدل مفهومی ذخیره در حافظه یا دیسک
در مقایسه بین سامانهها ردیفگرا و ستونگرا موضوع اصلی دسترسی مؤثر به دیسک سخت است. گاهی اوقات دسترسی به یک مگابایت ار دادهای پشتسر هم مانند دسترسی از نوع تصادفی است و یک زمان به طول میانجامد. اما از آنجا که طبق قانون مور، زمان جستجو همیشه کندتر از سرعت افزایش توان پردازندۀ مرکزی است، توجه به هارد دیسک برای افزایش سرعت جلب شدهاست. در ادامه تصویری از تفاوتها این دو ساختار ارائه داده خواهد شد.
در عمل، معماری سطرگرا برای سامانههای OLTP (مثل پایگاه داده های رابطه ای) بسیار مفیدتر است چراکه باز عظیمی کاری را برای تراکنشهای فعل و انفعالی فراهم مینماید. معماری ستونگرا برای سامانههای OLAP یا مکعب داده های مناسب است که دارای تعداد کمتری پرسشهای بسیار پیچیده بر روی تمام دادههاست که گاه حجم این دادهها تا چندین ترابایت داده هم میرسد. مانند ترادیتا
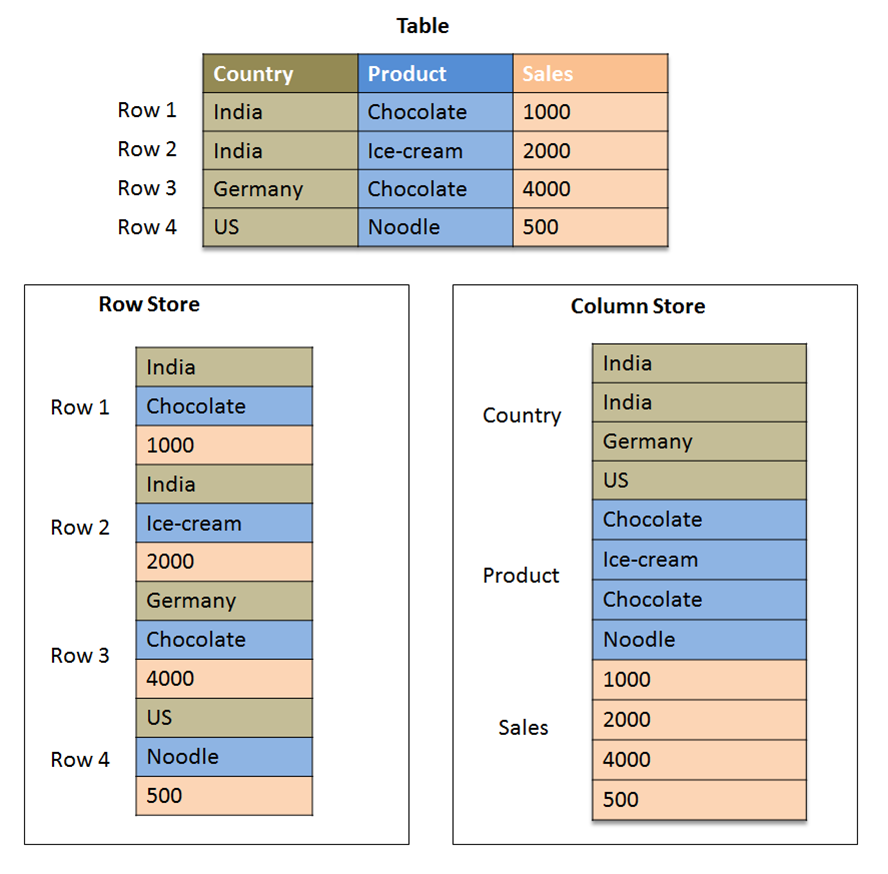
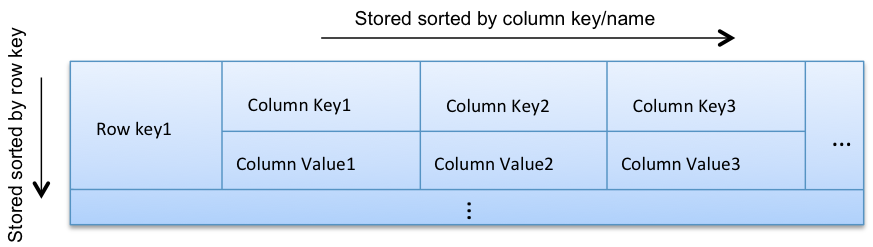
پایگاه داده های مبتنی بر ستون، داده ها را بجای اینکه در ردیف ذخیره کند، در ستون های گروه بندی شده ذخیره می کند و از مفهومی به نام keyspace استفاده می کند که مانند schema در پایگاه داده های رابطه ای می باشد. Keyspace شامل چندین گروه از ستون ها می باشد. گروه ستون ها مشابه جداول در یک مدل رابطه ای می باشد. اما به جای اینکه فقط شامل ردیف ها باشد یک گروه از ستون شامل ردیف هایی از ستون ها می باشد. هر ردیف در یک گروه ستون یک کلید منحصر به فرد دارد و هر ستون در یک ردیف شامل یک نام، مقدار و time stamp است.
