 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش کامل یادگیری ماشین (Machine learning) به صورت گام به گام
مقدمه ای بر یادگیری ماشین
یادگیری ماشین بزرگترین راه حل بشر برای انجام کارهای پیچیده و تکراری است. پیش از این گمان میشد که یادگیری ماشین یک کار بسیار تخصصی و پیچیده است که فقط متخصصان هوش مصنوعی می توانند آن را انجام دهند. ولی امروز می بینیم که حتی دانشجویان علوم انسانی از یادگیری ماشین برای انجام پایان نامه های خود بهره می برد. هدف از این مبحث ارائه یک آموزشی کاربردی و آسان آن برای همگان جهت آشنایی با مبانی و کاربردهای یادگیری ماشین و همچنین شناخت روش ها و ابزارهای کاربردی در این زمینه است.
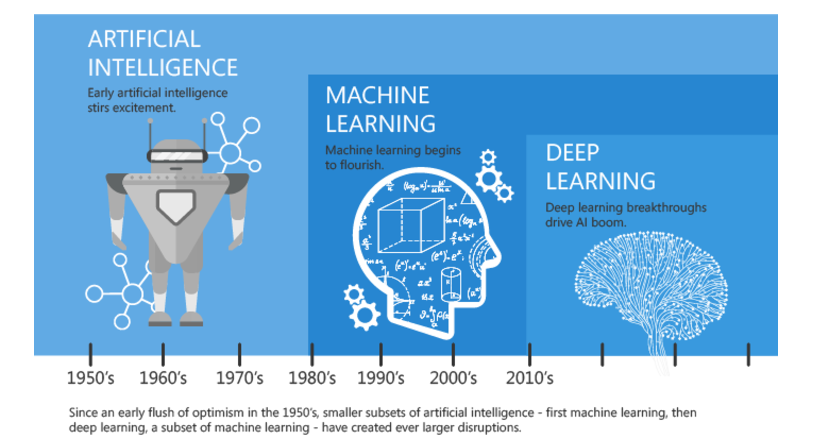
عناوين مطالب: '
- یادگیری ماشین چیست؟
- کاربردهای یادگیری ماشین
- دیتاست یا مجموعه داده چیست؟
- فرایند یا مراحل یادگیری ماشین؟
- ۱- شناخت نیازمندیهای کسبوکار و جمع آوری داده
- ۲ آمادهسازی داده
- ۳ مهندسی ویژگی و استخراج و انتخاب ویژگی (Feature extraction)
- ۴ انتخاب الگوریتم و روش یادگیری
- ۵ آموزش مدل یادگیری ماشین براساس دادههای آموزش (Train)
- ۶ آزمودن یا تست مدل براساس دادههای آزمون (Test)
- ۷ ارزیابی دقت و صحت مدل
- 8 بکارگیری مدل در محیط عملیاتی
- 9 ارزیابی نهایی مدل در محیط واقعی
- 10 کسب بینش ناشی از تحلیلهای دادهمحور
- ابزارهای یادگیری ماشین:
- تفاوت یادگیری ماشین با یادگیری عمیق:
یادگیری ماشین چیست؟
یادگیری ماشین از تخصص های ذیل رشته هوش مصنوعی و از جمله روش های داده کاوی می باشد. یادگیری ماشین فرآیندی است که در آن، کامپیوتر به واسطه الگوریتم های خاص عملکرد خاصی را آموزش می بیند. به عبارتی انسان با گردآوری دادههایی که به آن دیتا ست یا مجموعه داده می گویند ماشین را برای انجام عملیات خاصی آموزش می دهد. این آموزش تا جایی ادامه می یابد تا اطمینان حاصل شود ماشین میتواند آن عمل را همانند انسان با کیفیتی شبیه به او انجام دهد. این فرایند را همچنین یادگیری با ناظر اطلاق می کنند چرا که ماشین به واسطه آموزش هایی که انسان به او داده میتواند به فعالیت ادامه دهد.
کاربردهای یادگیری ماشین
تشخیص تصویر: یکی از کاربردهای بسیار مهم یادگیری ماشین تشخیص تصاویر است. تشخیص تصاویر می تواند حوزههای مختلفی را شامل شود. شود تشخیص اشیا و تشخیص چهره نمونههایی از شناخت شده ترین کاربردها در این این حوزه است. امروزه با تکنیکهای یادگیری عمیق این روش ها به دقت های فزایندهای رسیدهاند.
تشخیص صوت: نمونه های دیگر میتوان آن به تشخیص اصوات اشاره نمود. تشخیص اصوات مختلف و تفکیک آنها و طبقه بندی و حتی تبدیل صوت به من متن از جمله این روش هاست. به عنوان یک کار عملی می توان از پروژهای یاد کرد که در آن با استفاده از یادگیری صدای موتور اتومبیل علت خرابی موتور را را تشخیص داد. روش کار به این صورت است که در هنگام خرابی های مختلف خودرو صدای آن آن به عنوان مجموعه داده به الگوریتم های یادگیری ماشین تحویل داده شده تا صدای خودروی خراب را یاد بگیرند و در مراحل بعد خودرو های دیگر که برای بررسی فنی مورد آزمون قرار میگیرند اگر صدایی همچون این صدای اتومبیلهای خراب داشته باشد ماشین علت خرابی را را اعلام می کند.
