 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خصوصیات و امکانات آپاچی کاساندرا نسخه سری 3.9
نکته مهمی که باید پیش از نصب و راه اندازی Cassandra به آن توجه کرد، نسخه آن است. جدیدترین نسخه Cassandra (در زمان تحریر این سند) 3.9 و جدیدترین نسخه پایدار آن، 2.2.8 است. نسخه 2.2.8 ، پایان حیات سری 2.0 است (یعنی آخرین نسخه در سری دو، 2.2 است) و این نسخه تا زمان انتشار نسخه 4.0 کاساندرا پشتیبانی میشود. کاساندرا، از نسخه 3.0 ویژگیهای قابل توجهی را ایجاد کرده است. نسخه های 3.x معروف به نسخه های تیک تاک هستند؛ بدین معنی که x های فرد، شامل رفع اشکال و x های زوج شامل رفع اشکال و ویژگیهای جدید است. مهمترین ویژگیها شامل موارد زیر است:
پیاده سازی ایندکس SASI
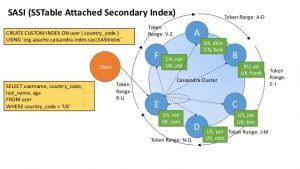
از نسخه 3.4، میتوان از پیاده سازی جدیدی از اندیسهای ثانویه SSTable Attached Secondary Index (SASI) بهره برد. برای ستونهایی که توسط پیادهسازی SASI، اندیس ثانویه میشوند، میتوان در پرسوجوها از عملگرهای نامساوی (پرسوجوی محدودهای از مقادیر) و LIKE (مانند SQL) استفاده کرد. همچنین در این نوع پیاده سازی، در پرسوجوهایی که نیاز به پالایش دارند (Allow filtering)، کارایی قابل توجهی حاصل میشود. در این پیاده سازی تا به امروز (نسخه 3.9) نمیتوان Collection ها را اندیس نمود.
برای دیدن مطالب بیشتر در رابطه با این موضوع اینجا کلیک کنید.
Materialized view استفاده ویژیگی نما های از پیش تولید شده materialized view
اما در نسخه های سری 3.0 کاساندرا، میتوان از قابلیت materialized view بهره برد. این ویژگی در نسخه 3.0 کاساندرا و نسخه های بعدی از آن اضافه شده است. materialized view جدولی است که از داده های جدول دیگری با کلید اصلی و مشخصه های جدید ایجاد میشود.
سخه ۳ کاساندرا ،با معرفی نماهای محاسبه شده، این امکان را می دهد که برای یک موجودیت خاص، کوئری های مختلف را در قالب نماهای محاسبه شده ذخیره شود و با آنها مانند یک جدول اصلی رفتار میکند. یعنی دیگر نیاز به تعریف جدول های مختلف با ساختار یکسان برای یک موجودیت نخواهد بود.
create materialized view user_by_name
as select * from user1
where name is not null and user_id is not null and birthday is not null
primary key(name,user_id,birthday );
- نقاط قوت این روش:
- با هر درج اطلاعات در جدول اصلی، این نماها هم به طور خودکار آپدیت شوند و نگرانی قدیمی بودن این نماها وجود ندارد.
- دیگر نیاز به تعریف جدول های مختلف با ساختار یکسان برای یک موجودیت نخواهد بود.
- سرعت اجرا در مقایسه با استفاده از قابلیت ALLOW FILTERING بهبود پیدا میکند.
- نتایج از قبل محاسبه شده هستند.
برای دیدن مطالب بیشتر در رابطه با این موضوع اینجا کلیک کنید.
ارتقاء آسان
نسخههای 3.x (3.1 تا 3.9) بدون دردسر قابل ارتقاء هستند.
ستون ایستا
از نسخه 3.4، ستونهایstatic قابل اندیس(اندیس ثانویه) هستند و از نسخه 3.6 میتوان از پیاده سازی SASI برای اندیسگذاری ستون های ایستا استفاده کرد.
قابلیت Allow Filtering از کساندرا 3.6 برای بهره برداری بهتر از کاساندرا به این پایگاه داده اضافه شد.
