 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش پایگاه داده مبتنی بر گراف Neo4J و اتصال با زبان جاوا
چکیده
بسیاری از برنامه نویسان کار با پایگاه داده های رابطه ای (RDMS) را ترک نموده و به سمت پایگاه داده های گراف متمایل شده اند. Neo4j یکی از محبوب ترین پایگاه داده گرافی (Graph databases) اپن سورس است که امکان مدیریت و کار با داده ها و رابط پیچیده تر را فراهم می کند. همانطور که می دانید یک پایگاه دادههای گراف از ساختار گراف با گرهها، گوشهها و ویژگیها برای نمایش و ذخیرهسازی دادهها استفاده میکند. بنابر تعریف یک پایگاه دادههای گراف هر حافظهای است که بتواند همسایگیهای بدون اندیس را پشتیبانی کند. این بدین معنی است که هر عنصر شامل یک اشارهگر به عناصر همسایهاش است و متغیر اندیسی نیاز ندارد.
مقدمه
اغلب پایگاه داده های مبتنی بر گراف به طور طبیعی زیرمجموعهای از NoSql ها محسوب میشوند و اطلاعاتشان را به صورت key-value یا دیتابیس سند محور (document-oriented database) ذخیره میکنند. در شرایط کلی آنها میتوانند به عنوان دیتابیس key-value با بهرهگیری از مفهوم روابط پذیری (relationship) در نظر گرفته شوند. روابط (Relationships) در ذخیرهسازی دادهها به valuesها اجازه میدهند در شکل یک فورم آزاد به یکدیگر مرتبط باشند؛ و برعکس دیتابیسهای سنتی که روابط در داخل خود دیتاها تعریف میشد عمل کنند.
این روابط اجازه میدهند سلسله مراتبهای پیچیده به سرعت طی شود و در نتیجه سرعت دسترسی و بهینه گی سیستم افزایش مییابد؛ که این نوع فرایند ذخیرهسازی پیچیده در دیتابیس های گرافی یکی از مشکلات عمومی عملکرد که در ذخیرهسازی سنتی key-value صورت میگرفت را به نوعی حل کرده است. اکثر دیتابیسهای گرافی همچنین مفهوم tags یا properties را نیز به مقوله پایگاه داده اضافه کردند که اساساً روابط فاقد یک اشاره گر به پروندههای دیگر بود.
از جمله پایگاه داد های NoSQL در حوزه ذخیره سازی گراف Neo4j است. یک پایگاه داده مبتنی بر گراف، پایگاه داده ای است که از ساختار گرافها برای queries های معنایی با گره ها و یالها و خواص برای نشان دادن و ذخیره داده ها استفاده می کند. Neo4j معروف ترین DBMS متن باز گرافی است که کارایی و مستندسازی بسیار خوب و جامعه کاربران بسیار فعالی دارد. برای پرسوجو از گراف های Neo4j می توان توسط زبان پرس وجوی امری cypher استفاده کرد.
در Neo4j مقایس پذیری افقی عمل خواندن توسط روش تکثیر ارباب-برده، صورت می گیرد، اما تمام درخواست های نوشتن، فقط در یک ماشین پاسخ داده می شوند، درنتیجه عمل نوشتن بصورت افقی مقیاس پذیر نمی باشد. بنابراین می توان نتیجه گرفت که Neo4j برای کاربردهایی که میزان نوشتن کم و خواندن زیاد است، مناسب است. به عبارتی Neo4j برای کاربردهایی که بصورت دوره ای، گراف را بهنگام می کنند اما بار عمل خواندن در آنها بسیار بالا است، مناسب می باشد.
