 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
انواع پایگاه داده های غیر رابطه ای یا NOSQL
انواع پایگاه داده های NOSQL: پایگاه داده های غیر رابطه ای براساسِ روشی که داده ها را ذخیره میکنند، دسته بندی میشوند. هر چند امروزه بعضی از پایگاه داده های غیر رابطه ای پا را از دسته بندی مطرح شده در این مبحث فراتر گذاشته و به صورت چند منظوره عمل میکنند. البته قبل از ارائه دسته بندی در این پست، سیر زمانی بوجود آمدن پایگاه دادهای NoSQL را در دوشکل زیر بررسی میکنم. هر چند که از سال 2003 فعالیت هایی در حوزه تولید ابزار های کلان داده مثل هدوپ صورت گرفته است ولی عملا از سال 2013 پایگاه داده های غیر رابطه ای معروف ارائه شده اند. (پیشنهاد میشود برای دیدن سایر ابزار های در حوزه کلان داده و گراف کاوی به این مبحث مراجعه کنید)
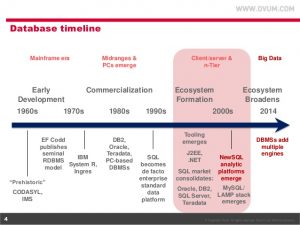
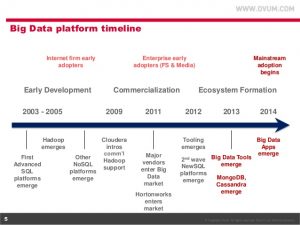
دسته های اصلی که در مقالات بیان میشود، شامل موارد ذیل است:
- مخازن کلید-مقدار (Key-value stores)
- مخازن سندگرا (Document-oriented stores)
- مخازن ستونگرا یا ستونی گسترده (Wide column stores-Column family stores-Extensible Record stores)
- پایگاه های داده مبتنی بر گراف (Graph oriented,Graph base)