تحلیل احساس (opinion mining): احساس افراد از روی موتون یکی دیگر از موارد جذاب در حوزه یادگیری ماشین است. اگر ما مجموعه دادهای از متون که شامل نوعی از احساسات باشد به الگوریتم های یادگیری ماشین تحویل بدهیم ماشین این احساسات را یاد گرفته و بعد از آن هر متنی که در آن این چنین احساس هایی وجود داشته باشد آن را برای ما استخراج میکند.
طبقه بندی یا classification: می توان گفت که طبقه بندی یا رده بندی داده ها از معروف ترین کاربردهای یادگیری ماشین است. همچون مثال های قبل کافی است ما داده هایی را از یک موضوع خاص به ماشین آموزش داده تا ماشین در آینده دادههای از آن طبقه را تشخیص دهد.
هدایت وسایل حمل و نقل: امروز شاهد آن هستیم که بسیاری از وسایل حمل و نقل چه زمینی، دریای یا هوایی نیاز به هدایت خودکار دارند. هدایت خودکار یعنی آنکه یک ماشین هدایت آن وسیله را به عهده بگیرد. تنظیم جهت، سرعت، عدم برخورد به موانع و امثال این از جمله نیازهایی است که می توان با بهره گیری از تکنیک های یادگیری ماشین از آن بهره مند شد.
دیتاست یا مجموعه داده چیست؟
دیتا ست ها دسته ای از اطلاعات با ویژگی های مشخص هستند که در یک حوزه ی مشخص گرداوری شده است. دیتاست یا مجموعه داده به مجموعهای از دادهها میگویند که با موضوعیت یکسان، جهت انجام تحلیل ها و پروژههای داده کاوی استفاده میشوند. البته یک کاربرد دیگر دیتاست ها نیز برای مقایسه بین روشهای مختلف هست، به این صورت که بهطور نمونه بر روی یک مجموعه داده، دو روش(الگوریتم) مختلف را اجرا کرده و با توجه به نتایج میتوان بر اساس معیارهای دقت، سرعت و پیچیدگی هریک از روشها را مقایسه کرد.
روش انتخاب دیتاست مناسب برای تحقیق:
برای هر تحلیلی در دنیای داده کاوی می بایست دیتاست مناسب آن را فراهم آوریم. فرض کنید تحلیلی که میخواهید انجام شود در مورد ردهبندی (Classification) است. درنتیجه ما باید به دنبال دیتاستی باشیم که Lable یا برچسب خورده باشد. یا در مثال دیگر، فرض کنید ما به دنبال ایجاد یا ارتقاء روشی برای کاهش ابعاد دیتا هستیم در این صورت نیز ما باید مجموعه داده ای را انتخاب کنیم که دارای بُعد زیاد باشد. یا فرض کنید که ما به دنبال تحلیل متن فارسی هستیم. پس بدیهی است که باید یک مجموعه داده به زبان فارسی پیدا کنیم. با این که فرض کنید میخواهیم تست فشار برای یک سیستم بزرگ مقیاس انجام دهیم پس باید به دنبال داده های حجیم باشم. گونه های مختلفی در دیتاستها وجود دارد بهطور خلاصه میتوان دیتاست ها را به موارد زیر تقسیمبندی کنیم:
- مجموعه داده متنی (متن مقاله، کتاب، نظرات شبکههای اجتماعی، توییت ها و …)
- مجموعه داده جدولی (دادههای موجود در پایگاه داده، خوشهبندی، طبقهبندی، سری زمانی و …)
- مجموعه داده چندرسانه ای (عکس، ویدیو و صوت)(عکسهای هوایی، دوربینهای مداربسته و …)
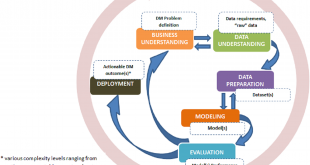
فرایند یا مراحل یادگیری ماشین؟
یکی از مولفههای مهم جهت موفقیت در پروژههای یادگیری ماشین، بهرهگیری از متدولوژی و جریانهای کاری دقیق جهت مدیریت پروژه است. در ادامه گامهای لازم جهت پیادهسازی مدلهای تحلیلی مبتنی بر یادگیری ماشین ذکر شدهاند. در منابع مختلف می بینیم که مراحل یادگیری ماشین، از لحاظ تعداد مراحل اختلاف نظر وجود دارد. در عمده منابع با پنج، شش یا هفت مرحله مواجه هستیم. که البته این اختلاف بنیادی نیست بلکه در برخی از منابع ترجیح داده شده است که بعضی از مراحل تفکیک شوند و و جزئی تر و یا نشوند. لذا امکان دارد که حتی در برخی از منابع با بیش از ۷ مرحله هم مواجه شویم لذا در اینجا یک فرایند 10مرحله ای را برای یادگیری ماشین مورد بررسی قرار میدهیم.
