معرفی کامل صف پیشرفته کافکا (Kafka) همراه با نصب و راه اندازی در داکر
17,924 تعداد نمایش
در مباحث قبل به ActiveMQ به عنوان یک سیستم صف و کارگزار پیام پرداختیم. آپاچی کافکا نیز پلت فرم متن باز به منظور پردازش جریانی اطلاعات توسعه یافته است که توسط بنیاد نرم افزار آپاچی نوشته شده و با اسکالا و جاوا است. این پروژه با هدف ارائه یک پلت فرم پر توان، با زمان تاخیر کم واحد و یکپارچه برای دست کاری اطلاعات ورودی به آن در زمان واقعی تولید شده است. لایه ذخیره سازی آن اساسا برای یک معماری کارگزار صف پیام انبوه و مقیاس پذیر و برای تراکنش های توزیع شده تولید شده است. تکنولوژی کافکا به طور مشخص برای پردازش جریان داده ها (Stream Processing) و کارگزار ارسال و دریافت پیام (Message Broker) مورد استفاده قرار می گیرد. و آن را بسیار با ارزش برای زیرساخت پردازش جریانی داده ها نموده است. علاوه بر این، کافکا اتصال به سیستم های خارجی (برای داده های ورودی / خروجی) از طریق Kafka Connect و provides Kafka Streams فراهم می کند.
آپاچی کافکا ابتدا در سال ۲۰۱۱ در لینکدین (LinkedIn) به منظور رفع مشکل کندی زمان ضبط دادهها از روی وبسایت و همچنین مدیریت کردن سیستمهای پردازش رویدادهای بلادرنگ توسعه داده شد. در نهایت این سیستم به بنیاد نرمافزار آپاچی اهدا شد. جالب است بدانید که امروزه یک سوم از شرکتهایی که نام آنها در فهرست Fortune 500 قرار دارد، از کافکا استفاده میکنند. این فهرست، ۱۰ شرکت اول گردشگری، ۷ بانک از فهرست ۱۰ بانک برتر، ۸ شرکت نخست بیمه از مجموع ۱۰ شرکت و ۹ شرکت از مجموع ۱۰ شرکت برتر حوزه تلکام را دربر میگیرد.
موارد استفاده کافکا (kafka)
یکی از بزرگترین چالشهای همراه با کلان داده، تحلیل دادهها است، زمانی که در پروژه های بیگ دیتا قرار است حجم عظیمی از داده ها به سمت ما سرریز شود و ما فرصت کافی برای تحلیل یا بررسی آنها را نداریم در اینجا کافکا به عنوان یک بافر و خط لوله قدرتمند جریان داده را برای ما ذخیره و کنترل مینماید تا ما فرصت لازم را برای عملیات بر روی داده ها داشته باشیم.
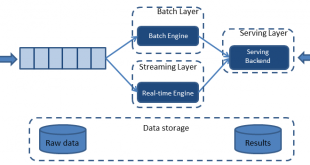
برای همین کافکا امکان کار را با تمامی سامانه های مربوط به عملیات پردازش داده مانند Flume, Flafka, Spark Streaming, Storm, HBase, Flink و Spark را برای ورودی بلادرنگ، تحلیل و پردازش جریانهای داده فراهم میکند. کافکا جریان دادهای است که برای تغذیه دریاچههای کلان داده Apache Hadoop به کار میرود. بروکرهای کافکا، جریانهای حجیم پیام را به منظور تحلیل آنها در هدوپ (Apache Hadoop) یا اسپارک پشتیبانی مینمایند. سادگی عملیات کافکا یکی از دلایل گسترش روزافزون کاربرد میتواند باشد، اما دلیل اصلی عمومیت آن، کارایی بسیار مناسب آن است. در شکل زیر جایگاه استفاده از کافکا در مقایسه با دیگر تکنولوژی ها مشخص است.
ویژگی های کافکا (kafka)
کافکا برای مواجهه با انبوهی از داده ها که بی وقفه در حال ارسال هستند و شما فرصت کافی برای پردازش و ذخیره سازی آنها نداشته باشید تولید شده است. به عبارت ساده تر می توان گفت که کافکا یک بافر قدرتمند برای زمانی که بیگ دیتا در حال انتقال هست می باشد. کافکا ™ برای استفاده در پروژه های زمان واقعی (real-time) به منظور فراهم آوردن خط لوله داده ها و جریان برنامه های استفاده می شود. کافکا به صورت افقی مقیاس پذیر، مقاوم در برابر خطا و بسیار سریع است. و در تولیدات هزاران شرکت استفاده می شود.
ما از یک پلت فرم جریان داشتن سه قابلیت کلیدی اننتظار داریم:
· اجازه انتشار و اشتراک در جریان ثبت داده می دهد. در این راستا آن شبیه به یک سیستم صف پیام است.