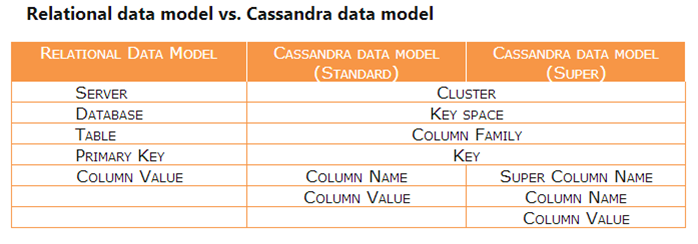
مقادیر نال و فرم نرمال سازی 4 در پایگاه داده های ستون گرا
از مزایای پایگاه داده های مبتنی بر ستون مقایسه داده ها، عملکرد بالا با توابع تجمعی (SUM، COUNT و غیره) و مقیاس پذیری می باشد. اما نوشتن داده های جدید در پایگاه داده های مبتنی بر ستون زمان بیشتری می گیرد. در پایگاه داده های مبتنی بر ردیف شما می توانید داده را تنها با یک عملیات بنویسید اما در پایگاه داده های مبتنی بر ستون باید در ستون ها به صورت یک به یک بنویسید. بنابراین پایگاه داده های مبتنی بر ستون برای پردازش داده ها با تعداد ستون های کم و تعداد ردیف های زیاد مناسب است.
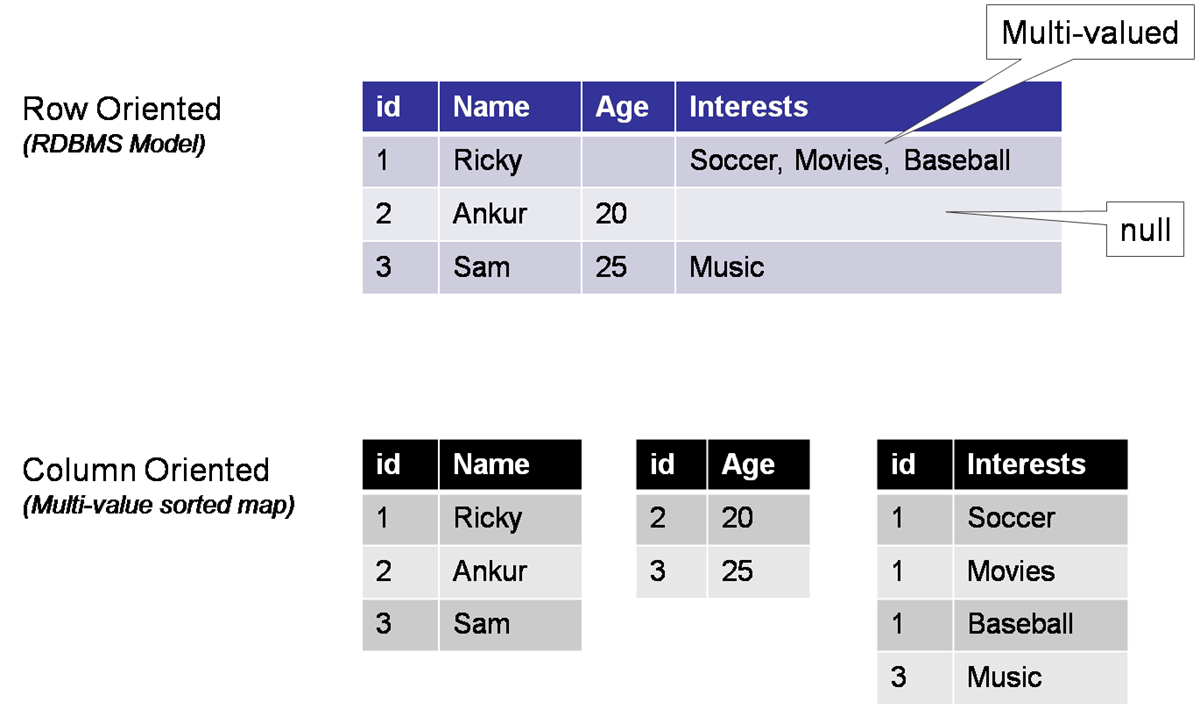
برای آشنایی با مدل دادهای ستون گرا در کاساندرا، بهتر است از درک مفاهیم ساده و ابتدایی برای ذخیرهسازی دادهها شروع کنیم. در ادامه با این مفاهیم آشنا می شوید.
آشنایی با مدل داده ستون گرا در کاساندرا
Cassandra یک پایگاه داده توزیع شده است. برای اینکه بدانید توزیع شدگی چیست، بهتر است درس سیستم توزیع شده چیست را مطالعه ای داشته باشید. این پایگاه داده برای مدیریت داده های بزرگ و مه داده (Big Data) کاربرد فراوانی دارد. Cassandra هیچ نقطه خاص خرابی (Single Point Of Failure) ندارد و به راحتی میتواند بر روی چندین کامپیوتر توزیع شود.
