 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار با طبقه بندی موضوعی (classification) و خوشه بندی سلسله مراتبی در زیر برای دانلود ارائه شده است.
دانلود مجموعه داده اخبار فارسی دسته بندی شده
بررسی و مقایسه الگوریتمهای خوشه بندی سلسله مراتبی
توصیف کلی از الگوریتمهای سلسله مراتبی در سند (Algorithm_Total14-8-90) [8] میباشد. هدف از تدوین سند فعلی، بررسی الگوریتمهای خوشه بندی با جزییات بیشتر و مقایسه آنها میباشد. در ابتدا به مشکلات خوشه بندی ROCK و cure میپردازیم. سپس به پیچیدگی زمانی و مقایسه الگوریتمهای متفاوت پرداخته و از میان خوشه بندیهای ارائه شده، خوشه بندی مناسب را انتخاب میکنیم. برای کاهش زمان از روشهای کاهش بعد استفاده شده است. تستهای انجام گرفته در این زمینه نیز در این سند آورده شده است.
ROCK: در مجموعه داده با ابعاد بالا، فاصله یا شباهت میان نقاط یکنواختتر میشود و خوشه بندی را سختتر میکند. محاسبه شباهت با استفاده از نزدیکترین همسایه مشترک[1] در خوشه بندی ROCK میتواند برای حل این مشکل مفید باشد[1,6] . شباهت با استفاده از نزدیکترین همسایه مشترک اطلاعات کلیتری از فضای خوشه را نیز میدهد. با توجه اینکه خوشه بندی Rockدر نرمالسازی اتصالات خوشه موفق نیست، برای خوشه های پیچیده با چگالیهای متفاوت مناسب نیست. این خوشه بندی به انتخاب پارامتر بسیار حساس بوده و به نویز[2] نیز حساس است.[2] در این خوشه بندی ممکن است حالتی اتفاق بیفتد که تعداد خوشه ها را 9 انتخاب کنیم و خروجی شامل یک خوشه بزرگ و 8 خوشه نویز باشد. یا حالتی پیش بیاید که 1000 خوشه را بخواهیم و خروجی شامل 5 خوشه بزرگ و بقیه نویز باشد. ROCK برای محاسبه مقدار اتصال برای جفت نقطهها از ضریب Jaccard استفاده میکند:
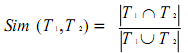
EROCK [4] به جای ضریب Jaccard، از cosine استفاده میکند. Cosine از طول سند مستقل است.
Cure: نتیجه خوشه بندی cure به انتخاب نقاط نماینده و ضریب کوچک شدن[3] α بستگی دارد. اگر α بزرگ باشد، شبیه k-means و در صورتی که کوچک باشد نسبت به داده های دورافتاده[4] حساس خواهد بود. جدول 1 نشان می دهد که این خوشه بندی توانایی مقابله با مجموعه داده با ابعاد بالا را دارد.
CHAMELEON: با وجود اینکه CHAMELEON در خوشه بندی بسیار موثر است، داده دورافتاده را نمیتواند مدیریت کند و پارامترهای زیادی را مانند تعداد نزدیکترین همسایگی در گراف خلوت، شرط توقف تقسیم گراف و ضریب α برای تنظیم نزدیکی نسبی دارد.