توضیح (نحوه انجام کار)
بطور خلاصه گامهای زیر در این کار انجام خواهد شد:
- نصب و راه اندازی Neo4J
- آموزش و کار با محیط Neo4J
- نصب و راه اندازی Driver (برای … , java)
- توسعه کد در محیط IntelliJ IDEA 2018 (تشریح پروژه)
- نصب و راه اندازی Neo4J
با مراجعه به سایت neo4j می توانید نسخه دسکتاپ و یا سرور محلی را دانلود و نصب کنید. اگر قصد استفاده از نسخه Desktop را داشته باشید باید از Bloom neo4J و یا Server محلی برای explore پروژه خود استفاده کنید. ساده ترین راه نصب سرور محلی و کار با آن است. پس از طی مراحل نصب سرور، از آدرس http://localhost:7474/ و نام کاربری و رمز عبور neo4j استفاده کرده و در اولین ورود رمز خود را تغییر دهید.
نکته : اگر رمز سرور محلی خود را فراموش کردید کافی است فایل احراز هویت auth در مسیر نصب سرور را پاک کرده سرویس neo4j را دوباره راه اندازی (restart) کنید.
sudo rm -rf ./data/dbms/auth
sudo bash ./bin/neo4j restart
در این محیط می توانید در خط فرمان دستورات مورد نظر خود را اجرا و نتیجه را مورد مشاهده و بازبینی قرار دهید.
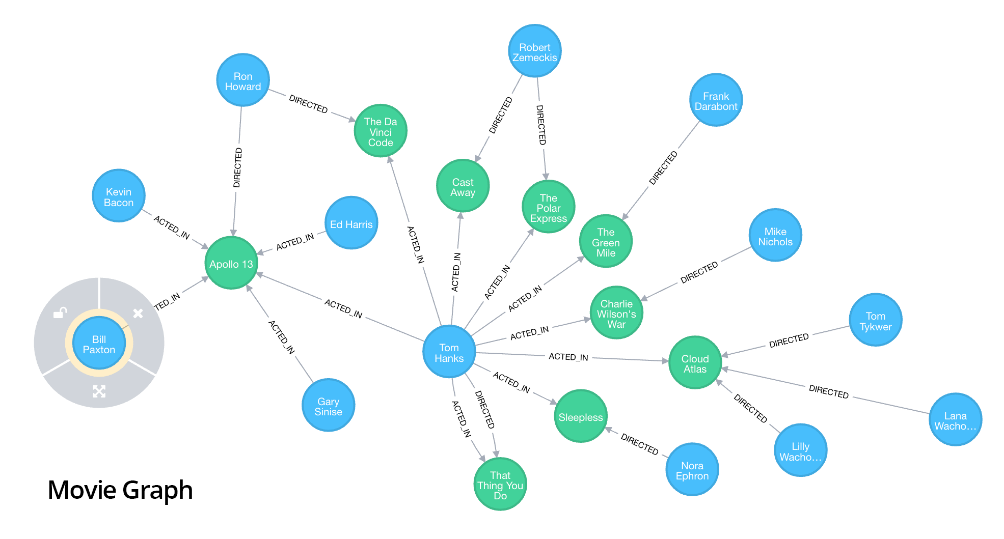
بصورت خلاصه کارهای زیر را می توانید انجام دهید:
- Import data
- Call user-defined procedures in Java
- Profile queries, looking at the execution plan with EXPLAIN and PROFILE.
- آموزش و کار با محیط Neo4J
آموزش های زیادی با موضوع neo4j می توان استفاده که به عنوان نمونه من از آموزش زیر استفاده کرده ام :
زبان آموزش: انگلیسی
مدرس: Duane Nickull
سطح آموزشی: متوسطه
زمان آموزش: 3 ساعت + 12 دقیقه
حجم فایل: 346.5 مگابایت
تاریخ انتشار: 1393/7/18 | 2014.10.10
بطور خلاصه مطالب زیر در این آموزش آمده است:
– تعریف NoSQL و پایگاه داده گراف
– بررسی مبانی مدل سازی گراف
– استفاده از Cypher برای کوئری ها (query) در Neo4j
– استفاده از مسیرها (paths) برای عبور از گره های متعدد
– استفاده از گره های خاص
– ایجاد موجودیت (entity)
– حذف موجودیت
– و …
- نصب و راه اندازی Driver (برای … , java)
بطور خلاصه درایور های neo4j رابط های برنامه نویسی و توسعه کد هستند و به برنامه نویسان این امکان را می دهند تا از این ابزار در برنامه های خود استفاده کنند. این رابط ها در Javascript, Java, .NET, and Python قابل استفاده هستند و کاربر می بایست از قبل این کتابخانه ها را با توجه به زبان برنامه نویسی خود دانلود کند. البته درایورهایی برای PHP, Ruby, Go, Haskell , … نیز در سایت neo4j وجود دارند که می توان بکار برد.