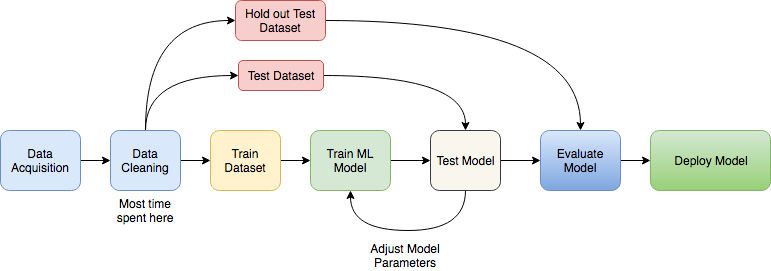
۱ شناخت نیازمندیهای کسبوکار و جمع آوری داده
۲ آمادهسازی داده
۳ مهندسی ویژگی و استخراج و انتخاب ویژگی (Feature extraction)
۴ انتخاب الگوریتم و روش یادگیری
۵ آموزش مدل یادگیری ماشین براساس دادههای آموزش (Train)
۶ آزمودن یا تست مدل براساس دادههای آزمون (Test)
۷ ارزیابی دقت و صحت مدل
8 بکارگیری مدل در محیط عملیاتی
9 ارزیابی نهایی مدل در محیط واقعی
10 کسب بینش ناشی از تحلیلهای دادهمحور
این هفت گام در فرایند یادگیری ماشین بارها و بارها تکرار می شود. مخصوصا مرحله 2 تا 9 از جمله مراحلی هست که جهت بهبود عملکرد مدل یادگیری ماشین تا زمان رسیدن به کیفیت مطلوب باید به صورت متناوب تکرار شود. در ادامه هر یک از این گام ها به صورت مختصر بررسی می شود.
۱- شناخت نیازمندیهای کسبوکار و جمع آوری داده
جمع آوری داده فرایندی است بسیار متنوع. هر فرد یا سازمانی ممکن است دیتا ست های مورد نظر خود را از راه های مختلف تهیه کنند. از تهیه دستی توسط نیروی انسانی یا جمع آوری خودکار داده ها از فضای اینترنت می تواند متصور شد. یا حتی تهیه داده از بازار سیاه یا داده های سازمانی مثل دیتابیس ها و فایل های ثبت وقایع میتواند نیازهای داده ای ما را تامین کند.
آنچه که در این مرحله از اهمیت ویژهای برخوردار است آن است که بدانیم ما به دنبال چه هستیم و قرار است الگوریتمهای یادگیری ماشین را به چه جهت آموزش دهیم یا یا به عبارت دیگر باید هدف نهایی ما از یادگیری ماشین کاملاً برای خودمان و کاربر سیستم کاملا واضح و روشن باشد. لذا این مرحله می تواند در موفقیت فرایند یادگیری بسیار اثر گذار باشد. در صورت تبیین شدن درست صورت مسئله و انتخاب داده نامناسب یا بی ارزش و یا داده های دارای نویز بیش از حد، عملیات یادگیری و بهره گیری از سیستم با شکست مواجه می شود.
استفاده از افراد خبره و مشاوران با تجربه در این هنگام می تواند موفقیت پروژه را تا حد زیادی تضمین کند و برعکس اشتباه در این مرحله ممکن است موجب زاویه گرفتن پروژه از نیاز اصلی کارفرما شود و در نتیجه پروژه یادگیری ماشین برای وی مفید فایده قرار نگیرد.
۲ آمادهسازی داده
این امکان وجود دارد که داده ها در سراسر سازمان توزیع شده و در قالب های مختلف ذخیره گردند و یا اینکه ممکن است شامل تناقضات و ناسازگاری هایی از جمله ورودی های نادرست یا از دست رفته باشند.
مراحل Data Cleansing یا تمیزسازی داده (با تلفظ: دیتا کلینزینگ)
۱- مجتمع کردن داده ها
۲- بازسازی داده های گم شده
۳- استانداد سازی یا یک شکل کردن داده
۴- نرمال سازی داده
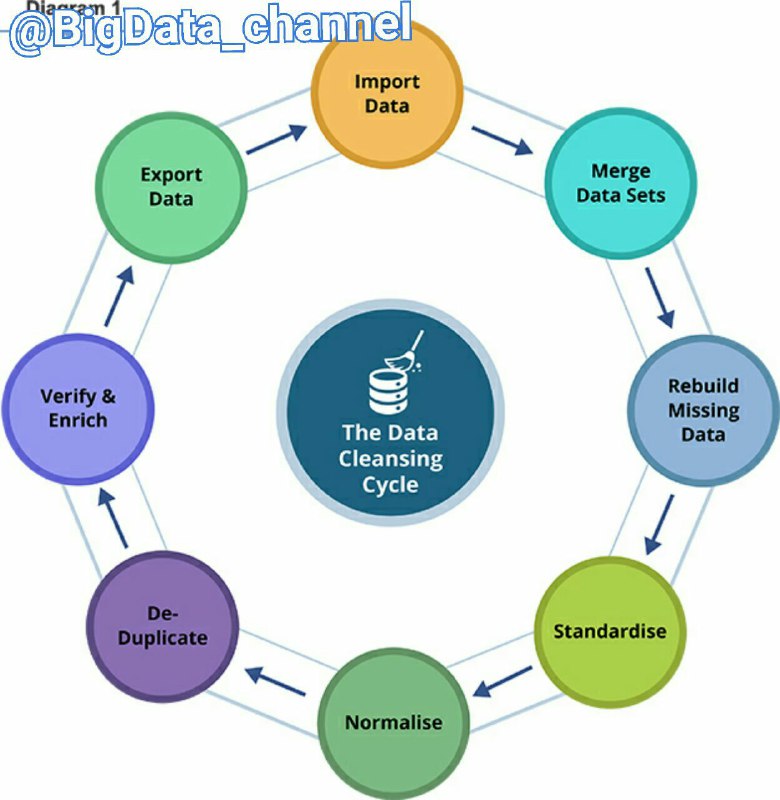
فرآیند پاکسازی داده ها (Data Cleansing) تنها به حذف داده های نامناسب یا وارد کردن مقادیر از دست رفته خلاصه نمی شود. پاکسازی کشف روابط پنهان شده ی میان داده ها، شناسایی دقیق ترین منابع داده و تعیین مناسب ترین ستون ها برای استفاده در آنالیز را نیز دربر میگیرد. لازم به ذکر است که داده های ناقص، داده های نادرست و داده های ورودی به ظاهر مجزا اما در حقیقت بسیار به هم پیوسته و مرتبط با یکدیگر، می توانند تاثیری فراتر از حد انتظار بر روی نتایج داشته باشند.
