 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
محصولات و تکنولوژی های آپاچی (Apache) در حوزه کلان داده و داده کاوی
یکی از موسسات مطرح در زمینه پشتیبانی از داده های حجیم، بنیاد آپاچی می باشد. لذا شناخت محصولات و تکنولوژی های نرم افزاری آپاچی بسیار لازم است. معمولا از مجموعه ی این تکنولوژی ها تحت عنوان اکوسیستم هدوپ یاد میشود. در این مبحث تکنولوژی های آپاچی بررسی خواهد.
این نرم افزار محبوب و قدرتمند یک نرم افزار کدباز پیام رسانی (یا کارگزار) پیام و سرویس دهنده تجمیع کننده الگوها می باشد. این نرم افزار بسیار سریع بوده و بسیاری از زبانهای مبتنی بر ایستگاه کاری و پروتکل های مختلف را پشتیبانی می نماید. این نرم افزار به صورت بسیار کاربر پسند و حرفه ای، الگوهای تجاری را تجمیع می نماید . ActiveMQ قابلیت های پیشرفته ای در خود گنجانده است. همچنین نسخه جدید این نرم افزار از استاندراد JMS 1.1 و J2EE 1.4 پشتیبانی می نماید . این نرم افزار تحت مجوز Apache 2.0 License انتشار می نماید .
قابلیت های کلیدی نرم افزار :
- پشتیبانی از پروتکل ها و زبان های مبتنی بر ایستگاه کاری همانند Java, C, C++, C#, Ruby, Perl, Python, PHP
- استفاده از تکنولوژی OpenWire برای بالابردن کارایی ایستگاه های کاری در زبان های java ،C++, C#
- با استفاده از قابلیت stomp ، ایستگاه های کاری را می توان براحتی با زبان های C, Ruby, Perl, Python, PHP, ActionScript/ توسعه داد و با ابزار smaltalk ، activemq به دیگر واسط های پیام محبوب متصل شد.
- پشتیبانی کامل از تجمیع کننده های الگوهای تجاری . این تجمیع کننده ها در ایستگاه های کاری jms و و در پیام رسان های واسط قابل استفاده هستند.
- پشتیبانی از قابلیت های افزوده همانند پیام های گروهی ،مقاصد مجازی ،wildcard ها و مقاصد کامپوزیت
- پشتیبانی کامل از JMS 1.1 و J2EE 1.4 برای پیام های گذرا ،ماندگار ، معاملاتی و XA ها
- با استفاده از spring می توان به راحتی در نرم افزارهای توسعه داده شده توسط spring ، تنظیمات را به وسیله مکانیزم spring xml در نرم افزار جاسازی نمود.
- در کنار سرویس دهنده های J2EE همانند TomEE, Geronimo, JBoss, GlassFish و weblogic کاملا تست شده است
- همچنین از JCA 1.5 resource adaptors برای پیام های ورودی و خروجی که توسط ActiveMQ به صورت خودکار در سرویس دهنده های سازگار با J2EE استقرار یافته ، استفاده نمود
- پشتیبانی از پروتکل های جایگزین حمل و نقل همانند in-VM, TCP, SSL, NIO, UDP, multicast, JGroups and JXTA transports
- پشتیبانی سریع و مقیم شده از JDBC برای کارایی بالای ژورنال فایل
- طراحی شده برای کارایی بالاتر برای سرویس های مبتنی بر ارتباطات خوشه ای ، سرویس دهنده – ایستگاه کاری
- استفاده از توابع REST برای فراهم نمودن تکنولوژی agnostic و توابع بومی تحت وب برای پیام رسانی
- استفاده از AJAX برای پشتیبانی web streaming مروگرهای وب با استفاده از تکنولوژی DHTML که به مرورگرها اجازه می دهد که بخش باز یک سیستم یکپارچه پیام رسانی باشند .
- پشتیبانی از CXF و AJAX برای ساده نمودن انجام کارهایی ازقبیل کاهش دادن هر کدام از پشته های سرویس های وب با ایجاد شرایط reliable messaging
- می تواند برای حالت ایده آل تست واحدهای JMS همانند یک حافظه jms عمل نماید.
