 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
همه چيز درمورد مکعب داده (Data Cube) و OLAP با مثال عملي
مکعب داده يا OLAP چيست؟ نوع پایگاه داده ای که تراکنش ها را ذخیره می کند، OLTP یا پردازش تراکنش آنلاین نامیده می شود و برای عملیات ساده مانند درج ، به روز رسانی یا حذف یک مورد کاملاً مناسب است. ولي وقتی صحبت از تجزیه و تحلیل حجم زیادی از داده ها از زوایای مختلف می شود ، منطق OLTP دارای محدودیت های جدی است. بنابراین ، ما به راه حلی نیاز داریم که بتواند داده ها را از ابعاد مختلف نشان دهد.
یک مکعب OLAP به تجزیه و تحلیل ها اجازه می دهد تا اقلام را بر اساس دسته های مختلف گروه بندی یا برش دهند. آنها در درجه اول برای اجرای پرس و جوهای پیچیده طراحی شده اند ، که توسط پایگاه های داده معمول OLTP قابل انجام نیستند.
عناوين مطالب: '
- مکعب داده (Data Cube) و OLAP چیست؟
- جایگاه OLAP یا مکعب داده
- درک مکعب داده
- درک تفاوت OLAP و OLTP
- مدل سازی داده ها در OLAP
- جدول واقعیت (Fact Table)
- انبار داده و اتباط آن با مکعب
- اجزای OLAP
- اعمال اصلی در مکعب داده
- ارائه دهندگان محصولات OLAP
- محصول Microsoft SQL Server Analysis Services (SSAS)
- نقش پایگاه داده های ستون گرا در ایجاد مکعب داده
مکعب داده (Data Cube) و OLAP چیست؟
مفهوم ديتا کيوب(Data Cube) و OLAP (Online Analytical Processing) بسیار نزدیک بوده تا جایی که میتوانیم برای این دو واژه یک مفهوم را در نظر بگیریم. در واقع مکعب داده یک تکنیک اصلی برای تحلیل های OLAP است. مکعب داده لزوما یک ساختار سه یعدی نیست. مکعب داده یک محدوده سه بعدی کمتر یا بالاتر از داده های به هم مرتبط است که معمولا برای توضیح توالی زمان یک داده استفاده میشود.
مکعب داده به راحتی دادهها را تفسیر میکند و هنگامی مفید است که بخواهید دادهها را با ویژگیهایی به عنوان سنجههای مشخصی از نیازهایِ کسب و کار، ارائه دهید. مکعب داده ها برای نمایش دادههای پیچیده، که توسط جدولی از سطرها و ستونها توصیف میشود، استفاده میشوند که در آن داده ها به صورت چند بُعدی نمایش داده شده و هر بُعد یک ویژگی از انبار داده را نشان میدهد. به عنوان مثال، فروش روزانه، ماهانه یا سالانه.
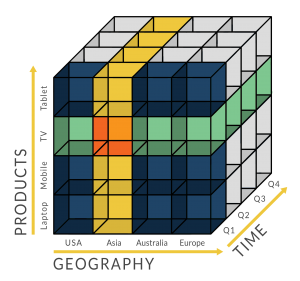
جایگاه OLAP یا مکعب داده
olap مولفه اصلی فرایند رسیدن از داده به اطلاعات و رسیدن از اطلاعات به دانش است. هوشتجاری در واقع فرآیند تبدیل دادههای سازمان به ارزش (Value) برای آن سازمان است و برای این کار از انبار داده (Data Warehouse) استفاده میکند تا دادهها را در گوشهای انبار کند و بتواند از آنها در مواقع لازم استفاده نماید. در این مبحث میخواهیم یکی از روشهای معروف انبار کردن دادهها که به آن مکعب داده یا همان Data Cube گفته میشود را با هم دیگر مرور کنیم تا دید بهتری در حوزه انبار کردن دادهها به دست بیاوریم.
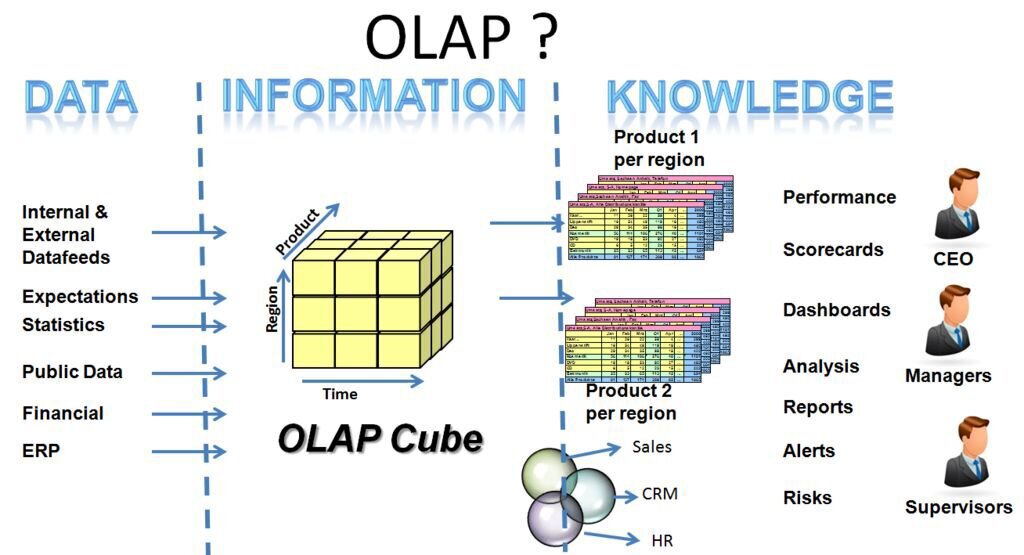
درک مکعب داده
حتما با پایگاهدادههای رابطهای مانند SQL و نرمافزار Excel یا Access آشنا هستید. در این حالت ذخیره دادهها که در SQL و یا Excel مورد استفاده قرار میگیرد، دادهها به صورت دو بُعدی (مستطیلی) ذخیره و نمایش داده میشوند. یه این حالت ذخیره سازی دادههای مستطیلی گفته می شود. در مبحث دادهکاوی هر ستون نمایانگر یک بُعد از داده است. اما در مکعبداده موضوع فرق میکند. در مکعبداده، دادهها به صورت چند بُعدی نمایش داده میشوند و هر بُعد یک ویژگی از انبارداده ما را نمایش میدهد. توجه کنید که ما برای راحتی دادهها را ۳بُعد فرض کردهایم در حالی که انبار داده میتواند بینهایت بُعد (ویژگی) داشته باشد که با توجه به آنها میتوانید دادههای خود را تحلیل کنید.
