 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
رایانش شناختی و بکارگیری رایانش ابری در آن
ذهن انسان و توانمندی پردازشی آن فراتر از تصور است اما جامعه محاسبات رایانه ای به دنبال آن هستند که توانایی فکر کردن، رفتار و تصمیم گیری را بدون دخالت انسان برای رایانه ها فراهم نمایند. هدف رایانش شناختی در این حوزه آن است که فرآیند ذهن انسان را توسط رایانش مدل سازی نماید. رایانش شناختی ترکیبی از علوم شناختی و علوم رایانه ای است که یک مسیر راه را برای هوش مصنوعی فراهم می نماید و با قدرت محاسبات ابری قرار است قدرت تصمیم بهتر رایانشی، پیاده سازی ساده تر و دسترسی پذیری را فراهم نماید. رایانش شناختی بر بستر رایانش ابری همچنین می تواند میزان بازگشت سرمایه را نیز برای سیستم محاسبات شاختی فراهم نماید. این سیستم ابزاری خواهد بود که با تسهیل سازی ایجاد مدلهای فناوری اطلاعات بصورت خودکار، حل مشکلات را بدون دخالت انسان بصورت گسترده فراهم می نماید. سند پیش رو تلاش خواهد کرد پس از معرفی رایانش شناختی، بکار گیری بستر رایانش ابری برای آن و دغدغه های آینده آن را ارائه نماید. رایانش شناختی می تواند به عنوان مقدمه بر جنگ شناختی باشد.
عناوين مطالب: '
مروری بر محاسبات شناختی:
وضعیت حال حاضر کارکردهای رایانش نشاختی را اگر بخواهیم بررسی کنیم، خواهیم دید راه حل های پایه ارائه شده نقش ویژهای در دسترسی و کمک به انسان فراهم آورده اند. SIRI شرکت اپل، Google Assistant شرکت گوگل و Cortana شرکت مایکروسافت بخشی از این توسعه های پایه بر مبنای رایانش شناختی میباشند. این تکنولوژی به کمک حوزه های پزشکی و تحلیل داده های صنعتی و حوزه نفت و گاز نیز رفته است. در حقیقت هدف اصلی محاسبات شناختی ایجاد یک چارچوب محاسباتی است که بتواند مشکلات پیچیده دنیای انسان ها را بدون دخالت مستقیم انسان حل نماید. برای پیاده سازی این سیستم در سطح گسترده کاربردی، کنسرسیوم محاسبات شناختی قابلیت های زیر را برای این سیستم توصیه نموده است:
- تطابق: اولین قدم در ایجاد رایانش شناختی مبتنی بر یادگیری ماشین تطابق است. در این قابلیت، سیستم باید توانایی ذهن انسان در آموزش و تطابق با محیط اطراف تقلید نماید. این قابلیت برای یک وظیفه ایزوله شده نمیتواند برنامه ریزی گردد بلکه نیازمند پویایی در جمع آوری داده، فهم اهداف و فهم نیازمندی میباشد.
- تعامل: همانند ذهن انسان، رایانش شناختی باید با محیط اطراف، همه المان های سیستمی و … تعامل داشته باشد. همچنین نیازمند این است که با سیستم هوش تجاری نیز بصورت مستقیم ارتباط داشته باشد. سیستم باید ورودیهاي انسان را بفهمد و نتايج مرتبط را با زبان پردازش طبيعي و يادگيري عميق فراهم نمايد.
- تکرار و حفظ وضعيت: سيستم بايد تعامل قبلي انجام شده پردازشي را به ياد داشته و اطلاعات مناسب کاربرد خاص تعريف شده را در نقطه زمان مورد نياز ارائه دهد. اين ويژگي بايد بتواند مشکل نيازمند راه حل را با پرسيدن سوالات و يافتن منابع اضافي تعريف نمايد. البته ضروري است داده هاي ارائه شده به سيستم قبل از بهره برداري ارزيابي و ارزش گذاري گردد.
- محتوا: در اين ويژگي سيستم بايد المان هاي محتوايي مانند زمان، محل، دامنه مناسب، پروفايل کاربر، پردازه، وظايف و اهداف را درک و استخراج نمايد. اين داده ها ممکن است در منابع مختلف وجود داشته و بصورت ساختار يافته ديجيتال و يا بدون ساختار وجود داشته باشد. همچنين ممکن است بصورت گرافيکي، متني، صوتي و يا ارائه شده توسط حسگر ها باشد.