این پایگاه داده توسعه پذیر خطی (Linear Scalable) است و دسترس پذیری بالایی (High Availability) دارد. برای درک مفهوم توسعه پذیر خطی میتوانید این درس را مطالعه کنید. Cassandra برای کار با داده های بسیار بزرگ طراحی شده است تا کاربران بتوانند این داده ها را به راحتی و با سرعت بالا دریافت کنند.
در Cassandra از معماری Master/Slave استفاده نشده است. زیرا در این معماری معمولا گره Master (سرپرست) به دلیل کارکرد زیاد به گلوگاه سیستم (Bottleneck) تبدیل می شود. یعنی در صورتی که master از کار بیفتد یا کند شود، کل سیستم از کار می افتد یا کند می شود. برای همین در Cassandra چیزی به نام Master وجود ندارد و تمامی گره ها (کامپیوترها)ی متصل به هم، مانند یکدیگر رفتار می کنند. داده ها در گره های مختلف تکرار (Replicate) می شوند.
Cassandra از زبان پرس و جویی به نام CQL استفاده میکند که بسیار شبیه SQL است و برنامه نویسانی که میخواهند از SQL به Cassandra مهاجرت کنند، کار زیاد سختی در پیش ندارند.
ساختار ذخیره سازی آرایه ای تک بعدی
سادهترین حالت ذخیرهسازی دادهای با استفاده از یک آرایه یا لیست قابل پیادهسازی است. در این حالت، برای فهمیدن اینکه هر عنصر ذخیره کننده چیست، باید اسناد و دانشی درباره آن بهصورت خارجی نگهداری شود. همچنین، برای اینکه اندازه یک شکل کل مجموعه دادهای حفظ شود، باید مقادیر خالی را با مقادیری مشخص همانند(null) پر کرد. یک آرایه، بهطور ساده ساختار دادهای سودمندی است، اما از لحاظ معنایی، قوی نیست .