CouchDB
در سال 2013 این پروژه از ادغام کدهای Big Couch و Cloudant که نسخهای از Couch DB برای کلاسترینگ میباشد، به وجود آمد .
|پیادهسازی ACID
این سمپاد قابلیت پیادهسازی ACID را به وسیله ساده سازی به فرمهای [4]MVCC را دارد . این بدان معنا است که این سمپاد از تعداد زیادی عمل خواندن و نوشتن همزمان ،بدون مغایرت پشتیبانی مینماید.
این سمپاد برای پرسوجو و اندیس کردن از مکانیزم MapReduce و جاوا اسکریپت استفاده مینماید.
این سمپاد برای صفحات وب طراحی گردیده است . داده را به صورت اسناد در قالب Field/Value و در فرمت json ذخیره مینماید و میتوان از طریق مرورگر و پروتکل HTTP به اسناد دسترسی پیدا نمود.
پرس و جو، ادغام و ارسال اسناد به وسیله جاوا اسکریپت میتوان سرعت عملکرد در صفحات وب را بالا ببرد.
این سمپاد با تمامی نسخههای وب و نرم افزارهای موبایل همخوانی دارد. این سمپاد قابلیت Replication به صورت Master-Master را دارد ، همچنین تنظیمات Replication به همراه کشف مغایرت در Replication از قابلیتهای این سمپاد میباشد .
Accumolo
این پروژه در سال 2008 توسط سازمان امنیت ملی ایالات متحده (NSA) با هدف ایجاد یک سمپاد غیر رابطه ای با قابلیتهای امنیتی بالا و با قابلیت ذخیره سازی فوقالعاده بالا ایجاد گردید و در سال 2011 بک پروژه به بنیاد آپاچی برای توسعه به حالت کدباز و در قالب مجوز آپاچی اهدا گردید .و در حدود یک سال بعد یک نسخه تجاری از این محصول با نام Sqrrl به بازار ارائه شد . از قابلیتهای کلیدی این نرم افزار در حوزه امنیتی میتوان به موارد زیر اشاره کرد .
این تکنولوژی امنیتی بر پایه Hadoop ایجاد گردیده که قابلیت آنالیز امنیتی را ارائه مینماید . همچنین قابلیت ذخیره سازی تا حجم پتابایت را بر روی چندین ساختار داده ای گوناگون با مشخصات سخت افزاری پایین را دارا میباشد و تحلیلگران سایبری را قادر میسازد تا از طریق مجموعه دادههایی که قبلاً ذخیره شدهاند به تجزیه و تحلیل و اعمال عملیات امن سازی در دادهها بپردازند.
آنالیز امنیتی داده های حجیم :
Sqrrl نسخه تجاریAccumolo میتواند به عنوان یک مخزن مرکزی به صورت یک log proxy، NetFlow دادهها ،ایمیلها ، داده های Dns ای ، فعالیتهای سایتهای اجتماعی ، شناسایی محتوای اطلاعات و امن سازی سایبری مجموعه دادهها استفاده میگردد . این دادهها به طور مداوم ایندکس شده و برای جستجوها و تجزیه و تحلیلهای تعاملی در دسترس قرار میگیرد ,
Apache Ant
یک نرم افزار برای اتوماسیون سازی فرآیندهای ساخت مبتنی بر جاوا است است . این نرم افزار برای کدهای نوشته شده توسط زبان جاوا طراحی گریده است . این نرم افزار بستر مناسب را برای اجرای نرم افزاری جاوا فراهم می آورد. به این ابزار ها Buildtools می گویند .