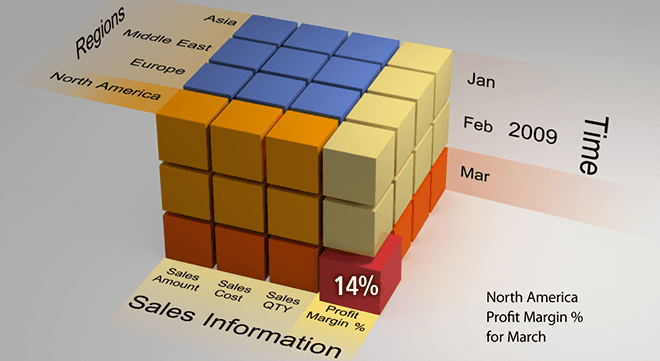
مثالی از کاربرد مکعب داده
فرض کنيد میخواهیم فروش یک سازمان را بررسی کنیم و برای اینکار، سابق بر اين از پایگاهدادها با جداول مختلف، استفاده ميکرديم. مثلا اگر میخواستیم فروش فصل اول در شهر تهران چقدر بوده است براي این کار بدون استفاده از مکعب داده میبایستی برای هر سوال یک پرس و جو (Query) بر روی پایگاه داده مینوشتیم
توجه داشته باشيد که ابعاد اين کوئري خیلی بیشتر از این ۳بُعد است) و این نیازمند Joinهای مختلف و Query سنگین بود که برای پایگاهدادههای بزرگ احتمالا زمان زیادی (حتی در حد چند ساعت) تلف میشد. ولی در مکعب داده و با کمک سیستمهای OLAP میتوان این دادهها را با توجه به موضوع خاصی که به دنبال آن هستیم (در این مثال مقدار فروش) تجمیع و گردآوری کنیم و به سرعت پاسخ پرس و جو (Query)های خود را به دست آوریم.
درک تفاوت OLAP و OLTP
ساده ترین راه برای درک نحوه عملکرد OLAP مقایسه پایگاه های داده OLAP و OLTP و بررسی نحوه ساختار و پردازش آنها است. بین پایگاه های داده OLTP و OLAP از نظر هدف ، ساختار اطلاعات و قابلیت دسترسی به اطلاعات تفاوت های زیادی وجود دارد. جدول زیر جنبه های اصلی این دو سیستم را مقایسه می کند.
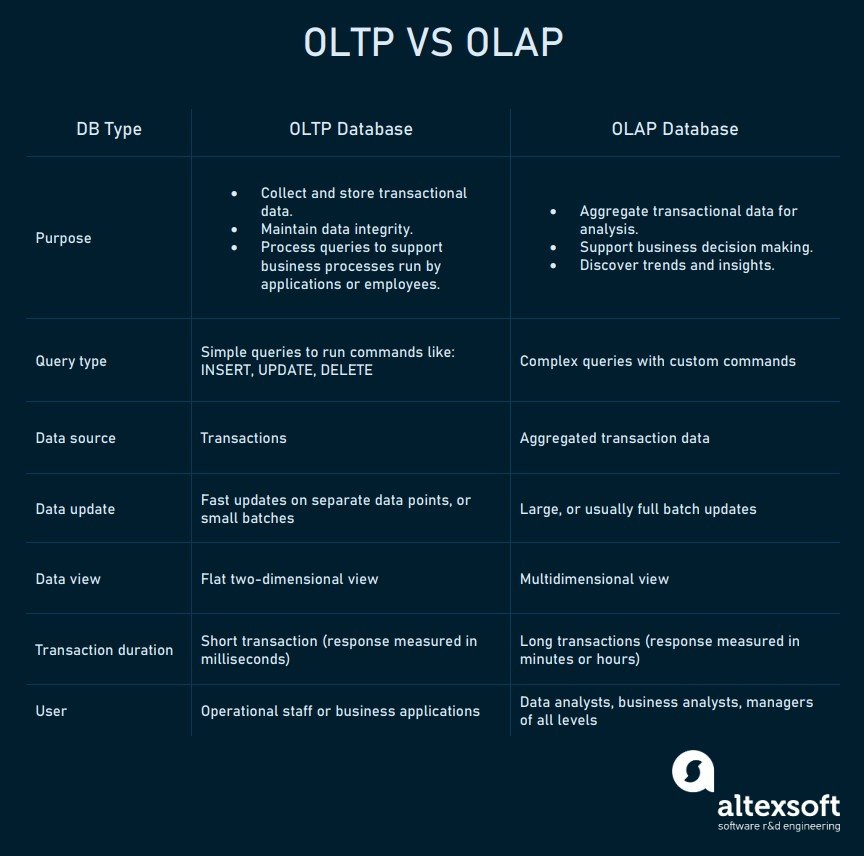
عملیات داده در OLTP
پایگاه داده معاملاتی یا OLTP یک راه حل ذخیره سازی رایج است که ما برای ثبت هرگونه اطلاعات تجاری با آن سروکار داریم. بگویید ، ما نوع جدیدی از تلفن هوشمند را به مشتری می فروشیم و می خواهیم این تراکنش را از جمله نوع محصول ، قیمت ، تاریخ ، اطلاعات مشتری ، نام فروشنده و غیره ثبت کنیم. همه این موارد در یک نمای مسطح ، که به ما امکان می دهد به سرعت کار کرده و اطلاعات مورد نیاز را جستجو کنیم. داده ها به عنوان مجموعه ای از اقلام و مقادیر مربوط به این تراکنش ذخیره می شوند. یک راه حل OLTP به کاربر امکان می دهد عملیات زیر را با این داده ها انجام دهد:
- insert
- copy
- paste
- edit/update, and
- delete
چنین معاملاتی دارای زمان پاسخ کوتاه هستند – در ثانیه اندازه گیری می شود – زیرا برای OLTP طبیعی هستند. اما وقتی نوبت به پرس و جوهای پیچیده تری می رسد که شامل تجمیع داده ها از جداول متعدد است ، یک پایگاه داده تراکنش دچار مشکل می شود. هرچه داده های بیشتری مورد پرسش قرار گیرد ، برای OLTP مشکل تر و منابع بیشتری خواهد بود.
عملیات داده در OLAP
OLAP یا پردازش تحلیلی آنلاین ، داده های معاملاتی را از یک ذخیره سازی تجمیع می کند تا آن را به یک فرم قابل تجزیه و تحلیل تبدیل کند. به عنوان منبع داده ، OLAP می تواند از نوعی ذخیره سازی یکپارچه مانند انبار داده ، دریاچه داده یا داده مارت یا به سادگی هر مکانی که داده های تاریخی را ذخیره می کنید استفاده کند.
اما برای اجرای پرس و جوهای پیچیده سفارشی ، باید داده ها را به درستی ساختار دهیم. به همین دلیل است که در بیشتر موارد ، نیاز به پایگاه داده یا انبار OLAP جداگانه ای وجود دارد که داده ها را برای تجزیه و تحلیل چند بعدی مدل کند.
پرس و جو در OLAP ممکن است چیزی شبیه به این باشد:
- “نمایش فروش گوشی های هوشمند 64 گیگابایتی در وینیپگ در 6 ماه گذشته ،”
- “فروش 64 گیگابایتی مدل کانادا را با 256 گیگابایت در سه ماهه چهارم مقایسه کنید.”
- “همه مدلهای 64 گیگابایتی برای فروش 2021 توسط فروشنده جان دو” گروه بندی شود “
- “حاشیه متوسط را برای یک فروشنده تلفن هوشمند مشخص در سال جاری نشان دهید.”
چنین پرسش های تحلیلی به پایگاه داده نیاز دارد تا اطلاعات را از جداول متعددی جمع آوری کند که داده ها را بر اساس “ابعاد” طبقه بندی می کند. نمونه ای از ابعاد می تواند زمان ، محصول ، مکان ، مشتری و غیره باشد.
OLAP یک پایگاه داده را به گونه ای مدل می کند که امکان جمع آوری سریع داده ها و ارائه آنها به تحلیلگران به صورت چند بعدی و نه به عنوان یک میز صاف وجود دارد. به همین دلیل پایگاه های داده OLTP و OLAP از جهات مختلف متفاوت خواهند بود.