با قابلیت Allow Filtering از کساندرا 3.6 به بعد بدون استفاده از ایندکس ثانویه میتوان در جدول مورد نظر، درخواست پرسوجوی (where) بر روی هر فیلدی انجام داد بدون آنکه در شرط کلید پارتیشن یا کلید اصلی ذکر شود. همچنین بعد انجام ایندکس ثانویه میتوان در جدول مورد نظر، درخواست پرسوجوی (where) بر روی هر فیلدی که ایندکس ثانویه شده، بدون آنکه در شرط کلید پارتیشن یا کلید اصلی ذکر شود، انجام داد.
نکته: استفاده از قابلیت Allow Filtering بر روی نتایج خیلی بزرگ مناسب نیست.
نکته: استفاده از قابلیت Allow Filtering بر روی داده های هایی که به واسطه استفاده از Allow Filtering تعداد زیادی از آنها حذف میشود. هزینه زیادی دارد و یک استفاده صحیح از Allow Filtering نیست.
نکته: استفاده از قابلیت Allow Filtering در اصل فیلتر زدن بر روی نتیجه داده های select است به عبارتی گویا یک درخواست دوم بر روی درخواست اول انجام میشود.
نکته: استفاده از قابلیت Allow Filtering در اصل فیلتر زدن بر روی نتیجه داده های select است که در سمت استفاده کننده از درخواست پردازش میشود به عیارتی سربار این عمل بر روی کامپیوتر مصرف کننده از این دستور است. (البته تا جایی که متوجه شدم بعدا اگر وقت کردم بررسی میکنم و این نکته را اصلاح میکنم)
برای دیدن مطالب بیشتر در رابطه با این موضوع اینجا کلیک کنید.
موتور ذخیره سازی:
در موتور ذخیرهسازی (مدل دادهای داخلی) نسخه 3.x، تغییرات اساسی ایجاد شده است. موتور ذخیره سازی در نسخه های پیش از 3.0 (برای نمونه نسخه پایدار 2.2.x) دارای ساختار زیر است:
| ساختار قدیمی | Map<byte[], SortedMap<byte[], Cell>> |
این ساختار علیرغم سادگی (در درک ساختار)، پیچیدگی هایی را برای موتور ذخیره سازی بوجود میآورد که موجب تکرارهای زیاد (افزونگی غیرضروری) و ناکارامدی میشود. در واقع یک SSTable، نمایشی از پارتیشها و سلولهای آنها است.
همانطور که مشاهده میشود، مقدار مهرزمانی هر ستون، در ستونهای غیر از کلید اصلی، در هر سلول تکرار میشود (باید توجه داشت که مقدار ttl نیز در صورت وجود، مانند مقدار مهرزمانی، در هر سلول تکرار میشود).
ساختار دادهها در موتور ذخیرهسازی در نسخههای پس از 3.0، بصورت ذیل میباشد:
| ساختار جدید | Map<byte[], SortedMap<Clustering, Row>> |
به دلیل سطر محور بودن مدل دادهای در نسخه 3.9، مقدار مهرزمانی (و مقدار ttl در صورت وجود) تنها یکبار و آن هم در سطح سطر قرار دارد. حجیم بودن مدل دادهای در نسخه 3.9، تنها بهدلیل نحوه نمایش ابزار sstabledump است و در حقیقت (مدل دادهای واقعی) اینگونه نخواهد بود.
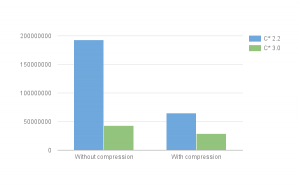
همانطور که در شکل مشاهده میشود، حجم دادهها در نسخه 2.2 حتی در صورت اعمال فشردهسازی (در اینصورت سربار پردازشی افزایش مییابد) بسیار بیشتر از حجم دادهها در نسخه ی 3.0 است.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 1159
برچسبAllow Filtering Cassandra Materialized view SSTable Attached Secondary Index view کاساندرا متریالایز ویو نما نماهای از پیش محاسبه شده نماهای محاسبه شده
نوشته های مرتبط










همچنین ببینید
راه اندازی و نصب کسندرا بر روی چند سرور و ایجاد خوشه پردازشی
در پست های قبلی به نصب و راه اندازی پایگاه داده غیر رابطه ای کاساندرا …
نحوه اتصال به کاساندرا با جاوا (قسمت دوم برنامه نمونه)
در قسمت اول با درایور یا راه اندازهای کاساندرا نسخه 3 برای اتصال به جاوا …