Maven
بسیاری از برنامه نویسان Maven را یک ابزار Build میدانند. ابزاری که برای ساختن محصولات ( Artifacts ) از Code Source مورد استفاده قرار میگیرد. نگاه مدیران پروژه و مهندسان نرم افزار به Maven گسترده تر است : یک ابزار مدیریت پروژه. تفاوت این دو دیدگاه چیست ؟ یک ابزار Build مانند Ant فقط بر روی پیش پردازش (Preprocessing) ، کامپایل ، بسته بندی (Packaging ) ، آزمایش و توزیع متمرکز میباشد.یک ابزار مدیریت پروژه مانند Maven یک سری ویژگی های مافوق ابزار Build را در اختیار شما قرار میدهد. Maven علاوه بر این که قابلیت های Build را داراست ، همچنین در تهیه گزارشات ، تولید Web Site و تسهیل ارتباط بین اعضای تیم توسعه نرم افزار استفاده میشود. به عبارت ديگر ، هر چقدر كه پروژه هاي متن باز به Maven به عنوان يك سكوي مديريت منتقل ميشوند ، توسعه دهندگان نيز به اين نتيجه رسيده اند كه Maven فقط ابزار ساده سازي مديريت Build نيست ، بلكه يك رابط مشترك بين توسعه دهنگان و پروژه هاي نرم افزاري مي باشد
هدوپ یک نرم افزار متن باز تحت لیسانس آپاچی است که با جاوا برنامه نویسی شده و برای تقسیم بندی و توزیع فایل های متمرکز به کار می رود. هدف از پروژه Hadoop توسعه نرم افزاری متن باز برای انجام محاسبات مطمئن، مقیاس پذیر و توزیع شده می باشد. نرم افزار Hadoop یک چارچوب است که امکان پردازش توزیع شده مجموعه ای از داده های حجیم را فراهم می آورد و این عملیات توسط یک مدل برنامه نویسی ساده بر روی سیستم clustering انجام میگیرد.طراحی آن به شکلی است که میتواند بر روی یک یا هزاران سرور محاسبات یا عملیات ذخیره سازی اطلاعات را به شکلی محلی انجام دهد. به جای تکیه بر سخت افزار، کتابخانه این نرم افزار هرگونه شکست را در لایه Application تشخیص و برطرف میکند، بنابراین سرویس موردنظر با قابلیت اطمینان بسیار بالایی بر روی سیستم clustering تعدادی سخت افزار ارائه میگردد که هرکدام میتواند منجر به شکست شود.ایده اولیه هدوپ اولین بار در شرکت گوگل رقم خورد اما خیلی ها باور به پیاده سازی این سیستم نداشتند و در چند سال اول این ایده تنها بصورت تئوری مطرح بود این شرکت در پی افزایش حجم تبادل اطلاعات، به دنبال راه حلی برای افزایش سرعت و راندمان سرورهای خود بود که سیستم توزیع منحصر به فردی برای خود ابداع کرد به نامGFS Google File System و در پی این موفقیت، انجمن توزیعApache به فکر گسترش این تکنولوژی در سطح وسیعتری افتاد و سیستم هدوپ به وجود آمد. کلودرا شرکتی است که بصورت فعال در این زمینه فعال می باشد و بسته نرم افزاری بی نظیر هدوپ را ایجاد کرده و آن را انتشار داده و پشتیبانی می کند.
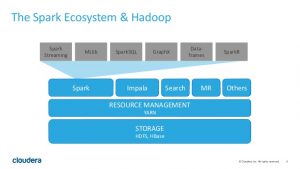
ساختار کلی اطلاعاتی در هدوپ بدینگونه می باشد که اطلاعات توسط سیستم هدوپ شکسته شده و به چندین سرور فرستاده می شود. سرورها بسته به نوع اطلاعات که ممکن است پردازشی یا ذخیره ای باشد اطلاعات را پردازش یا ذخیره سازی می کنند. در هنگام در خواست اطلاعات مجدد سیستم اطلاعات را از سرور های مختلف گرفته ، مونتاژ کرده و در خروجی نمایش می دهد.
خوبی این سیستم تهیه نسخه پشتیبان از اطلاعات بصورت خودکار است. هر تکه از اطلاعات در چندین قسمت سرور ذخیره می شود و در صورت آسیب دیدن یکی از سرورها ، سرور دیگر قادر است مسئولیت را بر عهده گرفته و اطلاعات مورد نظر را جایگزین کند.
Apache Hadoop از چه قسمت هایی تشکیل شده است؟
Hadoopازچهار بخش زیر تشکیل گردیده است:
- Hadoop Common:امکاناتی برای پشتیبانی از ماژول های دیگر Hadoop
- Hadoop Distributed File System : سیستم توزیع شده فایل ها که دسترسی به داده های نرم افزار را با توان بالا فراهم میسازد.
