 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
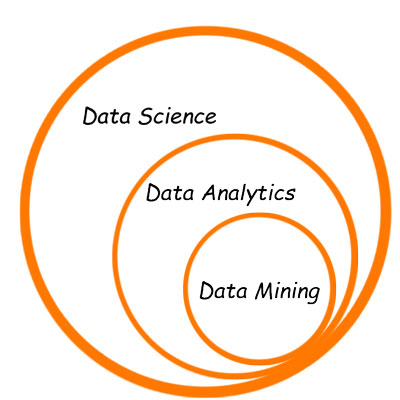
روش های داده کاوی (Data Mining) به زبان ساده
امروزه داده کاوی به عنوان پایه و مبنای تصمیم های مهم محسوب میشود. داده کاوی به ما کمک میکند که سامانه هایی را توسعه دهیم که قادر است از میان میلیونها یا میلیاردها رکورد، روابط غیر آشکار را شناسایی کند. داده کاوی در حال تغییر دادن جهانی است که در آن زندگی میکنیم. به بیانی دیگر داده کاوی استخراج اطلاعات نهان و یا الگوها و روابط نهفته و غیر آشکار در حجم زیادی از دادهها در مخازن اطلاعاتی است.
عناوين مطالب: '
داده کاوی چیست؟
داده کاوی ترجمه ی عبارت لاتین Data Mining و به معنای تحت الفظی “کاویدن داده” است. کلمه ی Mining در معنای تحت الفظی خود یعنی «استخراج از معدن» بکار می رود. در واقع عبارت Data Mining نشان می دهد که حجم انبوه اطلاعات مانند یک معدن عمل می کند و از ظاهر آن مشخص نیست چه عناصر گرانبهایی در عمق این معدن وجود دارد. تنها با کند و کاو و استخراج این معدن است که می توان به آن عناصر گرانبها دست پیدا کرد.
![]()
تفاوت داده کاوی و تحلیل های آماری
تفاوت اصلی داده کاوی و علم آمار، در حجم داده های مورد تحلیل، روش مدلسازی داده ها و استفاده از هوش مصنوعی است. داده کاوی شاخه ی توسعه یافته و پیچیده ی علم آمار است. داده کاوی یک روش حل مسئله مبتنی بر داده های موجود است. بر اساس استاندارد جهانی کریسپ دی ام (CRISP-DM) این فرایند حل مسئله را به اجرا می گذارد. داده کاوی در محل تلاقی سه رشته علمی قرار گرفته است:
۱٫ آمار (مطالعه عددی روابط دادهها)
۲٫ هوش مصنوعی (هوش انسان مانند که توسط نرمافزار و یا ماشین ظهور مییابد)
۳٫ یادگیری ماشین (الگوریتمهایی که میتواند با آموزش دیدن از دادهها، آینده را پیشبینی کند)
داده کاوي با آنالیز های متداول آماری متفاوت است؛ در زیرمی توان برخی از اصلی ترین تفاوت های داده کاوي و آنالیز آماری را مشاهده نمود.
آنالیز آماری:
• آمار شناسان همیشه با یک فرضیه شروع به کار می کنند.
• آنها از داده های عددی استفاده می کنند.
• آمارشناسان باید رابطه هایی را ایجاد کنند که به فرضیه آنها مربوط است.
• آنها می توانند داده های نابجا و نادرست را در طول آنالیز مشخص کنند.
• آنها می توانند نتایج کار خود را تفسیر و برای مدیران بیان کنند.
داده کاوی:
• به فرضیه احتیاجی ندارد.
• ابزارهای داده کاوی از انواع مختلف داده ، نه تنها عددی می توانند استفاده کنند.
• الگوریتمهای داده کاوی به طور اتوماتیک روابط را ایجاد می کنند.
• داده کاوی به داده های صحیح و درست نیاز دارد.
• نتایج داده کاوی نسبتا پیچیده می باشد و نیاز به متخصصانی جهت بیان آنها به مدیران دارد.
روش تحلیل آماری:
یک مفسر ممکن است متوجه الگوی رفتاری شود که سبب کلاهبرداری بیمه گردد. بر اساس این فرضیه، مفسر به طرح یک سری سوال می پردازد تا این موضوع را بررسی کند. اگر نتایج حاصله مناسب نبود، مفسر فرضیه را اصلاح می کند و یا با انتخاب فرضیه دیگری مجددا شروع می کند.
این روش نه تنها وقت گیر است بلکه به قدرت تجزیه و تحلیل مفسر نیز بستگی دارد. مهمتر از همه اینکه این روش هیچ وقت الگوهای کلاهبرداری دیگری را که مفسر به آنها مظنون نشده و در فرضیه جا نداده ، پیدا نمی کند.
روش داده کاوی:
یک مفسر سیستم های داده کاوی را ساخته و پس از طی مراحلی از جمله جمع آوری داده ها، یکپارچه سازی داده ها به انجام عملیات داده کاوی می پردازد. داده کاوی تمام الگوهای غیرعادی را که از حالت عادی و نرمال انحراف دارند و ممکن است منجر به کلاهبرداری شوند را پیدا می کند.
نتایج داده کاوی حالت های مختلفی را که مفسر باید در مراحل بعدی تحقیق کند، نشان می دهند. در نهایت مدل های به دست آمده می توانند مشتریانی را که امکان کلاهبرداری دارند، پیش بینی نمایند.
ویژگی های اصلی داده کاوی:
- کشف اتوماتیک الگوها
- پیش بینی احتمالی نتایج و خروجی ها
- ایجاد اطلاعات اجرایی و مفید
- تمرکز بر روی داده های بزرگ و مجموعه پایگاه های داده
نمونه کاربردهای داده کاوی
استفاده تجاری
یکی از نمونه های بارز داده کاوی را می توان در فروشگاه های زنجیره ای مشاهده نمود، که در آن سعی می شود ارتباط محصولات مختلف هنگام خرید مشتریان مشخص گردد. فروشگاه های زنجیره ای مشتاقند بدانند که چه محصولاتی با یکدیگر به فروش می روند. برای مثال طی یک عملیات داده کاوی گسترده در یک فروشگاه زنجیره ای در آمریکای شمالی که بر روی حجم عظیمی از داده های فروش صورت گرفت، مشخص گردید که مشتریانی که تلویزیون خریداری می کنند، غالبا گلدان کریستالی نیز می خرند.
نمونه دیگر از استفاده تجاری
نمونه مشابه عملیات داده کاوی را می توان در یک شرکت بزرگ تولید و عرضه پوشاک در اروپا مشاهده نمود، به شکلی که نتایج داده کاوی مشخص می کرد که افرادی که کراوات های ابریشمی خریداری می کنند، در همان روز یا روزهای آینده گیره کراوات مشکی رنگ نیز خریداری می کنند. به روشنی این مطلب قابل درک است که این نوع استفاده از داده کاوی می تواند فروشگاه ها را در برگزاری هوشمندانه فستیوال های فروش و نحوه ارائه اجناس به مشتریان یاری رساند.
نمونه دیگر استفاده از داده کاوی در زمینه فروش را می توان در یک شرکت بزرگ دوبلاژ و تکثیر و عرضه فیلم های سینمایی در آمریکای شمالی مشاهده نمود که در آن عملیات داده کاوی، روابط مشتریان و هنرپیشه های سینمایی و نیز گروه های مختلف مشتریان بر اساس سبک فیلم ها (ترسناک، رمانتیک، حادثه ای و …) مشخص گردید.بنابراین آن شرکت به صورت کاملاً هوشمندانه می توانست مشتریان بالقوه فیلم های سینمایی را بر اساس علاقه مشتریان به هنرپیشه های مختلف و سبک های سینمایی شناسایی کند.
استفاده پزشکی
از دیگر زمینه های به کارگیری داده کاوی، استفاده بیمارستان ها و کارخانه های داروسازی جهت کشف الگوها و مدلهای ناشناخته تأثیر داروها بر بیماری های مختلف و نیز بیماران گروه های سنی مختلف را می توان نام برد.
استفاده در بانک داری
استفاده از داده کاوی در زمینه های مالی و بانکداری به شناخت مشتریان پر خطر و سودجو براساس معیارهایی از جمله سن، درآمد، وضعیت سکونت، تحصیلات، شغل و غیره می انجامد.
Michael Schrage کارشناس و تحلیلگر هاروارد میگوید: اگر داده کاوی و تحلیلهای پیشگویانه (predictive analytics) به گونهای درست و اصولی انجام شود، تحلیلها فقط وسیلهای برای پیشبینی نیستند بلکه این پیشبینیها به ابزاری برای به دست آوردن بینشهای تحلیلی تبدیل خواهد شد.