· به شما امکان ذخیره جریان پرونده را از طریق تحمل خطا میدهد.
· به شما امکانپردازش جریانی می دهد.
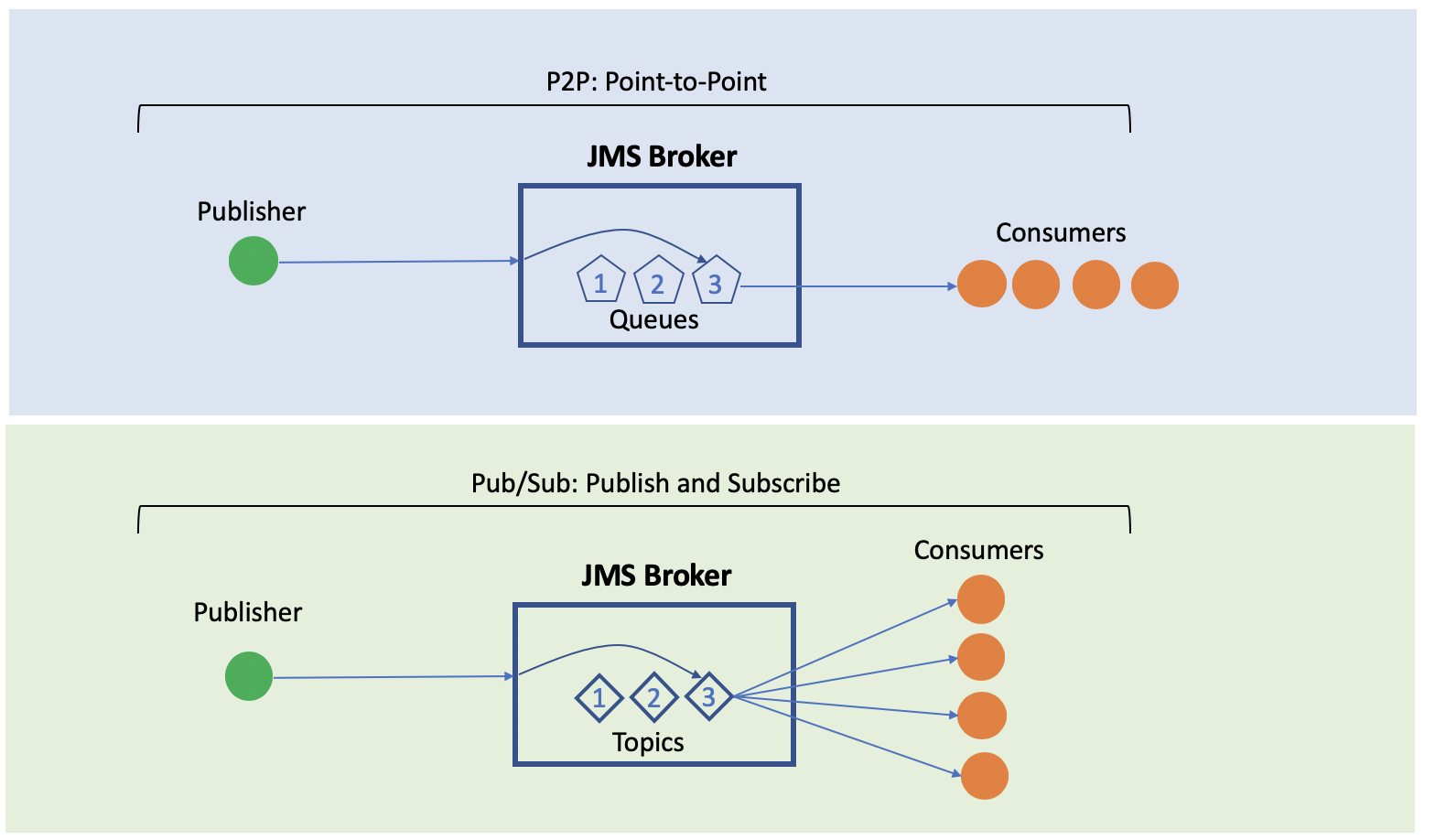
انواع کارگزار های پیام در کافکا
Message Broker ها به طور استاندارد به دو شکل Queuing و یا Topic (ویا Publish-Subscribe ) وجود دارند. در روش اول داده ها در یک صف قرار می گیرند و می توان آنها را با ترتیب وارد شده به صف خواند. مزیت این روش این است که می توان خواندن و پردازش را به صورت موازی انجام داد ولی با مصرف شدن هر پیام، به طور کامل از صف حذف می گردد. این ایراد در روش دوم به دلیل ارسال یک پیام به تمامی Subscriber ها وجود ندارد ولی در عوض تقسیم بار کاری بی معنی می باشد. استفاده از کافکا مزیت هر دو روش را در اختیار می گذارد.