- Hadoop YARN : چهارچوبی برای مدیریت Clustering
- HadoopMapReduce :سیستمی برای پردازش موازی از مجموعه داده های بزرگ
Hadoop چگونه عمل می کند؟
سیستم بدین صورت عمل میکند که اطلاعات دریافت شده به صورت بلوک های ۶۴ مگابایتی در آمده و هر تکه در یک سرور جداگانه ذخیره می شود. در تصویر زیر سرورNamenodeدر واقع همان سرور اصلی (Master) می باشد که وظیفه ی کنترل سرورهای دیگر (Slave) را به عهده دارد. بخشMap Reduce نیز بر روی سرور اصلی اجرا می شود و بخشHDFS یا همانHadoop Distributed File System بر روی سرورهای جانبی اجرا می شود. سرورهای جانبی وظیفه ی ذخیره سازی اطلاعات را بر روی هارد دیسک های خود به عهده دارند. یعنی زمانی که کاربر درخواست فراخوانی یک فایل را صادر می کند، سرور اصلی از طریق آدرس هایی که در اختیار دارد، بلوک های مورد نظر را از سرورهای مختلف فراخوانی کرده و پس از سر هم کردن و تکمیل کردن فایل، آن را به کاربر تحویل می دهد.
نکته ی جالب پروسه مربوط بهData Replication می شود. الگوریتم این برنامه طوری نوشته شده است که چندین نسخه کپی از بلاک ها بر روی دیگر سرور ها قرار می گیرد و این امر دو مزیت بزرگ دارد: اول این که شبکه در مقابل خطاهای سخت افزاری از قبیل سوختن هارد دیسک، اشکالات سخت افزاری سرورها و … در امان میباشد و در صورتی که هر یک از سرورها به دلایلی از شبکه خارج شوند، اطلاعات مورد نظر از روی سرورهای دیگر فراخوانی می شوند. مزیت دوم این قابلیت این است که دیگر نیازی به استفاده از تکنولوژیRAID نمیباشد و می توان از حداکثر فضای هارد دیسک های خود استفاده نمود.
مزایای استفادهHadoop :
- دسترسپذیراست: هدوپ روی کلاسترهای بزرگ تشکیل شده از سرورهای معمولی (در دسترس) یا روی سرویسهای رایانش ابری همچون سرویسEC2 آمازون اجرا میشود.
- مقاوم است:Hadoopبر روی سختافزارهایی معمولی اجرا میشود و به راحتی از عهده خرابی گرهها بر میآید. زیرا فرض میکند که عناصر رایانشی و ذخیرهسازی از کار خواهند افتاد، بنابرایم چندین کپی از دادهای که روی آن دارد کار میکند را نگه میدارد تا اطمینان حاصل کند که پردازش میتواند باز توزیع شود.
- مقیاسپذیر است:Hadoopهمچنان که حجم دادهها افزایش مییابد با افزودن گرههای جدید به کلاستر به صورت خطی گسترش مییابد و با این کار اجازه عملیات روی هزاران گیگابایت از دادهها را میدهد.
- ساده است:Hadoopبه کاربران این اجازه را میدهد که به سرعت کًدهای موازی کارا بنویسند.
- مقرون به صرفه است :Hadoopمحاسبات موازی انبوه را در سرورها امکان پذیر میسازد. در نتیجه کاهش قابل ملاحظه ای در هزینه هر ترابایت ذخیره سازی را با خود به همراه دارد و به نوبه خود باعث می شود آن را مقرون به صرفه نماید.
- انعطاف پذیر است:Hadoopبر خلاف ظاهر ساده خود هر نوع و فرمتی از اطلاعات را میتواند از منابع مختلف به خود جذب کند.داده ها از منابع مختلف میتوانند در کنار یکدیگر قرار گرفته و در نتیجه تجزیه و تحلیل بهتری بر روی آن ها انجام خواهد پذیرفت
- دارای تحمل پذیری بالای خطاها:هنگامی که یک نود در مدار از دست برود سیستم تغییرمسیرداده وادامه کار را با مسیر دوم دیتا ادامه خواهد داد و پردازش بدون از دست دادن زمان ادامه می یابد.