متدولوژی های مختلف و مدل های داده کاوی
متدولوژی های متفاوتی برای داده کاوی از قبل سال 1996 ارائه شده است که در جدول وشکل زیر مهمترین آنها همراه با ارتباط های آنها مقایسه شده است.
| Name | Origin | Basis | Key concept | Year |
|---|---|---|---|---|
| Human-Centered | Academy | KDD | Iterative process and interactivity (user’s point of view and needed decisions) | 1996, 2004 |
| Cabena et al. | Academy | KDD | Focus on data processing and discovery tasks | 1997 |
| Anand and Buchner | Academy | KDD | Supplementary steps and integration of web-mining | 1998, 1999 |
| Two Crows | Industry | KDD | Modified definitions of steps | 1998 |
| SEMMA | Industry | KDD | Tool-specific (SAS Institute), elimination of some steps | 2005 |
| 5 A’s | Industry | Independent | Supplementary steps | 2003 |
| 6 Sigmas | Industry | Independent | Six Sigma quality improvement paradigm in conjunction with DMAIC performance improvement model | 2003 |
| CRISP-DM | Joint industry and academy | KDD | Iterative execution of steps, significant refinements to tasks and outputs | 2000 |
| Cios et al. | Academy | Crisp-DM | Integration of data mining and knowledge discovery, feedback mechanisms, usage of received insights supported by technologies | 2005 |
| RAMSYS | Academy | Crisp-DM | Integration of collaborative work aspects | 2001–2002 |
| DMIE | Academy | Crisp-DM | Integration and adaptation to Industrial Engineering domain | 2001 |
| Marban | Academy | Crisp-DM | Integration and adaptation to Software Engineering domain | 2007 |
| KDD roadmap | Joint industry and academy | Independent | Tool-specific, resourcing task | 2001 |
| ASUM | Industry | Crisp-DM | Tool-specific, combination of traditional Crisp-DM and agile implementation approach | 2015 |
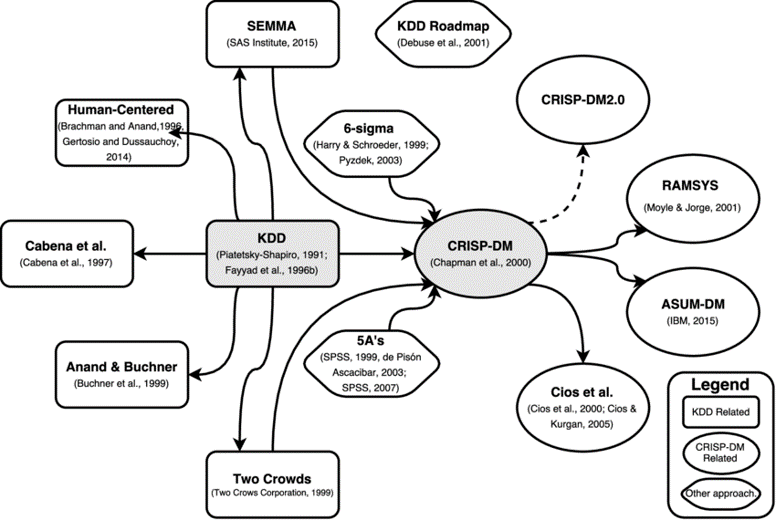
برخی از معروف ترین مدل ها داده های شامل مدل های مبتنی بر CRISP-DM از شرکت IBM و مدلهای مبتنی بر KDD است و مدل های متفرقه دیگر هست که در شکل زیر با هم مقایسه شده اند. که در این مبحث به علت اهمیت مدل CRISP-DM صرفا این مدل مورد بررسی قرار خواهد گرفت.
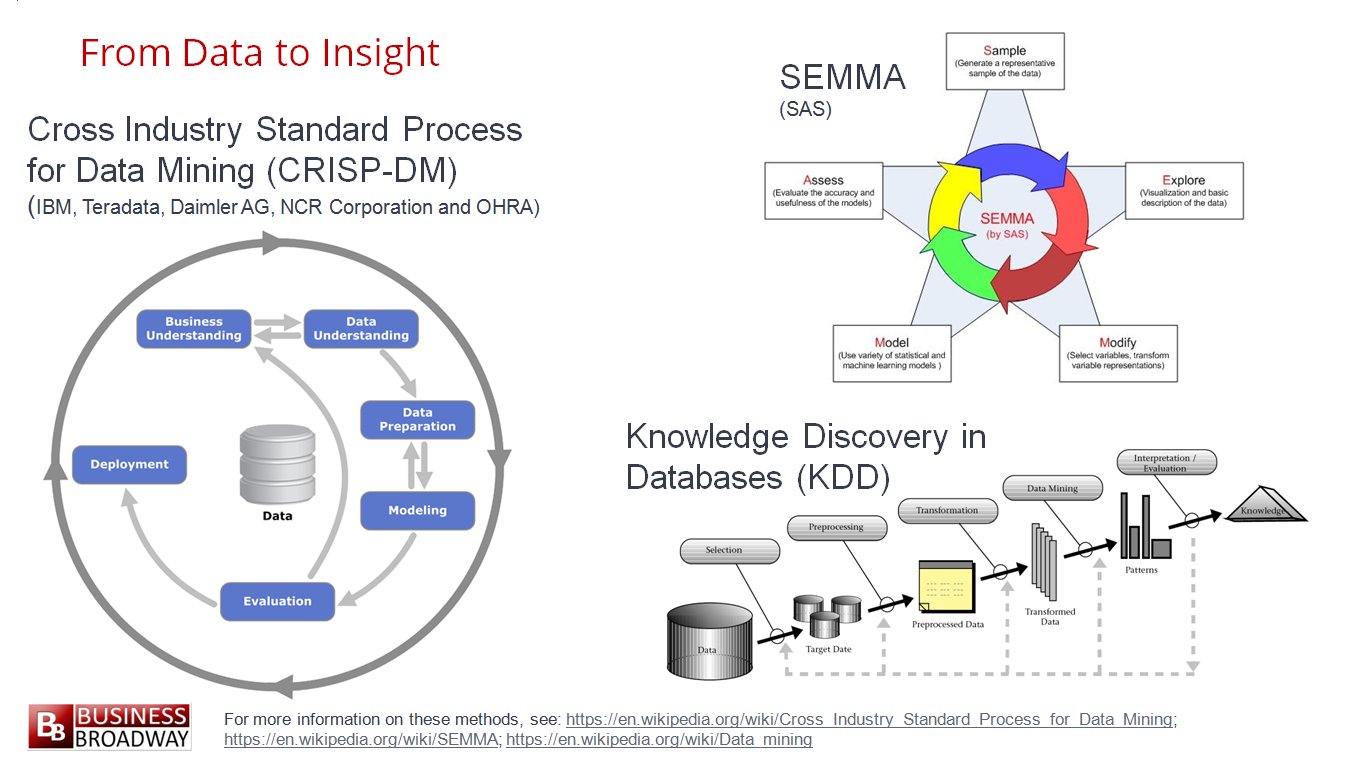
مراحل اصلی داده کاوی در روش های مبتنی بر CRISP-DM
روش داده کاوی مبتنی بر مدل CRISP-DM در شش گام زیر صورت می گیرد. که در ادامه هر کدام شرح داده می شود. این روش از اهمیت ویژه ای برخوردار است لذا در ابزار SPSS Modeler در شرکت IBM نیز از این مدل برای کار با نرم افزار SPSS استفاده شده است لذا یادگیری این مدل نسبت به مدل های دیگر دارای ارجحیت می باشد. در شکل 6 مرحله مختلف و ارتباطات آنها و بازخوردها مشخص شده است.
- درک کسب و کار
- بررسی و درک داده ها
- آماده سازی داده ها
- مدل سازی
- تست و ارزیابی مدل
- توسعه مدل نهایی و استقرار

مرحله اول: درک کسب و کار
کاربران برای اتخاذ تصمیم های مناسب در هنگام ایجاد مدل های داده کاوی باید به درک صحیحی از داده ها برسند. در این مرحله مواردی همچون الزامات مربوط به کسب کار، تعریف چارچوب مساله، تعریف معیارهای مورد استفاده برای ارزیابی مدل و تعریف اهداف مشخص برای پروژه ی داده کاوی صورت می پذیرد.
این فعالیت ها در قالب سوالات متعددی بیان میشود که پاسخ به این سوالات ممکن است مستلزم انجام تحقیق و بررسی در خصوص دسترس پذیری داده ها باشد. به عبارتی نیاز کاربران با توجه به داده های دردسترس تامین گردد. در صورتی که داده ها قادر به تامین نیازهای کاربران نباشند، ممکن است نیاز به تعریف مجدد پروژه باشد.