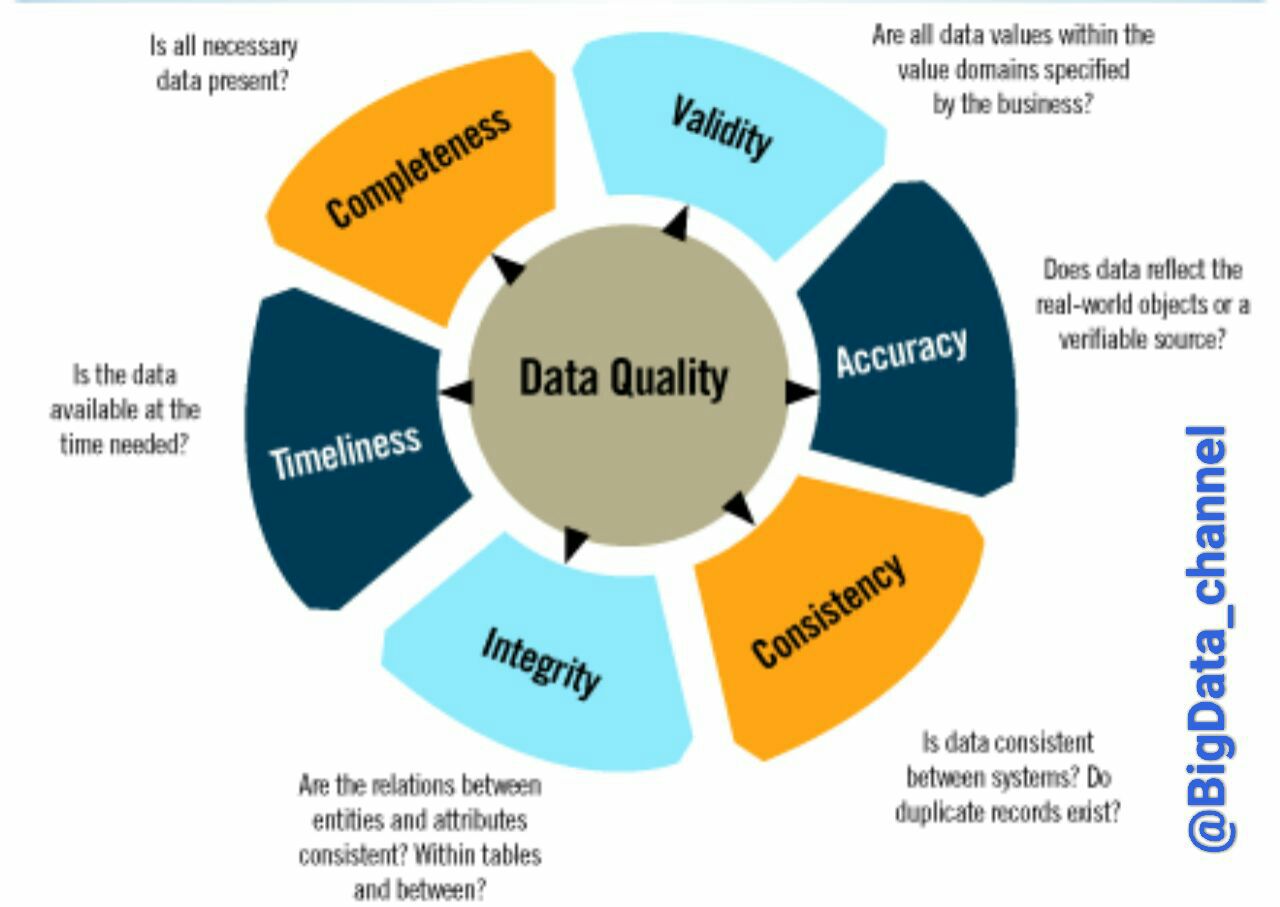
یک داده با کیفیت برای تحلیل معمولا شش ویژگی زیر را دارد:
۱- ارزش یا اعتبار داده
۲- دقت و صحت داده
۳- دوام یا پایداری داده
۴- یکپارچگی ارتباطات و بخش های مختلف داده
۵- بردار زمانی داده
تذکر:
الزامی در رابطه با ذخیره ی داده های مورد استفاده در داده کاوی بر روی یک پایگاه داده ی Cube OLAP و یا پایگاه های داده ی رابطه ای (Relational Database) وجود ندارد، اگرچه میتوان از هردوی آنها به عنوان منبع های داده استفاده نمود. بنابراین فرآیند داده کاوی را میتوان با استفاده از هر منبع داده ای که به عنوان منبع داده ی Analysis Services تعریف شده باشد، انجام داد. این منابع داده ممکن است شامل فایل های متنی (Text) و Workbookهای Excel یا داده های سایر منابع خارجی باشد.