تفاوت صف با Topic
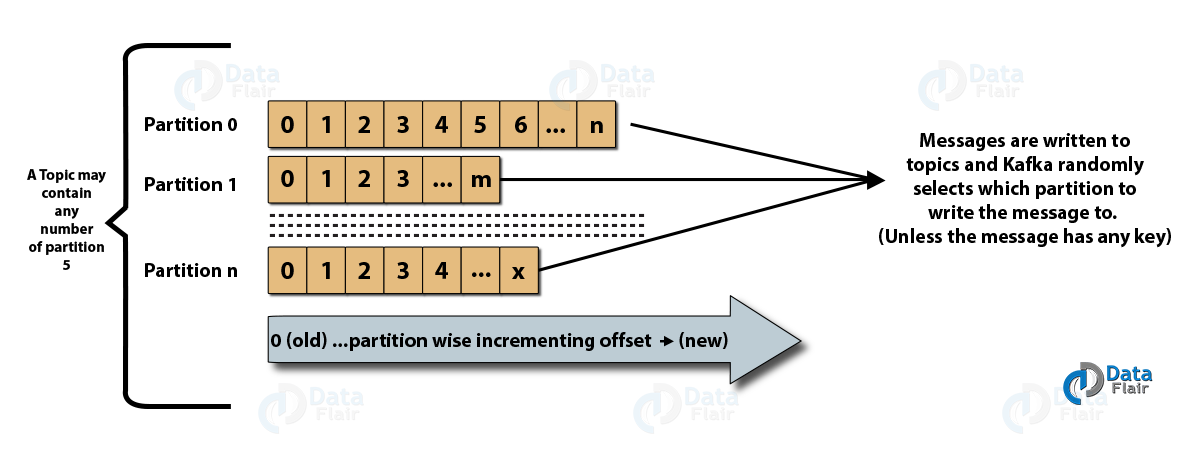
پارتیشن ها پیام ها را به ترتیب ورود ذخیره می کنند و مصرف کننده نیز به همان ترتیب پیام را دریافت می دارد. با تخصیص هر مصرف کننده به یک پارتیشن، دریافت اطلاعات به صورت موازی انجام می گیرد. در عین حال محدودیتی در تعداد گروه های مصرف کننده یک Topicوجود ندارد و offset خوانده شده هر گروه جدا از گروه های دیگر نگهداری می گردد. Offset به نقطه ای از پارتیشن که در فرمان Poll بعدی داده ها باید از آنجا خوانده شود اشاره دارد که می تواند به صورت خودکار توسط مصرف کننده بعد از خواندن داده ها کامیت شود و یا به صورت دستی توسط برنامه نویس بعد از پرداش اطلاعات کامیت گردد.
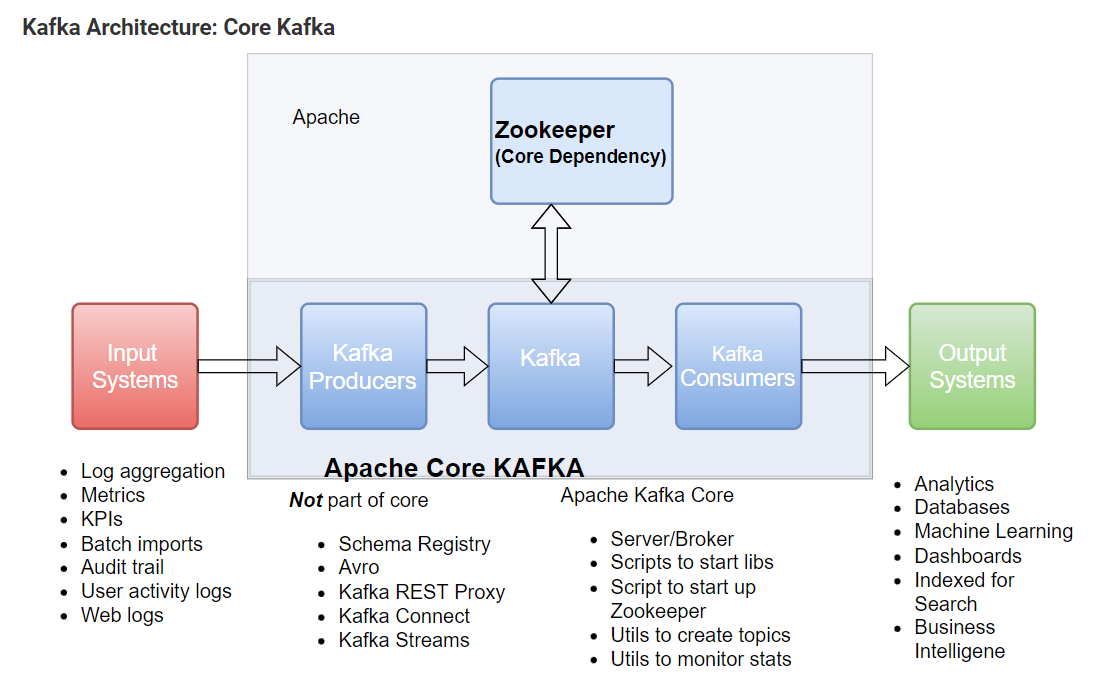
معماری یک کلاستر کافکا
مولفه ها و اجزای کافکا
کارگزار کافکا (Kafka Broker)
اساساً برای حفظ تعادل بار، خوشه کافکا معمولاً از چندین کارگزار تشکیل شده است. با این حال، این ها بدون حالت(stateless) هستند، بنابراین برای حفظ حالت خوشه از ZooKeeper استفاده می کنند. اگرچه، یک نمونه بروکر کافکا می تواند صدها هزار خواندن و نوشتن در ثانیه انجام دهد و بدون تأثیر عملکرد، هر کارگزار می تواند ترا بایت پیام را مدیریت کند. با این حال ، مطمئن شوید که ZooKeeper راهبری کافکا را انجام می دهد.