مرحله دوم: بررسی و درک داده ها
متخصص داده کاوی، داده های ثبت شده در کسب و کار کارفرما را از وی درخواست می کند و به بررسی داده ها می پردازد. متخصص داده کاوی با توجه به حجم و کیفیت داده ها مسئله ی طرح شده در مرحله ی قبل را تعدیل می کند تا نتیجه ی پروسه ی داده کاوی واقع بینانه تر بشود.
ماهیت مجموعه داده:
برای هر تحلیلی در دنیای داده کاوی می بایست دیتاست مناسب آن را فراهم آوریم. فرض کنید تحلیلی که میخواهید انجام شود در مورد ردهبندی (Classification) است. درنتیجه ما باید به دنبال دیتاستی باشیم که Lable یا برچسب خورده باشد. یا در مثال دیگر، فرض کنید ما به دنبال ایجاد یا ارتقاء روشی برای کاهش ابعاد دیتا هستیم در این صورت نیز ما باید مجموعه داده ای را انتخاب کنیم که دارای بُعد زیاد باشد. یا فرض کنید که ما به دنبال تحلیل متن فارسی هستیم. پس بدیهی است که باید یک مجموعه داده به زبان فارسی پیدا کنیم. با این که فرض کنید میخواهیم تست فشار برای یک سیستم بزرگ مقیاس انجام دهیم پس باید به دنبال داده های حجیم باشم. گونه های مختلفی در دیتاستها وجود دارد بهطور خلاصه میتوان دیتاست ها را به موارد زیر تقسیمبندی کنیم:
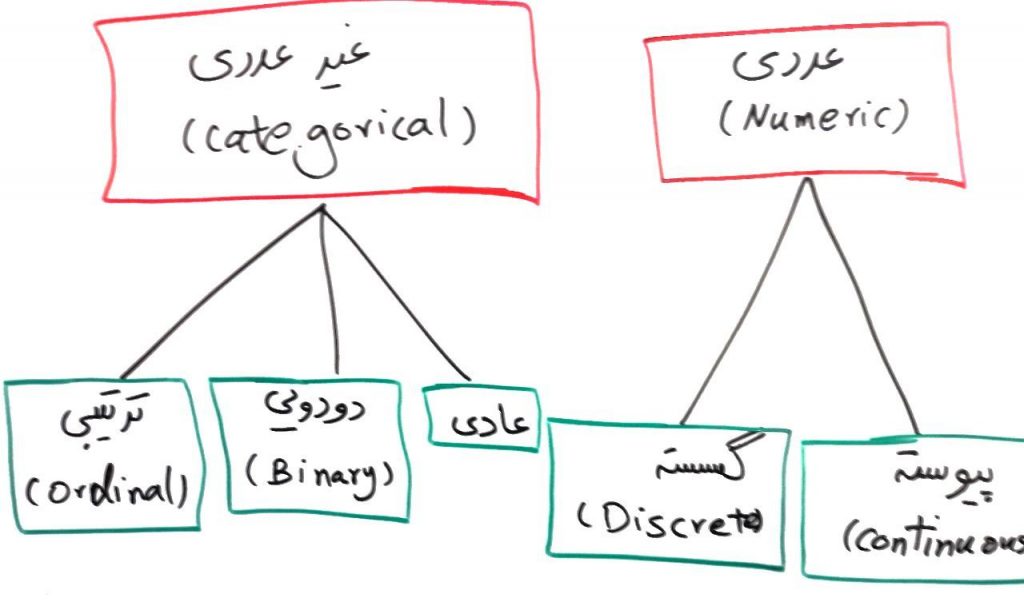
«کمی» (Quantitative): اندازهگیریها یا شمارشهایی که به صورت مقادیر عددی ذخیره شدهاند، دادههای کمی هستند. از جمله این موارد میتوان به درجه حرارت و قد افراد اشاره کرد.
«کیفی» (Qualitative): گروه یا دستهها، برای مثال دسته مدارک تحصیلی (دیپلم، فوق دیپلم، لیسانس، فوق لیسانس و دکترا) یا گروه رنگها (زرد، قرمز و آبی) از این جملهاند.
«ترتیبی» (Ordinal): چنین دادههایی دارای یک ترتیب طبیعی هستند. اندازه پیراهن (XL ،L ، M ،S و XXL) و مدارج تحصیلی (دبستان، راهنمایی، دبیرستان، کارشناسی، کارشناسی ارشد و دکترا) از این جملهاند.
«اسمی» (Nominal): اسامی دستهها، مانند وضعیت تاهل، جنسیت و رنگها از انواع دادههای اسمی هستند.
«عددی» (Numeric): دادههای عددی خود به دو دسته فاصلهای و نسبتی تقسیم میشوند. دادههای فاصلهای بر اساس مقیاس واحدهایی با اندازه برابر اندازهگیری میشوند. مقادیر ویژگیهای عددی دارای ترتیب هستند و میتوانند مثبت، صفر و یا منفی باشند. یک داده نسبتی، خصیصه عددی دارای یک صفر مطلق است. اگر اندازهها نسبتی باشند، میتوان از نسبت مقادیر با یکدیگر سخن گفت. به علاوه، مقادیر قابل مرتبسازی شدن هستند و میتوان تفاضل بین آنها، میانگین، میانه و مُد را محاسبه کرد.
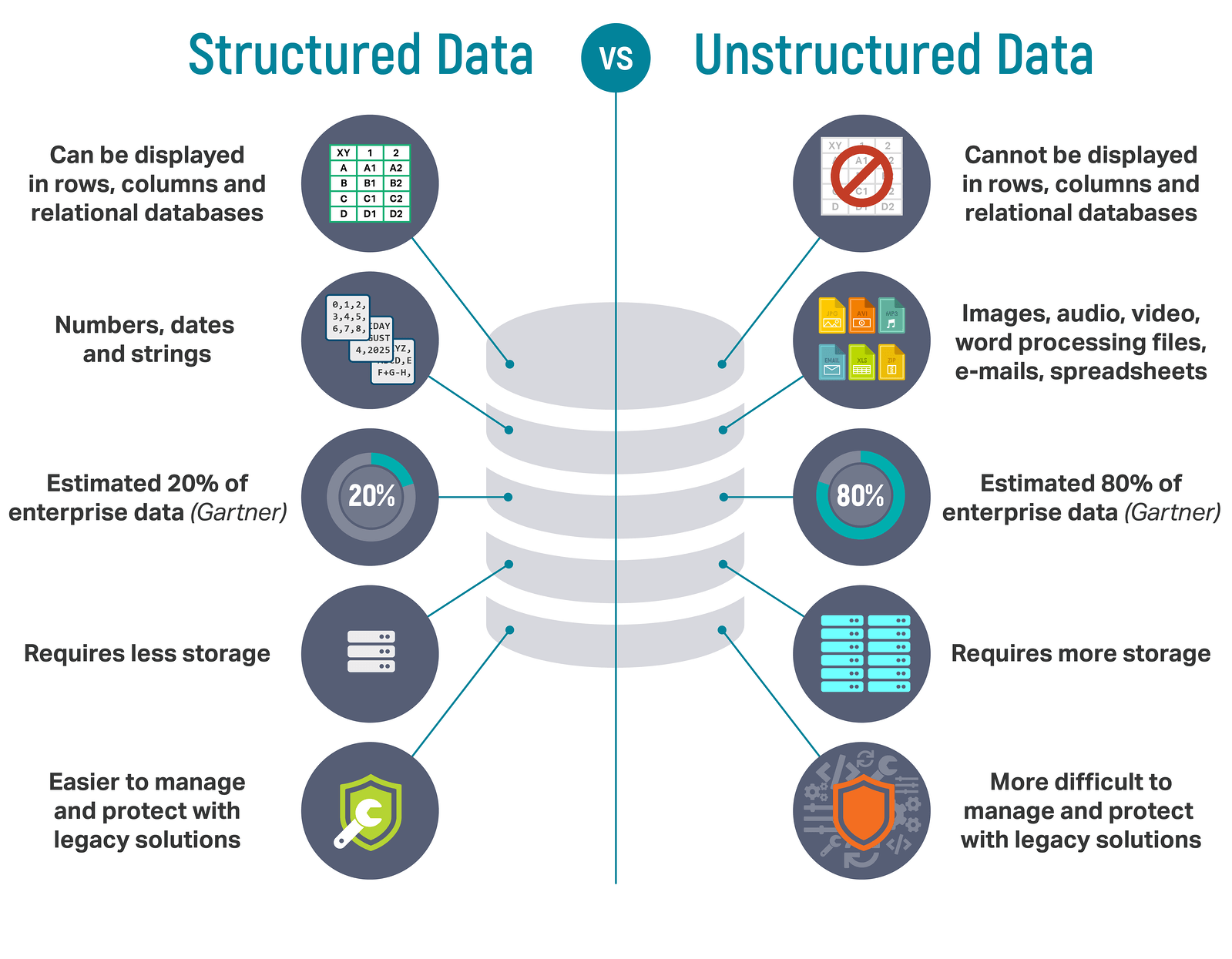
داده ساختاریافته (Structured) با غیرساختاریافته (Unstructured)
در بسیاری از مباحثِ دادهکاوی، یادگیریماشین و کلاندادهها (Big Data)، دادهها را میتوان به دو دسته تقسیمبندی کرد:
۱. دادههای ساختاریافته (Structured Data)
۲. دادههای غیرساختاریافته (Unstructured Data)
این دو نوع داده تفاوتهای اساسی با هم دارند و معمولا در عملیات دادهکاوی و یادگیریماشین سعی بر این است که دادههای غیرساختاریافته را به دادههای ساختاریافته تبدیل کنند تا برای ماشین (کامپیوتر) قابل فهم باشد.