۳ مهندسی ویژگی و استخراج و انتخاب ویژگی (Feature extraction)
در این گام استخراج ویژگی و انتخاب ویژگی تاثیرگذار و انواع روشهای آن مورد بحث قرار میگیرد. برای درک بهتر این مرحله یک مثال ساده می آوریم. برای مثال فرض کنید شرکت گوگل میخواهد یک الگوریتم توسعه دهد که با آن بتواند بفهمد که یک ایمیلْ هرزنامه است یا خیر؟ برای این کار بایستی ویژگیهای مختلفی را جمع آوری کند، برای مثال یکی از مجموعه ویژگیها میتواند بردار TF-IDF باشد (که در درسی جدا به آن خواهیم پرداخت). بردار TF-IDF برداری است که از روی کلمات میتواند ویژگیهای مختلف را برای یک متن بسازد (در واقع متن را تبدیل به اعداد قابل فهم برای الگوریتم کند). همانطور که میدانید محتوای اصلی یک ایمیلْ متنِ آن است. پس گوگل از متنهای موجود در ایمیل یک مجموعه ویژگی میسازد. مثلا اینکه تعداد تکرار کلمهی “تبلیغ” در متن یک ایمیل چقدر بوده است؟ یا تعداد تکرار کلمه “جایزه” در یک ایمیل چقدر بوده است؟ الگوریتم یادگیریماشین با استفاده از این دست ویژگیها میتواند به بفهمد یک ایمیلْ هرزنامه هست یا خیر.
ولی آیا تمامِ ویژگیها برای طبقهبندیِ یک ایمیلْ میتواند صرفاً از روی متونِ آن به دست آید؟ در این مثال شاید بتوان ویژگیها یا همان ابعادِ دیگری را نیز از ایمیلها استخراج کرد و به الگوریتم یاد داد. مثلا اینکه IP ارسال کننده کدام است؟ یعنی ممکن است IP ارسال کننده نیز در طبقهبندی تاثیر داشته باشد چون برخی از ارسال کنندههای هرزنامه (Spam) از IPهای مشخصْ ایمیلهای هرزنامه را ارسال میکنند و الگوریتمِ یادگیریماشین میتواند این IPها را در طبقهبندیِ ایمیل (به هرزنامه یا غیرِ هرزنامه) تاثیر دهد.
مثلا تعدادِ تصاویرِ موجود در یک ایمیل هم میتواند به عنوان یکی از ویژگیها یا همان ابعادْ درنظر گرفته شود چون این احتمال میرود که تعداد تصاویر هم بتواند یکی از ویژگیهای تاثیرگزار در هرزنامه بودن یا نبودن ایمیل باشد.
روشهای انتخاب ویژگی (Feature Selection Methods) به منظور مواجهه با دادهها با ابعاد بالا است. یک انتخاب ویژگی صحیح میتواند منجر به بهبود فرایند یادگیری شود. مجموعه دادههای متعددی با ابعاد بالا در اینترنت در دسترس است. اما این موضوع چالش جالب توجهی را برای جوامع پژوهشی در پی داشته است. زیرا برای الگوریتمهای یادگیری ماشین سر و کار داشتن با حجم زیادی از ویژگیهای ورودی کاری دشوار است. در این رابطه واژه «ابعاد کلان» (Big Dimensionality) در قیاس با واژه بیگ دیتا ساخته شده است. روشهای کاهش ابعاد به ترتیب در دو دسته استخراج ویژگی و انتخاب ویژگی مطرح است.
استخراج ویژگی (Feature extraction)
با توجه بع توضیحات فوق اولین قدم بدست آوردن تمام وییژگی های داده ی مورد نظر است. تا بتوان در مراحل بعدی ویژگی های برتر را گل چین نمود. روشهای استخراج ویژگی با ترکیب ویژگیهای اصلی به کاهش ابعاد دست مییابند. از این رو، قادر به ساخت مجموعهای از ویژگیهای جدید هستند که معمولا فشردهتر و دارای خاصیت متمایزکنندگی بیشتری است.

انتخاب ویژگی (Feature Selection)
شاید مهمترین بخش برای عملیاتِ دادهکاویْ عملیاتِ انتخابِ ویژگی است. در گام انتخاب ویژگی با حذف ویژگیهای غیر مرتبط و تکراری میتوان ابعاد مسئله را کاهش داد. در مباحثِ آکادمیک معمولا ویژگیها در مسئله در اختیار کاربران قرار دارند ولی در مباحث عملی یک متخصص علومداده بایستی خود ویژگیهای مورد نیاز را از میان دادگان استخراج کند. انتخاب ویژگی که با عناوین دیگری همانند Variable Selection و Attribute Selection و نیز Variable Subset Selection شناخته می شود. انتخاب ویژگی را میتوان به عنوان فرآیند شناسایی ویژگیهای مرتبط و حذف ویژگیهای غیر مرتبط و تکراری با هدف مشاهده زیرمجموعهای از ویژگیها که مساله را به خوبی تشریح میکنند تعریف کرد.