AVRO
یک سیستم ارتباطی از راه دور و چهارچوب توسعه ترتیبی از سری نرم افزارهای Hadoop می باشد .
این نرم افزار از JSON برای تعریف نوع های مختلف داده ای و پروتکل ها استفاده کرده و داده را به صورت ترتیبی و فشرده به صورت باینری ذخیره می نماید . در تعریفی دیگر . AVRO یک سیستم داده ای ترتیبی می باشد . در اصل این نرم افزار در Apache Hadoop به کار گرفته می شود . همچنین این نرم افزار هم فرمت سریال و هم داده های ماندگار را ارائه نموده و یک قالب سیم برای ارتباط بین گره های هدوپ ، از سمت برنامه های مشتریان به سرویس های هدوپ برقرار می نماید .
این نرم افزار همانند Apache Thrift می باشد با این تفاوت که نیازی به اجرای یک نرم افزار تولید کد زمانی که اسکیمای تغییر کرده ندارد (در موارد خاص برای زبان های نوع-ایستا لازم است )
Zookeper
یک پروژه نرم افزاری متن باز می باشد که سرویس حفظ تنظیمات توزیع شده ،سرویس هماهنگ سازی در سیستم های توزیع شده و نام گذاری رجیستری برای سیستم های بزرگ توزیع شده است . Zeooker یک زیر پروژه از Hadoop بود ولی در حال حاضر تبدیل به پروژه منفرد سطح بالا شده است .
تمامی این سرویس ها به فرم ها ی گوناگون و یا در نرم افزارهای توزیع شده استفاده می شوند . هر زمانی این نرم افزارها پیاده سازی می شوند کارهای زیادی برای برطرف نمودن مشکلات صورت می پذیرد و شرایط مسابقه [5] اجتناب ناپذیر است . علت آن سختی پیاده سازی این سرویس ها ، نرم افزار ها، و اینکه در ایندا انجام تغییرات بر روی آنها دشوار می باشد و آنها در مقابل تغییر شکننده هستند . این امر به مدیریت کم در سیستم های توزیع شده برمی گردد . همچنین پیاده سازی های مختلف از این خدمات به پیچیدگی مدیریت منجر خواهد شد . Zookeper برای فائق آمدن به این مشکلات و مدیریت سیستم های توزیع شده طراحی گردیده است .
Lucene
این روژه در سال 1999 نوشته شدو در سایت source forge به صورت متن باز ارائه شد و بعدها به بنیاد آپاچی ملحق شد . این نرم افزار یک کتابخانه نرم افزاری بازیابی اطلاعات می باشد . این نرم افزار توسط java نوشته شده است . این نرم افزار به زبان های برنامه نویسی دیگر از جمله دلفی، پرل، C #، C + +، پایتون، روبی و PHP پورت شده است. این نرم افزار برای هر نرم افزاری که نیاز به شاخص گذاری[6] و جستجوی متن به صورت کامل داشته باشد بسیار مفید خواهد بود . Lucene به صورت گسترده ای مورد قبول واقع شده و در موتور جستجوهای اینترنتی و محلی و جستجوی تک سایت مورد استفاده قرار می گیرد. .
در معماری منطقی هسته Lucene ایده ای نهفته است . این ایده متذکر می شود که یک سند حاوی فیلدهایی از متن هستند . این انعطاف پذیری به API های این نرم افزار اجازه می دهد که مستقل از فرمت فایل باشند . متن از هر فرمت WORD،HTML،Open Document و … می تواند استخراج شده و شاخص گذاری شود . این عمل بر روی تصاویر غیر قابل ممکن است .
Lucene شامل توابع و کتابخانه هایی برای خزش[7] و پارس نمودن[8] فایل های Html نمی باشد ولی پروژه های دیگری این قابلیت ها را به ارائه نموده اند.
Apache Nutch
Apache Solr
Elastic Search
Compas
و …..
Apache Nutch
خزشگر متن باز بسیار توسعه پذیر و مقیاس پذیر از بنیاد آپاچی می باشد . این پروژه از پروژه Lucene آپاچی نشعت گرفته است..
