 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آپاچی دروید (druid) پایگاه داده ای برای انبارش داده، تحلیل سری زمانی و OLAP
این مبحث شما را با Apache Druid و برخی از ویژگی های اساسی آن آشنا می کند. پس از این مراحل، Druid را نصب میکنید و دادههای نمونه را با استفاده از ویژگی جذب دستهای بومی آن بارگیری میکنید.
آپاچی دروید (druid)
نیازمندی های عملیاتی
نیازمندی های تحلیلی
عناوين مطالب: '
مقدمه ای بر آپاچی دروید
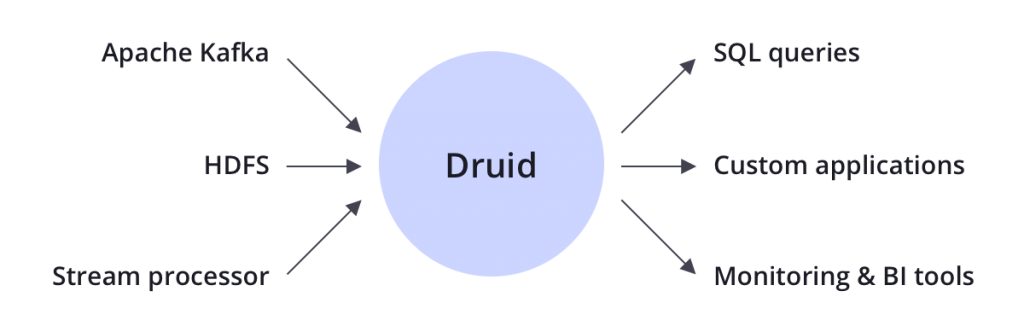
Apache Druid یک پایگاه داده تحلیلی بلادرنگ است که برای تجزیه و تحلیل سریع برش و تاس (پرس و جوهای “OLAP”) در مجموعه داده های بزرگ طراحی شده است. اغلب، قدرتهای Druid از مواردی استفاده میکنند که در آن جذب بلادرنگ، عملکرد سریع پرسوجو و زمان آپدیت بالا مهم هستند.
Druid معمولاً بهعنوان پشتیبان پایگاه داده برای رابطهای کاربری گرافیکی برنامههای تحلیلی یا برای APIهای بسیار همزمان که نیاز به تجمیع سریع دارند، استفاده میشود. Druid با داده های رویداد محور بهترین کار را دارد.
زمینه های کاربردی رایج برای Druid عبارتند از:
- تجزیه و تحلیل جریان کلیک از جمله تجزیه و تحلیل وب و موبایل
- تجزیه و تحلیل تله متری شبکه از جمله نظارت بر عملکرد شبکه
- ذخیره سازی معیارهای سرور
- تجزیه و تحلیل زنجیره تامین از جمله معیارهای تولید
- معیارهای عملکرد برنامه
- بازاریابی دیجیتال / تجزیه و تحلیل تبلیغات
- هوش تجاری/OLAP
قابلیت های آپاچی دروید
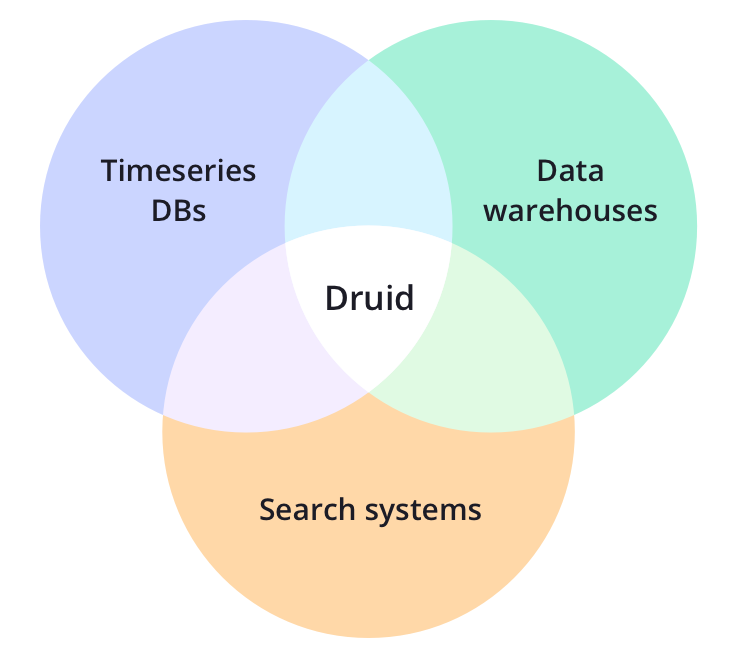
Apache Druid یک ذخیره ساز داده منبع باز و توزیع شده است. طراحی هسته Druid ایدههایی را از انبارهای داده، پایگاههای داده سری زمانی و سیستمهای جستجو ترکیب میکند تا یک پایگاه داده تحلیلی با کارایی بالا برای طیف وسیعی از موارد استفاده ایجاد کند. Druid ویژگی های کلیدی هر یک از 3 سیستم را در لایه ingestion ، فرمت ذخیره سازی، لایه پرس و جو و معماری هسته ادغام می کند. ویژگیهای مهم دروید در زیر آمده است.
- Column-oriented storage