حال ، ما باید به دو سوال simple ساده پاسخ دهیم. مدل سازی داده های OLAP چگونه با پایگاه های داده تراکنش متفاوت است؟ و چرا ما نمی توانیم چنین درخواست های پیچیده ای را در OLTP اجرا کنیم؟
مدل سازی داده ها در OLTP
پایگاه های داده سنتی (OLTP) از یک مدل داده رابطه ای استفاده می کنند ، از این رو نام آن “پایگاه داده رابطه ای” است. روابط چیزی جز جداول ارزشها نیستند. هر سطر در جدول یک رابطه واقعی یک مورد با ویژگی آن را نشان می دهد. به عنوان مثال ، یک مشتری ممکن است دارای ویژگی های مرتبط مانند آدرس ، ایمیل ، کارت اعتباری ، نام و غیره باشد.
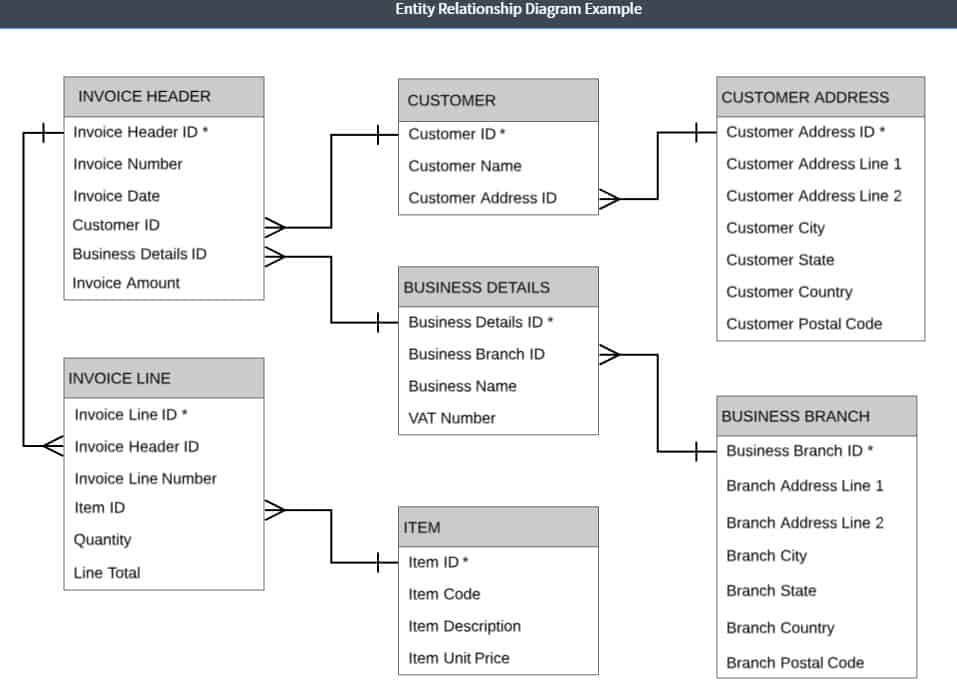
این استاندارد ترین روشی است که ما داده ها را ذخیره کرده و اطلاعات تراکنش ها را تغییر می دهیم. چنین رویکردی برای پرس و جوهای ساده برای تغییر داده های تراکنش عالی عمل می کند. اما اگر بخواهیم چیزی مانند “مقایسه فروش یک محصول در سه ماهه سوم در سه سال گذشته در ایالات متحده” را بپرسیم – پایگاه داده رابطه ای به منابع عظیمی نیاز دارد زیرا هر جدول را به طور کامل اسکن می کند تا همه مقادیر مرتبط را پیدا کند.
علاوه بر این ، پرس و جو اقلام داده متفاوتی را با بسیاری از اطلاعات غیر ضروری برمی گرداند ، زیرا مدل رابطه ای از فیلتر کردن در ابعاد متعدد به طور همزمان پشتیبانی نمی کند (نوع محصول ، دوره زمانی ، مکان).
مدل سازی داده ها در OLAP
در مقابل ، OLAP از طرحواره های ستاره ای و دانه برفی برای مدل سازی داده ها استفاده می کند.
مدل ستاره ای
در طرح ستاره ما داده ها را بر اساس حقایق (Fact) ساختار می دهیم و کلیدهای هر ابعاد را برای اندازه گیری ارائه می دهیم. در این مورد ، یک دسته از اقلام تجاری مرتبط ، به عنوان مثال ، محصول ، میزان فروش ، درآمد ، مشتریان ، زمان ، مکان و غیره است. هر یک از این موارد یک بعد جداگانه است که شامل زیر مجموعه ها می شود. بنابراین می توانیم مثلاً زمان به سال ، ربع ، ماه ، هفته و روز تقسیم کنیم.
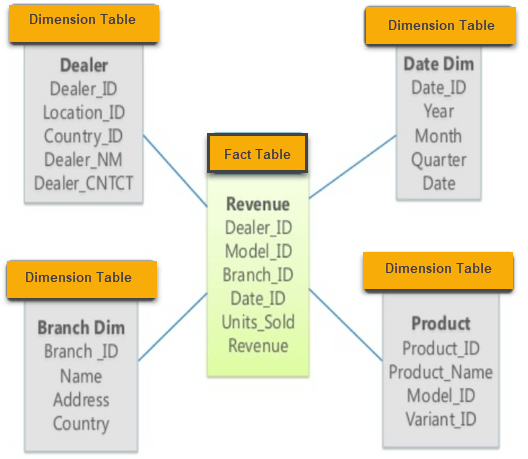
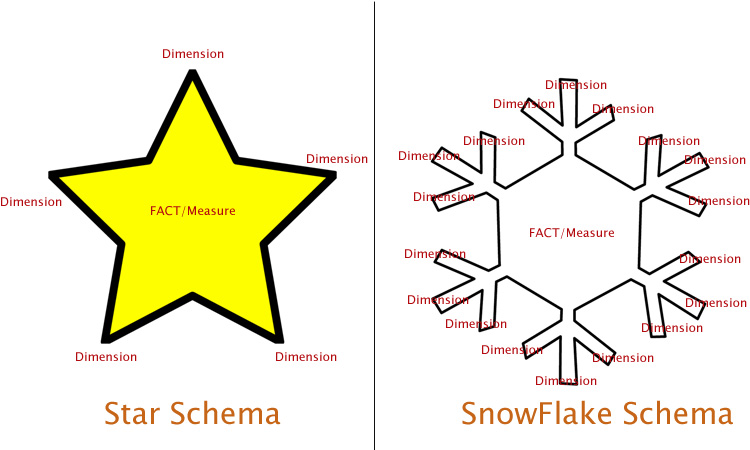
مدل دانه برفی
طرح واره برف یک بسط به طرح ستاره است: اساساً ابعاد بیشتری را به ابعاد موجود اضافه می کند. اما داده ها هنوز در اطراف جداول واقعی سازماندهی شده اند. بنابراین اگر جداول ابعاد بیشتری اضافه کنیم ، پایگاه داده شروع به شکل “دانه برف” می کند.