عناوين مطالب: '
نمونه هایی از انواع پایگاه داده های NOSQL:
- مخازن کلید-مقدار (key value)مانند: Aerospike, Couchbase, Dynamo, FairCom c-treeACE, FoundationDB, HyperDex, MemcacheDB, MUMPS, Oracle NoSQL Database, OrientDB, Redis, Riak, Berkeley DB
- مخازن سندگرا مانند: Apache CouchDB, Clusterpoint, Couchbase, DocumentDB, HyperDex, Lotus Notes, MarkLogic, MongoDB, OrientDB, Qizx, RethinkDB
- مخازن ستونگرا مانند: , Accumulo , Cassandra , Druid , HBase Vertica
- پایگاههای داده مبتنی بر گراف: AllegroGraph, InfiniteGraph, Giraph, MarkLogic, Neo4J, OrientDB, Virtuoso, Stardog
- چند مدلی مانند: Alchemy Database, ArangoDB, CortexDB, FoundationDB, MarkLogic, OrientDB
انواع پایگاه داده های NOSQL
مخازن کلید-مقدار
بانکهای key value اطلاعاتی شامل جداولی از اطلاعات هستند. هر جدول نیز شامل تعدادی ردیف است؛ چیزی همانند بانکهای اطلاعاتی رابطهای. اما در هر ردیف، یک Dictionary یا آرایهای از اطلاعات key-value شکل را شاهد خواهید بود. در اینجا ساختار و شمای ردیفها میتوانند نسبت به یکدیگر کاملاً متفاوت باشند. دراینبین، تنها تضمین خواهد شد که هر ردیف، Id منحصربهفردی دارد. از این نوع بانکهای اطلاعاتی، در سکوهای کاری ابری زیاد استفاده میشود.
ساده ترین نوع از DBMSهای NoSQL، شامل مجموعهای از جفتهای کلید-مقدار است. همانطور که از نام آن مشخص است، مخزن کلید-مقدار، سیستمی است که به منظور بازیابی، مقادیر را بدون شِما (schema-less) و براساس کلید، اندیسگذاری و ذخیره میکند. یک کلید بطور یکتا، مقداری را که میتواند دارای ساختار یا کاملا بدون ساختار باشد، مشخص میکند. در واقع، جستجو معمولا تنها بر اساس کلید صورت میگیرد.
سادگی مخازن کلید-مقدار، آنها را برای بازیابی بسیار سریع مقادیر در کاربردهایی نظیر مدیریت نمایههای کاربر، مدیریت وضعیت (برای مثال، ثبت وضعیت سبد خرید کاربر) و جلسه و همچنین بازیابی نام محصولات، مناسب میسازد. Amazon، از مخزن کلید-مقدار Dynamo برای مدیریت سبد خرید کاربران استفاده میکند.
مخازن سندگرا
در مخازن سندگرا میتوان داده های پیچیده تری را نسبت به مخازن کلید-مقدار، ذخیره کرد. این نوع از DBMSهای NoSQL از اندیسهای ثانویه، از انواع اسناد یا اشیاء در هر پایگاهداده، و اسناد تودرتو یا لیستها، پشتیبانی میکنند. به هر عضو از داده ها در این نوع از مخازن، سند، و به گروهی از اسناد، مجموعه میگویند. میتوان مجموعهها را معادل جداول در پایگاههای داده رابطهای و سند را نیز، رکورد فرض کرد. اما تفاوت بسیار مهم در این دو مدل این است که هر رکورد در هر جدول، دارای تعداد مشابهی از فیلدها(یا ستونها) است، در حالیکه اسناد در یک مجموعه ممکن است دارای فیلدهای مختلفی باشند. در این نوع از DBMSها، اسناد را علاوه بر کلید، میتوان براساس محتوا نیز جستجو کرد .
مخازن سندگرا، برای مدیریت و ذخیرهسازی دادههای عظیم پراکنده که نیاز به استفاده از مقادیر null در DBMSهای رابطهای دارند(نیمه ساختیافته)، مناسب هستند.
در مخازن سندگرا بجای جداول، دارای بانکهای اطلاعاتی مختلفی هستند و در اینجا بجای ردیفها، سند یا document دارند. ساختار سندها نیز عموماً بر مبنای اشیاء JSON تعریف میگردد. بنابراین هر سند دارای تعدادی خاصیت است (چون اشیاء JSON به این نحو تعریف میگردند) که دارای مقدار هستند. در نگاه اول، شاید این نوع اسناد، بسیار شبیه به key-value stores به نظر برسند. اما در حین تعریف اشیاء JSON، یک مقدار میتواند خود یک شیء کامل دیگر باشد و نه صرفاً یک مقدار ساده. به همین جهت عدهای به این نوع بانکهای اطلاعاتی، بانکهای اطلاعاتی Key-value store سفارشی و خاص نیز میگویند.
مخازن ستونی گسترده
پایگاههای داده ستونی با توسعه کلید-مقدارها بوجود آمدهاند. این سیستمها درواقع بجای یک جفت کلید-مقدار، میتوانند برای هر رکورد چندین جفت کلید-مقدار داشته باشند. در این نوع نیازی به ساختار نداریم و هر رکورد میتواند چندین ستون با تعداد صفات متفاوت داشته باشند. از مزایای این دسته میتواند ذخیره سازی میزان وسیع و متفاوتی از رکوردها با مقادیر بسیار باشد.
مخازن ستونی گسترده یا ستونگرا، از محصول موفق BigTable شرکت گوگل تاثیر پذیرفتهاند. سطرها و ستونها، مدل دادهای اصلی آنها را تشکیل میدهند. در این نوع از DBMSها، مقیاسپذیری با تقسیم سطرها و ستونها در میان چندین گره، فراهم میشود (توزیع دادهها بصورت افقی و عمودی):
- سطرها توسط sharding و براساس کلید اصلی، شکسته و در میان گرهها تقسیم میشود.
- ستونهای جدول، بر اساس فامیلی ستون، در میان گرهها توزیع میشود.
پایگاه های داده مبتنی بر گراف
پایگاه های داده گرافی، جداول رابطهای را با گرافهای رابطهای ساخت یافته ی جفتهای کلید-مقدار متصل، جایگزین میکند. در واقع، این DBMSها، برای رابطه(پیمایش) بهینه سازی شده است (برای مثال، دوستِ دوستِ دوستِ … تمام کاربران). زمانیکه روابط بین دادهها، از خود دادهها، مهمتر باشد، از DBMSهای گرافی استفاده میشود؛ برای مثال نمایش و پیمایش شبکه های اجتماعی، تولید لیست پیشنهاد در فروشگاه های برخط و غیره. برای مدل کردن این گرافها در پایگاه داده رابطهای، تعداد بسیار زیادی رابطه چند به چند ایجاد خواهد شد. بنابراین، برای اجرای پرسوجوهایی که تمرکز آنها بر روی روابط بین دادهها است، عملیات الحاق (join) پیچیدهای لازم خواهد بود.
Graph databases نوع خاصی از بانکهای اطلاعاتی NoSQL هستند که جهت ردیابی ارتباطات بین اطلاعات طراحی شدهاند و برای برنامههای شبکههای اجتماعی بسیار مفید هستند. در اینجا نودها میتوانند دارای خاصیتها و مقادیر متناظر با آنها باشند.
در نهایت برای درک میزان حجم قابل پشتیبانی و پیچیدگی داده، نمودار زیر را بررسی کنید.

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 10967
برچسبNOSQL انواع NOSQL انواع پایگاه داده های NOSQL انواع پایگاه داده های غیر رابطه ای انواع پایگاه داده های غیر رابطه ای یا NOSQL پایگاه پایگاه داده غیر رابطه ای پایگاه داده های NOSQL ستون گسترده غیر رابطه ای کلید-مقدار مبتنی بر سند مبتنی بر گراف مخازن ستونگرا مخازن سندگرا مدل های NOSQL
نوشته های مرتبط








همچنین ببینید
راه اندازی و نصب کسندرا بر روی چند سرور و ایجاد خوشه پردازشی
در پست های قبلی به نصب و راه اندازی پایگاه داده غیر رابطه ای کاساندرا …
نحوه اتصال به کاساندرا با جاوا (قسمت اول آشنایی با راه اندازها)
در این بخش، نحوه اتصال به کاساندرا با جاوا بررسی خواهد شد. ابتدا به نحوه …
یک دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

خیلی خوب و کامل بود