 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
پردازش متن با Jhazm نسخه جاوا کتابخانه هضم برای پردازش زبان فارسی
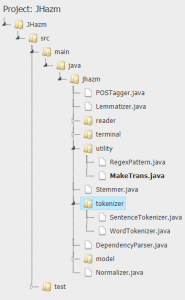
jHazm نسخه جاوایی هضم از کتابخانه پایتون برای پردازش زبان فارسی است. کتابخانه HAZM برای انجام پردازش های لازم بر روی زبان فارسی توسط دانشجویان دانشگاه علم و صنعت در سال 1392 به صورت متن باز و با استفاده از کتابخانه NLTK منتشر شد. لایسنس این ابزار MIT میباشد. هضم، ابتدا برای زبان پایتون و بر روی سیستم عامل لینوکس طراحی شد ولی بعدها توسط تیم توسعه دهنده برای زبان جاوا و C# نیز بازطراحی شد. با توجه به این که نسخه Jhazm با زبان برنامه نویسی جاوا توسعه داده شده است قابلیت استفاده از آن در پلتفرم ها وجود دارد. تمیز و مرتب کردن متن، جداسازی جملهها و واژهها، ریشهیابی، تحلیل صرفی جمله، تجزیه نحوی جمله و غیره از قابلیتهای هضم است. در زیر عناوین مهم قابلیت های کتابخانه جی هضم آورده شده است.
- تمیز کردن متن (Text cleaning) برای یادگیری normalizer به آموزش نرمال سازی متن با jhazm مراجعه کنید.
- قطعه بند کلمه و جمله (Sentence and word tokenizer)
- ریشه یاب کلمه (Word lemmatizer)
- ماژول بن یاب یا Stemmer
- ماژول StopWord Remover
- برچسب معنایی (POS tagger)
- ماژول کار با عبارات با قاعده RegexPattern
- تجزیه کننده وابستگی (Dependency parser)
- تحلیل صرفی جمله
- تجزیه نحوی جمله
- واسط استفاده از دادههای زبان فارسی
- سازگاری با بسته NLTK
- …
در آینده نزدیک تمام امکانات بالا را به مرور آموزش خواهیم داد.
برای پیکره دادگان از منابع زیر استفاده میشود:
- Hamshahri
- Bijankhan
- Persica
- Verb Valency
نیازمندی ها
- You can download pre-trained tagger and parser models for persian and put these models in the JHazm/resources folder of your project.
برای یادگیری بیشتر ویدئوی زیر را که البته با زبان پایتون است را مشاهده کنید.
منابع:
https://github.com/mojtaba-khallash/JHazm/blob/master/README.md
http://www.sobhe.ir/hazm
آدرس کانال تلگرام ما:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
بازدیدها: 3453
برچسبdependency Parser hpn shc jhazm lemmatizer NLTK Regex Pattern rxui fkn Tokenizer پردازش زبان پردازش متن پردازش متن با Jhazm پردازش متن با کتابخانه Jhazm پردازش متن فارسی تحلیل متن جاوا جی هضم فارسی کتابخانه JHazm متن کاوی متن کاوی با زبان جاوا هضم
نوشته های مرتبط











همچنین ببینید
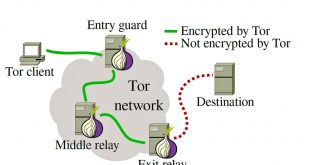
مجموعه داده اسامی مکان برای تشخیص موجودیت های مکانی در پردازش زبان طبیعی
عناوين مطالب: 'مقدمه ای بر اسامی مکان:کاربردهای (Named-entity recognition) NERروشهای تشخیص اسم مکاندانلود دیتاست اسامی …
آموزش فارسی اسپرینگ بوت (Spring Boot) به صورت کاربردی
در این مبحث قصد دارم به صورت خلاصه به آموزش کاربردی اسپرینگ بوت بپردازم. برای …
یک دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام و خسته نباشید
برای پردازش متن عربی لطفا کتابخانه هارا معرفی کنید .
به امید خدا