 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
دریاچه داده (Data Lake) چيست و چه تفاوتی با باتلاق داده (Data Swamp) دارد
دریاچه داده (Data Lake) و مفهوم بیگ دیتا دو واژه ناگسستنی هستند به عبارتی Data Lake ظرفی برای نگهداری بیگ دیتا یا کلان داده است که با توجه به گذر زمان ویژگیهای فنی زیادی برای آن شمارده شده است که در ادامه به آن میپردازیم. نکته ای درک آن بسیار مهم است این است که دریاچه داده به تنهایی این امکان را فراهم میکند که جایگزینی برای انبار داده و سایر اعضا همچون دیتا مارت گردد. این مفهوم غلط است که دریاچه داده تنها برای نگهداری داده های خام است. در دریاچه داده نه تنها ذخیره هر نوع داده امکان پذیر است بلکه و پردازش و داده کاوی در دریاچه داده نشانه افزایش سطح بلوغ آن بوده که در ادامه بررسی خواهد شد.
عناوين مطالب: '
دریاچه داده (Data Lake) چيست؟
یک دریاچه را در نظر بگیرید که رودخانههای مختلف به آن وارد میشوند. در واقع هر رودخانه مقداری آب در این دریاچه خواهد ریخت و آبهای موجود در این دریاچه حاصل مجموعه این رودها است. دریاچه داده یا همان Data Lake نیز به همین صورت است. یک مخزن عظیم که دادههای مختلف از طُرق متفاوت وارد این دریاچه میشوند و در آن ذخیره میگردند.
تفاوت انبارداده (Data Warehouse) و دریاچه داده (Data Lake)
دریاچه داده محلی برای نگهداری بیگ دیتا است. با بیان ساده، مفهوم دریاچه داده را میتوان اینگونه توضیح داد که اگر انبار داده را مشابه یک بطری آب تصفیهشده، بستهبندی شده و آماده مصرف در نظر بگیریم، دریاچه داده (همانند نام آن) دریاچهای است که آب از منابع مختلف ( آب باران، چشمهها، رودها یا منابع دیگر) در آن سرازیر شده و افراد میتوانند از آب دریاچه برای شنا، آشامیدن یا حتی نمونهبرداری! استفاده کنند. در یک شرکت، ما باید همیشه بر اساس داده ها تصمیم بگیریم. ما به داده های کل گروه نیاز داریم تا تصویری جامع داشته باشیم و تصمیمات تجاری درستی بگیریم، هدف حاکمیت داده از اهداف مهم دریاچه داده است.
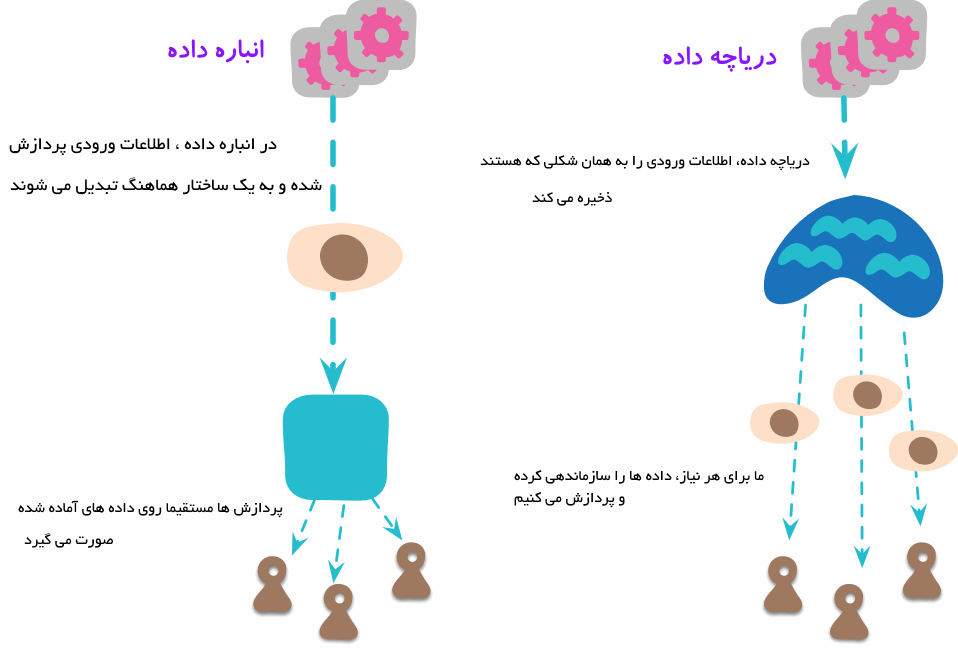
در انبارداده، دادههای ساختاریافته (Structured Data) قرار میگیرند در حالی که در دریاچه داده هر نوع دادهای (چه ساختاریافته و چه غیرساختاریافته) میتوانند در دریاچه داده یا همان Data Lake ذخیره شوند. دریاچه داده یک الگوی طراحی مبتنی بر دادههای مدرن است که برای نگهداری طیف گستردهای از انواع دادهها، اعم از قدیمی و جدید، در مقیاس وسیع کاربرد دارد. طبق تعریف، دریاچه داده به منظور ذخیره سریع دادههای خام به همراه پردازش دادهها برای اکتشاف، تجزیه و تحلیل و عملیات بهینهسازی شده است.