بررسی دامنه رايانش شناختي
در حالي ها رايانهها به دنبال سريع تر شدن و محاسبات و پردازش نسبت به انسان طي دهه گذشته بودهاند، اما آنچنان که بايد در وظايفي و فعاليت هايي که انسان انجام مي دهد مانند تشخيص و درک زبان طبيعي با تحليل و برداشت از تصاوير موفق نبوده اند. رايانش شناختي به دنبال آن است که چالش هاي جديد را قابل محاسبه نمايد.
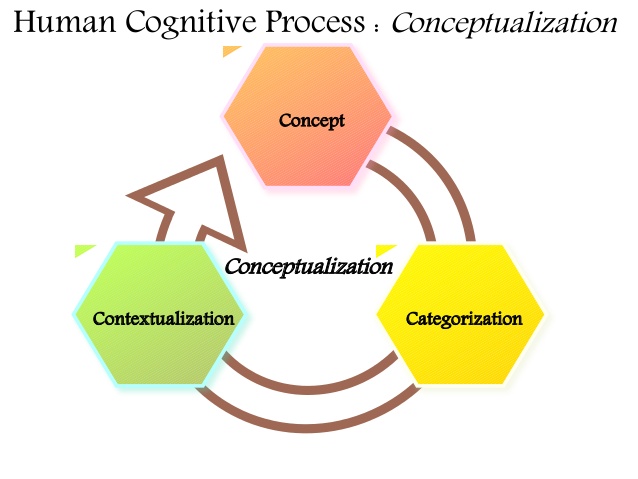
بر اساس مطالعاتي که IBM براي ارزشهاي تجاري رايانش شناختي انجام داده است، دامنه رايانش شناختي شامل سه توانمندي زير است که مرتبط با نحوه فکر کردن انسان و تصميمگيريهاي او در فعاليت هاي روزمره است.
- تعامل و مشارکت: سيستم هاي رايانش شناختي مخازن گسترده اي از داده هاي ساختار يافته و بدون ساختار دارند. اين منابع توانايي توسعه و عمق بخشيدن و دامنه فهميدن سيستم و ارائه دستياري خبره را دارند. مدل ساخته شده توسط اين سيستم شامل روابط محتوايي ميان مولفه هاي داخل سيستمهاي دنيا مي باشد که قابليت شکل دادن فرضیه ها و استدلال ها را فراهم ميکند و می توانند داده های مبهم و حتی خود متناقض را سازگار کنند. اين سيستم ها قادر به ايجاد يک گفت و گوي عميق با انسان هستند.
- تصميم: يک گام جلوتر از سيستمهاي تعامل، اين سيستم تصميم است که با استفاده از تقويت يادگيري مدل شده و قابليت تصميم گيري را فراهم مينمايد. تصمیمات گرفته شده توسط سیستم های شناختی به طور مداوم بر اساس اطلاعات ، نتایج و اقدامات جدید تکامل می یابند. تصمیم گیری مستقل به توانایی ردیابی اينکه چرا يک تصميم خاص اتخاذ شده و تغيير نمره اطمينان به آن تصميم خاص گرفته شده بستگي دارد. نمونه عمومي استفاده اين مدل، بکار گيري IBM Watson در سيستم هاي سلامت است. اين سيستم ميتواند داده هاي مرتبط به بيماران با شامل تاريخته و درمانشان جمع آوري و تحليل کند. سيستم داده هاي محتوايي پيچيده پزشکي ساختار يافته و بدون ساختار و با زبان طبيعي را در پرس و جو هايي استخراج و تحليل ميکند.
- کشف: پيشرفته ترين بخش در رايانش شناختي سيستم کشف است. اين سيستم شامل پیدا کردن بینش و درک مقدار زیادی از اطلاعات و توسعه مهارت هاي سيستم است. این مدل ها بر اساس یادگیری عمیق و یادگیری ماشین بدون نظارت ساخته شده اند. با حجم روزافزون داده ها ، نیاز آشکاری به سیستم هایی وجود دارد که به بهره برداری موثرتر از اطلاعات انسان کمک کند. اين سيستم اين قابليت را فراهم مي کند. سيستم مديريت اطلاعات شناختي يکي از خروجي هاي اين قابليت است که توسط جمع آوري جريان داده مانند ويديو، متن و … يک احساس تعامل، بررسي و نمايان سازي را در قالب پايش بر خط فراهم مينمايد.