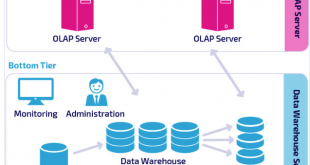
انبار داده و اتباط آن با مکعب
انباره داده معمولا مبتنی بر ساختارهای دادههای چند بعدی مدل میشود. این ساختارها داده مکعب – Data Cube – نامیده میشوند. در داده مکعب هر بعد با یک خصوصیت یا مجموعهای از خصوصیتها در ارتباط است. انباره داده، مخزنی شامل مکعب داده های جمع آوری شده از چندین منبع مختلف است که این اطلاعات را تحت یک طرح واحد جمع آوری کرده است. مخازن اطلاعات معمولا در یک سایت واحد قرار میگیرند. انبارههای داده حاصل فرآیند پاکسازی داده، یکپارچهسازی داده، تغییر شکل داده، بارگذاری داده – Data Loading – و نوسازی دورهای داده – Periodic Data Refreshing – هستند.
ديتا کيوب هایی که در انباره داده وجود دارد، با هدف تسهیل تصمیم سازی بر اساس موضوعات اصلی تقسیمبندی میشوند. (برای مثال، مشتری، موارد کالا، تامینکننده و فعالیت) گردآوری دادهها با هدف به دستآوردن اطلاعات از چشم اندازهای تاریخی (برای مثال موضوعات مربوط به 6 تا 12 ماه گذشته) انجام شده و این اطلاعات معمولا در ادامه خلاصهسازی میشوند.

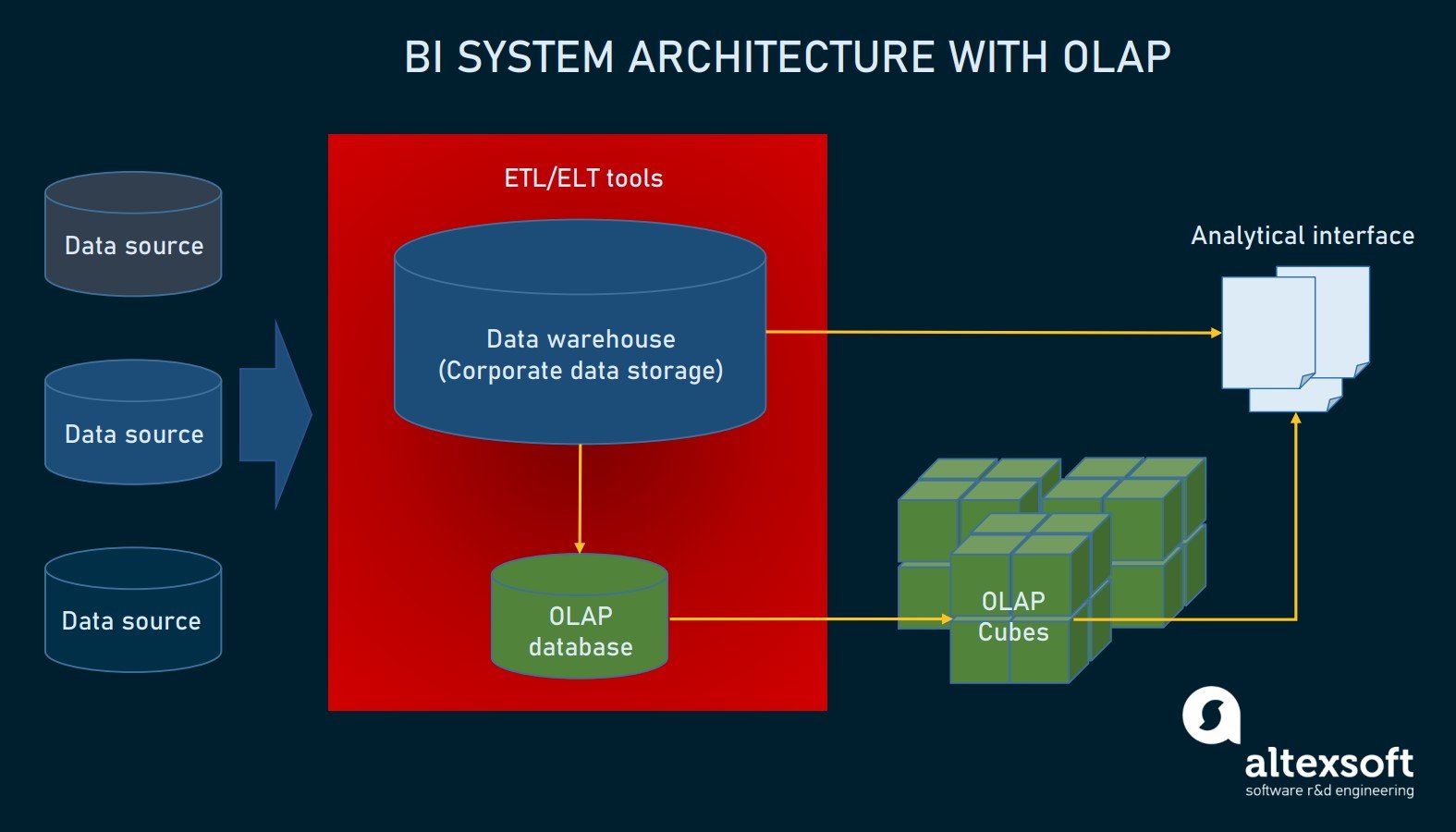
اجزای OLAP
منبع داده یا Data source:
این می تواند یک پایگاه داده تراکنش یا هر فضای ذخیره سازی دیگری باشد که ما از آن اطلاعات می گیریم. داده ها در قالب استاندارد برای درخواست های OLAP بهینه نشده اند ، بنابراین قبل از استفاده نیاز به تغییر و بازسازی دارند.
OLAP database
پایگاه داده OLAP جایی است که ما داده ها را برای تجزیه و تحلیل ذخیره می کنیم. معمولاً قبل از بارگذاری داده ها در پایگاه داده ، تغییر شکل می گیرد ، اما روش ممکن است متفاوت باشد.
OLAP cube
مکعب OLAP اساساً ابزاری برای نمایش داده های چند بعدی برای تجزیه و تحلیل است. همانطور که ما در مورد پردازش تحلیلی آنلاین صحبت می کنیم ، مکعب ها روی یک سرور اختصاصی مستقر می شوند.