ساختار ذخیره سازی آرایه ای دو بعدی
با اضافه کردن یک بعد به ساختار دادهای قبلی، ساختاری جدید و با مفهومتر، مطابق آنچه در شکل زیر نشان داده شده، به دست میآید که حلال برخی مشکلات موجود در مدل قبلی است. بهعنوان مثال، هم اکنون میدانیم که کدام مقدار، نمایانگر چیست و به چه چیزی اشاره میکند.
با این حال، با این ساختار تنها میتوان به یک مفهوم (مثلاً یک شخص) اشاره شود و راهی برای ذخیرهسازی دادههای چندگانه (مثلاً اشخاص مختلف) در یک ساختار منفرد را در اختیار نخواهیم داشت. به بیان دیگر، ما به ستونهایی احتیاج داریم که در آنها نیاز نباشد تا نام آنها همواره تکرار شود و همچنین، به مفهومی نیاز داریم تا بتوانیم گروهی از ستونها را در یک قالب مفهومی دستهبندی کنیم.
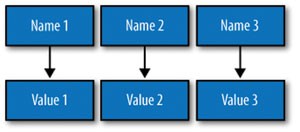
ساختار آرايه ای چند بعدی در Cassandra
راهحل ساده برای اضافه کردن مقادیر چندگانه به ستونها، سطرها هستند که میتوانند یک شناسه انحصاری به نام کلید سطر یا Row Key را نیز در اختیار داشته باشند. کاساندرا، مفهومی ستون گرا به نام Column Family را معرفی کرده که برای تقسیمبندی گروهی از ستونهای مرتبط با یکدیگر در نظر گرفتهشده است و مثالی از آن یک Column Family برای مشخصات اشخاص است. در اصل، مفهوم Column Family در کاساندرا به نوعی شبیه به مفهوم جدول در مدل سنتی رابطهای است. با کنار هم قرار دادن مباحث بالا، ساختار دادهای کلی کاساندرا ازاینقرار خواهد بود:
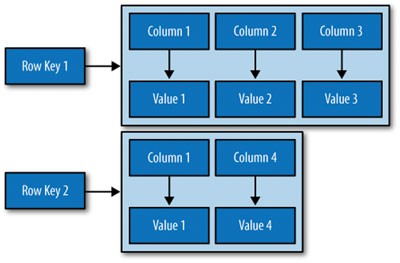
ستونها که جفتهای Name/Value هستند و Column Familyها که حاوی سطرهایی هستند که مجموعههای ستونی مشابه، اما نه دقیقاً یکسان با تعداد ستونهای موجود در سیستم، هستند. نکته مهم دیگری که در کاساندرا مطرح است آن است که برخلاف پایگاههای داده سنتی که در آنها نام ستونها باید تنها یک متغیر رشتهای باشد، نام ستونها و مقادیر ذخیرهشده در سطرهای مرتبط میتوانند علاوه بر نوع رشتهای، مقادیر Integer، UUID یا هر نوع آرایه بایتی دیگری نیز باشند. این قابلیت، امکان ذخیرهسازی دادههای ارزشمند در کلیدها (خود ستونها) را علاوه بر مقادیر آنها (سطرها) فراهم میسازد که کاربردهای پیشرفتهای ، بهخصوص در زمینه ایندکس کردن دارد.