- محدوديت هاي رايانش شناختي
اگرچه سيستمهاي رايانش شناختي به دنبال فراهم کردن قابليت هاي مغز انسان هستند، اما همچنان در موارد بسياري وابستگي داشته و در مواردي نيز ناتوان هستند. مهم ترين مواردي که براي سيستم هاي رايانش شناختي محدوديت ايجاد ميکنند شامل موارد زير هستند:
- محدوديت هاي تحليل ريسک: سیستم های شناختی در تجزیه و تحلیل ریسکی که در داده های بدون ساختار وجود دارد ، دچار محدوديت هستند. این موارد شامل عوامل اقتصادی – اجتماعی ، فرهنگ ، محیط های سیاسی و افراد است. به عنوان مثال، یک از کاربرد هاي اين سيستم مدل پیش بینی کننده مکانی برای اکتشاف نفت مي باشد که محل استخراج را مشخص می کند. اما اگر کشور بهره بردار در حال تغییر در دولت باشد، مدل شناختی باید این عامل را در نظر بگیرد و نتيجه بر روي خروجي تاثير گذار است. لذا مداخله انسان براي تصميم گيري در حوزه هدف نهايي موثر و مورد نياز است.
- فرآيند يادگيري موشکافانه: در ابتدا، سیستم های شناختی برای درک کامل فرآیند و پیشرفت به داده های آموزشی نیاز دارند. اين فرآیند پر زحمت آموزشي سیستم های شناختی به احتمال زیاد دليلي براي کندی پذیرش و تطابق آن خواهد بود. نمونه اين چالش در مديريت مالي WellPoint’s است که با چالش هاي مختلفي توسط محصولي که IBM-Watson ارائه داده است روبروست. فرآيند يادگيري اين محصول براي بکار گيري توسط بيمه شامل بازبيني دقيق متن ها در هر سياست تدوين شده پزشکي است که توسط مهندسان IBM انجام ميپذيرد. اين مورد براي پزشکي نيز صادق است. پرستاران براي تصميم گيري سيستم بايد تا زمان تکميل شدن تغذيه اطلاعاتي صبر کنند و اين زمان ممکن است براي آنها قابل قبول مباشد.
- هوش رفتاري انساني غالب بر هوش مصنوعي: دامنه فناوری شناختی فعلی محدود به مشارکت و تصمیم گیری است. از آنجا که سيستمهاي محاسبات شناختي عمدتا قرار است در نقش دستياري انسان قرار گيرند، لازم است عملکرد هوش رفتاري انساني غالب داشته باشند تا هوش مصنوعي. لذا هوش مصنوعي با عدم قطعيت هاي زيادي در بکارگيري مواجه است. اين مشکل زمان قابل توجه ميگردد که که تعداد منابع داده به طرز قابل توجهي افزايش يافته و به سرعت تغيير مي نمايند. لذا نياز است اين موضوع سيستم را با محدوديت هايي از جمله يکپارچگي، تجميع و تحليل داده هاي بدون ساختار مواجه مي نمايد. يک سيستم رايانش شناختي بايد تکنولوژي هاي زيادي را بکار گيرد تا بتواند به فهم عميقي از دامنه دست يابد.
قدرت هاي توسعه دهنده رايانش شناختي
قدرت هاي نرمافزاري دنيا از زمان شکل گيري رايانش شناختي بخش قابل توجهي از توان توسعه اي و تجاري خود را بر روي اين تکنولوژي متمرکز کردهاند. شرکت مايکروسافت، IBM و گوگل پيشتازان اين عرصه براي توسعه اين حوزه بودهاند. پيشتازان اين عرصه بودجه اي بيش از 26 ميليون دلار را براي اين حوزه اختصاص اند. البته حوزه هاي ديگر تجارت نرمافزار نيز در اين حوزه ورود کرده و قابليت هايي را توسعه داده اند. در ادامه مهمترين و فعالترين هاي اين حوزه ارائه ميگردند:
- IBM Watson: يک سوپرکامپيوتر است که ترکيب هوش مصنوعي و برنامه هاي تحليلي پيچيده را براي بازدهي بهينه به عنوان ماشين سوال و پاسخ بکار گرفته است. اما با توسعه مجموعه فن آوری های تحول آفرین مانند پردازش زبان طبیعی ، تشخیص تصویر ، تجزیه و تحلیل متن و عوامل مجازی، اين سيستم نيز خود را با آن منطبق کرده است. اين سيستم از تجزیه و تحلیل محتوای عمیق و استدلال مبتنی بر شواهد استفاده می کند و همراه با تکنیک های پردازش احتمالی، تصمیم گیری را بهبود بخشده، هزینه را کاهش و نتایج را بهینه ميکند.