جدول 1 [3]
Pca را با k- means ادغام می کند.[8]
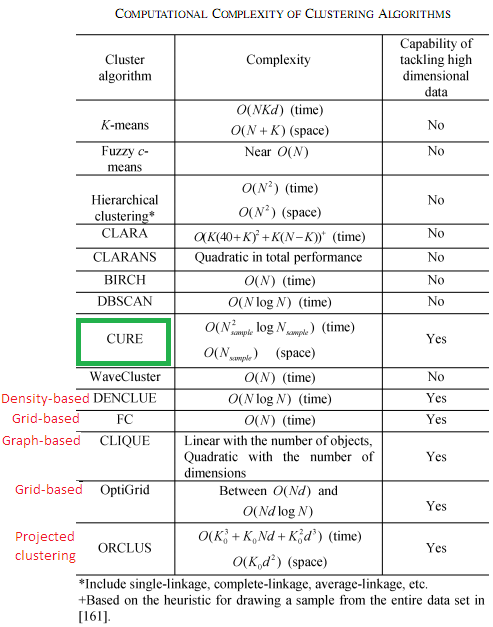
خوشه بندیهای سلسله مراتبی در جدول 2 highlight شده است. Block و ERiC [8] به ترتیب خصیصه ها بستگی ندارند. Block مجموعه سطرها ERiC یکی از انواع خوشه بندی همبستگی میباشد. در خوشه بندی همبستگی، ارتباط میان داده ها به جای خود داده به کار می رود. برای مثال یک گراف امضا شده G=(V,E) می تواند مورد استفاده قرار بگیرد که در آن برچسب یال شباهت یا تفاوت گره ها را نشان میدهد. خوشه بندی همبستگی به task دیگری نیز مربوط میشود که در آن همبستگی میان خصیصه های بردارهای ویژگی در ابعاد بالا در فرآیند خوشه بندی مورد استفاده قرار میگیرد. این همبستگیها ممکن است در کلاسترهای مختلف متفاوت باشد. همبستگی میان زیرمجموعه خصیصه ها منجر به شکلهای مختلف خوشه میشود.
ERiC [8]شامل دو مرحله می باشد: 1- در ابتدا برای همسایگی محلی هر داده، همبستگی بعد محلی تعیین میشود. همبستگی بعد محلی این داده کمترین تعداد eigenvalue است که حداقل به اندازه α از کل واریانس را توصیف کند. نقاط همسایگی میتوانند k نزدیکترین همسایه باشند. K بایستی به طور قابل ملاحظه از d بزرگتر باشد. با توجه به این مساله این نوع خوشه بندی برای متن مناسب نیست زیرا در بسیاری از موارد با ابعاد مجموعه داده از تعداد داده ها بزرگتر است.
جدول 2- [5]
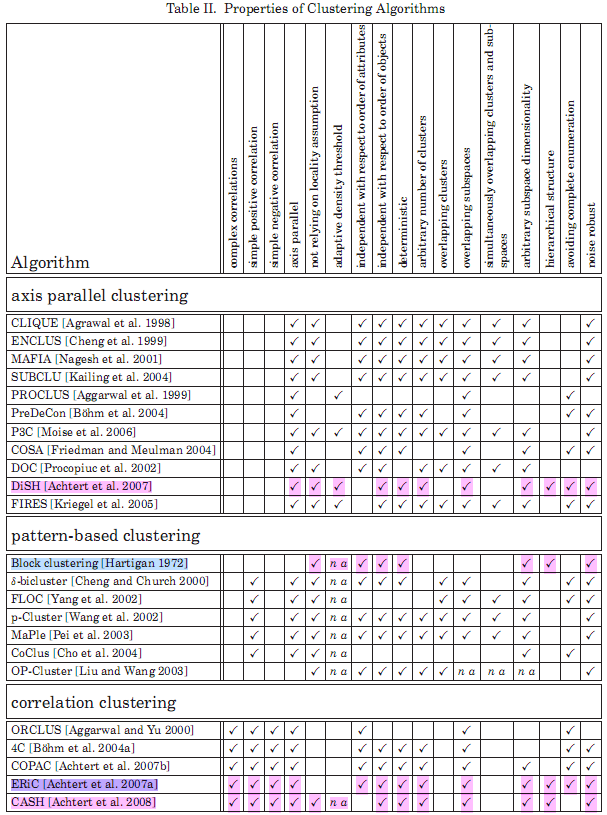
جدول 3- خوشهبندهای اسناد وب [7]
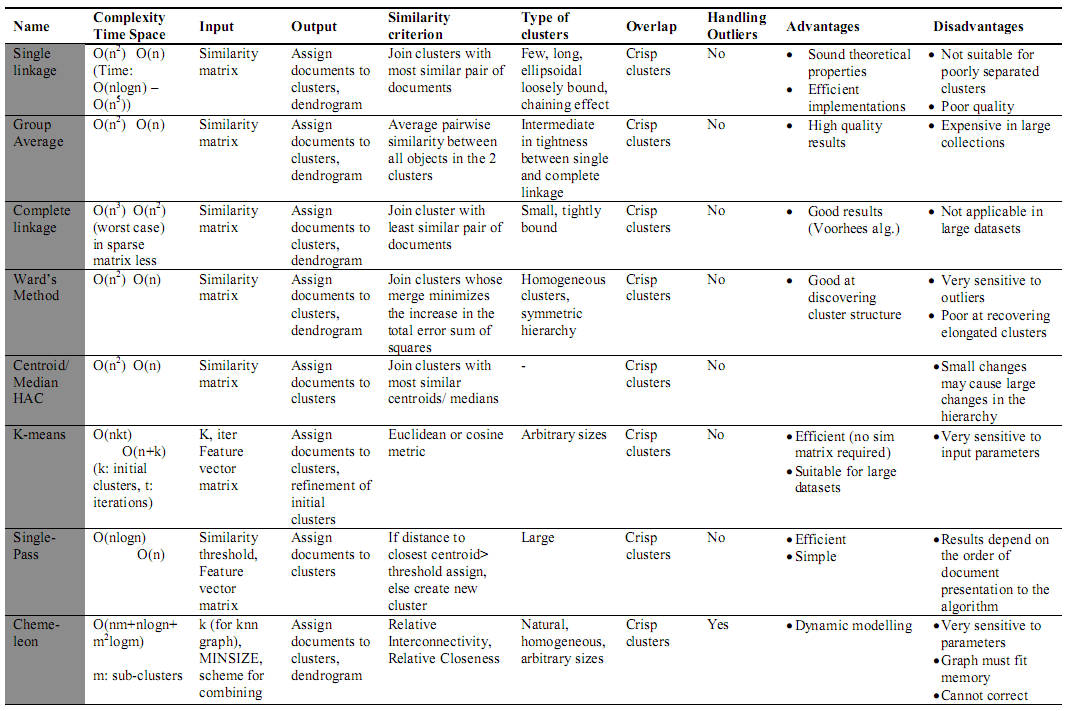
جدول 4- خوشهبندهای اسناد وب [7]
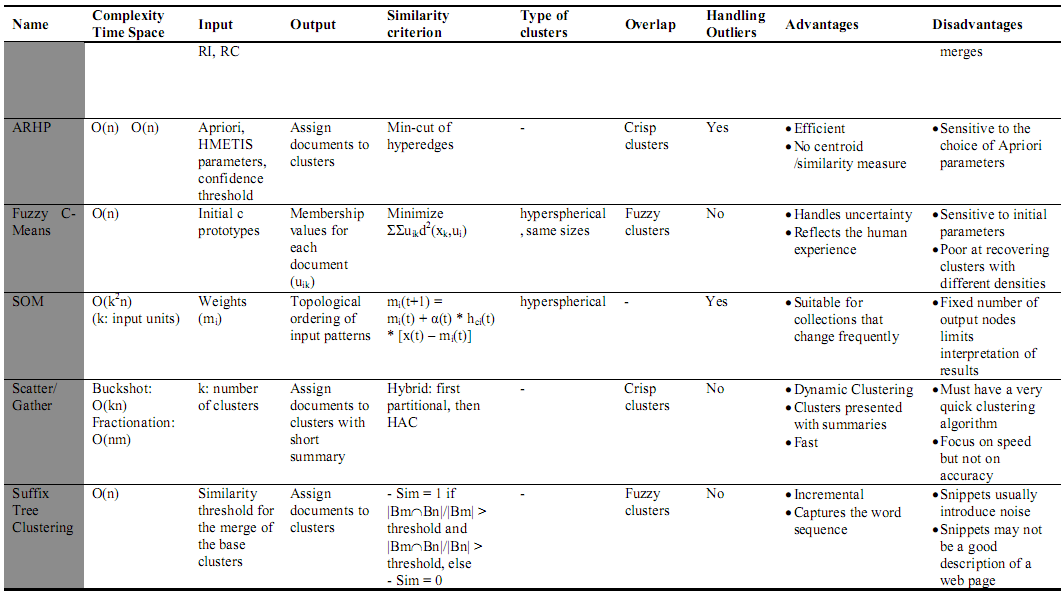
جدول 5- مقایسه خوشهبندها [7]
|
نام الگوریتم |
پیچیدگی محاسباتی |
مزایا |
معایب |
پیاده سازی |
توانایی مقابله با مجموعه داده با ابعاد بالا [3] |
|
O(n2 )- در صورت استفاده از آرایه نزدیکترین همسایگی |