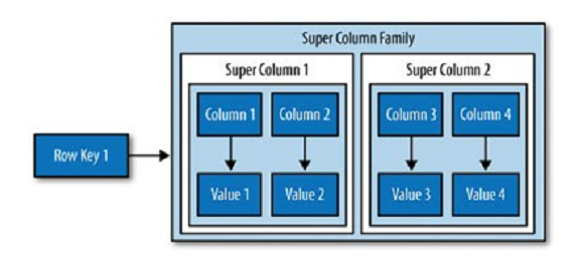
Super column
(اين روش در کاساندرا منقضي شده است) واحدهای دیگری نیز برای گروهبندی ساختار پایگاه داده وجود دارند که با نام Super Column شناخته میشوند. این اَبَرستونها، مجموعهای از ستونهای مرتبط را در یک Column Family شامل میشوند که میتوان از آنها به نقشه نقشهها تعبیر کرد. شکل زیرین نمایی از مدل دادهای کامل کاساندرا را نشان میدهد. به یاد داشته باشید که ستونها در کاساندرا در اصل یک بعد دیگر با نام timestamp نیز دارند که ذخیره کننده آخرین بهروزرسانی دادههای درون ستون است. این برچسب زمانی، مقداری خودکار و یک متادیتا نیست، بلکه مقداری است که باید توسط کلاینت فراهم شود و قابلیت پرسوجو نیز ندارد، بلکه برای جلوگیری از اختلاط دادهها مورد استفاده قرار میگیرد. توجه کنید، سطرها برچسب زمانی ندارند، بلکه تنها ستونهای منفرد برچسب زمانی را ذخیره میکنند.
هر کلاستر، نگهدارنده (یک یا چند) مفهوم کلی و انتزاعی با نام Keyspace است که بزرگترین مفهوم دادهای در کاساندرا به شمار میآید و معادل مفهوم Database در مدل RDBMS است. هر فضای کلیدی خصوصیات مختلفی (مانند فاکتور جایگزینی، راهبرد جایگزینی، Column Familyها و…) دارد که چگونگی رفتار آن را در کل کلاستر تعیین میکنند.
مفهوم بعدی، Column Familyها هستند که نگهدارنده مجموعه مرتبی از سطرهای دادهای است و هر کدام از آنها، حاوی مجموعه مرتبی از ستونهای دادهای هستند. مفهوم Column Family را میتوان به نوعی معادل جدولها در مدل رابطهای به شمار آورد، اما توجه کنید که با جدولها بسیار متفاوت هستند. با توجه به مفهوم کلید سطر و مفهوم ستون که در بخش قبل نیز مطرح شدند، به ساختار ۴ بعدی معمول در کاساندرا خواهیم رسید که نقشی اساسی را در دسترسی به دادهها ایفا میکند:
[Keyspace][ColumnFamily][Key][Column]
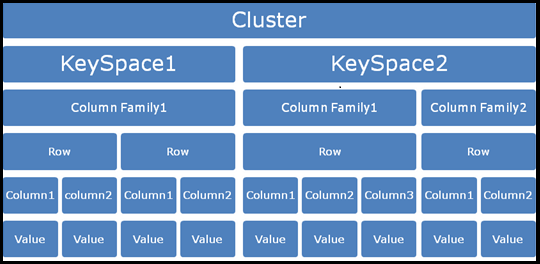
برای روشن شدن مطلب، میتوانیم یک مثال برای ذخیره دادهها در کاساندرا مطرح کنیم. برای این منظور، یک Column Family با نام Hotel برای ذخیرهسازی دادههای چند هتل، مطابق نوشتار JSON ارائه شده در زیر را در نظر میگیریم:
Hotel {
key: THE_043 { name: Espinas, phone: 021-66352565,
address: Keshavarz Blvd., city: Tehran, state: Tehran}
key: THC_011 { name: Evin, phone: 021-22668562,
address: Chamran Highway, city: Tehran, state: Tehran}
key: HRD_021 { name: Dariush, phone: 0764-4223659,
address: Dariush Sq. , city: Kish, state: Hormozgan}
key: GIH_042 { name: Height, phone: 0131-5262266,
address: Namak Abrood, city: Chaloos, state: Gilan}
}
توجه کنید که در مثال فوق، برچسب زمانی ستونها را برای سادگی در نظر گرفته نشده است. در صورتی که از طریق CLI(کلاینت استاندارد کاساندرا) پایگاه داده فوق مورد پرس و جو قرار گیرد، خروجی زیر تولید خواهد شد.