تفاوت انبارداده (Data Warehouse) و دریاچه داده (Data Lake)
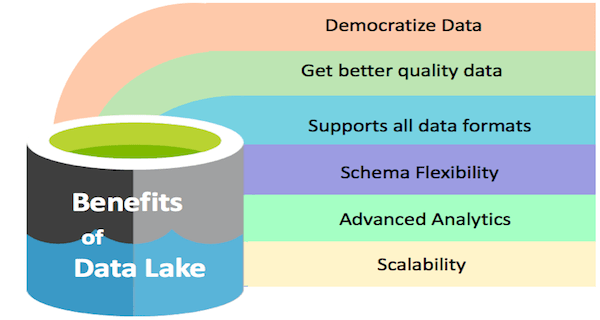
مزایای دریاچه داده (Data Lake)
دمکراتیک کردن داده ها
یک دریاچه داده می تواند داده ها را در اختیار کل سازمان قرار دهد. این همان چیزی است که ما آن را دموکراتیزاسیون داده ها می نامیم. در حال حاضر، فقط مدیران ارشد این تجمل را دارند که از بخشهای مختلف گزارش بخواهند، چیزهایی را از آنها دریافت کنند و سپس تصمیم بگیرند. سایر مزایای دریاچه داده را در شکل زیر بررسی کنید:
Ingestion Data
این مفهوم به اتصالات اجازه میدهد تا دادهها را از منابع مختلف داده دریافت کرده و در دریاچه اطلاعات بارگیری کنند. مفهوم Ingestion Data با موارد زیر سر و کار دارد:
- انواع مختلف منابع داده مانند پایگاه داده، وب سرورها، ایمیلها، اینترنت اشیا و FTP
- استفاده از دادهها به دفعات زیاد مانند مصرف دستهای یا مصرف لحظهای
- انواع داده های ساختار یافته، داده های نیمه ساختار یافته و ساختار نیافته
حاکمیت دادهها
این مفهوم برای کنترل در دسترس بودن، قابلیت استفاده، امنیت و یکپارچگی دادههای مورد استفاده در سازمان مورد استفاده قرار میگیرد.
مقیاس پذیر
ذخیره داده یک مفهوم مقیاس پذیر است. این مفهوم، با ارائه یک ذخیره سازی به صرفه، دسترسی سریع به اکتشاف داده را امکانپذیر میکند. همچنین مفهوم «ذخیره داده» باید از قالبهای مختلف داده پشتیبانی و حمایت کند.