- سرويس شناختي مايکروسافت: اين محصول که قبلا به عنوان Project Oxford شناخته ميشد، مجموعه اي از API ها و SDK ها را به همراه سرويسهاي شناختي ارائه ميداد تا توسعه دهندگان بتوانند توسط آن برنامههاي هوشمند تر توليد نمايند. با اين سرويس توسعه دهندگان ميتوانند خدمات شناختی از جمله ویژگی های هوشمند – مانند تشخیص احساسات و عاطفه ، تشخیص بینایی و گفتار، کشف دانش، جستجو و درک زبان را به برنامه های خود اضافه کنند.
- Google DeepMind: deepMind در سال 2014 توسط گوگل خریداری شد و به عنوان یکی از بازیگران برجسته در تحقیقات هوش مصنوعی شروع به کار کرد. این تیم متشکل از بسیاری از متخصصان مشهور در زمینه شبکه های عصبی، تقويت يادگيري و مدل های الهام گرفته از علوم عصبي ميباشد.
- SparkCognition: یک استارتاپ مستقر در آستین است که در سال 2014 تشکیل شده است. اين تيم محصولات قدرت يافته هوش مصنوعي سخت افزاري و نرم افزاري براي، امنیت سايبري و قابلیت اطمینان IT ، OT و IIoT ایجاد می کند. این سيستم قابليت استفاده از داده های حسگرها در زمان واقعی و یادگیری مداوم از آنها را دارد و اين امکان را فراهم ميکند سیاست های دقیقتري براي کاهش و پیشگیری از خطر و مداخله جهت جلوگیری از بلایا اتخاذ شود.
- تحليل گر تهديدات شناختي سيسکو: سيسکو با اين سيستم به دنبال آن است که تهديدات را سريع تر تشخيص داده و به آنها پاسخ دهد. اين سيستم ناهنجاري هاي حوزه وب را با بررسي ترافيک و انواع پارامتر هاي مختلف شبکه اي و محتوايي ارزيابي مي کند و حملات را پيش از وقوع با افزايش فيلترينگ داده هاي حساس خنثي ميسازد.
رايانش شناختي مبتني بر ابر
قدرتمندان رايانش شناختي از جمله گوگل، مايکروسافت، IBM و سرمايه گذاران اين حوزه در تلاش هستند قدرت ايجاد شده توسط اين تکنولوژي جديد را بيش از پيش در اختيار جامعه توسعه دهنده سرويس و بهره برداران آن قرار دهند. همانگونه که در بخش هاي قبلي توضيح و تشريح گرديد، رايانش شناختي نيازمند کار با منابع گسترده اي ميباشد که ضروري است توسط سرويسدهندگان قدرتمند فراهم گردد. اين منابع ممکن است زيرساخت هاي پردازشي و محاسباتي و يا حتي منابع قدرت و انرژي باشد. اين موضوع سبب ميشود تا ساختارهاي تجاري که توانمندي بکار گيري اين منابع را ندارند محروم بمانند.
از اين رو ساختارهاي رايانش ابري و سرويسهاي مبتني بر آنها راهحل هايي هستند که شرکت هاي سرمايه گذار بکار گرفتهاند تا بتوانند قدرت ايجاد شده را در اختيار جامعه توسعه دهنده قرارداده و از طرف ديگر درآمد مورد نياز خود را کسب نمايند. رايانش ابري به توسعه دهندگان اين امکان را ميدهد که مدلهاي شناختي خود را شکل داده، راه حل هاي خود را تست کنند، با سيستم هاي موجود آن را بدون نياز به زيرساخت سخت افزاري يکپارچه نمايند. نکته ديگر فراهم شده توسط رايانش ابري براي محاسبات شناختي اين است که توسعه دهندگان ميتوانند به دقت منابع دراختيار گذاشته شده را مديريت، محاسبه و مصرف را کنترل نمايند.