-
Native search indexes
-
Streaming and batch ingest
-
Flexible schemas
-
Time-optimized partitioning
-
SQL support
-
Horizontal scalability
-
Easy operation
چه زمانی باید از Druid استفاده کرد؟
Druid توسط بسیاری از شرکت ها در اندازه های مختلف برای موارد استفاده مختلف استفاده می شود. اگر مورد استفاده شما با چند مورد زیر مطابقت داشته باشد، Druid احتمالاً انتخاب خوبی است:
- نرخ درج بسیار بالا است، اما به روز رسانی کمتر
- بیشتر پرس و جوهای شما عبارتند از پرس و جوهای تجمیع و گزارش. به عنوان مثال پرس و جوهای “group by”.
- شما تاخیرهای پرس و جو از 100 میلی ثانیه تا چند ثانیه را هدف قرار داده اید.
- داده های شما دارای یک جزء زمان هستند. Druid شامل بهینه سازی ها و انتخاب های طراحی به طور خاص مربوط به زمان است.
- ممکن است بیش از یک جدول داشته باشید، اما هر پرس و جو فقط به یک جدول توزیع شده بزرگ برخورد می کند. پرس و جوها ممکن است به طور بالقوه به بیش از یک “lookup table” کوچکتر برخورد کنند.
- شما ستون های داده با کاردینالیتی بالا دارید، به عنوان مثال. URL ها، شناسه های کاربر، و نیاز به شمارش سریع و رتبه بندی بر روی آنها دارند.
- میخواهید با سرعت بالا دادهها را از کافکا، HDFS، فایلهای مسطح یا ذخیرهسازی اشیا مانند Amazon S3 بارگیری کنید.
موقعیت هایی که احتمالاً نمی خواهید از Druid استفاده کنید عبارتند از:
- شما نیاز به update با تاخیر کم رکوردهای موجود به صورت جریانی با استفاده از کلید اصلی دارید. دروید از streaming insert پشتیبانی میکند، اما streaming update را پشتیبانی نمیکند. می توانید با استفاده از کارهای دسته ای پس زمینه به روز رسانی ها را انجام دهید.
- شما در حال ساختن یک سیستم گزارش دهی آفلاین هستید که در آن تأخیر پرس و جو خیلی مهم نیست.
- شما میخواهید join های بزرگ را انجام دهید، به این معنی که یک fact table بزرگ را به یک fact table دیگر بپیوندید، و شما مشکلی ندارید که این پرسشها زمان زیادی برای تکمیل شدن دارند.