حتماً با پایگاه دادههایی مانند Excel یا Sql Server کار کردهاید. این پایگاهدادهها معمولا سعی بر این دارند که دادهها را برای کامپیوتر قابل فهم کنند. در واقع دادههای ساختاریافته که در Excel یا پایگاهدادههای رابطهای مانندِ Sql Server داریم، دادههایی هستند که میتوان بر روی آنها عملیات مختلف را با الگوریتمهای شناختهشدهی کامپیوتری انجام داد. به این صورت است که میگوییم دادهها برای ماشین قابل فهم شده است.
مرحله سوم: آماده سازی یا پیش پردازش داده ها
این امکان وجود دارد که داده ها در سراسر سازمان توزیع شده و در قالب های مختلف ذخیره گردند و یا اینکه ممکن است شامل تناقضات و ناسازگاری هایی از جمله ورودی های نادرست یا از دست رفته باشند.
مراحل Data Cleansing یا تمیزسازی داده (با تلفظ: دیتا کلینزینگ)
۱- مجتمع کردن داده ها
۲- بازسازی داده های گم شده
۳- استانداد سازی یا یک شکل کردن داده
۴- نرمال سازی داده
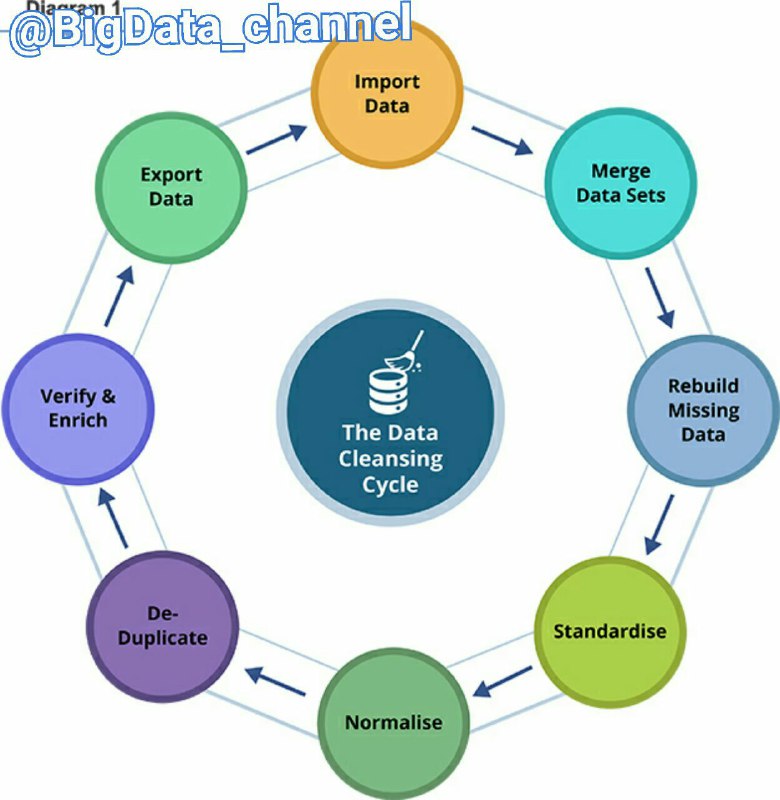
فرآیند پاکسازی داده ها (Data Cleansing) تنها به حذف داده های نامناسب یا وارد کردن مقادیر از دست رفته خلاصه نمی شود. پاکسازی کشف روابط پنهان شده ی میان داده ها، شناسایی دقیق ترین منابع داده و تعیین مناسب ترین ستون ها برای استفاده در آنالیز را نیز دربر میگیرد. لازم به ذکر است که داده های ناقص، داده های نادرست و داده های ورودی به ظاهر مجزا اما در حقیقت بسیار به هم پیوسته و مرتبط با یکدیگر، می توانند تاثیری فراتر از حد انتظار بر روی نتایج داشته باشند.
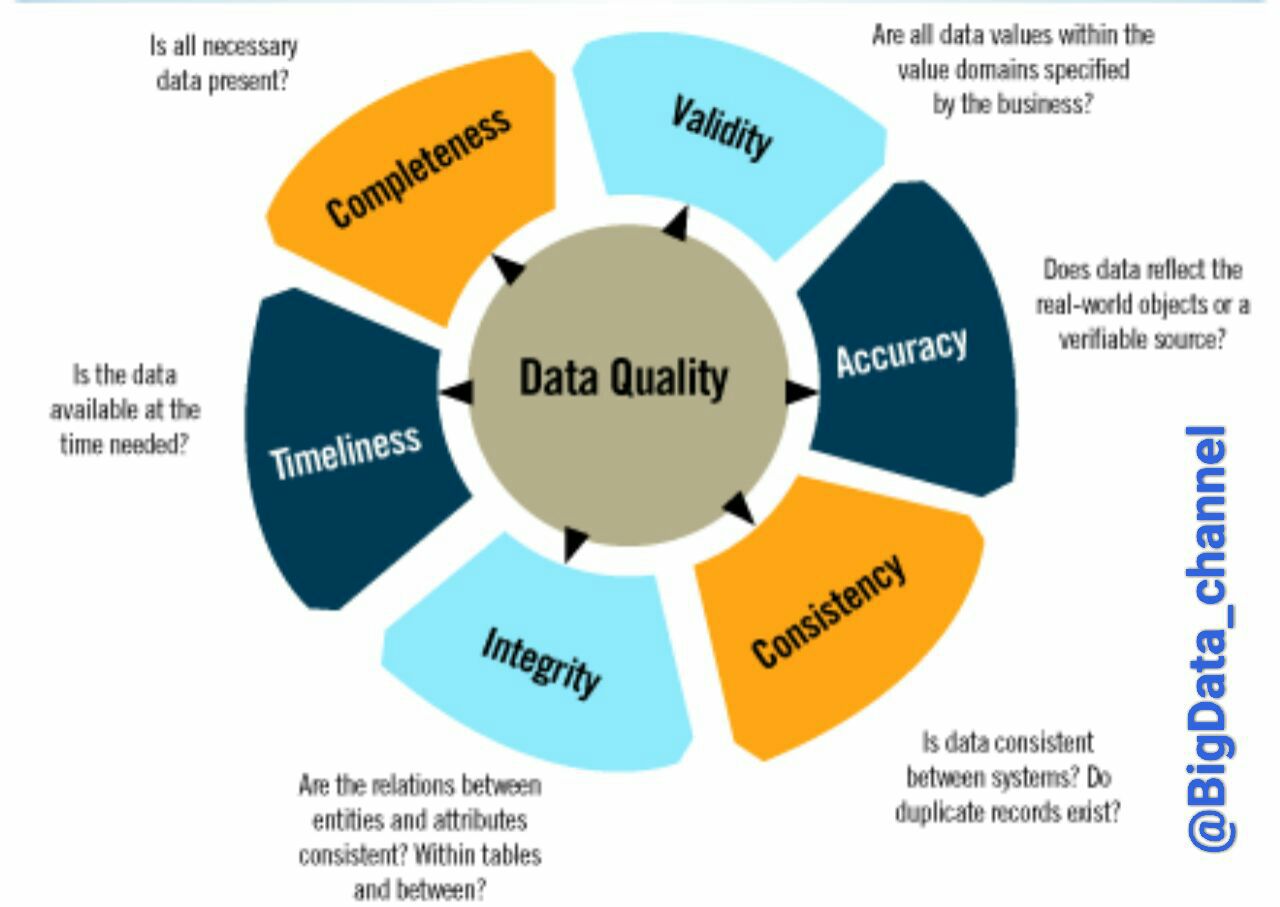
یک داده با کیفیت برای تحلیل معمولا شش ویژگی زیر را دارد:
۱- ارزش یا اعتبار داده
۲- دقت و صحت داده
۳- دوام یا پایداری داده
۴- یکپارچگی ارتباطات و بخش های مختلف داده
۵- بردار زمانی داده
تذکر:
الزامی در رابطه با ذخیره ی داده های مورد استفاده در داده کاوی بر روی یک پایگاه داده ی Cube OLAP و یا پایگاه های داده ی رابطه ای (Relational Database) وجود ندارد، اگرچه میتوان از هردوی آنها به عنوان منبع های داده استفاده نمود. بنابراین فرآیند داده کاوی را میتوان با استفاده از هر منبع داده ای که به عنوان منبع داده ی Analysis Services تعریف شده باشد، انجام داد. این منابع داده ممکن است شامل فایل های متنی (Text) و Workbookهای Excel یا داده های سایر منابع خارجی باشد.