- توسعه کد در محیط IntelliJ IDEA 2018 (با استفاده از sample)
بطور خلاصه برای کار با درایور جاوا باید از کتابخانه (package) مربوطه بصورت زیر استفاده کنیم :
import org.neo4j.driver.v1.*;
تشریح برنامه بطور خلاصه
- کلاس اصلی Neo4jTest
- متغیر driver جهت اتصال به درایور بانک neo4j
- متغیر NodeName جهت دخیره سازی Node Label در دیتابیس neo4j
- آرایه headers جهت ذخیره سازی نام properties نودها
- آرایه nodeIDs جهت ذخیره سازی نام یا شناسه نودها
- متد clearNodes تمامی نودها و رابطه آنها را حذف می کند
- متد importCSV با استفاده از متد داخلی neo4j جاوا فایل persons.csv را import می کند
- متد addNode نود جدید را ایجاد می کند
- متد addRelation رابطه بین نودها را ایجاد می کند
- بطور کلی در Main فرایندهای زیر به ترتیب انجام می شود :
– اتصال به بانک neo4j با
Neo4jTest example = new Neo4jTest(“bolt://localhost:7687”, “neo4j”, “admin”);
– import فایل persons.csv با استفاده از متد داخلی neo4j
example.importCSV(“persons.csv”);
– خواندن فایل names.csv و بدست آوردن تعداد و نام نودها و مشخصات (properties) نودها و پر کردن آرایه های نام نودها و نام مشخصات
– خواندن دوباره فایل names.csv و ایجاد نودها با برجسب و properties مربوط به هر نود
– خواندن فایل ماتریس مجاورت نودها relations.csv و ایجاد رابطه نودها
کد برنامه در زیر آمده است :
package com.example;
//import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import org.neo4j.driver.v1.*;
//import static org.neo4j.driver.v1.Values.ofToString;
import static org.neo4j.driver.v1.Values.parameters;
import static org.neo4j.driver.v1.Values.value;
public class Neo4jTest {
// Driver objects are thread-safe and are typically made available application-wide.
private Driver driver;
private String NodeName;
private String headers[];
private String nodeIDs[];
public Neo4jTest(String uri, String user, String password)
{
driver = GraphDatabase.driver(uri, AuthTokens.basic(user, password));
NodeName="PAGE";
}
private void set_NodeName(String st){
NodeName=st;
}
private void clearNodes()
{
// Sessions are lightweight and disposable connection wrappers.
try (Session session = driver.session())
{
// Wrapping Cypher in an explicit transaction provides atomicity
// and makes handling errors much easier.
try (Transaction tx = session.beginTransaction())
{
//MATCH (n { name: 'Andres' })-[r:KNOWS]->()
//DELETE r
tx.run(" MATCH (n) DELETE n;");
tx.success(); // Mark this write as successful.
//tx.run(" MATCH (n) REMOVE n");
//tx.success(); // Mark this write as successful.
}
}
}
private void importCSV(String file_name)
{
// Sessions are lightweight and disposable connection wrappers.
try (Session session = driver.session())
{
// Wrapping Cypher in an explicit transaction provides atomicity
// and makes handling errors much easier.
try (Transaction tx = session.beginTransaction())
{
tx.run("LOAD CSV WITH HEADERS FROM 'file:///"+file_name+"' AS csvLine CREATE (p:Person { id: toInteger(csvLine.id), name: csvLine.name });");
//tx.run("LOAD CSV WITH HEADERS FROM 'https://neo4j.com/docs/developer-manual/3.2/csv/import/persons.csv' AS csvLine CREATE (p:Person { id: toInteger(csvLine.id), name: csvLine.name });");
tx.success(); // Mark this write as successful.
