خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
پایگاه داده Nebula Graph برای گراف های بزرگ
پایگاه داده Nebula Graph یک دیتا بیس مبتنی بر گراف است که میتواندصدها میلیارد رأس و تریلیون ها یال را میزبانی کند و پرس و جوهایی را با تأخیر میلی ثانیه ارائه دهد. با این فناوری امکان پردازش گراف به صورت ابری فراهم است. دیتا بیس Nebula Graph یک پایگاه داده گراف منبع باز، توزیع شده، به راحتی مقیاس پذیر و native است. شرکت Vesoft، سازنده Nebula Graph، در رتبه هشتم، قبل از Bytedance مادر TikTok، و تنها یک جایگاه پس از هواوی قرار دارد.
عناوين مطالب: '
هسته پایگاه داده Nebula Graph
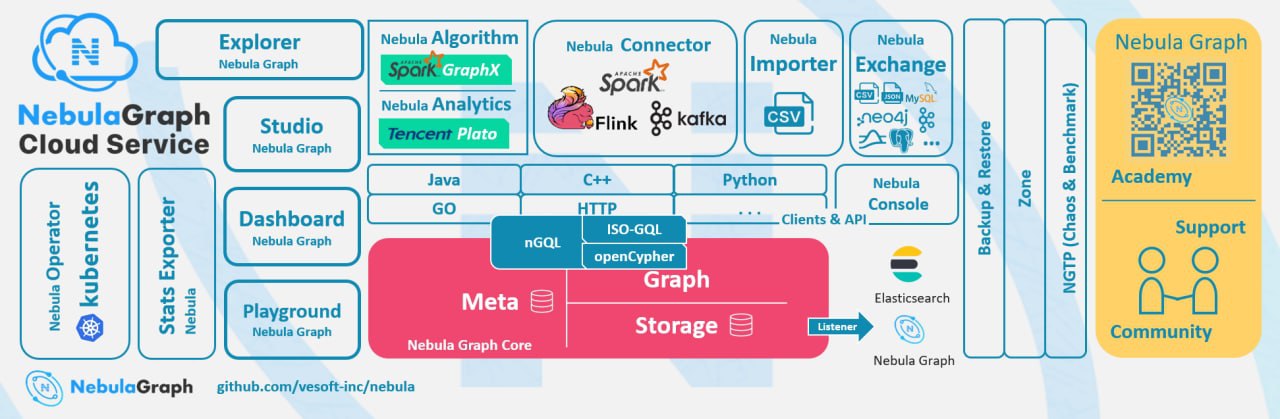
شکل بالا اکوسیستم ساخته شده در اطراف Nebula Graph را نشان می دهد. بخش با پسزمینه قرمز، هسته Nebula Graphاست که از سه بخش متا، نمودار و ذخیرهسازی تشکیل شده است.
زبان پرس و جو Nebula Graph
زبان پرس و جو nGQL است که با openCypher نیز سازگار است. ما همچنین کلاینت هایی را به زبان هایی از جمله جاوا، C++، Python و Go توسعه داده ایم. سپس در بالا تعدادی SDK داریم که می توانند با فریم ورک هایی مانند Spark، Flink، GraphX، Tencent Plato کار کنند.