عملکرد کافکا
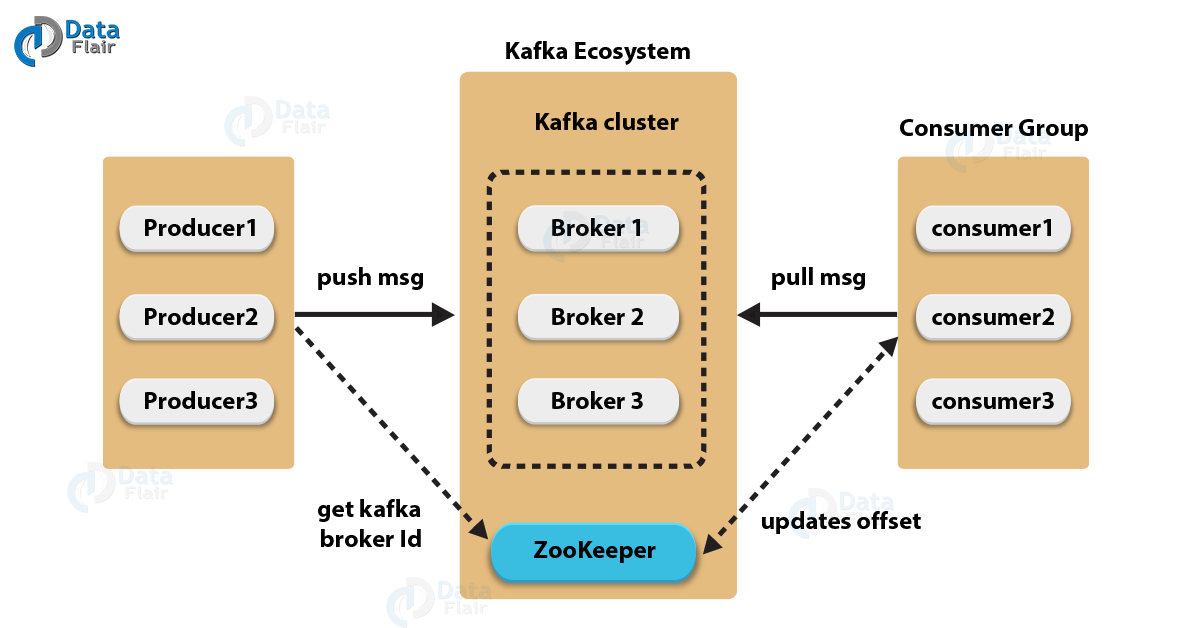
Kafka – ZooKeeper
زوکیپر یک مولفه ناگزیر برای استفاده از کافکا است. کارگزارهای کافکا به منظور مدیریت و هماهنگی باید از ZooKeeper استفاده می کنند. همچنین از آن برای اطلاع تولید کننده و مصرف کننده در مورد حضور هر کارگزار جدید و یا شکست کارگزار در سیستم کافکا استفاده می کند. به محض اینکه Zookeeper اطلاعیه حضور یا عدم موفقیت کارگزار را ارسال کرد، تولید کننده و مصرف کننده داده ها، شروع به هماهنگی کار خود با کارگزار دیگری می کند. همانطور که در شکل بالا مشخص است تولید کنندگان پیام توسط زوکیپر BrokerID مناسب را دریافت می کنند و همچنین مصرف کنندگان پیام نیز آدرس محل خواندن پیام را از زوکیپر دریافت خواهند کرد.
تولید کننده پیام (producers)
تولیدکنندگان (producers) در کافکا دادهها را به کارگزاران میفرستند. همچنین، تمام تولیدکنندگان آن را جستجو می کنند و دقیقاً زمانی که کارگزار جدید شروع به کار می کند، به طور خودکار برای آن کارگزار جدید پیام ارسال می کند. با این حال، به خاطر داشته باشید که تولیدکننده کافکا پیامها را به همان سرعتی که کارگزار از عهده آن بر میآید ارسال میکند، منتظر تأییدیههای کارگزار نیست.