}
}
}
private void addNode(String str)
{
// Sessions are lightweight and disposable connection wrappers.
try (Session session = driver.session())
{
// Wrapping Cypher in an explicit transaction provides atomicity
// and makes handling errors much easier.
try (Transaction tx = session.beginTransaction())
{
tx.run(str);
//tx.run("MERGE (n:" + NodeName + " {lnk: {x}})", parameters("x", str));
//tx.run("MERGE (a:PAGE {doc: {x}})", parameters("x", name));
tx.success(); // Mark this write as successful.
}
}
}
private void addRelation(String x)
{
// Sessions are lightweight and disposable connection wrappers.
try (Session session = driver.session())
{
// Wrapping Cypher in an explicit transaction provides atomicity
// and makes handling errors much easier.
try (Transaction tx = session.beginTransaction())
{
tx.run(x);
//MATCH (a:Person),(b:Person)
//WHERE a.name = 'A' AND b.name = 'B'
//CREATE (a)-[r:RELTYPE]->(b)
//RETURN type(r)
//tx.run(" MATCH (a:" + NodeName + "),(b:" + NodeName + ") WHERE a.x ='" + A + "' AND b.x ='" + B + "' CREATE (a)-[r:RELTYPE]->(b) RETURN type(r)", parameters("x", x,"A",A,"B",B));
tx.success(); // Mark this write as successful.
}
}
}
private void printNode(String initial)
{
try (Session session = driver.session())
{
// Auto-commit transactions are a quick and easy way to wrap a read.
StatementResult result = session.run(
"MATCH (n:Person) WHERE n.name STARTS WITH {x} RETURN n.name AS name",
parameters("x", initial));
// Each Cypher execution returns a stream of records.
while (result.hasNext())
{
Record record = result.next();
// Values can be extracted from a record by index or name.
System.out.println(record.get("name").asString());
}
}
}
public void close()
{
// Closing a driver immediately shuts down all open connections.
driver.close();
}
//___________________________________________________________________________
private void readFile(String fn) throws Exception{
FileReader fr=new FileReader(fn);
int i;
while((i=fr.read())!=-1)
System.out.print((char)i);
fr.close();
}
public static void main(String... args) throws IOException {
int ch,i,k,rec_enum=0,fld_enum=0,cur_line=0,x=1,y=1,properties=0,nodes=0;
String st="",str="",name="",fld="",line_str="";
Neo4jTest example = new Neo4jTest("bolt://localhost:7687", "neo4j", "admin");
//example.set_NodeName("NEO4J");
//example.headers= new String[20];
//example.nodeIDs= new String[20];
System.out.println("Nodes Cleared Successfully.");
example.clearNodes();
System.out.println("Importing persons.csv Successfully.");
example.importCSV("persons.csv");
FileReader fr=new FileReader("names.csv");
System.out.println("CALCULATING Headers & Nodes nemes.csv by JAVA FileReader ...");
str="";
while((ch=fr.read())!=-1) {
if (ch ==(int)',' || ch==13 || ch==10) {
if (ch==13 || ch==10) {
if (ch == 13) ch = fr.read();
rec_enum++;
nodes++;
properties=fld_enum;
fld_enum=0;
}else{
fld_enum++;
}
}
}
fr.close();
System.out.println("Nodes:"+String.valueOf(nodes-1)+",Headers:"+String.valueOf(properties+1));
example.set_NodeName("soheil");
properties++;
nodes--;
example.headers= new String[properties+1];
example.nodeIDs= new String[nodes+1];
fr=new FileReader("names.csv");
