 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
داده کاوی در بستر تکنولوژی Microsoft SQL Server
عناوين مطالب: '
مراحل داده کاوی در Microsoft
قبل از بررسی امکانات داده کاوی در SQL Server، نگاه اجمالی به نگرش شرکت میکروسافت در این مقوله می پردازیم. داده کاوی غالباً به عنوان فرآیند استخراج اطلاعات، الگوها و روندهای موجود در مجموعه ی داده های حجیم یاد می شود. این الگوها و روندها را می توان به عنوان یک مدل کاوشی تعریف نمود. به بیانی دیگر ایجاد یک مدل کاوشی بخشی از فرآیند بزرگتری است که در برگیرنده ی همه مراحل؛ از تعریف مسئله که مدل حل خواهد نمود تا اجرای مدل در محیطهای کاری است. می توان این فرآیند را با استفاده از 6 مرحله اساسی زیر تعریف نمود:
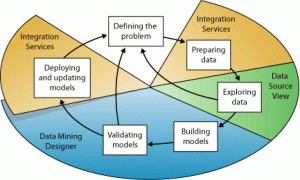
باید در نظر داشت که تهیه یک مدل داده کاوی، فرآیندی چرخشی، پویا و تکرار پذیر می باشد و ممکن است هر یک از این مراحل آن قدر تکرار شود، تا مدل مناسبی تهیه گردد.
- تعریف مسئله (Defining the Problem):
تعریف روشنی از مشکل و مسئله کسب و کار است. این مرحله شامل تجزیه و تحلیل نیازمندیهای کسب وکار، تعریف دامنه مشکل، تعریف معیارهایی که با آن مدلها ارزیابی خواهد شد و تعریف هدف نهایی پروژه ی داده کاوی است.
- آماده سازی دادهها (Preparing Data):
یکپارچه سازی و پالایش داده هایی است که در مرحله ی تعریف مسئله فرآیند معین شده است. SSIS حاوی تمامی ابزارهای ملزوم برای تکمیل این مرحله میباشد.
- بررسی دادهها (Exploring Data):
به منظور تصمیم گیریهای مناسب در هنگام تهیه مدل، می بایست دادهها را درک نمود و پس از آن می توان تصمیم گیری در مورد وجود دادههای مخدوش در مجموعه داده و در نهایت استراتژی مناسب برای رفع این مشکلات اتخاذ نمود. Data Source view Designer موجود در BIDS حاوی ابزارهای جامعی برای بررسی و شناخت دادهها شامل محاسبه ارقام حداقل و حداکثر، محاسبه میانگین و انحراف معیار و بررسی توزیع دادهها می باشد.
- تهیه مدل ها (Building Models):
پیش از تهیه مدل باید، دادهها را به دو دسته ی دادههای آموزشی و اعتبارسنجی (آزمایشی) تقسیم نمود. از دادههای آموزشی برای تهیه مدل و از دادههای اعتبارسنجی برای آزمایش صحت مدل با ایجاد سوالاتی در مورد صحت پیش بینیها استفاده نمود. پس از تعریف ساختار کاوشی، می بایست به پردازش مدل پرداخته شود و ساختارهای خالی با الگوهایی که مدل را توصیف می نمایند، پُر شوند. این مرحله با عنوان آموزش مدل شناخته می شود.
- بررسی و ارزیابی مدلها (Exploring and Validating Models):
این مرحله شامل بررسی مدلهای ایجاد شده به منظور آزمودن کارایی آنهاست. می توان مدلها را با ابزارهای موجود در Designer از جمله نمودار صعود و یا ماتریس دسته بندی بررسی نمود.
- اجرا و بروزرسانی مدلها (Deploying and Updating Models):
این مرحله شامل اجرای مدل هایی است که بهترین کارائی را در یک محیط عملیاتی داشته اند. پس از استقرار مدلهای کاوشی در یک محیط عملیاتی می توان از این مدلها برای پیش بینی هایی بهره گرفت.
داده کاوی در SQL Server
SQL Server عمدتاً به عنوان ابزار ذخیره سازی در بسیاری از سازمان ها مورد استفاده قرار می گیرد. با این حال ، با افزایش نیازهای بسیاری از مشاغل ، مردم به دنبال ویژگی های مختلف سرور SQL هستند. مردم به دنبال ذخیره سازی داده ها با SQL Server هستند. SQL Server در حال تهیه یک بستر داده کاوی است که می تواند برای پیش بینی داده ها مورد استفاده قرار گیرد.
SQL Server با ارائه داده کاوی در خدمات تجزیه و تحلیل ، از زمان انتشار نسخه 2000 پیشرو در تحلیل های پیش بینی کننده بوده است. ترکیبی از سرویس های یکپارچه سازی ، خدمات گزارشگری و SQL Server Data Mining یک بستر یکپارچه برای تجزیه و تحلیل پیش بینی فراهم می کند که شامل پاکسازی و آماده سازی داده ها ، یادگیری ماشین و گزارش است. SQL Server Data Mining شامل چندین الگوریتم استاندارد ، از جمله مدل های خوشه بندی EM و K-means ، شبکه های عصبی ، رگرسیون لجستیک و رگرسیون خطی ، درختان تصمیم گیری و طبقه بندی های خلیج ساده و ساده است. همه مدل ها دارای تجسم یکپارچه برای کمک به شما در توسعه ، اصلاح و ارزیابی مدل های شما هستند. ادغام داده کاوی در راه حل هوش تجاری به شما کمک می کند تا در مورد مشکلات پیچیده تصمیم هوشمندانه بگیرید.
ویژگی های کلیدی داده کاوی SQL Server
SQL Server Data Mining ویژگی های زیر را برای پشتیبانی از راه حل های داده کاوی یکپارچه فراهم می کند:
چندین منبع داده: برای داده کاوی می توانید از هر منبع داده جدولی استفاده کنید ، از جمله صفحات گسترده و پرونده های متنی. شما همچنین می توانید مکعب های OLAP ایجاد شده در Analysis Services را به راحتی استخراج کنید. با این حال ، شما نمی توانید از داده های یک پایگاه داده در حافظه استفاده کنید.
پاکسازی یکپارچه داده ، مدیریت داده و گزارش دهی: خدمات یکپارچه سازی ابزاری را برای پروفایل و پاکسازی داده ها فراهم می کند. شما می توانید فرآیندهای ETL را برای تمیز کردن داده ها در مرحله آماده سازی برای مدل سازی بسازید ، و ssISnoversion همچنین باعث می شود که مدل ها مجدداً به روز شود و به روز شود.
چند الگوریتم قابل تنظیم: علاوه بر ارائه الگوریتم هایی مانند خوشه بندی ، شبکه های عصبی و درختان تصمیم گیری ، SQL Server Data Mining از توسعه الگوریتم های پلاگین سفارشی خود پشتیبانی می کند.
زیرساخت آزمایش مدل: مدلها و مجموعه داده های خود را با استفاده از ابزارهای مهم آماری به عنوان اعتبار سنجی متقابل ، ماتریس های طبقه بندی ، نمودارهای بلند کردن و نمودارهای پراکنده آزمایش کنید. به راحتی مجموعه های آزمایش و آموزش را ایجاد و مدیریت کنید.
ابزارهای مشتری: علاوه بر استودیوهای توسعه و طراحی که توسط SQL Server ارائه شده است ، می توانید از افزودنیهای داده کاوی برای اکسل برای ایجاد ، پرس و جو و مرور مدل ها استفاده کنید. یا مشتری های سفارشی از جمله سرویس های وب ایجاد کنید.
پشتیبانی از زبان نوشتاری و API مدیریت شده: همه اشیا data داده کاوی کاملاً قابل برنامه ریزی هستند. برنامه نویسی از طریق MDX ، XMLA یا پسوند PowerShell برای خدمات آنالیز امکان پذیر است. برای پرس و جو سریع و اسکریپت نویسی از زبان Data Mining Extensions (DMX) استفاده کنید.
امنیت و استقرار: امنیت مبتنی بر نقش را از طریق خدمات تجزیه و تحلیل ، از جمله مجوزهای مجزا برای دستیابی به موفقیت در مدل سازی و ساختاری ، فراهم می کند. استقرار آسان مدلها به سرورهای دیگر ، به گونه ای که کاربران بتوانند به الگوهای دسترسی پیدا کنند یا پیش بینی ها را انجام دهند.
وظایف حل مشکلات تجاری در SQL Server
چند وظیفه وجود دارد که برای حل مشکلات تجاری استفاده می شود. این وظایف عبارتند از طبقه بندی ، برآورد ، خوشه ، پیش بینی ، ترتیب ، و همکار. SQL Server Data Mining دارای نه الگوریتم داده کاوی است که می تواند برای حل مشکلات تجاری فوق الذکر استفاده شود. در زیر لیستی از الگوریتم هایی وجود دارد که در مشکلات مختلف طبقه بندی شده اند.
طبقه بندی: بسته به ویژگی های مختلف طبقه بندی می شود. به عنوان مثال ، اینکه مشتری بسته به داده های دیگر مانند سن ، جنس ، وضعیت تأهل ، شغل ، تحصیلات واجد شرایط و غیره ، مشتری آینده نگر باشد.
برآورد: تخمین با استفاده از پارامترها انجام می شود. به عنوان مثال ، قیمت خانه بسته به موقعیت خانه ، اندازه خانه و غیره پیش بینی می شود.
خوشه: همچنین به عنوان تقسیم بندی نامگذاری شده است. بسته به ویژگی های مختلف گروه بندی طبیعی انجام می شود. تقسیم بندی مشتری مثال تجاری کلاسیک برای خوشه بندی است.
پیش بینی: پیش بینی متغیر مداوم برای زمان. پیش بینی میزان فروش برای چند سال آینده یک سناریوی بسیار معمول در صنعت است.
همکار: یافتن موارد یا گروه های مشترک در یک معامله. معامله می تواند یک سوپرمارکت فروشی یا دارو یا فروش آنلاین باشد.
منبع:
https://researchyar.ir/sql-server/
.https://www.dotnettips.info/courses/topic/15/c1cc7b1e-30bd-4060-9cbc-bb07be89e3da
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 633
برچسبSSAS دادکاوی داده کاوی در SQL Server
نوشته های مرتبط







همچنین ببینید
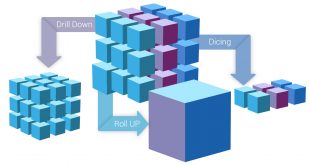
همه چيز درمورد مکعب داده (Data Cube) و OLAP با مثال عملي
مکعب داده يا OLAP چيست؟ نوع پایگاه داده ای که تراکنش ها را ذخیره می …