نمونه برداری…
قابل جستجو کردن داده ها
از جمله تکنیک های جستجو میتوان به محاسبه ی حداقل و حداکثر مقادیر، محاسبه ی میانگین و انحراف معیار و توجه به توزیع داده ها اشاره نمود. به طور مثال، این امکان وجود دارد تا با بازنگری حداقل، حداکثر و میانگین مقادیر به این نتیجه گیری دست یافت که داده ها قادر به نمایش فرآیندهای مرتبط با مشتریان یا کسب و کار نبوده و از همین رو نیاز به کسب داده های متوازن تر یا بازنگری فرضیاتی است که انتظارات بر مبنای آن شکل گرفته است.
با توجه به انحراف معیار و سایر مقادیر توزیعی می توان به اطلاعات مفیدی درباره ی ثبات و دقت نتایج دست یافت. انحراف معیار بالا ممکن است نشانه ی آن باشد که افزایش میزان داده ها میتواند به بهبود مدل کمک نماید. داده هایی که انحراف زیادی از توزیع استاندارد داشته باشند احتمالا خطا دارند، بدین معنا که تصویر دقیقی از یک مسئله در دنیای واقعی ارائه میدهند اما تناسب و هماهنگی مدل با داده ها را دشوار می نمایند.
مرحله چهارم: مدل سازی
قدم چهارم مدلسازی داده های آماده سازی شده است. با توجه به متدهای متفاوت، مدل های متفاوتی ساخته می شود و بهترین مدل ها از نظر متخصص داده کاوی انتخاب می شود. ستون هایی از داده ها که برای استفاده در نظر گرفته شده اند را میتوان با ایجاد یک ساختار داده کاوی (Mining Structure)، تعریف نمود.
هرچند ساختار داده کاوی، به منبع داده ها مرتبط میگردد اما در واقع تا قبل از پردازش، شامل هیچ داده ای نمی شود و در هنگام پردازش نمودن ساختار داده کاوی، Analysis Services میتواند اطلاعات گردآوری شده و سایر اطلاعات آماری مورد استفاده برای آنالیز را ارائه نماید.
ضمن اینکه این اطلاعات در هر مدل داده کاوی ساختاریافته نیز مورد استفاده قرار میگیرد. پیش از پردازش ساختار و مدل، مدل داده کاوی نیز تنها یک ظرفیت خالی محسوب میشود که مشخص کننده ی ستون های مربوط به داده های ورودی، صفات یا Attribute های پیش بینی شده و پارامترهایی میباشد که نحوه ی پردازش داده ها توسط الگوریتم را معین میکند.
پردازش یک مدلِ اغلب Training یا آموزشی نامیده میشود و در واقع فرآیندی است جهت به کارگیری یک الگوریتم ریاضی خاص برای داده های یک ساختار و هدف آن، استخراج الگوها میباشد. نوع الگوهای یافت شده در روند Training به مواردی همچون انتخاب داده های Training، الگوریتم انتخاب شده و چگونگی پیکربندی الگوریتم بستگی دارد.
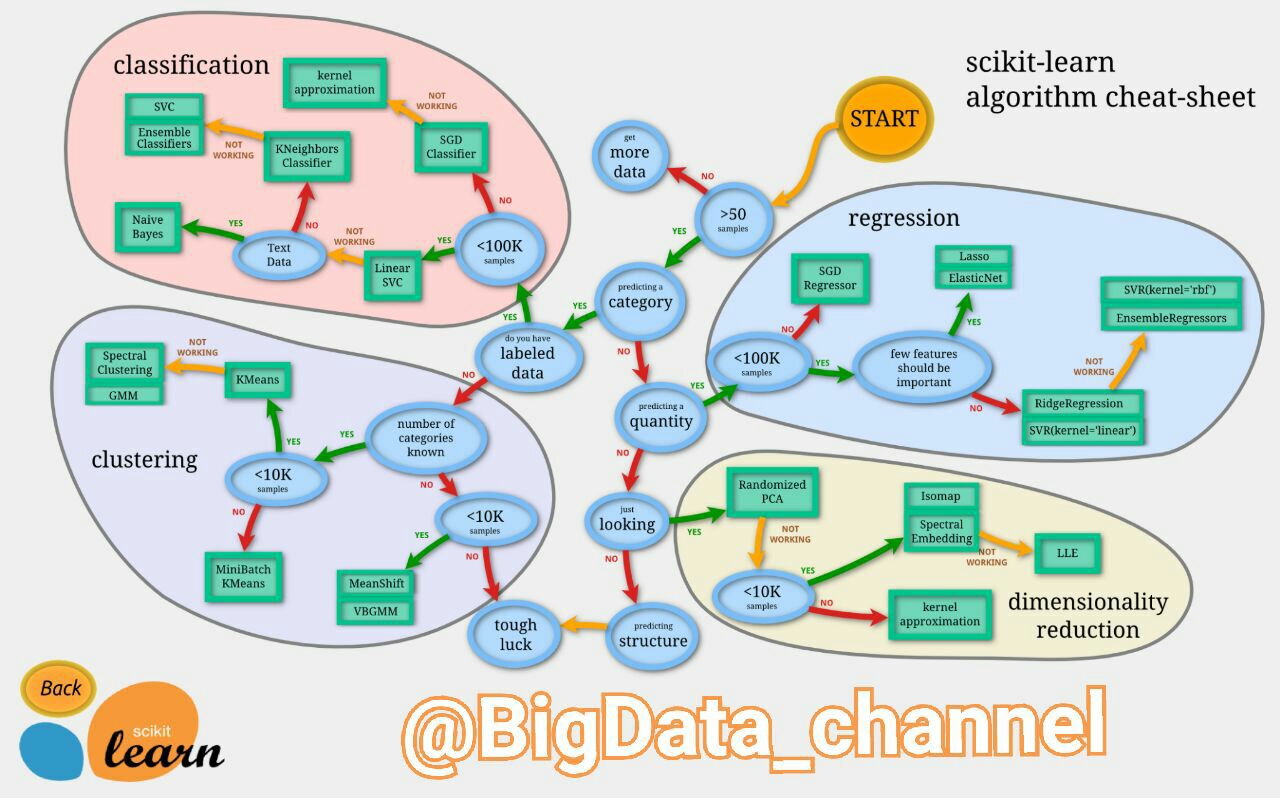
چگونه روش مناسب داده کاوی را تشخیص دهیم؟
تصویر زیر یک فلوچارتِ راهنمایِ بسیار خوب جهت تشخیص الگوریتم های داده کاوی در چهار حوزه طبقه بندی (یادگیری ماشین)، خوشه بندی، کاهش ابعاد و رگرسیون را ارائه میدهد. این تصویر راهنما، بر اساس مقدار دیتاستی که در دسترس است و نوع تحلیلی که قرار است رو آن انجام شود مسیر مطلوب را نمایش میدهد. مربع های سبز رنگ نشان دهنده نام الگوریتم ها و بیضی های آبی رنگ شرایط مورد نظر مبیاشد.
مرحله پنجم: تست و ارزیابی مدل
پیش از پیاده سازی مدل در محیط عملیاتی باید نحوه عملکرد آن مورد بررسی قرار گیرد. به علاوه در هنگام تهیه مدل معمولا باید چندین مدل با پیکربندی های متفاوت ارائه شوند تا پس از تست نمودن آنها بتوان به مدلی دست یافت که بهترین نتیجه را در ارتباط با مشکلات و داده ها فراهم می آورد.