مصرف کنندده پیام (Consumer)
خواندن اطلاعات ذخیره شده بر روی کافکا(Kafka) نیز از طریق همان Client هایی که برای ارسال پیام ها مورد استفاده بودند قابل انجام است. کلاینت مصرف کننده پیام که به اصطلاح Consumer نامیده می شود، جهت خواندن پیام ها باید خود را Subscribe یک Topic مشخص نماید. از این پس با اجرای متد Poll داده ها به سمت مصرف کننده سرازیر می شوند. در هنکام تعریف Topic جدید این امکان وجود دارد که داده های مرتبط با آن در چند پارتیشن ذخیره شوند. پارتیشن ها به سادگی جداسازی فیزیکی داده ها بر روی دیسک را انجام می دهند. در واقع کافکا تمامی پیام های ارسالی به یک Topic را در تمامی پارتیشن ها به همان ترتیبی که ارسال شده اند به صورت توزیع شده ذخیره می کند.
Topic یا موضوع
اولین قدم برای استفاده از آن ایجاد یک Topic می باشد. از این به بعد می توان از طریق ارتباط TCP پیام های جدید را جهت ذخیره سازی در Topic جدید ارسال نمود. این کار به سادگی از طریق Client های پیاده سازی شده که به زبان ها و برای پلتفرم های مختلف طراحی شده اند قابل انجام است. سپس این پیام ها باید در جایی ذخیره گردد. کافکا این پیام ها را در فایل هایی با نام Log ذخیره سازی می نماید. داده های جدید به انتهای فایل های Log افزوده می گردند. کافکا این توانایی را دارد که پیام های ارسالی را بر روی مجموعه ای از سرورهای کافکا که با یکدیگر کلاستر(Cluster) شده اند، ذخیره سازی نماید.
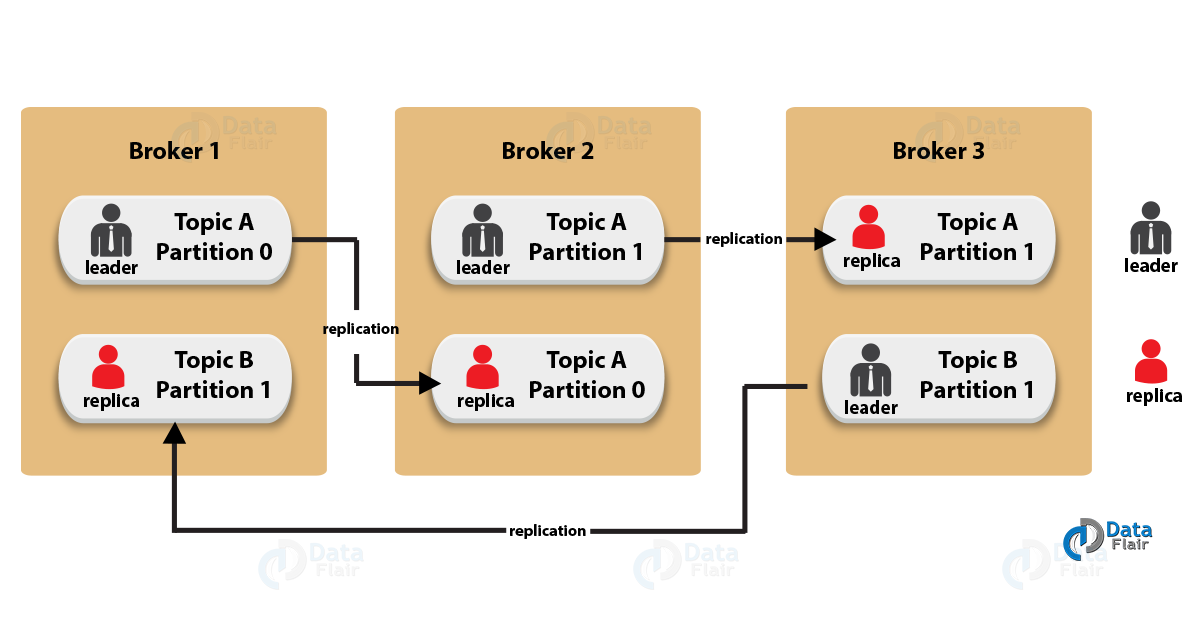
اگر به طور مثال تعداد n سرور کافکا در یک کلاستر وجود داشته باشند، داده های مرتبط با هر پیام ارسالی پس از ذخیره سازی بر روی سرور لیدر، بر روی تمامی سرور های پشتیبانی نیز کپی خواهد گردید. با این وصف، حتی اگر n-1 عدد از سرورها از سرویس خارج شوند، داده های Topic مورد نظر کماکان در دسترس و قابل استفاده خواهند بود. از این رو تحمل پذیری در برابر خطا به خوبی در کافکا دیده شده است.