System.out.println("MERGING names.csv by JAVA FileReader ...");
str="MERGE (n:"+ example.NodeName + " {";
fld_enum=0;
rec_enum=0;
while((ch=fr.read())!=-1) {
if (ch ==(int)',' || ch==13 || ch==10) {
fld = st;
st = "";
//
if(rec_enum==0){
example.headers[fld_enum]=fld;
}
if(fld_enum==0){
name=fld;
if(rec_enum>0){
example.nodeIDs[rec_enum]=name;
}
}
//
if (ch==13 || ch==10) {
if (ch == 13) ch = fr.read();
if(cur_line>0){
//CREATE (p:Person { id: toInteger(csvLine.id), name: csvLine.name });");
str=str + example.headers[fld_enum] + ":'" + fld +"'";
}
rec_enum++;
fld_enum=0;
str = str+"});";
}else{
if(cur_line>0){
//CREATE (p:Person { id: toInteger(csvLine.id), name: csvLine.name });");
str=str + example.headers[fld_enum] + ":'" + fld +"'";
}
//
str = str + ",";
line_str = line_str + ",";
fld_enum++;
}
//
if (rec_enum!=cur_line){
if(cur_line>0){
System.out.println(String.valueOf(cur_line)+":name("+name+")->"+line_str);
//example.addNode(name);
line_str="";
example.addNode(str);
}else{
System.out.println("HEADERS:"+line_str);
}
cur_line=rec_enum;
line_str="";
//str="";
str="MERGE (n:"+ example.NodeName + " {";
//st="";
//fld="";
//name="";
}
}else{
st = st + (char)ch;
line_str = line_str + (char)ch;
}
}
fr.close();
System.out.println("PRINTING nodeIDs names.csv ...");
for(i=1;i<rec_enum;++i){
System.out.println(String.valueOf(i)+":"+example.nodeIDs[i]);
}
fr=new FileReader("relations.csv");
System.out.println("CREATING RELATION relations.csv by JAVA FileReader ...");
st="";
line_str="";
//
while((ch=fr.read())!=-1) {
if (ch ==(int)',' || ch==13 || ch==10) {
k=Integer.parseInt(st);
str="("+String.valueOf(y)+","+String.valueOf(x)+")"+example.nodeIDs[y]+"->"+example.nodeIDs[x]+":"+String.valueOf(k);
System.out.println(str);
st="";
if(k==1){
line_str=" MATCH (a:" + example.NodeName + "),(b:" + example.NodeName + ") WHERE a."+example.headers[0]+" ='" + example.nodeIDs[y] + "' AND b."+example.headers[0]+" ='" + example.nodeIDs[x] + "' CREATE (a)-[r:RELTYPE]->(b) RETURN type(r)";
example.addRelation(line_str);
}
//
if (ch==13 || ch==10) {
if (ch == 13) ch = fr.read();
y++;
x=1;
}else{
x++;
}
}else{
st = st + (char)ch;
}
}
fr.close();
System.out.println("Finding Node Match(name='M') ...");
example.printNode("M");
example.close();
System.out.println("TEST Complete Successfully.");
}
//MATCH (n) DETACH DELETE n;
}
6– منابع
https://github.com/neo4j-contrib/graphgist/wiki
https://github.com/neo4j/neo4j-java-driver
https://neo4j.com/developer/get-started/
https://neo4j.com/docs/developer-manual/preview/drivers/
https://neo4j.com/docs/api/java-driver/1.7-preview/
http://boopathi.me/blog/category/neo4j/
http://p30download.com/fa/entry/52861/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 2469
نوشته های مرتبط








همچنین ببینید

25 فیلم سینمایی برتر با موضوع داده کاوی، هوش مصنوعی و فضای سایبر (با دوبله فارسی)
امروزه یکی از سرگرمیهای جذاب بشر تماشا کردن فیلم های سینمایی است. ولی انتخاب هدفمند …
مکانیک خاک به زبان ساده
عناوين مطالب: 'تعریف و اهمیت مکانیک خاکترکیب و خصوصیات خاکروابط وزنی-حجمی خاکدانهبندی و طبقهبندی خاکخصوصیات …
تحلیل احساس و نظرکاوی متون فارسی با یادگیری ماشین و شبکه های عصبی کانولوشنال
داده های متنی یکی از پرمصرف ترینها است که میتواند برای بدست آوردن اطلاعات مهم …
