 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
روش تحلیل و پردازش گراف های بزرگ
در قسمت های پیشین با تئوری گراف و تئوری شبکه اجتماعی آشنا شدیم. در این قسمت به روشهای معمول که در پردازش گراف های بزرگ مورد استفاده قرار میگیرد میپردازیم. این موارد را برای این بررسی میکنیم تا در زمان بررسی ابزار ها و فناوری های پردازش گراف های بزرگ مانند گرافچی و تایتان با ادبیات موضوع آشنا باشیم. سه رویکرد مهم در تحلیل و پردازش گراف های بزرگ عبارتند از:
- روش پردازش گراف Vertex-Centrice (راس محور)
- روش برنامه نویسی MapReduce (نگاشت/ کاهش)
- روش حافظه اشتراکی
لازم به ذکر است که ابزار های یا تکنولوژی های تحلیل گراف ممکن است یک یا بیش از یکی از این روش ها را همزمان برای پردازش گراف های بزرگ استفاده کنند.
روش پردازش گراف Vertex-Centrice (راس محور)
نام دیگر این رویکرد Pregel است که توسط گوگل ارائه شده است. و از مدل برنامه نویسی Bulk Synchronous Parallel الگو گرفته شده است. این روش با انجام گام هایی از فعالیت های تکراری بر روی گره های گراف انجام میشود که هر گام به عنوان Superstep شناخته میشود. این گام ها برای هر نود تا زمانی ادامه مییابد تا آن گره به هدف رسیده و غیر فعال شود.
روش عملکرد به این صورت است که در ابتدا تابعی توسط کاربر تعریف شده و در هر گام بر روی نود های گراف اجرا میشود و نتیجه رفتار آن گره ها بعد از اعمال تابع بدست می آید. این گام ها برای هر نود تا زمانی ادامه مییابد تا آن گره به هدف تابع تعریف شده توسط کاربر رسیده باشد و غیر فعال شود. به عبارتی گره های فعال زمانی غیر فعال میشوند که به هدف رسیده باشند و دیگر از سایر گره های پیامی دریف نکنند (ممکن است گره ای که در یک گام غیر فعال بوده دوباره در گام های بعد با دریافت پیام فعال شود). بعد از اعمال تایع بر روی گره نتیجه ی آن در گام بعدی به گره های اطراف یا هر گره دیگری که مشخص شده باشد ارسال میشود. گره ها با حرف V و گام ها با حرف S مشخص میشوند. رفتار گره V در گام S مشخص است. نتیجه اعمال تابع در گام S-1 گرفته شده و به عنوان ورودی به تابع در گام S تحویل و اعمال می شود و سپس بعد از اجرای گام فعلی، نتیجه اجرای تابع به گام S+1 برای تکرار بعدی ارسال میگردد. کار پردازش زمانی تمام است که تمامی گره های غیر فعال شده باشند یا به عبارتی دیگر همه گره ها به هدف رسیده باشند. برنامه های مانند Graphchi و GraphLab با مدل Vetrex-Centric نوشته شده اند.
به عنوان مثال میخواهیم با این روش در گراف زیر بزرگترین مقدار گره را در کل گراف تشخیص دهیم. هر گره با توجه به جهت گراف مقدار خود را به گره کناری جهت مقایسه مقادیر ارسال میکند. هر گره ای که مقدار آن از مقدار دریافت شده کوچکتر باشد مقدار خود را با مقدار بزرگتر جایگزین میکند و هر گره ای که مقدار دریافتی از گره کناری از مقدار خود کمتر باشد غیر فعال میگردد. این عمل انقدر تکرار میشود که تمامی گره های غیر فعال شده باشند. یا به عبارتی تمامی گره بزرگترین مقدار را نشان دهند. به این ترتیب بزرگترین مقدار کشف میشود. شکل زیر به سادگی این مراحل را نشان می دهد. از نوع روش نوضیح داده شده مشخص است که این کار را میتوان به سرعت خیلی زیاد و به طور موازی انجام داد.
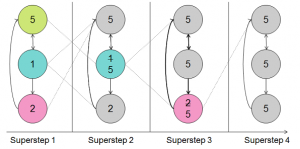
http://backstopmedia.booktype.pro/big-data-dictionary/pregel/
روش برنامه نویسی MapReduce (نگاشت/ کاهش)