موضوع یک کانال منطقی است که تولیدکنندگان پیام را در آن منتشر می کنند و مصرف کنندگان از آن پیام دریافت می کنند.
یک Topic جریان یک نوع/طبقه بندی خاص از داده ها را در کافکا تعریف می کند.
علاوه بر این، در اینجا پیام ها ساختاریافته یا سازماندهی شده اند. نوع خاصی از پیام ها در مورد یک Topic خاص منتشر می شود.
اصولاً در ابتدا یک تهیه کننده پیام های خود را در Topic ها می نویسد. سپس مصرف کنندگان آن پیام ها را از موضوعات می خوانند.
در یک خوشه کافکا، یک Topic با نام خود مشخص می شود و باید منحصر به فرد باشد.
هر تعداد Topic می تواند وجود داشته باشد، هیچ محدودیتی وجود ندارد.
ما نمیتوانیم دادهها را به محض انتشار تغییر یا بهروزرسانی کنیم.
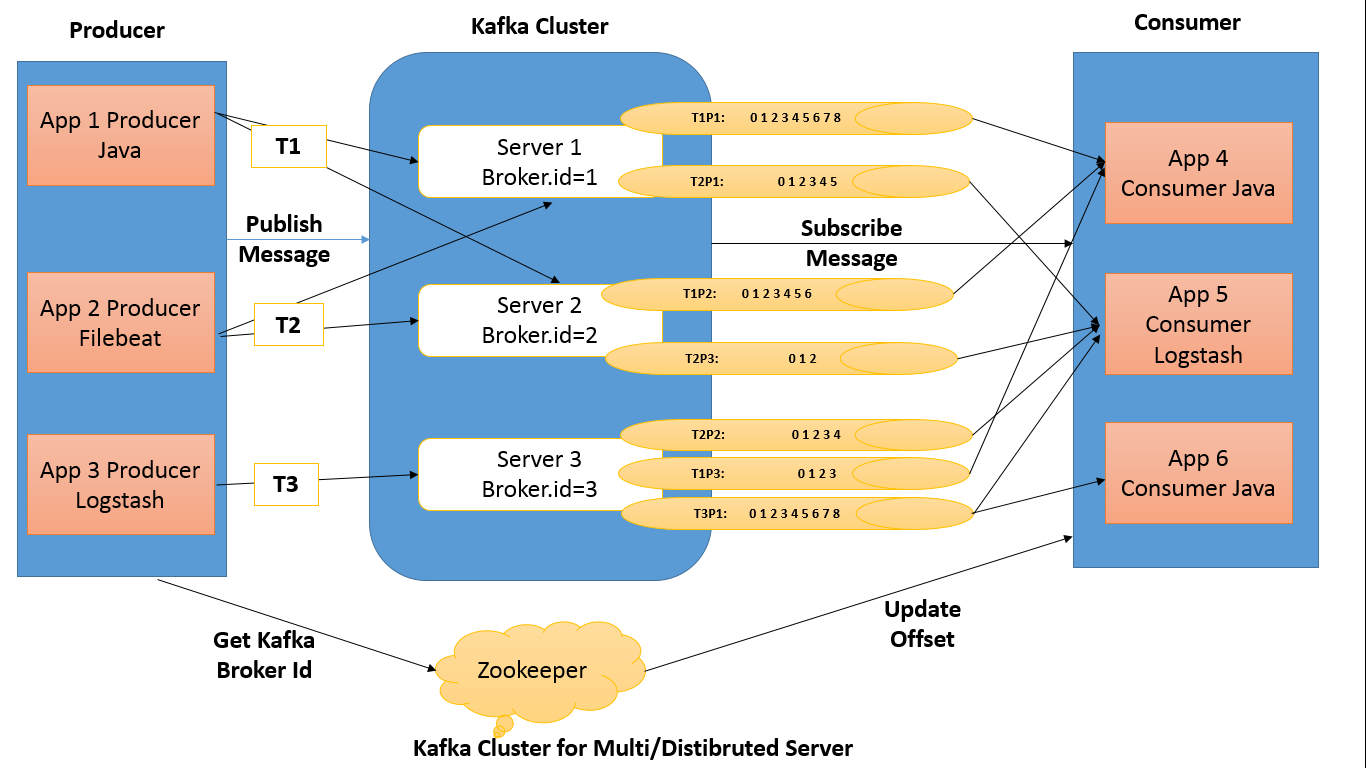
پارتیشن (Partitions)
در این مدل ذخیره سازی، هر پارتیشن بر روی یک سرور ذخیره شده و سایر سرور های حاضر در Cluster نسخه پشتیبان آن پارتیشن را کپی خواهند کرد. این ویژگی کافکا به مصرف کننده پیام این امکان را می دهد که به صورت موازی اطلاعات را دریافت نماید. روش کار به این شکل است که به تعداد پارتیشن های موجود یک Topic باید Consumer جدید تعریف شود و همگی آنها عضو یک گروه شوند.