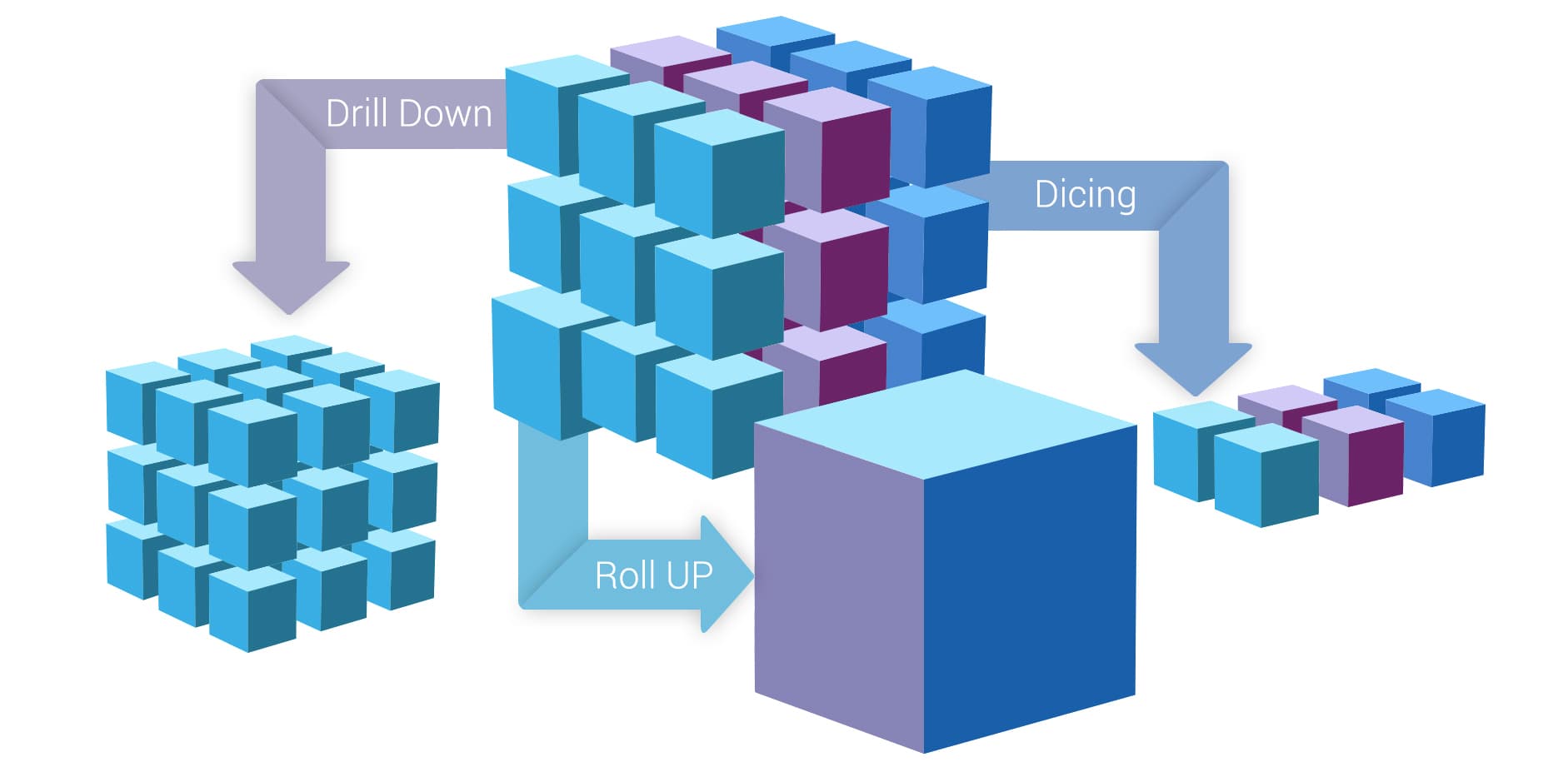
اعمال اصلی در مکعب داده
چند عمل اصلی در یک مکعب داده وجود دارد که هر کدام کاربرد و هدف ویژه ای در تحلیل و پردازش داده ها را دنبال می کند.
- Roll-up
- Drill-down
- Slice
- Dice
- Pivot (دووران)
- Scoping
- Screening
- Drill across
- Drill through
- Sort
- Add measure
- Drop measure
- Union
- Difference
Drill Down و Roll Up (حفاری و نورد)
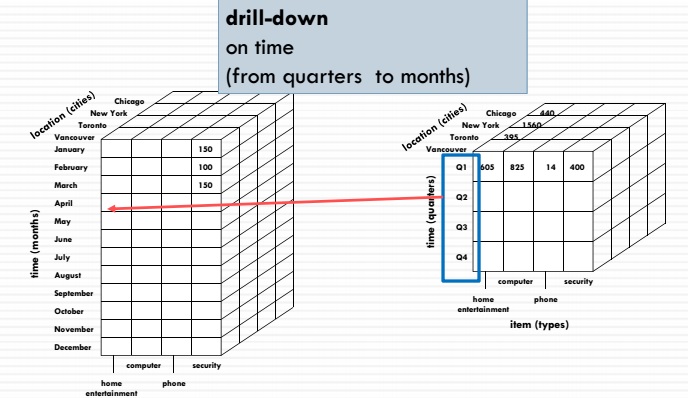
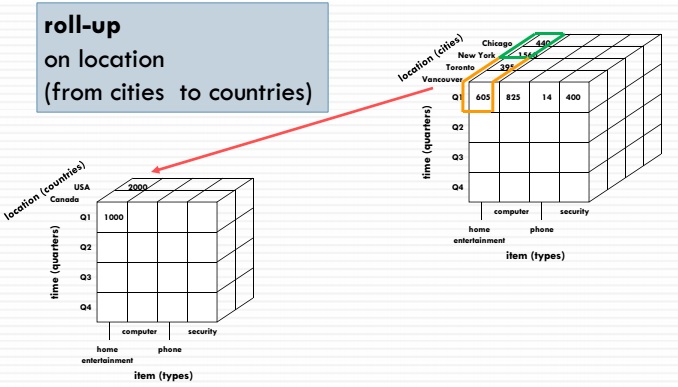
مفهوم Drill Down یا رفتن به عمق ساده است. فرض کنید میخواهیم Drill Down را بر روی بُعد زمان انجام دهیم. اگر در سطح فصل قرار داشته باشیم. حالا میخواهیم به یک سطح پایینتر برویم. سطح پایینتر فصل میتواند ماه باشد. یعنی ماه در بُعد زمان از سطح فصل به سطح ماه Drill Down میکنیم. عکس عمل Drill Down، عمل Roll Up است.
بررسی دقیق به کاربر اجازه می دهد از داده های سطح بالا (به عنوان مثال فروش سالانه) به سطح پایین تری (به عنوان مثال فروش ماهانه) برسد. در اینجا ما از مفهوم سلسله مراتب استفاده می کنیم که برای هر بعد واحد کاربرد دارد. بنابراین ، در بعد “زمان” ، می توانیم از ارقام سالانه به سوابق هفتگی یا حتی روزانه برویم. این بستگی به نحوه ذخیره اطلاعات شما و مدل سازی مکعب واقعی دارد.
Roll up برعکس drill down است ، زیرا اساساً داده ها را در سطوح سلسله مراتبی بالا می برد. هر دو عملیات یا اطلاعات را بیشتر یا کمتر جزئی می کنند ، یا ابعادی را برای تجزیه و تحلیل اضافه می کنند.
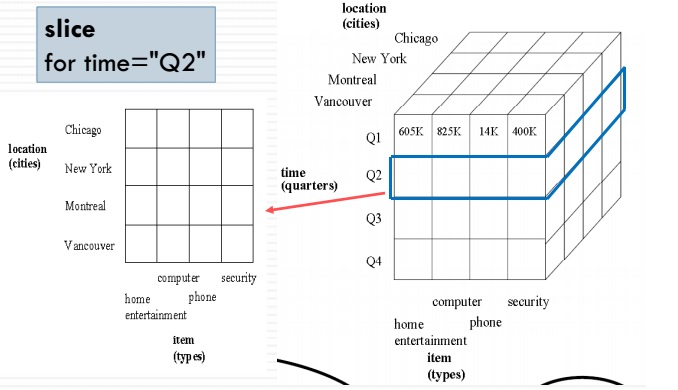
Slice و Dice (برش زنی و مقطع زنی)
دو عمل دیگر Slice و Dice هستند. این دو عمل نیز بسیار سادهاند. در عملیات Slice ما میتوانیم یک مقدار از یک بُعد را انتخاب کنیم و بقیه مقادیر آن را حذف کنیم. ( ابعاد دیگر باقی میمانند)
عملیات Dice هم به این صورت است که ابعاد حفظ میشوند ولی از هر بُعد میتوان یک یا چند مقدار را حذف کرد.