ار دیگر روش های پردازش گراف های بزرگ مپ ردیوس است. توسط چارچوب محاسباتی MapReduce میتوان حجم عظیمی از داده ها را بصورت توزیع شده و موازی پردازش کرد. MapReduce، مدل برنامه نویسی جهت پردازش و تولید مجموعه های داده های عظیم است. در محاسبه، مجموعه ای از جفت های کلید/مقدار ورودی، دریافت و مجموعه ای از جفت های کلید/مقدار خروجی، تولید میشود. توسعه دهنده توسط مدل برنامه نویسی نگاشت/کاهش، محاسبه موردنظر خود را میتواند به عنوان دو تابع نگاشت و کاهش بیان کند. تابع نگاشت که توسط کاربر نوشته میشود، یک جفت ورودی میگیرد و مجموعه ای از جفت های کلید/مقدار میانی را تولید میکند. کتابخانه نگاشت/کاهش، تمام مقادیر میانی مرتبط با همان کلید میانی I را با هم گروه بندی میکند و آنها را به تابع کاهش می سپارد. تابع کاهش نیز توسط کاربر نوشته میشود و یک کلید میانی I و مجموعه ای از مقادیر برای آن کلید را می پذیرد. این تابع سپس این مقادیر را با هم ادغام میکند تا مجموعه ای از مقادیر کوچکتر را تشکیل دهد. معمولا فقط صفر یا یک مقدار خروجی در هر فراخوانی نگاشت ایجاد میشود.
مپ-رديوس يا نگاشت-کاهش، يک چارچوبي براي نوشتن برنامه هايي است که نياز به پردازش بر روي داده هاي بسيار زيادي (چندين ترابايت از مجموعه داده ها) دارند بطوريکه اين پردازش ها بصورت موزاي با قابليت اعتماد و تحمل پذيري بالا روي خوشههايي با سخت افزارهاي معمولي اجرا شوند. عملکرد در مپ-رديوس شبيه سيستم خط لولهاي (pipeline) يونيکس است.
UNIX pipeline: cat input | grep | sort | uniq –c | cat > output
MapRedue: Input | Map |Shuffle & Sort | Reduce | Output
در مپ-رديوس معمولاً داده هاي ورودي به تکه هاي مستقلي تقسيم ميشوند. اين تکه ها توسط گره هاي نگاشت بصورت کاملاً موازي پردازش ميشود. سپس خروجي نتايج نگاشتها به عنوان ورودي به گره هاي کاهنده داده ميشود(خروجي نتايج مپ ممکن است برحسب نياز مرتب شوند). وروديها و خروجيهاي مراحل نگاشت-کاهش، به فرمت «کليد، مقدار» هستند. چارچوب مپ-رديوس مسئول زمانبندي وظيفه ها، مانيتور کردن آنها و اجراي دوباره وظيفه هاي شکست خورده است. مدل محاسباتي مپ-رديوس در شکل زیر نمايش داده شده است.
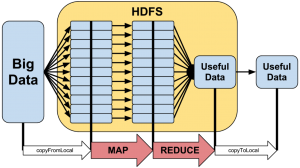
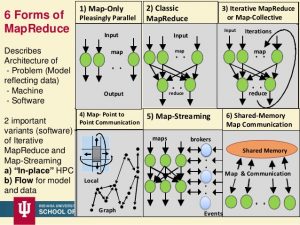
مپ-رديوس شامل يک JobTracker رئيس و چندين TaskTracker مرئوس است. هر کار جديدي که ايجاد ميشود يک JobTracker آن کار را به چندين TaskTracker ميشکند. هر TaskTracker بر روي يک ماشين مجزا اجرا ميشود. هر TaskTracker قسمتي از کار را انجام ميدهد و JobTracker مسئول زمانبندي و تقسيم وظايف است. در صورتيکه يک TaskTracker با خطا مواجه شد، توسط JobTracker يک TaskTracker ديگر آن وظيفه را دوباره اجرا ميکند. شماي کلي JobTracker و TaskTracker در شکل زیر آمده است. در زیر انواع نگاشت کاهش نمایش داده شده است.
روش حافظه اشتراکی
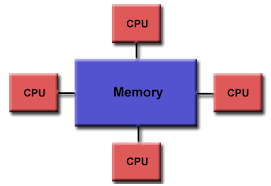
در این روش گراف بزرگ توسط سیستم های پردازشی به اشتراک گذاشته می شود تا پروسه های بر روی ماشین های پردازشی مختلف به بخش های مورد نیاز خود از گراف بزرگ دسترسی پیدا کنند تا عملیات مورد نیاز را بر روی گراف انجام دهند ویا داده ها را ویرایش کنند. در این روش ممکن است در عمل حافظه RAM استفاده نشود و در عوض بخشی از فضای دیسک را به نحوی پیکربندی کرد که رفتار حافظه RAM را از خود نشان دهد(RAM Disk). این روش پردازش به غیر از حوزه گراف در موارد دیگر نیز کاربرد دارد. فقط نکته مهم آن است که پردازه ها باید بلد باشند که داده های متناسب با نیاز خود را از حافظه واکشی کنند. این روش شاید مقیاس پذیری و انعطاف مطلوب برای افزایش ماشین های پردازشی را نداشته باشد.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 27742
برچسبMapReduce shared Memory Vertex Centrice پردازش گراف پردازش گراف های بزرگ تحلیل گراف توزیع شده حافظه اشتراکی راس محور روش تحلیل گراف های بزرگ گراف های بزرگ مپ ردیوس نگاشت کاهش
نوشته های مرتبط











همچنین ببینید

تحلیل گراف های بزرگ با آپاچی فلینک (Apache Flink)
تعریف جریان داده: جریان داده ها، داده هایی هستندکه بطور مداوم توسط هزاران منبع داده …

آموزش کامل نت ماینر (NetMiner) همراه با مثال
فهرست مطالب آمورش NetMiner تهیه کننده: حمید غلامی 1-مقدمه NetMiner چیست سیستم مورد نیاز درباره …