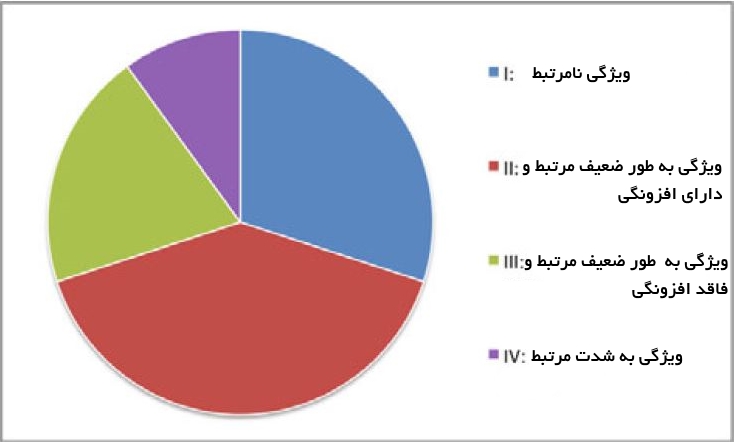
کل مجموعه ویژگی میتواند به طور مفهومی به چهار بخش مجزا تقسیم شود که عبارتند از:
- ویژگیهای نامرتبط
- ویژگیهای به طور ضعیف مرتبط و ویژگیهای دارای افزونگی
- ویژگیهای به طور ضعیف مرتبط ولی فاقد افزونگی
- ویژگیهای به شدت قدرتمند
لازم به ذکر است که مجموعه بهینه حاوی همه ویژگیهای موجود در بخشهای 3و 4میشود.
روش های انتخاب ویژگی (Feature Selection)
سه رویکرد کلی انتخاب ویژگی با توجه به ارتباط بین الگوریتمهای انتخاب ویژگی و روش یادگیری مورد استفاده قرار میگیرند. این موارد در ادامه بیان شدهاند.
«فیلترها» (Filters) بر ویژگیهای کلی مجموعه داده آموزش تکیه دارند و فرآیند انتخاب ویژگی را به عنوان یک گام پیش پردازش با استقلال از الگوریتم استقرایی انجام میدهند. مزیت این مدلها هزینه محاسباتی پایین و توانایی تعمیم خوب آنها محسوب میشود.
«بستهبندها» (Wrappers) شامل یک الگوریتم یادگیری به عنوان جعبه سیاه هستند و از کارایی پیشبینی آن برای ارزیابی مفید بودن زیرمجموعهای از متغیرها استفاده میکنند. به عبارت دیگر، الگوریتم انتخاب ویژگی از روش یادگیری به عنوان یک زیرمجموعه با بار محاسباتی استفاده میکند که از فراخوانی الگوریتم برای ارزیابی هر زیرمجموعه از ویژگیها نشات میگیرد. با این حال، این تعامل با دستهبند منجر به نتایج کارایی بهتری نسبت به فیلترها میشود.
«روشهای توکار» (Embedded) انتخاب ویژگی را در فرآیند آموزش انجام میدهند و معمولا برای ماشینهای یادگیری خاصی مورد استفاده قرار میگیرند. در این روشها، جستوجو برای یک زیرمجموعه بهینه از ویژگیها در مرحله ساخت دستهبند انجام میشود و میتوان آن را به عنوان جستوجویی در فضای ترکیبی از زیر مجموعهها و فرضیهها دید. این روشها قادر به ثبت وابستگیها با هزینههای محاسباتی پایینتر نسبت به بستهبندها هستند.
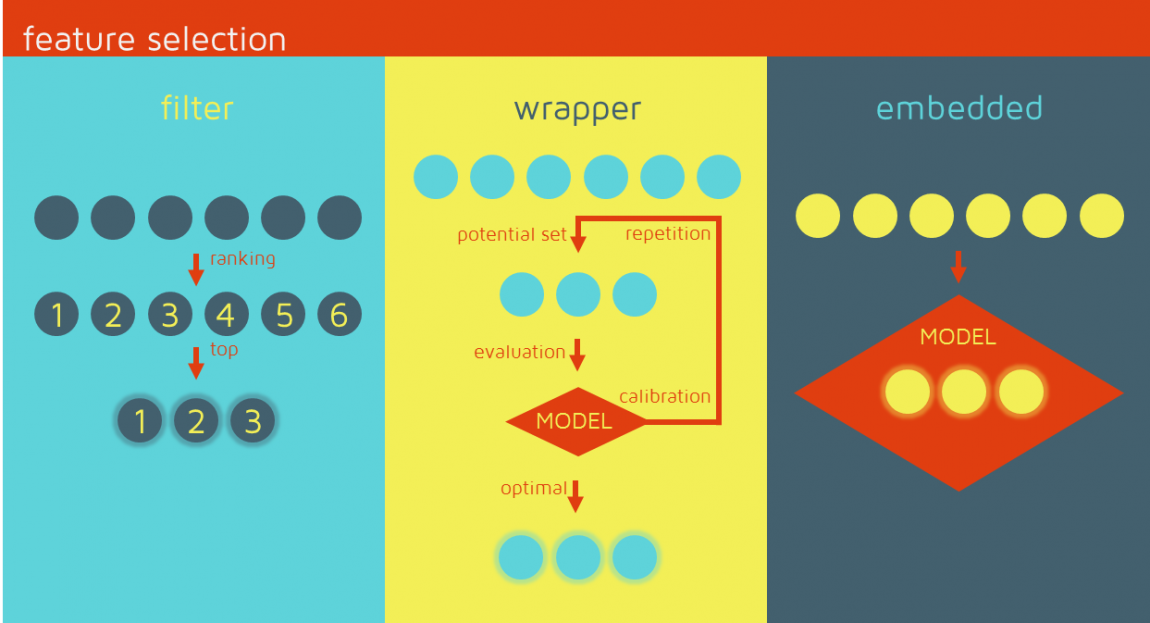
عناوین روش های انتخاب ویژگی (Feature Selection)
سه رویکرد کلی انتخاب ویژگی با توجه به ارتباط بین الگوریتمهای انتخاب ویژگی و روش یادگیری مورد استفاده قرار میگیرند. این موارد در ادامه بیان شدهاند. همراه با اسامی آنها در شکل زیر آورده شده است.