Nutchنسخه 1 عملیات خزش را بخ خوبی انجام می دهد و شما را قادر می سازد که با استفاده از Hadoop از پردازش دسته ای اطلاعات بهره ببرید .
Nutch نسخه 2 : یک مدل انتزاعی از نسخه یک است اما در یک نقطه متفاوت است و آنهم اینست که ذخیره سازی از هر زمینه خاص انبارداده ها [9] با استفاده از Apache Gora امکان پذیر شده است این امر برای نگهداری اشیایی که به صورت مداوم نگاشت شده است مفید خواهد بود . این بدان معنی است که ما قادر به پیاده سازی مدل/پشته برای ذخیره سزی هرچیزی در یکی از راه کارهای پایگاه دادههای غیر رابطه ای هستیم . ( خزش زمان،وضعیت،محتوا،پارس نوشته ها ،لینک های خارجی ، لینک های داخلی و …)
البته جایگرین و ماژول هایی برای نیازهای ما ارائه شده است. Nutch دارای یک رابط توسعه پذیر همانند پارس، شاخص گذار،فیلترهای مختلف برای پیاده سازی می باشد.
Elastic Search
یک سرویس دهنده جستجو بر پایه lucene می باشد . این نرم افزار یک موتور جستجوی متن کاملا توزیع شده و Multitent می باشد و یک رابط وب آرام را با اسکیمای آزاد JSON ارائه می دهد. Elastic Search توسط Java توسعه داده شده و این نسخه متن باز تحت مجوز آپاچی ارائه می شود.
این متوتور جستجو تواناییی جستجوی تمامی فرمتهای اسناد را دارد. این موتورجستجو یک جستجوی توزیع پذیر نزیدک به جستجوی برخط را ارئه می دهد و از Multitenancy حمایت می نماید. این موتور جستوج توزیع پذیر می باشد به این معنا که قابلیت تقسیم شدن عملیات به کارهای کوچکتر و افزونگی داده در گره ها میسر است.
این موتور جستجو از قابلیت های lucene و قابلیت های JSON و java API حمایت می نماید .
این برنامه از faceting و percolating حمایت می نماید. همچنین از قابلیت اطلاع رسانی در صورت هماهنگ بودن سند جدید با پرس و جوهای ثبت شده بهره می برد.
امکان دیگری که به نام Gateway (دروازه) شناخته می شود از شاخص های ماندگار طولانی مدت نگهداری می کند برای مثال یک شاخص می تواند از طریق دروازه در یک اتفاقی هماهننگ crack کردن سرویس دهنده ، بازیابی گردد. این نرم افزار از درخواست های برخط GET در صورتی که از راه کار پایگاه داده های غیر رابطه ای استفاده شده باشد ، پشتیبانی می نماید اما آن فاقد تراکنش های توزیع شده می شود .
OpenNLP
این کتابخانه یک ابزار برای یادگیری ماشین در پردازش نوشته های زبان های طبیعی می باشد.
همچنین آن از وظایف حساس و مهم در NLP همانند tokenization، تقسیم بندی جمله، تگ کردن بخشی از سخنرانی که استخراج مولفه ها نامیده می شود، تجزیه و … می باشد.
این وظایف عموما نیازمند ساخت سرویسهای پردازش متن پیشرفته تر است. OpenNLP همچنین در دارای حداکثر entropy و perceptron مبتنی بر بادگیری ماشین است .
Solr
Solr که در تلفظ Solar گفته می شود یک پلت فرم جستجوی کد باز تجاری می باشد که از Lucene گرفته می شود.این ماژول دارای قابلیت هایی همانند جستجوی کامل نوشته ،آمار برجسته،جستجوی وجهی ، خوشه بندی پویا،یکپارچه سازی پایگاه داده ها و نگهداری اسناد غنی (WORD، PDFو …) ، ازائه جستجوی توزیع شده شاخص گذاری افزونگی می باشد . Solr بسیار مقیاس پذیر می باشد و محبوب ترین موتور جستجوی تجاری محسوب می گردد.