در زیر تصویری وجود دارد که رابطه بین موضوعات کافکا و پارتیشن ها را نشان می دهد:
ارتباط بین Topic و Partition
Rebalance
این کار به سادگی با انتخاب مشخصه group.id یکسان برای همه آنها قابل انجام است و پس از آن می توان شروع به خواندن پیام ها نمود. تمام هماهنگی های مورد نیاز جهت تخصیص هر پارتیشن به یک مصرف کننده توسط کافکا(Kafka) انجام خواهد پذیرفت. در صورتی که تعداد مصرف کننده بیشتر از پارتیشن ها باشد یکی از آنها در عمل استفاده نخواهد شد ولی اگر تعداد پارتیشن ها بیشتر از تعداد مصرف کننده ها باشد به هر مصرف کننده بیش از یک پارتیشن جهت خواندن پیام ها اختصاص داده خواهد شد. با تغییر در تعداد مصرف کننده ها، کافکا گروه مصرف کننده رو دوباره تنظیم یا به اصطلاح Rebalance می نماید.
Topic Replication Factor
رابط های کاربری کافکا
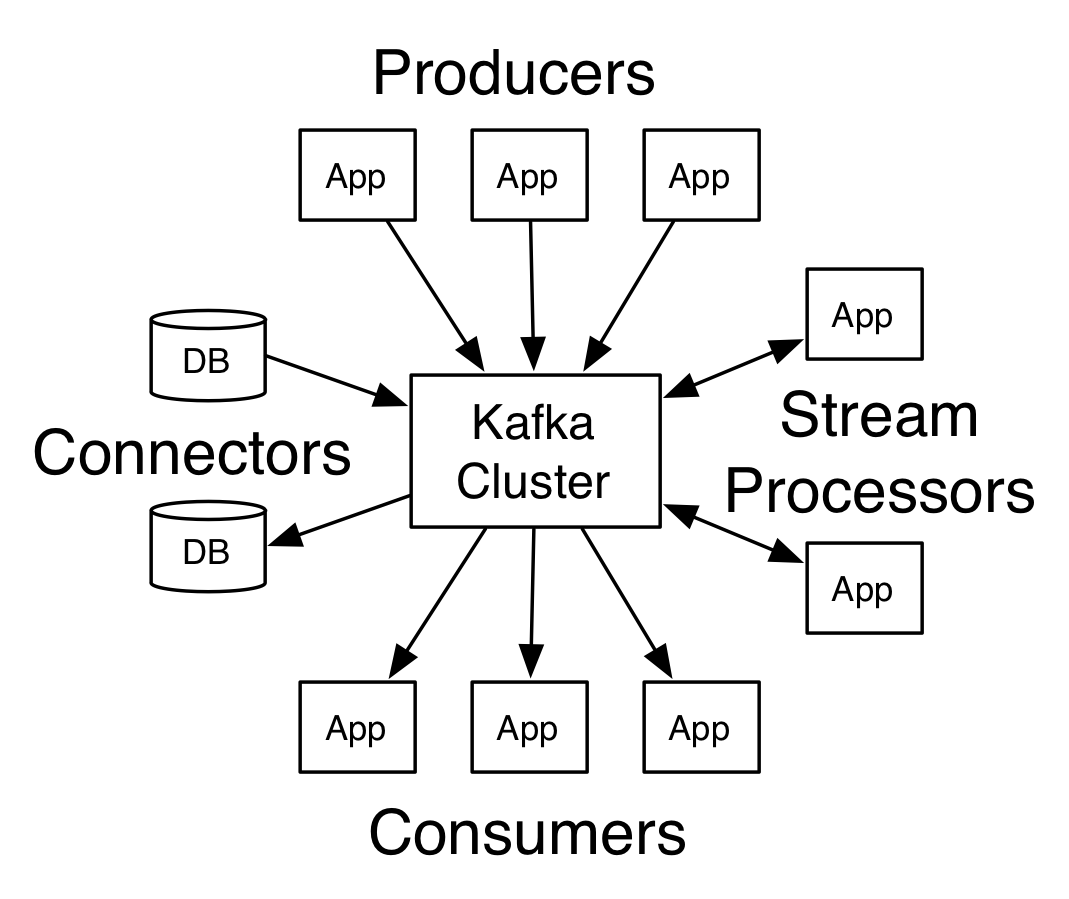
کافکا دارای چهار رابط زیر برای ارتباط است که مفهوم آن در شکل زیر نیز آمده است.
Producer API : به یک برنامه کاربردی اجازه می دهد تا stream از رکوردها را در یک یا چند موضوع(topics) کافکا منتشر کند.