دلايل اصلي بکارگيري
پياده سازي زيرساخت و بستر پردازشي مورد نياز رايانش شناختي علاوه بر هزينه بر بودن دشواري هايي نيز دارد. اما اين مورد به همراه موارد قيد شده در بالا را ميتوان در دستههاي زير بصورت خلاصه ارائه نمود:
- بهينه سازي بکار گيري منابع: علاوه بر اينکه هزينه هاي توسعه منابع براي بهره برداران هوش تجاري با استفاده از رايانش ابري کاهش مييابد، استفاده از منابع در زمان نياز نيز خود عامل افزوده اي براي بهينه سازي بهره برداري از منابع است. همچنين منابع و پلتفرم مي تواند زماني که دريافت سرويس در وضعيت بلا استفاده قرار گرفته، ديگر بهره برداران را منتفع نمايد.
- بکارگيري خبرگان دانش: همانگونه که گفته شد، رايانش شناختي با خبرگي متخصصين داده کامل ميشود و برخي محدوديت هايش را پشت سر ميگذارد. رايانش ابري اين امکان را فراهم ميکند که نيازمندان داده از دانش خبرگي اشتراکي نيز استفاده نمايند.
- تکرار پذيري: بستر هاي رايانش ابري علاوه بر اينکه منابع لازم زيرساختي و زيرساخت رايانش شناختي را فراهم ميکنند، مدل هاي لازم بهره برداران را نيز براي بکار گيري ارائه ميدهند. از اين رو مدل هاي بکار گرفته شده و ارزيابي شده به عنوان راه حل هاي آماده ارائه ميگردند.
- ارتباطات دادهاي و منابع بيشتر: همانگونه که در بخش هاي قبل گفته شد، يکي از اساسي ترين ويژگي هاي سيستم هاي رايانشي نيازمندي به دسترسي به منابع مختلف و انجام پرس و جو هاي لازم است. همچنين يکي از محدوديت هايي که عنوان شد يادگيري مو شکافانه بود. با قرارگيري مدلهاي مختلف بر روي يک ساختار رايانش ابري و اشتراک داده هاي مختلف، سيستم مي تواند به ميزان قابل توجهي اين محدوديت را پشت سر گذارد.
- پيشرفت همزمان با سيستم: بکارگيري توسعه ها و مدل هاي جديد رايانش شناختي هزينه ساز خواهد بود. فراهم کنندگان بستر ابري اين قابليت را براي بهره برداران فراهم ميسازند تا همزمان با ارائه مدل هاي جديد و قابليت هاي نو، خود را با آن منطبق سازند. همچنين با توجه به اينکه اين زيرساخت ها قابليت هاي ديگري همانند يادگيري ماشين، هوش تجاري و موارد ديگر مشابه را نيز ارائه ميدهند، از نظر به روز رساني هزينه هاي کاربر را کاهش ميدهند.
روش بکارگيري واسط کاربري
همانگونه که در بخش قبل عنوان شد، سرويسهاي پايه خدمات رايانش شناختي قرار است کاربردهاي استخراج محتوايي همانند پردازش زبان طبيعي، استخراج موضعات از تصاوير بر مبناي فهم انسان، استخراج از صوت و … را ارائه دهند. سرويسهاي رايانش ابري با ارائه API هاي مناسب به توسعه دهندگان اين امکان را فراهم ميکنند. توسعه دهندگان نيز با استفاده از REST API ميتوانند همانند هر سرويس وب ديگر از آن بهره مند گردند. همانگونه که عنوان شد شرکت هاي بزرگ حوزه فناوري بخشي از سرمايه گذاري خود را بر اين حوزه متمرکز کرده اند. اين شرکت ها از جمله هوش مصنوعی گوگل Google Cloud AI APIs، سرویسهای شناختی مایکروسافت Microsoft Cognitive Services و رابطهای برنامهنویسی کاربردی آیبیام واتسون IBM Watson API نمونههایی از سرویسهای ادراکی هستند که اکنون با رابطهاي API خدمات خود را بر بستر ابر ارائه ميدهند.
ارائه سرويس هاي زيرساختي
يکي از انواع ارائه سرويسهاي شناختي، فراهم کردن زيرساخت به عنوان سرويس است (IaaS). صاحبان مراکز داده بزرگ اين سرويس ها را با فراهم کردن ماشين هاي خام مجازي که به وسيله پردازنده هاي قوي و شتاب ساز ها مانند کارتهاي گرافيکي در کنار مدار هاي مجتمع پردازشي کاربرد همانند FPGA تجهيز شده فراهم ميآورند. تيم هاي DevOps کساني هستند که نيازمندان سرويس براي بهره برداري از اين زيرساخت ها کمک مينمايند. آنها زيرساخت مناسب را فراهم آورده و حتي کتابخانه هاي مورد نياز براي ايجاد سرويس را نيز پيکربندي و ارائه مي دهند.