ملاحظات نصب دروید
قبل از نصب نمونه Druid تولیدی، مطمئن شوید که حساب کاربری در سیستم عاملی که Druid تحت آن اجرا می شود را در نظر بگیرید. این مهم است زیرا هر کاربر کنسول Druid به طور موثر مجوزهای مشابه آن کاربر را خواهد داشت. بنابراین، برای مثال، رابط کاربری مرورگر فایل فایلهایی را که کاربر اصلی میتواند به آنها دسترسی داشته باشد، به کاربران کنسول نشان میدهد. به طور کلی، از اجرای Druid به عنوان کاربر ریشه خودداری کنید. ایجاد یک حساب کاربری اختصاصی برای اجرای Druid را در نظر بگیرید.
الزامات نصب
شما می توانید این مراحل را در یک دستگاه نسبتا کوچک مانند لپ تاپ با حدود 4 هسته CPU و 16 گیگابایت رم دنبال کنید.
Druid با چندین پروفایل پیکربندی راه اندازی برای طیف وسیعی از اندازه های ماشین ارائه می شود. مشخصات پیکربندی micro-quickstart نشان داده شده در اینجا برای ارزیابی Druid مناسب است. اگر میخواهید عملکرد Druid یا قابلیتهای مقیاسبندی را امتحان کنید، به یک دستگاه بزرگتر و مشخصات پیکربندی نیاز دارید.
پروفایل های پیکربندی موجود در Druid از پیکربندی حتی کوچکتر Nano-Quickstart (1 CPU، 4 گیگابایت رم) تا پیکربندی X-Large (64 CPU، 512GiB RAM) را شامل می شود.
نرم افزار مورد نیاز دستگاه نصب عبارتند از:
- لینوکس، Mac OS X یا سایر سیستمعاملهای مشابه یونیکس (ویندوز پشتیبانی نمیشود)
- جاوا 8، بهروزرسانی 92 یا بالاتر (8u92+)
Druid برای یافتن جاوا در دستگاه به متغیرهای محیطی JAVA_HOME یا DRUID_JAVA_HOME متکی است. اگر بیش از یک نمونه از جاوا وجود دارد، می توانید DRUID_JAVA_HOME را تنظیم کنید. برای تأیید الزامات جاوا برای محیط خود، اسکریپت bin/verify-java را اجرا کنید.
قدام به نصب دروید
- download Druid from https://druid.apache.org/downloads.html
- copy zip file into
appsfolder inWSLhome directory (~/home) - unzip druid :
tar -xvf apache-druid-0.22.0-bin.tar.gzip - verify java version
$ cp apache-druid-0.22.0-bin.tar.gzip ~/apps $ tar -xvf apache-druid-0.22.0-bin.tar.gzip $ cd ~/apache-druid-0.22.0 $ ./bin/verify-java Druid only officially supports Java 8. Any Java version later than 8 is still experimental. Your current version is: 11.0.11. If you believe this check is in error or you still want to proceed with Java version other than 8, you can skip this check using an environment variable: export DRUID_SKIP_JAVA_CHECK=1 Otherwise, install Java 8 and try again. This script searches for Java 8 in 3 locations in the following order * DRUID_JAVA_HOME * JAVA_HOME * java (installed on PATH)
- run this command
export DRUID_SKIP_JAVA_CHECK=1Verify Again :./bin/verify-javaRun Druid - Micro Quick Start
After the Druid services finish startup, open the Druid console at http://localhost:8888.