1-وجود درختواره، از مهمترين مزاياي اين روش به شمار ميرود. 2- الگوریتمهاي سلسله مراتبي کلیه اشکال را تشکیل میدهند. |
1- تأثير زنجيرهاي 2- نسبت به داده هاي پرت آسیب پذیر است. |
دارد |
خیر |
|
|
O(n2 log n) |
1-وجود درختواره، از مهمترين مزاياي اين روش به شمار ميرود. 2- الگوریتمهاي سلسله مراتبي کلیه اشکال را تشکیل میدهند. |
نسبت به وجود داده هاي پرت آسیب پذیر است |
دارد |
خیر |
|
|
O(n2 log2n) |
1-وجود درختواره، از مهمترين مزاياي اين روش به شمار ميرود. 2- الگوریتمهاي سلسله مراتبي کلیه اشکال را تشکیل میدهند. |
نسبت به وجود داده هاي پرت حساس است |
دارد |
خیر |
|
|
O(n2 log2n) |
1-وجود درختواره، از مهمترين مزاياي اين روش به شمار ميرود. 2- الگوریتمهاي سلسله مراتبي کلیه اشکال را تشکیل میدهند. |
1-علاوه بر ماتريس فاصله نیاز به خود ماتريس داده ها نیز دارد 2- تنها یک نقطه مركز ثقل را به عنوان نماینده یک خوشه در نظر می گیرد |
دارد |
خیر |
|
|
O(n2 log2n) |
1-وجود درختواره، از مهمترين مزاياي اين روش به شمار ميرود. 2- الگوریتم هاي سلسله مراتبي کلیه اشکال را تشکیل میدهند. 3-نسبت به روشهای قبلی حساسیت کمتری نسبت به داده هاي پرت دارد. |
این روش نیز علاوه بر تشكيل ماتريس فاصله در حافظه، به ماتريس خود داده ها نیز نیاز دارد. |
در rapid ندارد. در weka دارد. |
خیر |
|
|
O(n) |
1-تنها یکبار مجموعه داده را اسکن میکند. 2-دارای مکانیزم تجديد/بازسازي در ساخت درخت CF است. 3-پیچیدگی زمانی فوق العاده خوبی دارد. 4-مقياسپذيري آن بر خلاف الگوریتمهای معمولی سلسله مراتبی بسیار عالی است. 5-متناسب با منابع سخت افزاری موجود بهترین کارایی خود را ارائه میدهد. |
اگر خوشه ها ذاتا دارای شکل کروی نباشند، الگوریتم خوب عمل نمیکند. |
دارد |
خیر |
|
|