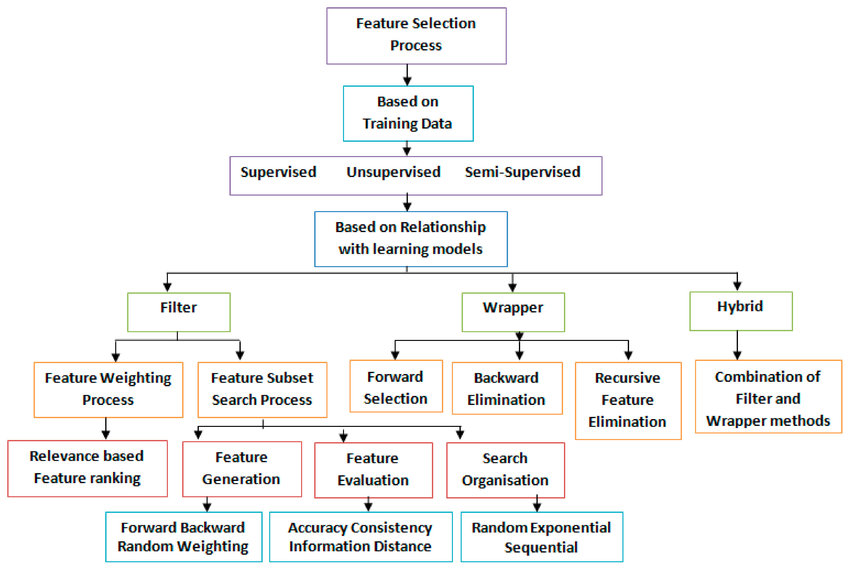
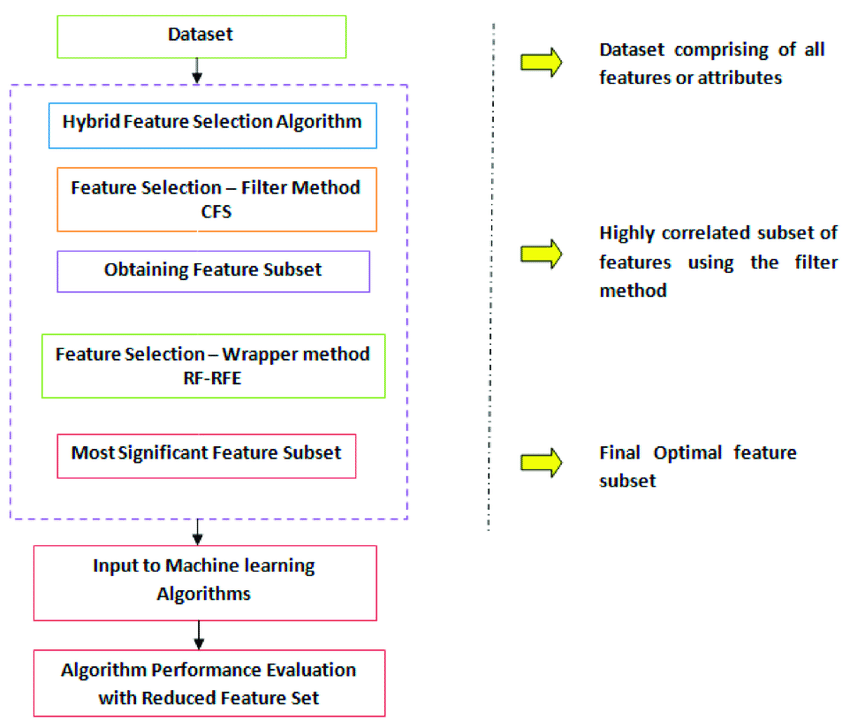
نمونه ای از بکارگیری روش های ترکیبی برای آشنایی بیشتر در شکل زیر نمایش داده شده است.
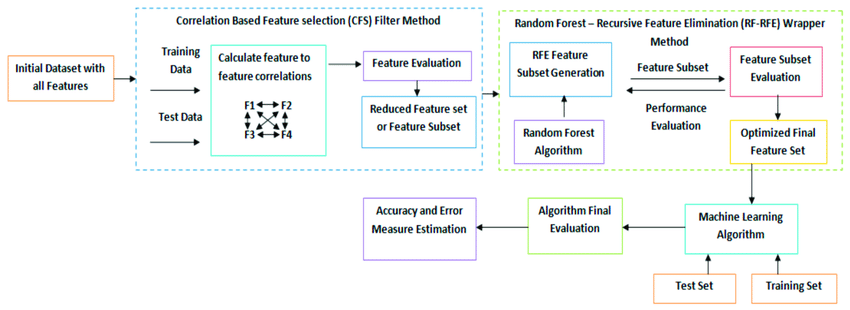
۴ انتخاب الگوریتم و روش یادگیری
گام چهارم مدلسازی داده های آماده شده است. با توجه به متدهای متفاوت، مدل های متفاوتی ساخته می شود و بهترین مدل ها از نظر متخصص داده کاوی انتخاب می شود. ستون هایی از داده ها که برای استفاده در نظر گرفته شده اند را میتوان با ایجاد یک ساختار داده کاوی (Mining Structure)، تعریف نمود.