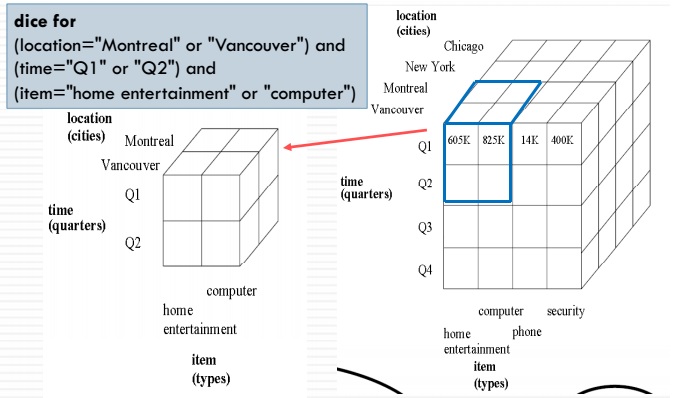
عملیات برش به شما کمک می کند تا بعد خاصی را به یک جدول جداگانه تقسیم کنید (نمای یک بعدی). “برش” می تواند ، مثلا ، ابعاد شهر را از بقیه مکعب جدا کند ، که یک صفحه گسترده جداگانه ایجاد می کند. به این ترتیب ما می توانیم اطلاعات سطح پایین را در محیط منزوی تجزیه و تحلیل کنیم.
Dice عملکرد جداسازی یکسانی را ارائه می دهد ، اما به شما امکان می دهد بیش از یک بعد را انتخاب کنید و یک مکعب جداگانه تولید کنید.
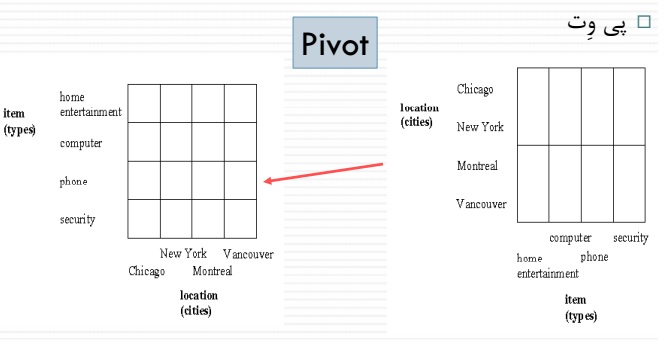
Pivot یا دوران
یک عملیات دیگر عملیات Pivot یا چرخش در Data Cube است. در این عملیات جای ابعاد عوض میشود.
ارائه دهندگان محصولات OLAP
OLAP بخش حیاتی هر سیستم BI است. با وجود ماهیت زیاد منابع ، OLAP یک راه حل استاندارد برای تجزیه و تحلیل های پیچیده است که در پایگاه های داده معمول قابل انجام نیست. همانطور که این فناوری در اوایل دهه 90 ظاهر شد ، بازار راه حل ها بسیار بزرگ است. و پیشنهادهای اصلی این محصولات از تولید کنندگان ابزارهای BI ارائه می شود.
این روزها تقریباً همه ارائه دهندگان از همه عملکردهای اصلی OLAP پشتیبانی می کنند و اجازه می دهند سیستم های مکعبی چند بعدی به عنوان بخشی از بستر BI خود ایجاد کنند. اکنون ، بیایید به برخی از محصولات محبوب که می توانند به عنوان یک ابزار جداگانه OLAP استفاده شوند نگاه کنیم.
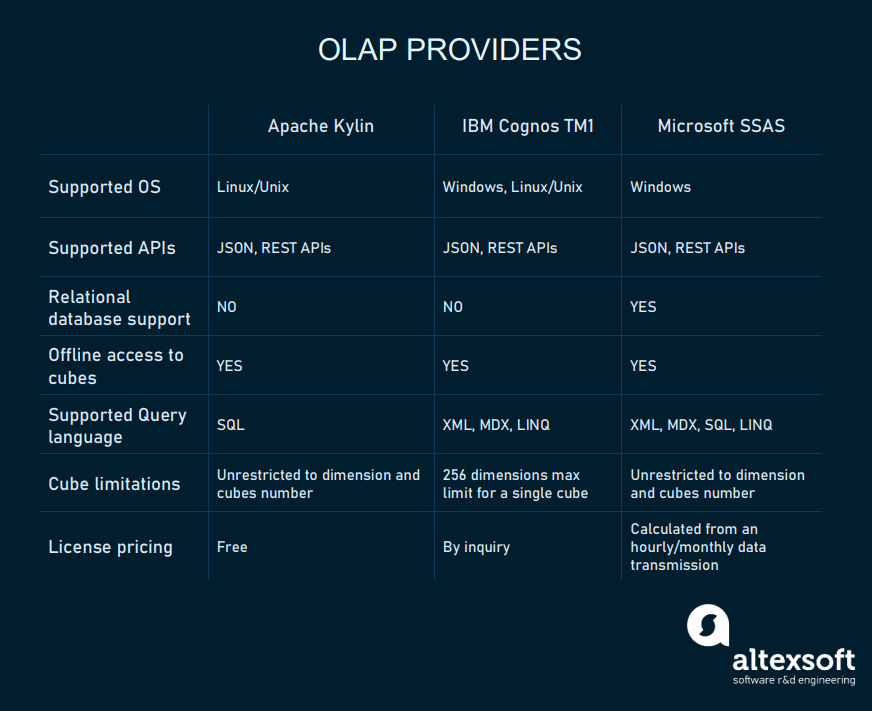
در ادا مه هر يک از موارد رو اجمالا معرفي کرده ولي محصول SSAS را با جزئيات بيشتري بررسي مي کنيم.
محصول Apache Kylin
Apache Kylin یک انبار داده توزیع شده منبع باز برای داده های بزرگ و OLAP است. Kylin برای تجزیه و تحلیل داخلی در Ebay توسعه یافته است. از سال 2014 ، منبع باز شده است و با مجوز رایگان توزیع می شود. در حالی که بر تجزیه و تحلیل داده های بزرگ تمرکز دارد ، Kylin همچنین می تواند برای انبارهای شرکت های با اندازه متوسط استفاده شود. به علاوه ، Kylin با رابط های BI معروف مانند Tableau ، Superset ، Qlik و Zeppelin ادغام می شود.