Solr 4 قابلیت NOSQL را نیز به خود افزوده است. Solr در جاوا نوشته شده و به عنوان یک سرویس دهنده جستجوی کامل نوشته تنها با یک نگهدارنده servlet همانند Apache Tomcat یا Jetty می باشد . Solr از کتابخانه های جستجوی جاوای Lucene در هسته خود برای شاخص گذاری کامل نوشته ها و جستجو بهره می برد. همچنین از توایع HTTP/XML و JSON برای ساخت محبوب ترین زبان های برنامه نویسی استفاده می شود.
یک چهارچوب محاسباتی و تجزیه و تحلیل کننده خوشه[10] داده متن باز می باشد. این چهارچوب ابتدا در آزمایشگاه AMPLab در دانشگاه برکلی خلق گردید . این چهاچوب راه خود را به صسوعت در بین اجتماع توسعه دهندگان هدوپ باز نمود . این چهارچوب از فایل سیستم HDFS برهره می برد و برای پردازش از چندین سطح بیشتر نسبت به Hadoop بهره می برد . نتیجه کارایی محاسباتی این مکانیزم ، سرعت 100 برابر بیشتر از Hadoop در تجزیه و تحلیل داده و پردازش آن می باشد.
Mahout
پیاده سازی از الگوریم توزیع شده و یا توسعه پذیر یادگیری ماشین می باشد که بر روی قسمتهای مهم همانند پالایش گروهی ،خوشه بندی و طبقه بندی تمرکز نموده است.
بسیاری از پیاده سازی ها از ساختار Hadoop استفاده می نمایند . Mahou همچنین از کتابخانه های جاوا برای عملگرهای مهم ریاضی (تمرکز بر روی آمار و جبر خطی ) و مجموعه جاوای بدوی بهره می برد.
تایتان یک پایگاه داده توزیع شده و مقیاس پذیر مبتنی بر گراف است. تیتان بسیار برای مرتب کردن داده های گراف و انجام پرسوجو بر روی گراف بهینه عمل میکند. این بانک اطلاعاتی توان پردازش میلیارد ها راس و یال به صورت توزیع شده در میان خوشه های چند ماشینه را دراد. تایتان یک بانک اطلاعاتی transactional با توان پشتیبانی هزاران کاربر همزمان برای پرسوجوی های از نوع complex graph traversals به صورت real time است.
تیتان ویژگی ها و قابلیت های زیر را مهیا میکند:
- Elastic and linear scalability for a growing data and user base.
- Data distribution and replication for performance and fault tolerance.
- Multi-datacenter high availability and hot backups.
- Support for ACID and eventual consistency.
- Support for various storage backends:
- Apache Cassandra
- Apache HBase
- Oracle BerkeleyDB
- Support for global graph data analytics, reporting, and ETL through integration with big data platforms:
- Support for geo, numeric range, and full-text search via:
- Native integration with the TinkerPop graph stack:
- Open source with the liberal Apache 2 license.
Riak
Riak هم یکی دیگر از پایگاه های داده ای NoSQL است که خالق آن شرکت Basho Technologies است، در سال 2009 تحت لیسانس آپاچی 2 توسعه داده شد. Riak تمامی اصول کار خود را از Amazon Dynamo تبعیت میکند. Dynamo یک سیستم ذخیره سازی توزیع شده ای است که متعلق به شرکت آمازون است. Riak علاوه بر اینکه از مکانیزم MapReduce استفاده میکند همچنین از جستجوی کامل با استفاده از الگوریتم Robust هم بهره می برد. در توضیحاتی که در وب سایت رسمی این پایگاه داده آمده است گفته شده که ارتباط شما میتواند با تمامی گره های شبکه ای که در حال تبادل داده های اطلاعاتی هستند قطع شود ولی هیچ وقت داده ها در این میان از بین نمی روند. فرق قابل توجه ای که این پایگاه داده با سایر پایگاه های داده ای خانواده NoSQL دارد در انتخاب گره اصلی یا Master است. به این صورت که اگر گره اصلی یا Master قطع شود، نزدیک ترین گره همسایه وظیفه سرویس دهی را بر عهده می گیرد که این موضوع بر خلاف روش های دیگری از جمله گره اصلی/فرعی که به طور مثال در پایگاه داده MongoDB شاهد آن هستیم می باشد.