معماری انتزاعی دریاچه داده (Data Lake) به چه صورت است؟
تصویر زیر، معماری دریاچه دادههای یک کسب و کار را نشان میدهد. سطوح پایین نشان دهنده دادههایی است که بیشتر در حالت استراحت هستند در حالی که سطوح بالاتر دادههای معاملاتی در زمان واقعی را نشان میدهند. این دادهها بدون تأخیر یا با کمی تأخیر، از طریق سیستم جریان مییابند. در ادامه طبقات مهم در معماری دریاچه داده را در نظر خواهیم داشت که عبارتند از:
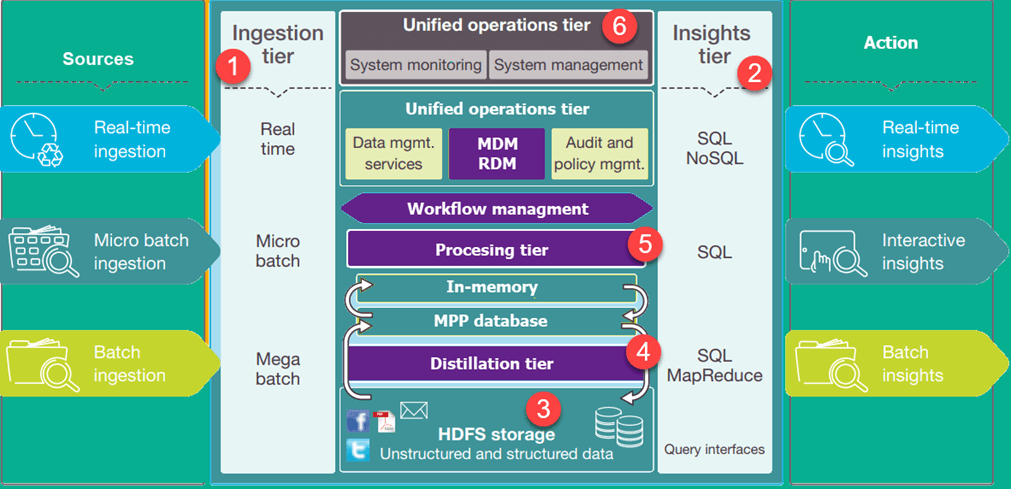
- Ingestion Tier: ردیفهای سمت چپ منابع داده را به تصویر میکشند. دادهها میتوانند به صورت دستهای یا در زمان واقعی در دریاچه داده بارگیری شوند.
- Insights Tier: طبقات سمت راست، نشان دهنده سطح تحقیق است که در آن بینش از سیستم استفاده میشود. برای تجزیه و تحلیل دادهها میتوان از SQL ،NoSQL query یا حتی excel استفاده کرد.
- HDFS: یک راهحل مقرون بهصرفه برای دادههای ساختاریافته و بدون ساختار است. این بخش، یک منطقه فرود (Landing Zone) برای تمام دادههایی است که در سیستم در حالت استراحت هستند.
- Distillation tier: دادهها را از حلقه ذخیرهسازی گرفته و برای تجزیه و تحلیل آسانتر به دادههای ساختاری تبدیل میکند.
- Processing tier: پردازش ردیف الگوریتمهای تحلیلی و پرس و جوهای کاربران با زمان واقعی متفاوت، تعاملی و دستهای برای تولید دادههای ساختار یافته به جهت تجزیه و تحلیل آسانتر.
- Unified operations tier: این ردیف عملیات واحد، حاکم بر مدیریت و نظارت بر سیستم است. این بخش شامل حسابرسی و مدیریت مهارت، مدیریت دادهها، مدیریت گردش کار میباشد.
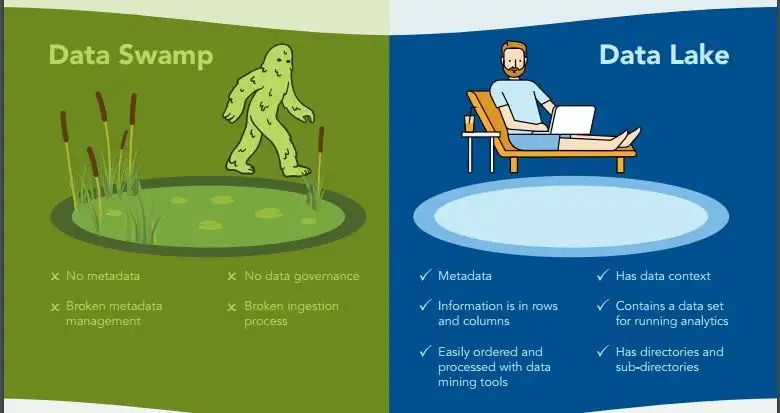
تفاوت بین دریاچه داده (Data Lake) و باتلاق داده (Data Swamp)
دلایل زیادی پشت باتلاق داده ها وجود دارد که در زیر به چند مورد اشاره می شود:
- هیچ خط مشی برای فراداده، تعریف یا فرآیند وجود ندارد
- از دست رفته چرخه حیات برای داده های موجود در دریاچه
- هیچ ذینفعی در سازمان برای داده ها وجود ندارد
- اسناد موجود در مورد فرآیند آمادهسازی/استفاده از دادهها وجود ندارد
- جزئیات حاکمیت داده تعریف نشده
شرکت های بزرگتر شروع به یافتن راه حلی برای این موضوع کرده اند. Metacat از Netflix به درک متادیتا در سرویسهای مختلف کمک میکند، یا اگر میخواهید آن را با رابط کاربری ساده نگه دارید، پورتال داده CKAN میتواند به شما در مدیریت و مدیریت دادههایتان کمک کند.