=> (column=state, value=Hormozgan, timestamp=۳۸۹۴۱۶۶۱۵۷۰۳۱۶۵۱) => (column=phone, value=0764-۴۲۲۳۶۵۹, timestamp=۳۸۹۴۱۶۶۱۵۷۰۳۱۶۵۱) => (column=name, value=Dariush, timestamp=۳۸۹۴۱۶۶۱۵۷۰۳۱۶۵۱) => (column=city, value=Kish, timestamp=۳۸۹۴۱۶۶۱۵۷۰۳۱۶۵۱) => (column=address, value= Dariush Sq., timestamp=۳۸۹۴۱۶۶۱۵۷۰۳۱۶۵۱) Returned ۵ results.
بر اساس موارد ذکرشده، از تفاوتهای کلی موجود میان مدل کاساندرا و مدل سنتی رابطهای میتوان به مواردی نظیر نبود زبان پرسوجو و نبود یکپارچگی مرجعی و در نتیجه نبود عملیات Join و انطباق بهتر کاساندرا با مدل Denormalize شده دادهای بر خلاف مدل رابطهای اشاره کرد.
Denormalization
در سطوح بالای نرمال سازی ، گاهی کاهش افزونگی داده ها معایبی را نیز به دنبال خواهند داشت ، مثلا فرآیند نرمال سازی باعث کاهش زمان پاسخگویی می شود و یا در پرس و جو های مختلف اغلب باید همه ی جداول بوجود آمده در فرم نرمال با یکدیگر الحاق شوند تا پرس و جو صورت گیرد ، که زمان زیادی را سپری خواهد کرد و در سرویس های پایگاه داده وب که زمان پاسخ گویی از فاکتور های مهم است ، اصلا مناسب نیست. در این نوع پایگاه داده ها که در آنها افزونگی داده اهمیت چندانی ندارد میتوان سطح نرمال سازی را کاهش داد که این فرآیند را Denormalization گویند.
نقش پایگاه داده های ستون گرا در طراحی OLAP
در حال حاضر ، OLAP همچنان یک فناوری دست و پاگیر است ، زیرا برای ساخت مکعب نیاز به مدل سازی پایگاه داده جداگانه دارد. و هرچه داده های بیشتری برای تجزیه و تحلیل نیاز داشته باشید ، به احتمال زیاد به یک انبار داده فقط برای نیازهای OLAP نیاز خواهید داشت. اما ممکن است با ظهور پایگاه داده های ستونی ، همه چیز تغییر کند.
همانطور که ممکن است به خاطر داشته باشید ، یک پایگاه داده سنتی رابطه ای مقادیر را در سطرها ذخیره می کند ، در حالی که ستون ها دسته بندی اقلام را نشان می دهند. پایگاه داده ستون نوعی طرحواره است که از ستون ها برای سازماندهی جداول در DB استفاده می کند. به همین سادگی ، این نوع طرحواره قابلیت هایی مشابه آنچه پایگاه داده OLAP انجام می دهد ، ارائه می دهد. هر جدول ابعادی را نشان می دهد که می تواند به سرعت اسکن و تجزیه و تحلیل شود.
پایگاه داده های ستونی به طور بالقوه می توانند به عنوان یک انبار داده استفاده شوند که قادر است به طور طبیعی پرس و جوهای OLAP را اداره کند. در حالی که این روش در سال 2012 در مطالعات مختلف توضیح داده شد ، چند سال پیش محبوبیت پیدا کرد. بنابراین این منجر به ظهور انبارهای داده ابری ستون محور شد.
منبع:
chistio.ir/پایگاه-داده-آپاچی-کاساندرا-apache-cassandra-چیست؟/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 3441
برچسبCassandra ColumnFamily NOSQL انواع کلید در cassandra بیگ دیتا خانواده ستون ستون گرا ستون گسترده ستونگرا شما کاساندرا کلان داده مدل داده مدل داده کاساندرا
نوشته های مرتبط










همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …

تحلیل گراف های بزرگ با آپاچی فلینک (Apache Flink)
تعریف جریان داده: جریان داده ها، داده هایی هستندکه بطور مداوم توسط هزاران منبع داده …