ساختار داده ای دروید
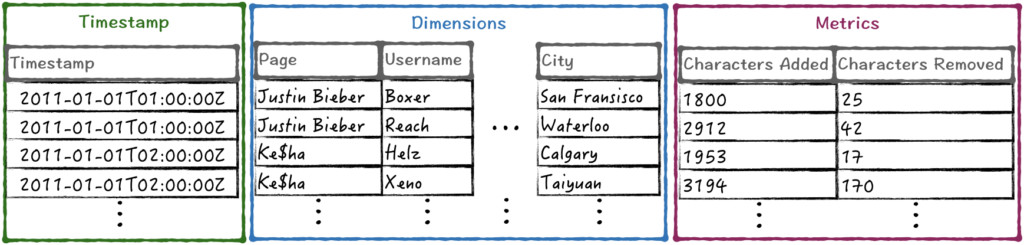
ساختار دیتاسورس ها در دروید : هر رکورد از سه بخش مهر زمانی، ابعاد یا ویژگی ها و متریک ها یا سنجه های آماری تشکیل شده است.
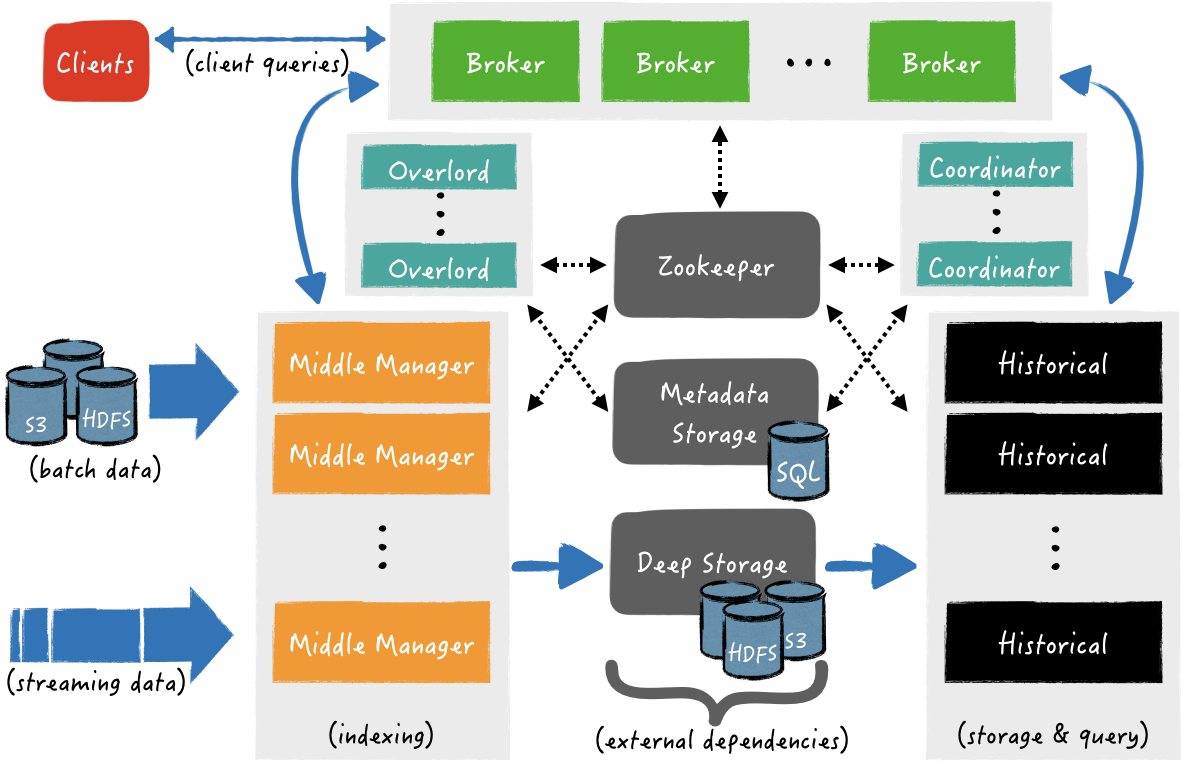
معماری و مولفه های دروید