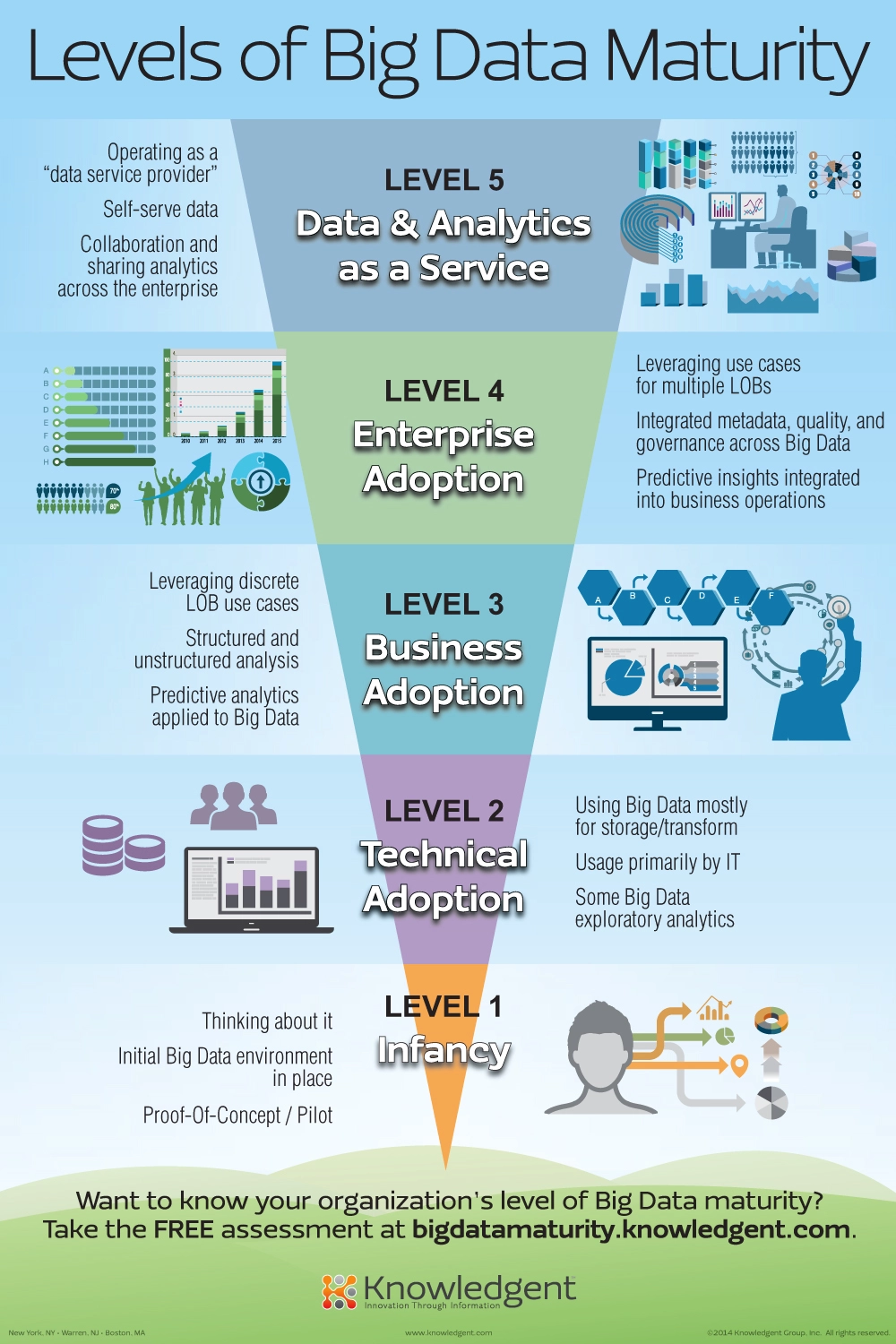
سطوح بلوغ بیگ دیتا
توسعه و اجرای استراتژی کلان داده برای سازمان ها کار آسانی نیست، به خصوص اگر فرهنگ داده محور نداشته باشند. چنین فرهنگی یک پیش نیاز برای اجرای موفقیت آمیز یک استراتژی کلان داده است و قبلاً نقشه راه Big Data را برای رسیدن به چنین فرهنگی به اشتراک گذاشته ام.
بر اساس این نقشه راه، راه درست برای شروع با Big Data این است که درک روشنی داشته باشید که چیست و چه کاری می تواند برای سازمان شما انجام دهد و از آنجا به بعد شروع به توسعه Proof of Concepts با یک تیم چند رشته ای کنید. این اولین اثبات مفاهیم برای شرکت شما و داده محور شدن حیاتی است و بنابراین باید بین همه کارکنان به اشتراک گذاشته شود. از آنجا به بعد، به آرامی می توانید داده محورتر شوید.
اینفوگرافیک زیر که توسط Knowledgent ایجاد شده است، پنج سطح بلوغ کلان داده را در یک سازمان نشان می دهد. سطح اول را مرحله نوزادی می نامند، مرحله ای که در آن فرد شروع به درک داده های بزرگ و توسعه اثبات مفاهیم می کند. سطح دومی که آنها شناسایی کرده اند، مرحله پذیرش فنی است، به این معنی که شرکت برای پیاده سازی فناوری های مختلف Big Data آماده می شود. این فناوریها، چه در محل و چه در فضای ابری، سازمان را قادر میسازد تا Proof of Concepts / محصولات یا خدمات کلان داده جدید را سریعتر و بهتر توسعه دهد.
هنگامی که بخش فناوری اطلاعات قادر به کار با فناوریهای کلان داده باشد و کسبوکار بفهمد که دادههای بزرگ میتواند برای سازمان انجام دهد، یک سازمان وارد سطح 3 شاخص بلوغ کلان داده میشود. پذیرش کسب و کار منجر به تجزیه و تحلیل عمیق تر داده های ساختاریافته و بدون ساختار موجود در شرکت می شود که منجر به بینش بیشتر و تصمیم گیری بهتر می شود.
سطح 4 پذیرش کلان داده در سراسر سازمان است و منجر به بینش پیش بینی یکپارچه در مورد عملیات تجاری می شود و جایی که تجزیه و تحلیل داده های بزرگ به بخشی جدایی ناپذیر از فرهنگ شرکت تبدیل شده است. این سطح آخرین سطح قبل از یک سازمان کاملاً مبتنی بر داده است که به عنوان “ارائه دهنده خدمات داده” عمل می کند. شرکتهایی که به سطح 5 شاخص بلوغ کلان دادهها رسیدهاند، تجزیه و تحلیل دادههای بزرگ را در تمام سطوح سازمان خود ادغام کردهاند، واقعاً دادهمحور هستند و صرفنظر از محصول یا خدماتی که ارائه میدهند، میتوانند به عنوان «شرکتهای داده» دیده شوند. آنها بر اساس بینش Big Data خود به طور قابل توجهی از رقبای خود بهتر عمل خواهند کرد.
همه شرکت ها باید برای سطح 5 از شاخص بلوغ کلان داده تلاش کنند زیرا این امر منجر به تصمیم گیری بهتر، محصولات بهتر و خدمات بهتر می شود.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
منابع:
بازدیدها: 481
برچسبData Lake Data Swamp انبار داده باتلاق داده باتلاق داده (ِData Swamp) بیگ دیتا تفاوت انبارداده (Data Warehouse) و دریاچه داده (Data Lake) دریاچه داده سطح بلوغ کلان داده معماری دریاچه داده
نوشته های مرتبط












همچنین ببینید

پايگاه داده کاساندرا، روش نصب و بررسی نقاط ضعف و قوت
پايگاه داده کاساندرا یک سیستم انباره داده ی توزیعشده و کاملاً متن باز و رایگان …

تحلیل گراف های بزرگ با آپاچی فلینک (Apache Flink)
تعریف جریان داده: جریان داده ها، داده هایی هستندکه بطور مداوم توسط هزاران منبع داده …