مدل های ساخته شده تست و ارزیابی می شوند و بهترین مدل از نظر مسئله ی طرح شده در مرحله ی یک، انتخاب می شود. سپس در تبادل نظر با کارفرما، موثر بودن مدل انتخاب شده بررسی می شود. در صورتی که مدل انتخاب شده کمکی در حل مسئله نمی کند کل فرایند از مرحله ی یک دوباره انجام می شود.
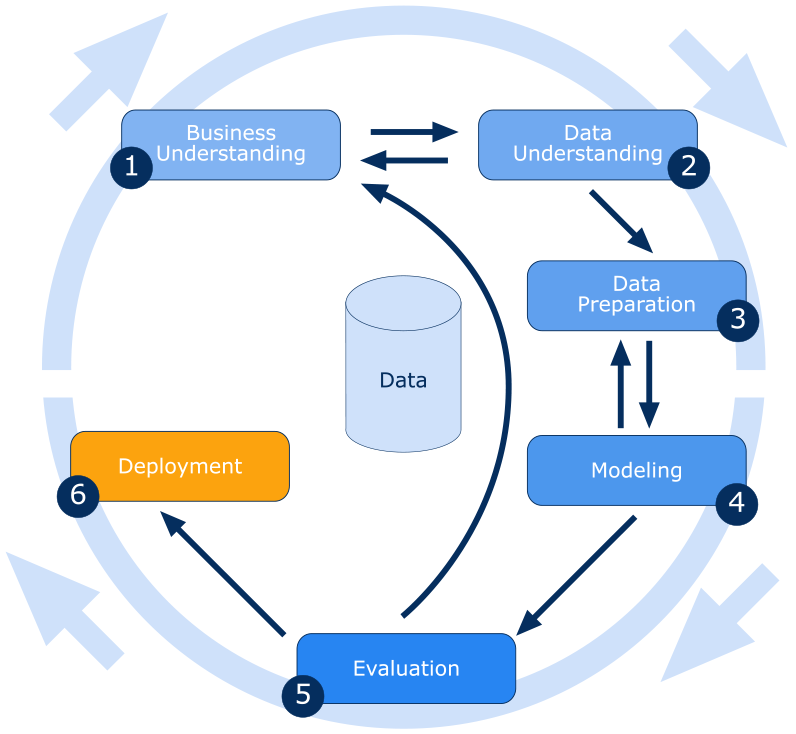
مرحله ششم: توسعه مدل نهایی و استقرار
پس از استقرار Mining Model در یک محیط عملیاتی میتوان عملکرد های بسیاری را با توجه به نیازها اجرا نمود. در زیر به برخی از این عملکردها اشاره می شود. استفاده از مدلها برای فرآیندهای پیش بینی که ممکن است در مراحل بعدی برای اتخاذ تصمیمات در کسب و کار نیز به کار گرفته شود.
. انجام Query های محتوا به منظور بازیابی اطلاعات آماری، قواعد یا فرمولهای مربوط به مدل ها
. جایگذاریِ مستقیم عملکرد داده کاوی در برنامه های کاربردی
. ارائه گزارشی که امکان Query نمودن مستقیم در مدل داده کاوی موجود را برای کاربران فراهم میکند.
انواع داده کاوی
در داده کاوی از الگوریتمها و شیوههای مختلفی استفاده میشود. روشهای اصلی داده کاوی به سه دسته کلی تقسیم میشوند: توصیفی و پیشگویی و تجویزی. این سه گروه، بیانگر اهداف و عملکرد روشهای داده کاوی نیز هستند.
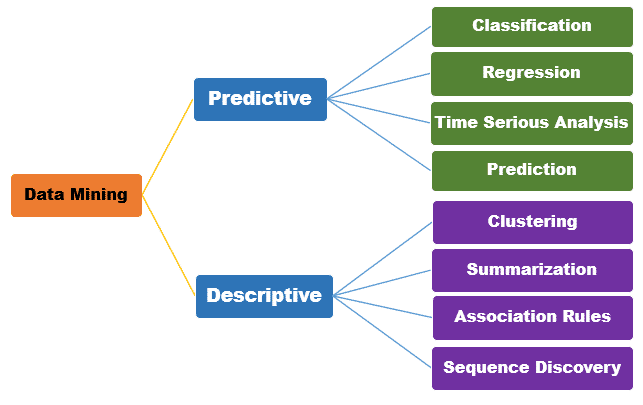
مدلسازی توصیفی
آشکارسازی موارد مشابه یا گروههای مشترک در دادههای موجود، با هدف تشخیص دلایل موفقیت یا شکست؛ از قبیل دستهبندی مشتریان بر اساس ترجیحات محصول یا احساسات آنها.
برخی تکنیکهای مورد استفاده در این روش عبارتند از:
- خوشهبندی (Clustering): گروهبندی رکوردهای مشابه
- کشف ناهنجاری (Anomaly detection): تشخیص الگوهای چندبعدی نامتعارف.
- یادگیری قانون وابستگی (Association rule learning): شناسایی روابط میان رکوردها.
- تحلیل مولفههای اصلی (Principal component analysis): شناسایی روابط میان متغیرها.
- گروهبندی شباهت (Affinity grouping): گروهبندی افراد با علایق مشترک یا اهداف مشابه. (مثال: مردمی که الف را میخرند، معمولاً ب را نیز میخرند و احتمال دارد که ج را نیز خرید کنند).
مدلسازی پیشبینانه
این مدل به گونهای عمیقتر، به دستهبندی رویدادها در آینده میپردازد و میکوشد نتایج ناشناخته را پیشاپیش برآورد کند. به عنوان مثال، با استفاده از امتیاز اعتباری یک فرد، میزان احتمال بازپرداخت اقساط وام او را تخمین میزند. مدل پیشبینانه همچنین در دستیابی به بینشهای مرتبط با اموری همچون رویگردانی مشتری، پاسخ به کمپین یا افول اعتبار کمک میکند. برخی تکنیکهای مورد استفاده در این روش عبارتند از:
- رگرسیون (Regression): اندازهگیری شدت رابطهی میان یک متغیر وابسته و مجموعهای از متغیرهای مستقلشبکههای عصبی (Neural networks): برنامههای رایانهای که میتواند الگوها را شناسایی کند، دست به پیشبینی بزند و آموزش ببیند.
- درختهای تصمیمگیری (Decision trees): نمودارهایی به شکل درخت که هر شاخه آن نشاندهنده یک رویداد احتمالی است.
- ماشینهای بردار پشتیبان (Support vector machines): مدلهایِ یادگیریِ تحت نظارت، در هماهنگی با الگوریتمهای یادگیری.
مدلسازی تجویزی
پا به پای رشد دادههای بدون ساختار در وب، فیلدهای اظهار نظر، کتابها، ایمیلها، فایلهای پیدیاف، منابع متنی و فایلهای صوتی، متن کاوی (text mining) نیز که یکی از شاخههای داده کاوی محسوب میشود، افزایش قابل توجهی داشته است. انواع تکنیکهای مرتبط با تحلیل متن:
– علامت گذاری متن
– متن کاوی
– طبقه بندی متن
– خوشه بندی متن
– نمایه گذاری متن
– مدل کردن پیشبینی
– تحلیل ارتباطات
– خلاصه سازی متن
– بصری سازی متن
دسته بندی
دسته بندی یا طبقه بندی در واقع ارزشیابی ویژگیهای مجموعهای از دادهها و سپس اختصاص دادن آنها به مجموعهای از گروههای از پیش تعریف شده است. این متداولترین قابلیت داده کاوی میباشد. در دسته بندی، به دنبال مدلی هستیم که با تشخیص دستهها میتواند دسته ناشناخته اشیاء دیگر را پیش بینی کند.
دسته بندی جهت پیشگویی مقادیر گسسته و اسمی مورد استفاده قرار میگیرد. دسته بندی نوعی یادگیری است که به کمک نمونهها صورت میگیرد و طبقه بندی بر اساس مجموعههای از پیش تعریف شده انجام میشود لذا میتوان گفت دسته بندی یادگیری با نظارت (هدایت شده) است.
دسته بندی فرآیندی دو مرحلهای میباشد. در گام اول، یک مدل بر اساس مجموعه دادههای آموزشی موجود در پایگاه دادهها ساخته میشود. این مدلها به فرمهایی از درخت تصمیم، یا فرمولهای ریاضی نمایش داده میشود. مجموعه دادههای آموزشی از رکوردها، نمونهها، مثالها و یا اشیائی که شامل مجموعهای از صفات یا جنبهها میباشد، تشکیل شدهاند.