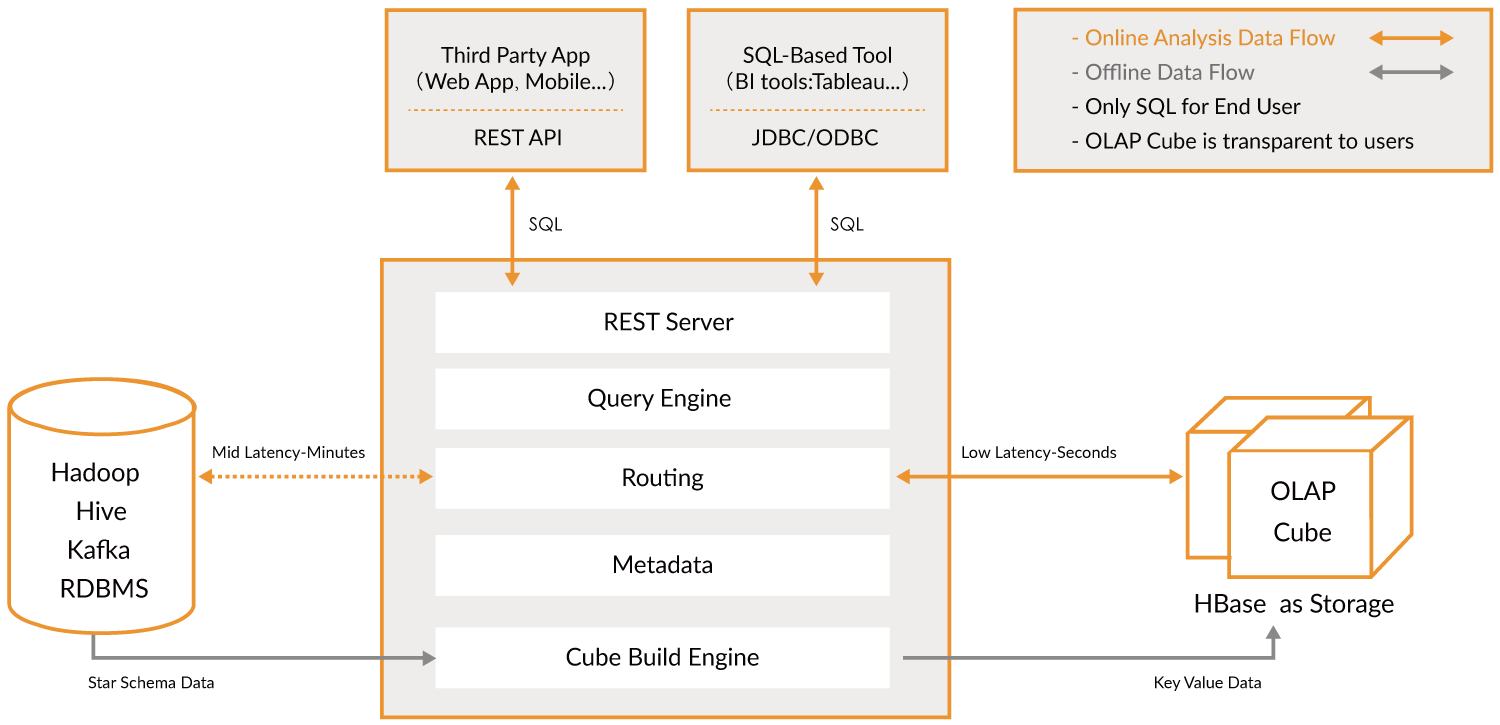
محصول IBM Cognos TM1
IBM Cognos TM1 بستر دیگری است که از ابزارهای متعددی برای تجزیه و تحلیل داده ها ، مدل سازی مکعب و تجسم داده ها تشکیل شده است. مانند مایکروسافت ، TM1 شامل طیف گسترده ای از محصولات Watson Analytics و یک سرور تحلیلی اختصاصی است. قیمت TM1 را می توانید از IBM در صفحه برنامه ریزی قیمت آنها دریافت کنید.
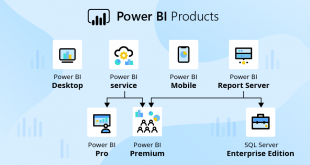
محصول Microsoft SQL Server Analysis Services (SSAS)
SQL Server شامل موتور(Engine) بسیار قدرتمندی برای ساخت ساختمان های داده چند بعدی(Multi-Dimensional) است که به شما اجازه مرتب کردن ،تجمیع (Aggregate)و تحلیل (Analyze)داده ها را می دهد و تحت عنوان SQL Server Analysis Services شناخته می شود.
SSAS یک سرور OLAP چند بعدی و همچنین یک موتور آنالیز است که به شما امکان می دهد حجم زیادی از داده ها را برش داده و تکه کنید. SSAS خدمات تحلیل را با استفاده از ابعاد مختلف ارائه می دهد. داده های جمع آوری شده از پايگاه داده MSSQL با استفاده از خدمات تجزیه و تحلیل SSAS به مکعب های منتقل می شود. در SSAS ابعاد از دو نوع هستند مانند Database Dimension و Cube Dimension.
شرکت مایکروسافت سالهاست به عنوان رهبر بازار در حوزه سرویس های OLAP (Online Analytical Processing) شناخته می شود. سرویس تجزیه و تحلیل اسکیول سرور یا ssas (sql server analysis service) یکی از سرویس های کاربردی مایکروسافت برای تحلیل دیتا و محاسبات تحلیلی است و چندین راهکار یا مدل برای ساخت مدل های هوش تجاری در اختیار شما قرار می دهد.
قبل از شروع یادگیری این سرویس باید انتخاب کنید که از مدل tabular (جدولی) استفاده کنید یا multidimensional (چندوجهی)! حتی برای افرادی که از این ابزار استفاده می کنند شاید تفاوت مدل tabular و multidimensional در حاله ای از ابهام باشد! و این سوال وجود داشته باشد که مدل های tabular و Multidimensional چه تفاوتی با هم دارند؟ از هر کدام در کجا و در چه شرايطي استفاده کنیم؟ مدل tabular و Multidimensional نسبت به هم چه مزایایی دارند؟
بسیاری از افراد فکر می کنند باید از مدل های multidimensional به مدل های tabular به دلیل جدید بودن و بهتر بودن مهاجرت کنند. اما در بسیاری از مواقع این موضوع پیشنهاد نمی شود یا حتی کار را بدتر می کند یا غیرممکن است. در اینجا راجع به چرایی این موضوع توضیح خواهیم داد. دقت داشته باشید برای ساخت مدل های چندوجهی و جدولی از Visual Studio استفاده میشود.
مدل multidimensional در ssas
دیتابیس multidimensional یا چندوجهی ساختار بسیار متفاوتی با دیتابیس های رابطه ای دارند و به ما اجازه می دهند که گزارش ها را بسیار سریع تولید کنیم. مدل چند وجهی در گذشته تنها راهکار برای ایجاد دیتابیس های چند وجهی بود. این مدل تغییر چندانی از sql server 2005 تا 2016 نداشته است.
اگر شما امکانات جدید سرویس تجزیه و تحلیل (analysis service) را بررسی کنید، خواهید دید که بیشتر آنها مربوط به ویژگی های جدید در مدل جدولی (tabular) است. راهکار چندوجهی یک ابزار سنتی OLAP cube است.
مدل tabular در ssas
مدل جدولی در sql server 2012 معرفی شد و در هر نسخه ویژگی های جدیدی به آن اضافه شد. مدل جدولی از موتور متفاوتی (xVelocity) استفاده می کند. این موتور برای کوئری ها با سرعت بالا در ستون ها طراحی شده است زیر در این مدل داده ها به صورت ستونی ذخیره میشوند (در حالی که در مدل چند وجهی داده ها به صورت سطری ذخیره میشوند).
در این مدل دیتا در رم (in memory) ذخیره می شود، به همین دلیل ضروری است که رم بالا و پردازنده بسیار سریع داشته باشید. در مدل جدولی فضای هارد بر خلاف مدل چند وجهی اهمیت کمتری دارد. این موضوع را در نظر داشته باشید که مدل جدولی به صورت وسیعی به عنوان راهکارهای سازمانی استاندارد توسط پلتفرم های مختلف پذیرفته شده است در صورتی که مدل چندوجهی اینگونه نیست.