Consumer API : به یک برنامه اجازه می دهد در یک یا چند موضوع(topics) مشترک(subscribe) شود و جریان رکوردهای تولید شده برای آنها را دریافت و پردازش کند.
Streams API : به یک برنامه کاربردی اجازه می دهد تا به عنوان یک پردازشگر جریان(stream processor) عمل کند، یک جریان ورودی از یک یا چند topics را مصرف کند و یک جریان خروجی را به یک یا چند topics خروجی تولید کند، و به طور موثر جریان های ورودی را به جریان های خروجی تبدیل کند.
Connector API: به تولیدکنندگان(producers) یا مصرف کنندگان(consumers) قابل استفاده مجدد را اجازه می دهد تا topics های کافکا را به برنامه های کاربردی یا سیستم های داده موجود متصل کنند. به عنوان مثال، یک اتصال دهنده به یک پایگاه داده رابطه ای ممکن است هر تغییری را در یک جدول ثبت کند.
کافکا
نحوه نگهداری اطلاعات پیکربندی کافکا
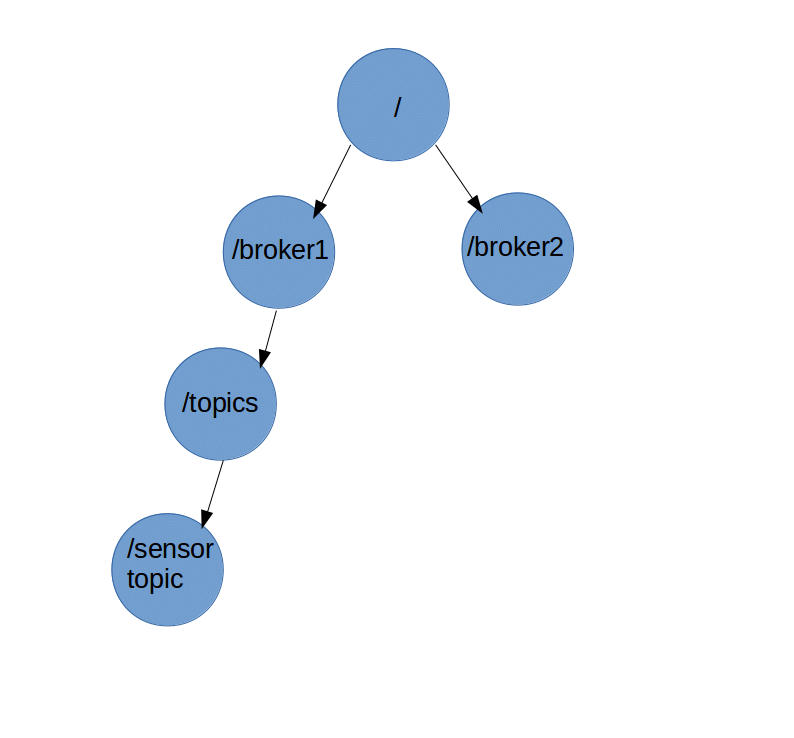
هر سرور کافکا دارای شناسه ای می باشد که در کلاستر منحصر یه فرد است و به آن broker.id می گویند. هر Broker دارای Topic های مربوط به خود است و هر Topic از مجموعه ای از پارتیشن ها تشکیل شده است. و در نهایت هر پارتیشن به ازای هر گروه مصرف کننده offset جداگانه نیاز خواهد داشت. این اطلاعات پیکربندی توسط Apache Zookeeper نگهداری می شود و کافکا برای اجرا نیاز به این سرویس دارد. Zookeeper اطلاعات مربوط به Topic های یک Broker را در ساختار درختی ذخیره می کند:
این اطلاعات که در یک ساختار فایل سیستم مانند و به صورت Key,Value ذخیره می شوند در سرتاسر کلاستر در دسترس هستند. پیش از راه اندازی کافکا سرویس Zookeeper باید راه اندازی شده باشد و در پیکربندی کافکا نحوه اتصال به آن مشخص می گردد.
همینطور کافکا این ویژگی را دارد که جریان داده های ورودی به یک Topic را پس از عبور دادن از یک پردازش کننده و تغییر حالت داده ها، در Topic/های جدید ذخیره نماید که این عمل به صورت بلادرنگ انجام می گیرد. به طور خلاصه کافکا ذخیره سازی داده ها بر روی کلاستر، خواندن اطلاعات به صورت Publish-Subscribe و البته موازی جهت تقسیم بار کاری و پردازش همزمان جریان داده ها را در اختیار سیستم هایی می گذارد که دغدغه پردازش داده های انبوه را دارند.
 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم














ترجمه تون افتضاحه. هیچی نفهمیدم. رفتم جای دیگه ای خواندم
با سلام و احترام
کارگاه آموزشی کافکا در حال حاضر برگزار نمی شود
سلام
کارگاه آموزشی راجع به کافکا دارید؟