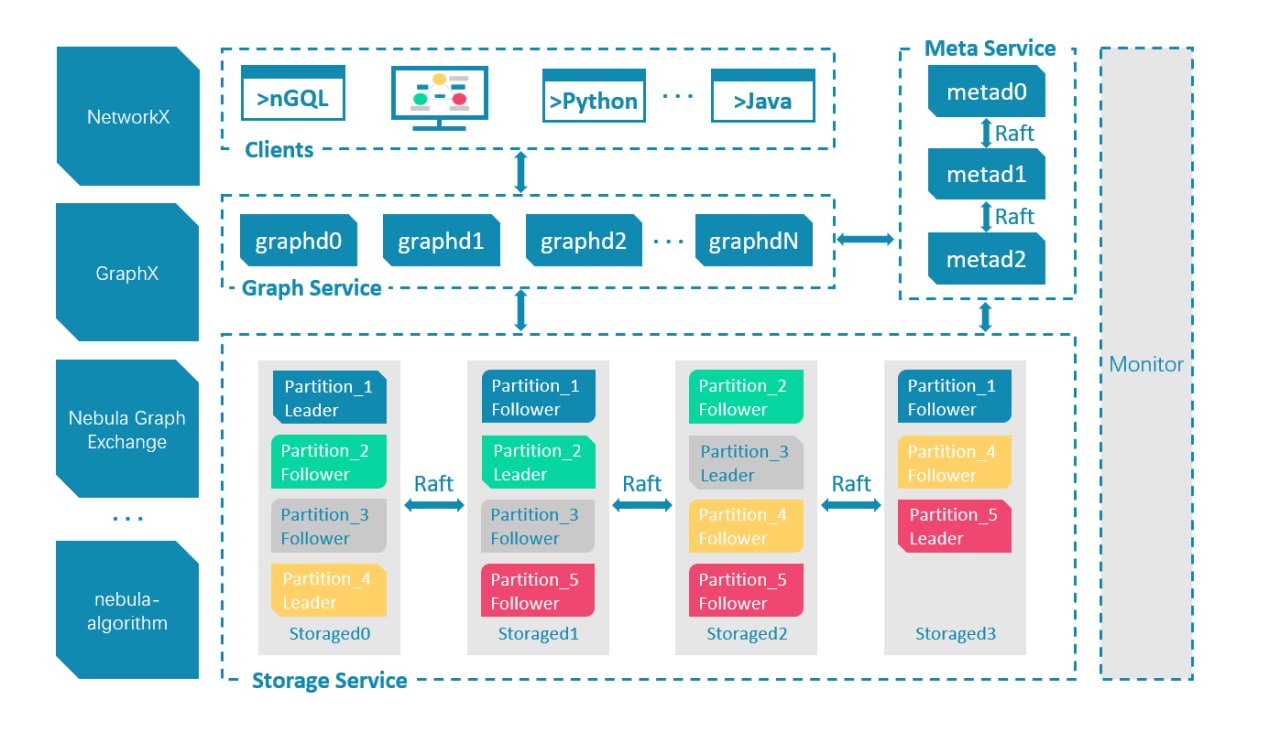
معماری Nebula Graph
?پایگاه داده Nebula Graph از سه سرویس تشکیل شده است:
سرویس های Graph Service، Storage Service و Meta Service. این جداسازی معماری ذخیره سازی و محاسباتی را اعمال می کند.
?هر سرویس دارای فایل باینری اجرایی خاص خود است. این فایل باجرایی میتوانند بر روی یک مجموعه میزبان یا بر روی میزبانهای مختلف مستقر شوند.
شکل بالا معماری یک خوشه Nebula Graph معمولی را نشان می دهد.
?سرویس Meta با ابرداده سروکار دارد، در حالی که سرویس Storage، داده ها را ذخیره می کند و سرویس Graph وظیفه پرس و جو را بر عهده دارد.
?این سه ماژول بر روی فرآیندهای مستقل خود اجرا می شوند و از جداسازی محاسبات و ذخیره سازی اطمینان حاصل می کنند.
معماری Nebula Graph
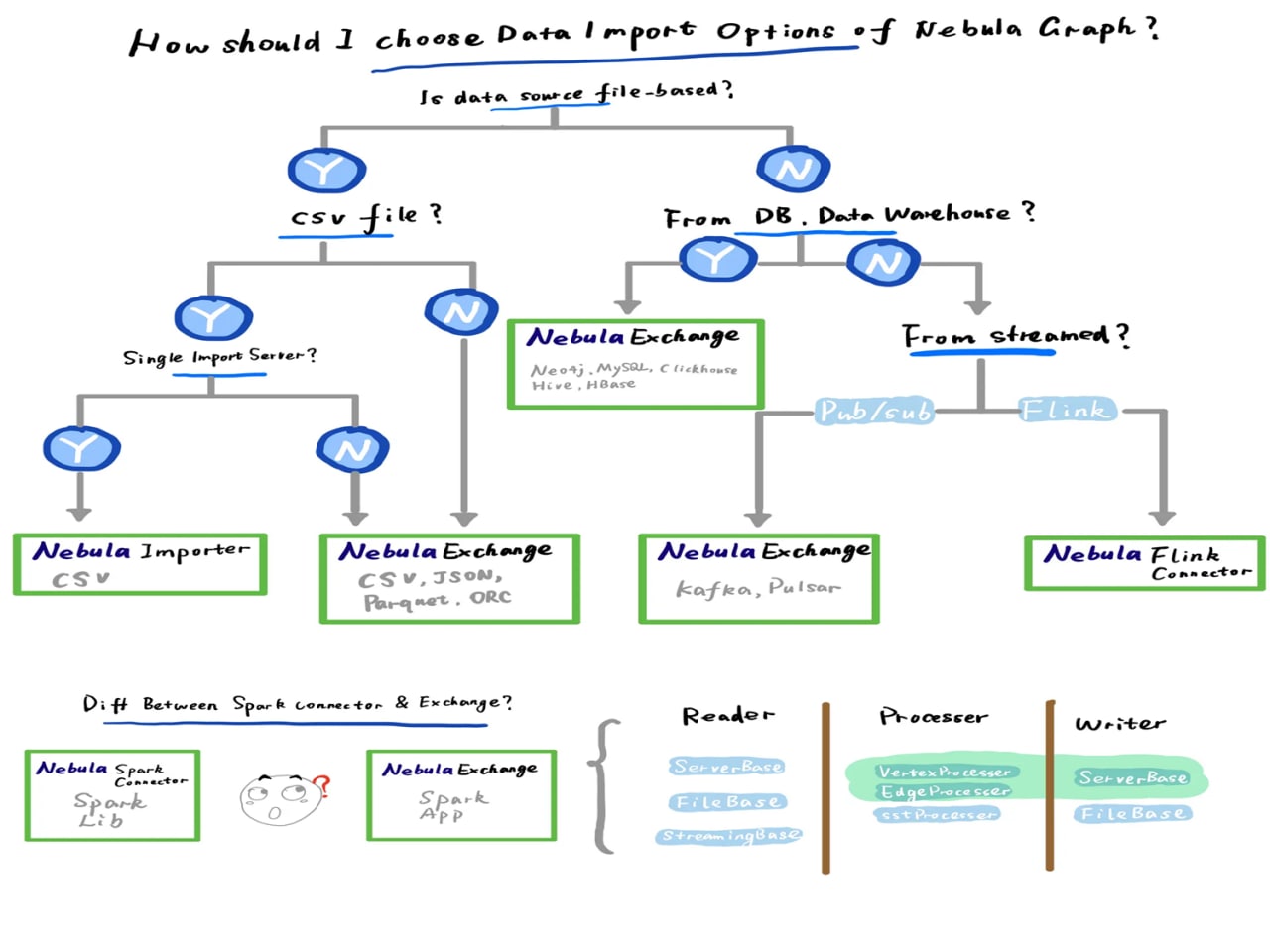
انواع روش های ورود داده پایگاه داده Nebula Graph
?دیتابس Nebula Graph از ElasticSearch برای نمایه متن کامل استفاده می کند. از Nebula Graph v2.x، عملکرد نوشتن قابلیت نمایه سازی Nebula را بهینه کرده است.
از نسخه 2.5.0، Nebula Graph شروع به پشتیبانی از ترکیب TTL انقضای داده و نمایه سازی کرده است. و از نسخه 2.6.0، Nebula Graph شروع به پشتیبانی از عملکرد TOSS (Transaction on Storage) برای دستیابی به سازگاری نهایی لبه ها کرد.
به این معنا که لبه ها یا با موفقیت نوشته می شوند یا در همان زمان با درج یا اصلاح شکست می خورند.