گوگل و مايکروسافت دو شرکت پيشتاز در اين حوزه طي سالهاي اخير بوده اند. واحد پردازشي گوگل Google’s TPU و FPGA مايکروسافت نمونه هايي از شتاب دهنده هاي سخت افزاري سفارشي هستند که بصورت خاص براي اين کاربرد طراحي شده اند. البته مولفه هايي مانند Kubernetes که پلتفرمي برای مدیریت کانتینرها هست نيز قدرت ويژه اي را به اين حوزه بخشيده است.
فرصت ها و چالشها رایانش شناختی
زيرساخت هاي ابري رايانش شناختي اگرچه قابليت هاي مناسبي را براي توسعه دهندگان و بهره برداران فراهم آوردهاند و ميتوانند بصورت قابل توجهي هزينه ها را کاهش و قابليت به روز بودن و استفاده از مدل هاي شناختي را فراهم کنند، اما به عنوان ساختارهايي که هر روز به منابع جديد دست يافته و فهم به روز تري پيدا ميکنند داراي نگراني هستند. از طرف ديگر بهره برداران بايد به دنبال روش هايي باشند که مدل هاي شناختي بتوانند با حفظ حريم خصوصي و محرمانگي داده هاي ارائه شده، خروجي ها و مسائل آنها را حل نمايند.
نکته قابل توجه ديگر اينکه زماني که بهره بردار به مدل شناختي سرويس دهنده اعتماد مينمايد، بايد خروجي ها و مسئله خود را نيز بر اساس پارامتر هاي ارائه دهنده سرويس حل نمايد. از اين رو براي چهار خدمت ياد شده از حمله تطابق، تکامل، تکرار و محتوا نيازمند اعتماد به سيستم ارائه دهنده ميباشد.
نتیجه گیری:
رايانش ابري به عنوان يه متدولوژي فرصت جديدي را براي کاهش هزينه ها و توسعه مبتني بر سطوح کاربرد فراهم آورده است. فناوري اطلاعات در حال گذر از نسل قديم و توسعه مبتني بر تکنولوژي هاي مجازي سازي و همچنين ابزارهاي مديريت مجازي سازي است. نسلهاي آينده تکنولوژي از جمله سرويسهاي مخابراتي تمرکز ارائه سرويس خود را بر هوش تجاري، هوش مصنوعي و محاسبات شناختي متمرکز کرده اند. همچنين شرکتهاي بزرگ حوزه فناوري اطلاعات و ارتباطات سرمايه قابل توجهي را به اين بخش اختصاص داده تا هم کسب درآمد نموده و هم از ظرفيت داده هاي در حال جمع آوري استفاده نمايند. محدوديت هاي کشور در دسترسي به منابع خارجي، تحريم ها و … لازمه بهره گيري مناسب و ايجاد زيرساخت هاي لازم در کشور به منظور بکارگيري اين سرويس ها را نياز دارد. با وجود محدود بودن مطالب منتشر شده در اين حوزه، تلاش شد در سند پيش رو چشم اندازي از اين تکنولوژي ارائه گردد.
منابع
- https://cognitivecomputingconsortium.com/resources/cognitive-computing-defined/
- https://www.ibm.com/downloads/cas/YVPMGWLP
- https://cdn-gcp.marutitech.com/wp-media/2017/06/What-is-Cognitive-Computing-Features-Scope-Limitations_2.jpg
- https://www.dataversity.net/another-face-cognitive-computing/
- https://www.predictiveanalyticstoday.com/what-is-cognitive-computing/
- https://medium.com/@arvind_mehrotra/cognitive-computing-takes-to-the-cloud-part-1-what-is-it-and-why-do-you-need-it-ed36e2775ea5
- https://itbizadvisor.com/2018/10/cognitive-cloud-computing-and-it-as-a-service-hold-the-key-to-enterprise-rebirth/
ارائه و تدوین: امیر حسین پورشمس تهیه شده زیر نظر جناب آقای دکتر حبیبی
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 804
برچسبرایانش شناختی












{kind=link}