O(n2+nmmma+n2logn) كه در آن mm و ma به ترتيب بيشترين و ميانگين تعداد همسايه ها و n تعداد اشياء است. |
در مواجهه با داده های طبقهاي بسیار بهتر از سایر الگوریتمها عمل میکند. |
در عملیات ادغام، نزديكي بین كلاستري را ملاک قرار نمیدهد. |
|||
|
Cure |
O(n2Logn) برای داده های با ابعاد بالا و O(n2) برای داده های دو بعدی و سه بعدی |
1-تشخیص خوشه هایی با شکل غیر کروی و با سایزهای متنوع 2-حساسیت کم نسبت به داده هاي پرت 3- این خوشه بندی توانایی مقابله با مجموعه داده با ابعاد بالا را دارد[3]. |
در عملیات ادغام، نزديكي درون كلاستري را ملاک قرار نمیدهد. |
بله |
|
|
در حالتی که مجموعه داده با ابعاد بالا داشته باشیم، پیچیدگی زمانی O(n^2) خواهد بود. |
1-در عملیات ادغام، فاصله بین كلاستري و نزديكي درون كلاستري را ملاک قرار میدهد. 2-تشخیص خوشه هایی با شکل غیر کروی و با سایزهای متنوع) شکلهایی یا کیفیت بهتر نسبت به Birch) |
|
|||
|
HiCO |
2- سلسله مراتب نسبتا ساده ای از خوشه های همبسته را درنظر می گیرد و سلسله مراتب پیچیده را نمی تواند شناسایی کند. |
||||
|
ERiC |
O(n2 d2) |
|
|||
|
block |
در مواردی که خوشه بندی اسناد و کلمات نیاز است. به جای اینکه جداگانه هر خوشه بندی اسناد براساس کلمات و خوشه بندی کلمات براساس اسناد صورت بگیرد، همزمان خوشه بندی اسناد و کلمات را انجام میدهد. |
||||
|
DiSH |
به ترتیب خصیصه ها بستگی دارد. |
||||
|
CASH |
به ترتیب خصیصه ها بستگی دارد. |
مراجع
1) Finding Clusters of Different Sizes, Shapes, and Densities in Noisy, High Dimensional Data, L. Ertöz, M. Steinbach, V. Kumar, University of Minnesota
Minneapolis, MN USA
2) On Data Clustering Analysis: Scalability, Constraints and Validation
O. R. Zaiane, A. Foss, Ch. Lee, and W. Wang, University of Alberta, Edmonton, Alberta, Canada
3) Survey of Clustering Algorithms, R. Xu, IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 16, NO. 3, MAY 2005
4) Document Topic Generation in Text Mining by Using Cluster Analysis with
EROCK, R. Ahmad, A. Khanum, National University of Science & Technology
Rawalpindi, Pakistan
5) Clustering High-Dimensional Data: A Survey on Subspace Clustering, Pattern-Based Clustering, and Correlation Clustering, H.P. KRIEGEL, P. KROGER, and A. Z. Ludwig-Maximilians-Universitat Muunchen
6) Cluster Cores-based Clustering for High Dimensional Data, Y.D. Shen, Z. Y. Shen and Sh.M. Zhang, Q. Yang
7) A Review of Web Document Clustering Approaches, N. Oikonomakou, M. Vazirgiannis, Athens University of Economics & Business
8) On Exploring Complex Relationships of Correlation Clusters, E. Achtert, Ch. B¨ohm, H. P. Kriegel, P. Kr¨oger, A. Zimek, In Proc. 19th International Conference on Scientific and Statistical Database Management (SSDBM 2007), Banff, Canada, 2007
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 3973
برچسبclassification data set اخبار تحلیل اخبار تحلیل متن دسته بندی دیتاست متن کاوی مجموعه داده مجموعه داده اخبار یادگیری ماشین
نوشته های مرتبط















همچنین ببینید
درخت تصمیم چیست و چگونه از الگوريتم هاي آن وضعیت آینده را پیشبینی کنیم
اگر میخواهید تا تصمیم پیچیدهای بگیرید و تصمیم دارید تا مسائل را برای خودتان به …

الگوریتم های برتر در حوزه داده کاوی، علم داده و یادگیری ماشین (قسمت اول)
مقدمه بر الگوریتم های برتر داده کاوی استفاده از دادهها به منظور کشف رابطه بین …