رگرسیون
رگرسیون بهترین مدلی است که میتواند متغیرهای خروجی را با متغیرهای ورودی متعدد ارتباط دهد. سادهترین حالت آن، مدل به ارزش خطی است، یعنی ارتباط بین متغیرهای ورودی و خروجی را به صورت خطی برقرار میکند. از نقطه نظر کلی، دسته بندی و رگرسیون دو نوع اصلی از مسائل پیشگویی هستند، که دسته بندی، جهت پیشگویی مقادیر گسسته و اسمی مورد استفاده قرار میگیرد، در حالی که رگرسیون جهت پیشگویی مقادیر پیوسته مورد استفاده قرار میگیرد.
انواع مدلهای یکسانی را میتوان هم برای رگرسیون و هم برای دسته بندی استفاده کرد. برای مثال الگوریتم درخت تصمیم CART را میتوان هم برای ساخت درختهای دسته بندی و هم درختهای رگرسیون استفاده کرد. شبکههای عصبی را نیز میتوان برای هر دو مورد استفاده کرد.

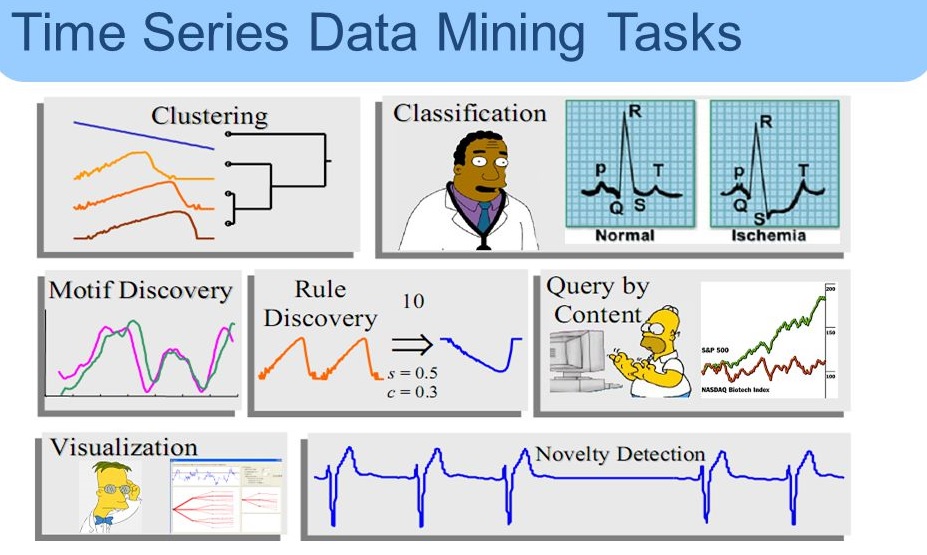
سریهای زمانی
تحلیل سریهای زمانی تکنیکی دیگر در دادهکاوی که هدف از آن، یافتن خصوصیات جالب توجه و نظمهای مشخص در حجم بالای داده است. یکی از سری های زمانی دنبالهای مرتب شده از مشاهدات است که،ارزش یک شیء را به عنوان تابعی از زمان در مجموعه دادههای جمع آوری شده توصیف میکند. رخداد وقایع متوالی در اصل مجموعهی وقایعی است که بعد از یک واقعهی مشخص به وقوع میپیوندند.
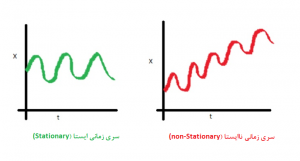
تکنیک های روش توصیفی
در روشهای توصیفی، خواص عمومی دادهها بیان میشود. هدف از توصیف، یافتن الگوهایی در مورد دادههاست که برای انسان قابل تفسیر باشد. روش توصیفی نیز شامل تکنیکهای: خوشه بندی، خلاصه سازی، کشف توالی (تحلیل دنباله) ، قوانین انجمنی میباشد.
خوشه بندی
خوشه بندی، گروه بندی نمونههای مشابه با هم، در یک حجم داده میباشد. خوشه بندی یک دسته بندی بدون نظارت (هدایت نشده) است. دستهها از قبل تعریف نشده اند. در خوشهبندی -بر خلاف طبقهبندی که هر داده به یک طبقهی (کلاس) از پیش مشخص شده تخصیص مییابد- هیچ اطلاعی از کلاسهای موجود درون دادهها وجود ندارد. به عبارتی خود خوشهها نیز از دادهها استخراج میشوند.
هدف از خوشه بندی این است که دادههای موجود، به چند گروه تقسیم شوند. در این تقسیم بندی دادههای گروههای مختلف حداکثر تفاوت ممکن را به هم داشته باشند و دادههای موجود در یک گروه باید بسیار به هم شبیه باشند. (تشابه یا عدم تشابه بر اساس معیارهای اندازه گیری فاصله تعریف میشود.) پس از اینکه دادهها به چند گروه منطقی و توجیه پذیر تقسیم شدند از این تقسیم بندی میتوان برای کسب اطلاعات در مورد دادهها یا تقسیم دادهها جدید استفاده کنیم.
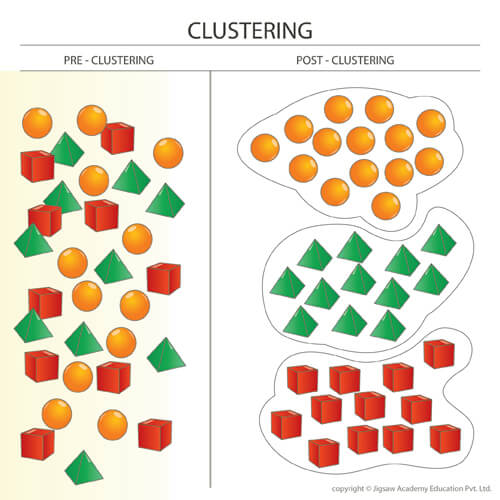
قوانین انجمنی
استخراج قواعد انجمنی، نوعی عملیات داده کاوی است که به جستجو برای یافتن ارتباط بین ویژگیها در مجموعه دادهها میپردازد. نام دیگر این روش، تحلیل سبد بازار است. این روش به دنبال استخراج قواعد، به منظور کمی کردن ارتباط میان دو یا چند خصوصیت میباشد. قواعد انجمنی ماهیتی احتمالی دارد و به شکل اگر و آنگاه و به همراه دو معیار پشتیبان و اطمینان تعریف میشوند. این دو شاخص به ترتیب مفید بودن و اطمینان از قواعد مکشوفه را نشان میدهند.

معیار اطمینان: میزان وابستگی یک کالای خاص را به دیگری بیان میکند. یعنی درجه وابستگی بین دو مجموعه X و Y را محاسبه میکند و به عنوان شاخصی برای اندازه گیری توان یک قاعده در نظر گرفته میشود. معیار پشتیبان (X,Y): نشان دهنده درصد یا تعداد تراکنش هایی (زیرمجموعههایی از اقلام خریداری شده) است که شامل هر دوی اقلام (مجموعه اقلام)X و Y باشند.

مثالهایی از کاربرد قوانین انجمنی میتواند این گونه باشد:
بررسی اینکه چه اقلامی در یک فروشگاه با هم خریداری میشوند و اینکه چه اقلامی هیچ گاه خریداری نمیشوند.
بررسی ارتباط بین توانایی خواندن کودکان با خواندن داستان توسط والدین برای آنها.
اگر مجموعهای از عناصر، حداقل پشتیبانی را داشته باشند، “مکرر” خوانده میشوند.
“قواعد قوی” قواعدی هستند که به طور توامان دارای مقدار پشتیبان و اطمینان بیش از آستانه باشند.
با استفاده از این مفاهیم پیدا کردن قواعد انجمنی در دو گام خلاصه میشود،: پیدا کردن مجموعههای مکرر و استخراج قواعد قوی.
خلاصه سازی (تلخیص)
در برگیرنده روشهایی برای یافتن یک توصیف فشرده از زیر مجموعهای از دادهها است. به عنوان مثالی ساده میتوان اشاره داشت به: تهیهی جدول میانگین و انحراف معیار برای تمام فیلدها. روشهای پیچیدهتر شامل استنتاج قواعد خلاصه، فنون مصورسازی چند متغیره و کشف رابطه تابعی بین متغیرهاست. کاربرد فنون تلخیص معمولاً در تحلیل اکتشافی دادهها و تولید گزارش خودکار به کار برده میشوند.