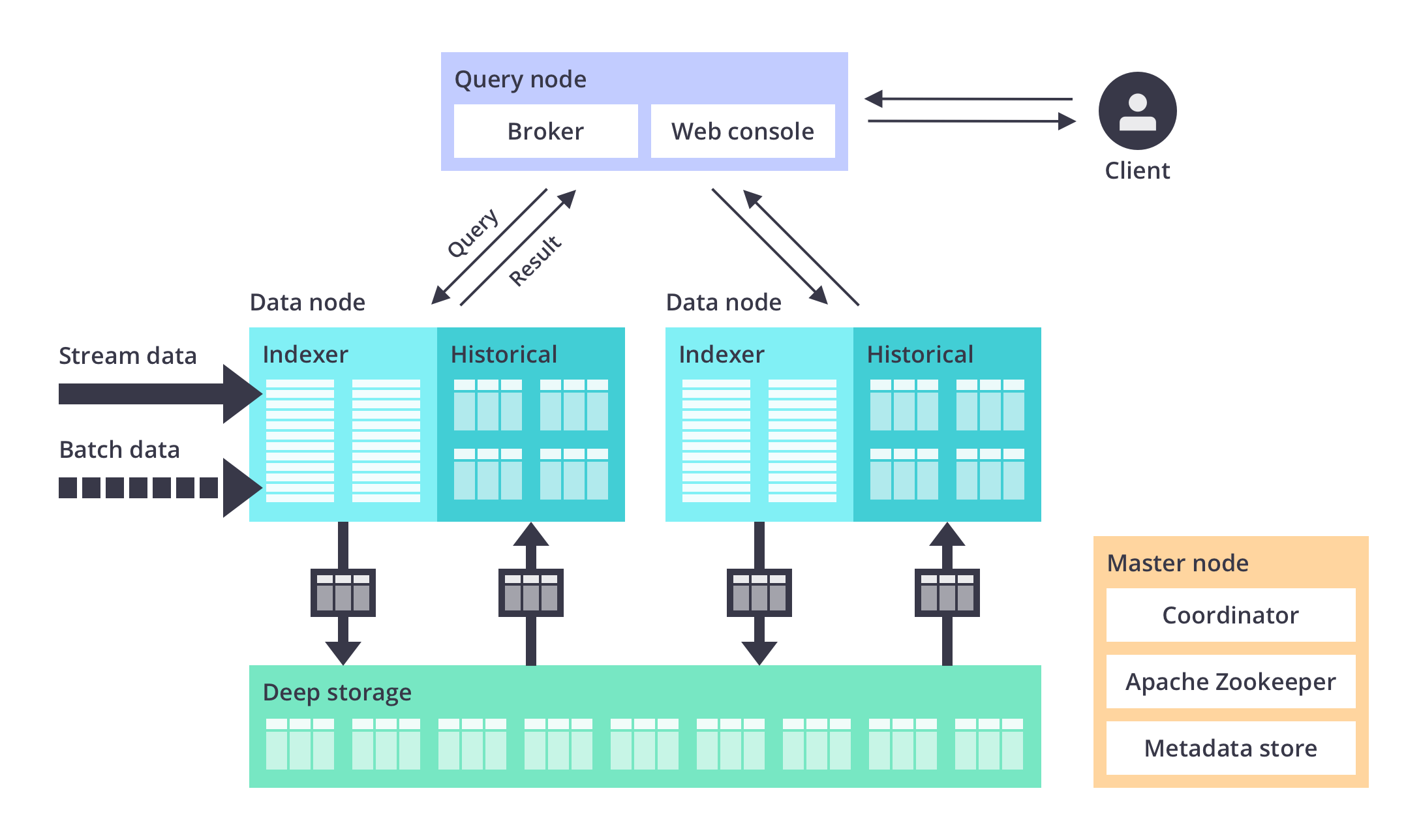
منبع:
https://druid.apache.org/docs/latest/tutorials/index.html
بازدیدها: 672
برچسبDataWarehouse Druid OLAP دروید
نوشته های مرتبط






همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …