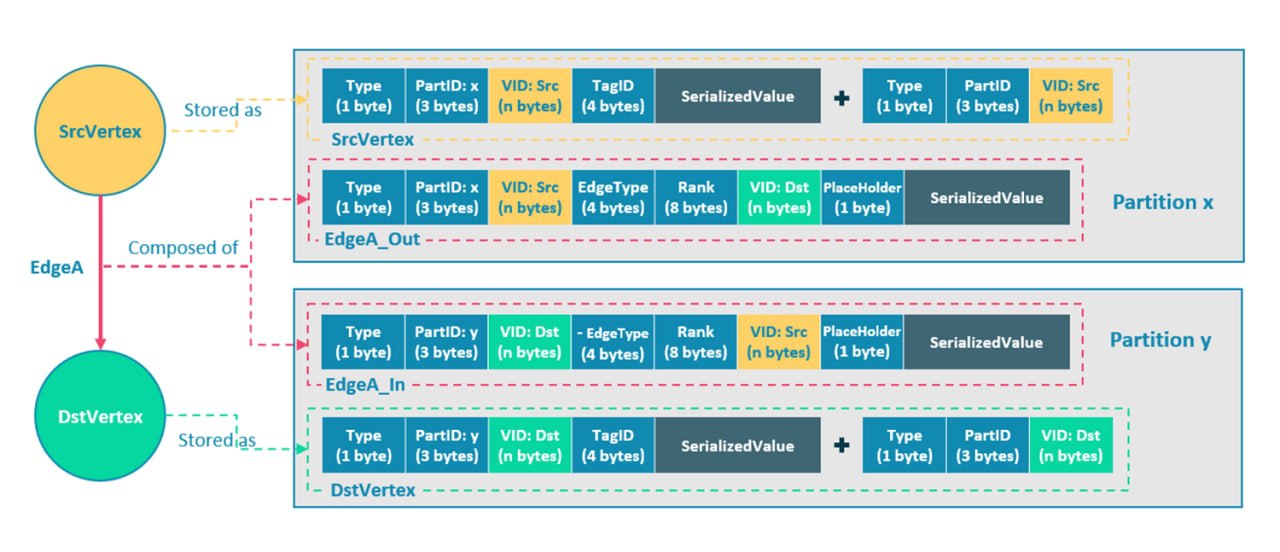
مدل داده در Nebula Graph
?پایگاه داده Nebula Graph میتواند دادههایی را با تریلیونها راس و یال مدیریت کند. این بدان معنی است که سیستم باید داده ها را در ذخیره سازی و مدیریت تقسیم بندی کند. Nebula Graph از تقسیم بندی لبه ها استفاده می کند و رئوس را در پارتیشن ها ذخیره می کند. هر پارتیشن ممکن است چند کپی داشته باشد و بر روی ماشین های مختلف اجرا شود.
?موتور پرس و جو بدون حالت است، به این معنی که تمام داده های پرس و جو باید یا از سرویس متا یا سرویس ذخیره سازی بازیابی شوند و هیچ ارتباطی بین سرویس های پرس و جو وجود ندارد.
?موارد فوق در مورد جدایی محاسبات و ذخیره سازی توسط Nebula Graph است. حالا بیایید در مورد ویژگی های داده صحبت کنیم. اشاره کردیم که Nebula Graph یک پایگاه داده بدون طرحواره نیست و تمام داده های ذخیره شده توسط زبان های تعریف داده (DDL) از پیش تعریف شده است.
رئوس با استفاده از یک 2 تایی متشکل از vid و تگ تعریف می شوند. یال ها با استفاده از یک 4 تایی متشکل از نقاط پایانی، EdgeType و رتبه تعریف می شوند.
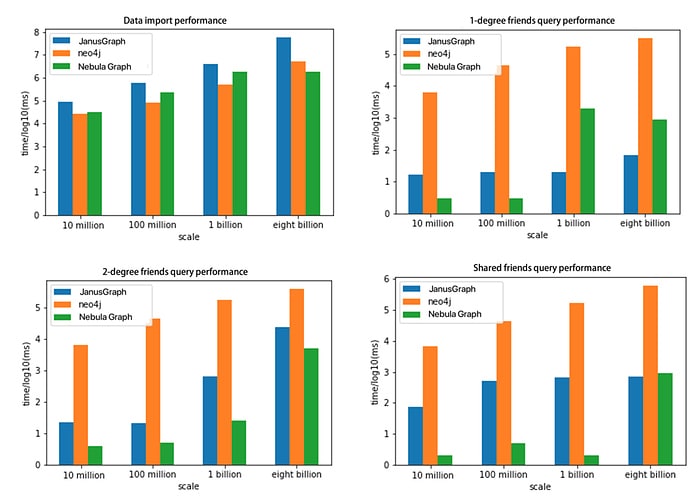
مقایسه Nebula Graph درحجم های میلیاردی
?از نظر ورود داده، Nebula Graph کمی کندتر از Neo4j است که اندازه داده کوچک است. با این حال، زمانی که اندازه داده بزرگ است، Nebula Graph بسیار سریعتر از دو مورد دیگر است. برای سه جستار نمودار، Nebula Graph عملکرد بهتری را در مقایسه با Neo4j و HugeGraph نشان می دهد.
در تصویر بالا یک نمودار کلی برای مقایسه آورده شده است:?
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 288
برچسبپایگاه داده Nebula Graph پایگاه داده مبتنی بر گراف گراف
نوشته های مرتبط








همچنین ببینید
مقایسه Neo4j با OrientDB با Titan
در رابطه با مقایسه سه پایگاه داده معروف مبنی بر گراف Neo4j و OrientDB و …