مدلسازی وابستگی (تحلیل لینک)
شامل یافتن مدلی برای توصیف وابستگیهای معنی دار بین متغیرهاست. مدلهای وابستگی در دو سطح وجود دارند: سطح ساختاری و سطح کمّی. در سطح ساختاری، مدل از طریق رسم شکل مشخص میکند که کدام متغیرها به طور محلی به دیگری وابستهاند. در سطح کمّی، مدل قدرت وابستگیها را با مقیاس عددی مشخص میکند.
وابستگیها به صورت A->B نمایش داده میشوند که به A مقدم و به B موخر یا نتیجه گفته میشود. مثلاً اگر یک قانون به صورت زیر داشته باشیم:
” اگر افراد چکش بخرند، آنگاه آنها میخ خواهند خرید”
در این قانون مقدم، خرید چکش و نتیجه، خرید میخ میباشد.
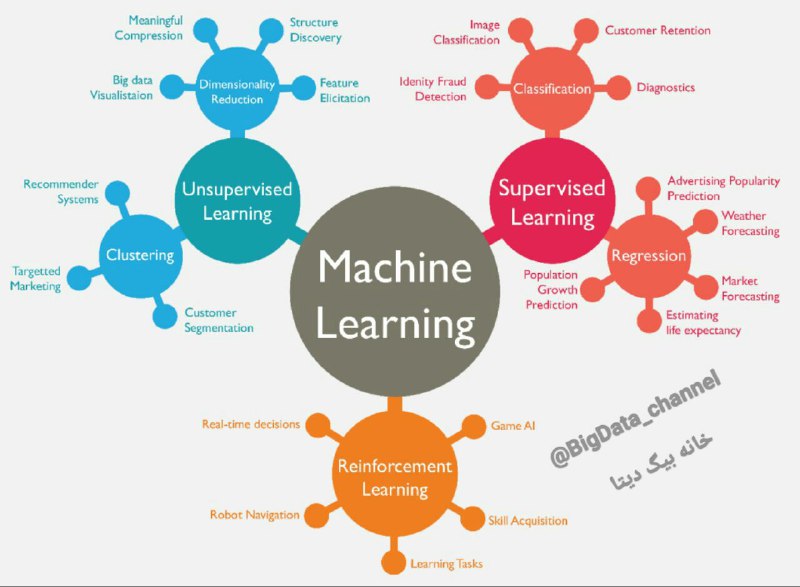
نمودار انواع روش های یادگیری ماشین همراه با مورد استفاده (Use Case):
- روش های یادگیری بی نظارت مانند:
خوشه بندی
کاهش ابعاد
- روش های یادگیری با نظارت مانند:
رده بندی
رگرسیون
- روش های یادگیری تقویتی
نرم افزارها و ابزار هایی داده کاوی
بدون شک، زبان برنامه نویسی و بسته نرم افزاری R یکی از مهم ترین و کارآمدترین ابزارها در زمینه تحلیل و استنتاج آماری و انجام انواع محاسبات است. زبان برنامه نویسی R، امکانات فراوانی نیز، برای انجام عملیات داده کاوی و پیاده سازی الگوریتم های مربوط به آن است. این بسته نرم افزاری، کاملا رایگان و متن باز است. برای داده کاوی از نرم افزار های مختلفی میشود استفاده کرد از جمله:
یکی دیگر از ابزارهای مهم و کاربردی در زمینه داده کاوی، نرم افزار اکسل (Microsoft Excel) است، که به صورت پیش فرض و بعضا با افزودن برخی افزونه های تجاری، امکان انجام عملیات داده کاوی را فراهم می آورد.
نرم افزار رپیدماینر (RapidMiner)
نیز، یکی دیگر از نرم افزارهای تخصصی داده کاوی است که امکانات متعددی را برای انجام انواع عملیات داده کاوی، یادگیری ماشین، پردازش متن، پیش بینی و تحلیل اقتصادی-مالی، تدارک دیده است. نسخه های قدیمی تر این نرم افزار به صورت متن باز منتشر شده اند؛ اما نسخه جدید آن، به صورت تجاری در دسترس قرار گرفته است.
بسته نرم افزاری Weka
یکی دیگر از مجموعه های نرم افزاری متن باز است که به زبان جاوا پیاده سازی شده است، و گروهی مستقر در دانشگاه وایکاتو (Waikato) در کشور نیوزلند، مسئولیت توسعه و نگهداری این بسته نرم افزاری را بر عهده دارند. این مجموعه نرم افزاری به صورت اختصاصی برای انجام عملیات یادگیری ماشین پیاده سازی شده است، که طبعا کاربردهای فراوانی را می تواند در حوزه داده کاوی داشته باشند. این بسته نرم افزاری به صورت رایگان و متن باز توزیع شده است.
نرم افزار و زبان برنامه نویسی متلب (MATLAB)
به عنوان یک نرم افزار بسیار پر کاربرد، دارای امکانابت بسیار زیادی برای رشته های مختلف است، که از آن جمله می توان به موضوع تحلیل و استنتاج آماری، یادگیری ماشینی، سیستم های فازی، شبکه های عصبی مصنوعی، مدل سازی، بهینه سازی و پیش بینی اشاره کرد، که همگی دارای کاربردهای گسترده در داده کاوی هستند.
در کنار قابلیت های موجود در نرم افزار متلب، می توان با استفاده از زبان برنامه نویسی متلب نیز، الگوریتم های جدید و مورد نیاز را نیز پیاده سازی کرد. هسته اصلی نرم افزار متلب به صورت تجاری توزیع شده است. اما برخی کتابخانه ها و جعبه ابزارهای رایگان نیز برای انجام عملیات داده کاوی توسط گروه های پژوهشی و دانشگاهی مختلف قابل استفاده هستند.
مجموعه نرم افزارهای IBM SPSS
برای تحلیل آماری (IBM SPSS Statistics)، و داده کاوی و مدل سازی (IBM SPSS Modeler)، مجموعه ای قدرتمند از ابزارها را برای انجام عملیات مختلف داده کاوی فراهم کرده اند. این نرم افزار ها، به صورت تجاری ارائه شده اند.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
منابع:
https://peerj.com/articles/cs-267/
http://scikit-learn.org/
http://www.iranresearches.ir/دانلود-رايگان-خبرخوان-2/1772-همه-آنچه-درباره-داده-کاوی-باید-بدانیم.html
.http://blog.vla.ir/داده-کاوی-چیست-و-چه-فایده-ای-دارد؟.html/
http://aminaramesh.ir/1397/12/12/معرفي-شغل-داده-كاوی/
https://education.systemgroup.net/blog/داده-کاوی-چیست-و-چرا-مهم-است؟/
.http://www.dayche.com/data-mining-definition/
https://www.parsdata.com/articles/what-is-data-mining
http://www.iranresearches.ir/دانلود-رايگان-خبرخوان-2/1772-همه-آنچه-درباره-داده-کاوی-باید-بدانیم.html
http://amnhak.blog.ir/1393/05/26
بازدیدها: 35583
برچسبCRISP-DM Data Cleansing data mining datamining SPSS آماده سازی داده ابزارهای داده کاوی اعتبارسنجی داده الگوریتمهای داده کاوی انواع داده انواع داده کاوی پیش پردازش تحلیل داده تحلیل های آماری داده کاوی دیتا ماینینگ دیتاماینینگ روش های داده کاوی علم داده کاربرد داده کاوی کاربردهای داده کاوی گام های داده کاوی مدل های داده کاوی مراحل داده کاوی نتایج داده کاوی
نوشته های مرتبط












همچنین ببینید
آموزش کامل شبکه عصبی ( artificial neural network) و نحوه استفاده آن
از چند دهه گذشته که رایانهها امکان پیادهسازی الگوریتمهای محاسباتی را فراهم ساختهاند، در راستای شبیهسازی …
آموزش کامل یادگیری ماشین (Machine learning) به صورت گام به گام
مقدمه ای بر یادگیری ماشین یادگیری ماشین بزرگترین راه حل بشر برای انجام کارهای پیچیده …
3 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

مطالب خلاصه شده و خوبی ارائه شده است . به نظر می رسد برگزاری کلاس های کاربردی با موضوع خاص ( مثلا یک کارگاه یا دوره کامل با تعریف پروژه از قبل ) بتواند دوره خوبی باشد . چون عمده دوره ها و کارگاهها عمومی است و در نهایت به یک پروژه کامل ( بصورت الگو ) تبدیل نمی شود .
در هر صورت ممنون از شما
ممنون از مطالب مفید تون.
این فیلم هم میتونه سبب کمک علاقه مندان به این حوزه باشه
https://www.aparat.com/v/SaJ7s