این پایگاه داده همچنین برای زبان های برنامه نویسی Java, Python, Perl, Erlang, Ruby, PHP, .NET دارای کتابخانه ای مجزا می باشد. سایت رسمی این پایگاه داده basho.com می باشد.
cassandra يک سمپاد[1] غير رابطهاي [2]مبتنی بر کلید- مقدار [3]است. در اين نوع پايگاه داده دو اصطلاح keySpace و columnFamily وجود دارد که ميتوان آنها را به ترتيب معادل پايگاه داده و جدول، در سمپادهای رابطهاي دانست.
این سمپاد از زبانی به نام CQL برای پرس و جو بر روی پایگاه داده استفاده می نماید . کاساندرا بهترین گزینه برای مهاجرت از سمپادهای رابطه ای به غیر رابطه ای می باشد . برنامه نویسان قادر خواهند بود بیش از 90% پرس و جو هایی را که در SQL انجام می دادند در CQL انجام دهند . این رویکرد باعث شده است که برنامه نویسان قادر باشند داده های خود را از نوع SQL به CASSANDRA و FAT FILE تبدیل نموده و از امکانات سمپادهای غیر رابطه ای استفاده نمایند .
با توجه به ساختار شاخه ای و درخت وار سمپادهای غیر رابطه ای می توان از آنها براحتی برای پایگاه داده های توزیع شده در سطح کلان و با هزینه های پایین تر از سمپادهای رابطه ای بهره برد .
اين سمپاد ميتواند از چندين keySpace تشکيل شود و هر keySpace نيز به نوبهي خود ميتواند از چندين columnFamily تشکيل شود. هر columnFamily داراي يک ستون کليد مختص هر سطر ميباشد. هر سطر نيز از چندين دوتايي (کليد، مقدار) تشکيل ميشود. تعداد اين دوتاييها از سطري به سطر ديگر متغير است به عبارت ديگر ممکن است سطري شامل يک دوتايي و سطر ديگر شامل ميليونها دوتايي باشد.
چينش گرهها در کاساندرای توزيع شده، به صورت نظير به نظير است. ترتيب نظيرها در آن با توجه به ويژگي توکن در فايل cassandra.yaml مشخص ميشود. تکثير در اين سمپاد در هنگام ايجاد columnFamily تعيين ميشود به عبارت ديگر ميتوان تعداد تکثيرها از يک columnFamily را هنگام ايجاد آن تعيين نمود. رويکردهاي مختلفي براي انتخاب گرهها در هنگام تکثير دادهها وجود دارد که اين رويکردها نيز در هنگام ايجاد columnFamily تعيين ميشوند. رويکرد پيشفرض، انتخاب تصادفي گرههاست.
[1] Database Management System
[2] NoSQL
[3] Key-Value
[4] Multi-Version Concurrency Control
[5] Race Condition
[6] indexing
[7] Crawl
[8] parsing
[9] Data store
[10] Cluster
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 31710
برچسبAccumolo ActiveMQ apache Apache Ant AVRO Cassandra CouchDB Elastic Search Hadoop Index Lucene Mahout Nutch OpenNLP OrientDB Search Solr Spark Titan Zookeper آپاچی آورو اسپارک الستیک سرچ ایندکس پایگاه داده غیر رابطه ای تایتان داده کاوی زوکیپر سرچ سولر غیر رابطه ای کاساندرا کسندرا کلان داده لوسین موتور جستجو هدوپ
نوشته های مرتبط











همچنین ببینید
درخت تصمیم چیست و چگونه از الگوريتم هاي آن وضعیت آینده را پیشبینی کنیم
اگر میخواهید تا تصمیم پیچیدهای بگیرید و تصمیم دارید تا مسائل را برای خودتان به …

انواع روش های بصری سازی داده (ِData Visualization) و نحوه انتخاب بهترین نمودار
بصری سازی داده همواره یکی از گام های نهایی تحلیل و یا داده کاوی است. …
4 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام میشه لینک داخل مطلبو چک کنید.برای من مشکل داشت.ممنون
واقعا ممنون. سایتی غنی ، جامع و مانع در نوع خود دارید.
سلام.واقعا وبسایت خوبی دارید
تو زمینه ای که فعالیت میکنید جزو بهترین سایت ها هستید.