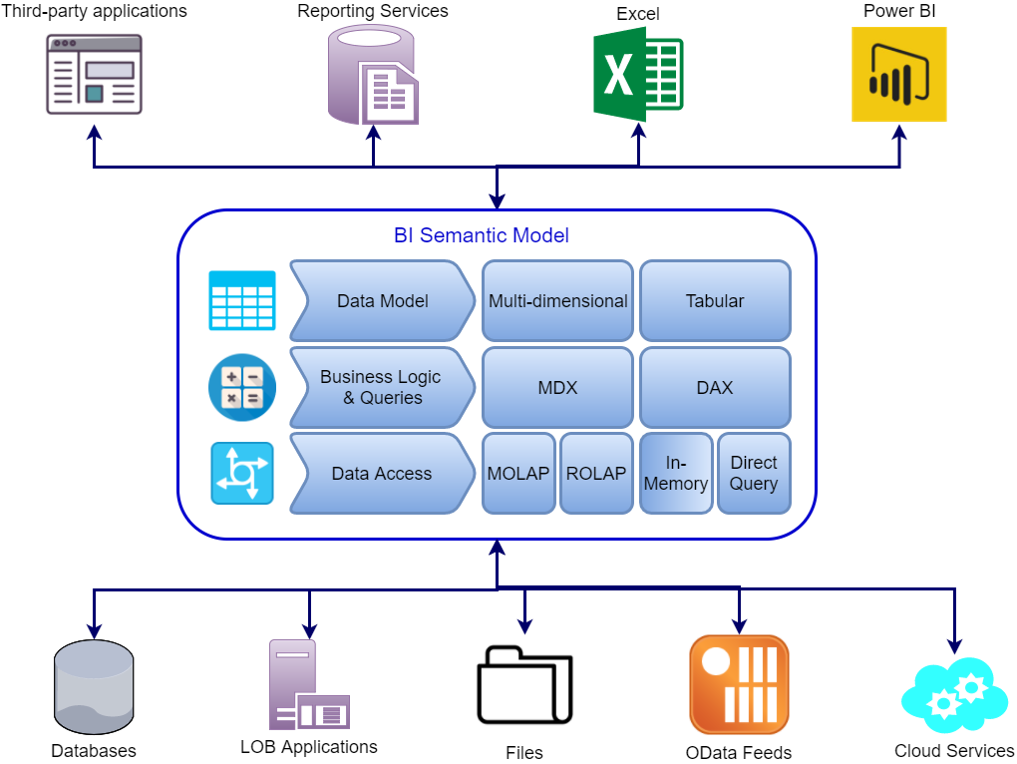
مقایسه دیتابیس جدولی (tabular) و چند وجهی (multidimensional)
در این قسمت به مقایسه این دو مدل دیتابیس خواهیم پرداخت و از وجوه مختلف آنها را مورد بررسی قرار خواهیم داد.
سخت افزار
باید به وضوح بدانید که سخت افزاری که در مدل دیتابیس چندوجهی مورد استفاده قرار می گیرد در بسیاری از مواقع برای مدل جدولی قابل استفاده نیست. مدل جدولی یک راهکار مبتنی بر رم است. هر چه رم شما بیشتر باشد عملکرد مدل جدولی بهتر خواهد بود. اگر رم کافی در اختیار ندارید مدل جدولی به سادگی شکست خواهد خورد.
در مدل جدولی سرعت هسته های پردازنده بسیار با اهمیت است. اگر دیتابیس شما حجم بسیار زیادی دارد (بیش از 5 ترابایت) مدل جدولی قابل پیاده سازی نیست و تنها راهکار شما مدل چندوجهی است.
مهم ترین مزیت مدل جدولی سرعت بالای آن در برخی از کوئری ها و کاهش حجم دیتا در مقایسه با مدل چندوجهی است. مدل چندوجهی حجم داده ها را یک سوم می کند در حالی که مدل جدولی حجم دیتا را تا یک دهم کاهش میدهد.) برای مثال مدل جدولی در شاخص های شمارش یکتا (distinct count) بسیار سریع عمل می کند.
اگر شما راجع به مدل جدولی شنیده باشید، نام Dax نیز برای شما آشناست. Dax یک زبان ساده برای کوئری های دیتابیس های چندوجهی، دیتابیس های جدولی، پاور پیوت و پاور بی آی است. این زبان فرمولی نویسی ساده تر از زبان قدیمی MDX است. در مدل های چند به چند (many to many)، در مدل جدولی dax بسیار سریع است.
همچنین در مدل های جدولی برخی از ویژگی های مدل های چندوجهی در دسترسی نیست مانند:
- تجمیع (aggregations)
- اقدامات (actions)
- اجتماع های شخصی سازی شده (Custom Assemblies)
- جمع آوری های شخصی سازی شده (Custom Rollups)
- رابطه های چند به چند (در نسخه های جدید tabular اضافه شده است.)
- پاسخگویی (Writeback)
اگر از مدل های چندوجهی استفاده کرده اید، به نکات بالا قبل از ایجاد مدل های جدولی دقت کنید.
خدمات تجزیه و تحلیل سرور SQL مایکروسافت (SSAS). مایکروسافت به عنوان بخشی از Azure Cloud Platform و PowerBI راه حل های تحلیلی ، محصولی جداگانه برای OLAP ارائه می دهد. در حال حاضر ، آنها آن را Azure Analysis Services می نامند. اساساً ، این یک ابزار مدل سازی و پردازش OLAP است که با PowerBI یکپارچه شده است. قیمت گذاری بر اساس منابع محاسباتی مانند تمام محصولات Azure محاسبه می شود. می توانید قیمت ها را در صفحه مربوطه بررسی کنید.
نقش پایگاه داده های ستون گرا در ایجاد مکعب داده
در حال حاضر ، OLAP همچنان یک فناوری دست و پاگیر است ، زیرا برای ساخت مکعب نیاز به مدل سازی پایگاه داده جداگانه دارد. و هرچه داده های بیشتری برای تجزیه و تحلیل نیاز داشته باشید ، به احتمال زیاد به یک انبار داده فقط برای نیازهای OLAP نیاز خواهید داشت. اما ممکن است با ظهور پایگاه داده های ستونی یا ستون گرا ، همه چیز تغییر کند.
همانطور که ممکن است به خاطر داشته باشید ، یک پایگاه داده سنتی رابطه ای مقادیر را در سطرها ذخیره می کند ، در حالی که ستون ها دسته بندی اقلام را نشان می دهند. پایگاه داده ستون نوعی طرحواره است که از ستون ها برای سازماندهی جداول در DB استفاده می کند. به همین سادگی ، این نوع طرحواره قابلیت هایی مشابه آنچه پایگاه داده OLAP انجام می دهد ، ارائه می دهد. هر جدول ابعادی را نشان می دهد که می تواند به سرعت اسکن و تجزیه و تحلیل شود.
پایگاه داده های ستونی به طور بالقوه می توانند به عنوان یک انبار داده استفاده شوند که قادر است به طور طبیعی پرس و جوهای OLAP را اداره کند. در حالی که این روش در سال 2012 در مطالعات مختلف توضیح داده شد ، چند سال پیش محبوبیت پیدا کرد. بنابراین این منجر به ظهور انبارهای داده ابری ستون محور شد.
منابع:
https://www.altexsoft.com/blog/olap-online-analytical-processing/
.https://skillpro.ir/astabular-vs-multidimensional-models-ss/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 4909
برچسبData Cube OLAP OLTP SSAS پایگاه داده های تحلیلی پردازش تحلیلی برخط دیتا کیوب مکعب داده
نوشته های مرتبط











همچنین ببینید
داده کاوی در بستر تکنولوژی Microsoft SQL Server
عناوين مطالب: 'مراحل داده کاوی در Microsoftداده کاوی در SQL Serverویژگی های کلیدی داده کاوی …