هرچند ساختار داده کاوی، به منبع داده ها مرتبط میگردد اما در واقع تا قبل از پردازش، شامل هیچ داده ای نمی شود و در هنگام پردازش نمودن ساختار داده کاوی، Analysis Services میتواند اطلاعات گردآوری شده و سایر اطلاعات آماری مورد استفاده برای آنالیز را ارائه نماید.
ضمن اینکه این اطلاعات در هر مدل داده کاوی ساختاریافته نیز مورد استفاده قرار میگیرد. پیش از پردازش ساختار و مدل، مدل داده کاوی نیز تنها یک ظرفیت خالی محسوب میشود که مشخص کننده ی ستون های مربوط به داده های ورودی، صفات یا Attribute های پیش بینی شده و پارامترهایی میباشد که نحوه ی پردازش داده ها توسط الگوریتم را معین میکند.
پردازش یک مدلِ اغلب Training یا آموزشی نامیده میشود و در واقع فرآیندی است جهت به کارگیری یک الگوریتم ریاضی خاص برای داده های یک ساختار و هدف آن، استخراج الگوها میباشد. نوع الگوهای یافت شده در روند Training به مواردی همچون انتخاب داده های Training، الگوریتم انتخاب شده و چگونگی پیکربندی الگوریتم بستگی دارد.
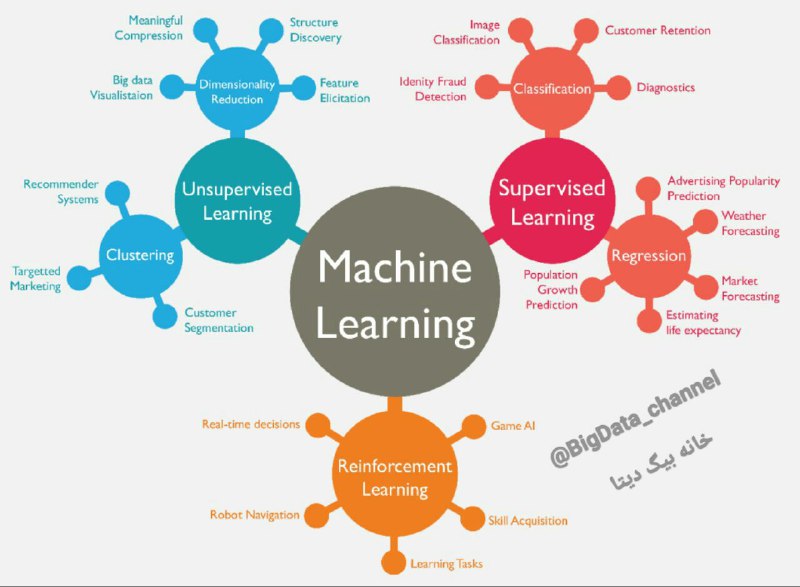
شکل زیر انواع روش های یادگیری ماشین همراه با مورد استفاده (Use Case) آن ها را نمایش میدهد.
- یادگیری تحت نظارت یا Supervised Learning
- یادگیری بدون نظارت یا Unsupervised Machine Learning
- یادگیری تقویتی یا Reinforcement Learning
یادگیری با نظارت چیست؟
در این روش، یک انسان تمام اطلاعات را تگگذاری میکند مانند: روش های رده بندی و رگرسیون. یادگیری تحت نظارت را میتوان به آموزش دانشآموزان تحت نظر و هدایت یک معلم تشبیه کرد. در اینجا، مجموعهای از دادهها را داریم که درست مثل یک معلم عمل میکنند و وظیفه تعلیم ماشین یا مدل را بر عهده دارند. زمانی که مدل مربوطه یادگیری کرد، قادر خواهد بود تا پیشبینیها و تصمیمات دقیق لازم در مورد دادههای جدید ورودی به سیستم را ارائه دهد.
یادگیری بدون نظارت چیست؟
در این شیوه، یادگیری بر روی دادههای بدون برچسب انجام میشود و سیستم خودش باید الگوهای پنهان در دادهها را کشف کند مانند: خوشه بندی و کاهش ابعاد. در این حالت، مدل از طریق مشاهدات یادگیری کرده و دستورالعملها و ساختارهای موجود در مجموعهی دادهها را کشف میکند. زمانی که مجموعه دادهای به مدل معرفی میشود. مدل با استفاده از خوشهبندی دادهها، ارتباطات و الگوهای موجود در آنها را بهصورت اتوماتیک کشف میکند. تنها کاری که چنین سیستمی نمیتواند انجام دهد، برچسبزنی روی دستههای مختلف است. برای مثال، با وجود اینکه یک سیستم یادگیری ماشین بدون نظارت قادر است دو نوع میوه سیب و انبه را به راحتی از یکدیگر سوا کند، اما نمیتواند نام آنها را بهصورت جداگانه روی هر دسته مشخص کند.
فرض کنید مجموعهای از میوههای سیب، موز و انبه را بهعنوان دادههای ورودی به سیستم یادگیری ماشین بدون نظارت دادهایم. چیزی که اتفاق میافتد، خوشهبندی این ورودیها در سه دسته جداگانه بر اساس ارتباطات و الگوهایی است که ماشین کشف کرده است. اکنون اگر داده جدیدی را به سیستم معرفی کنیم، در یکی از این سه دسته جای خواهد گرفت.
یادگیری تقویتی چیست؟
در این روش، الگوریتم با وارد شدن به چرخه آزمون و خطا، میآموزد که تصمیمات مشخصی اتخاذ کند و به این ترتیب مدام در حال آموختن باشد. یادگیری تقویتی نیز به توانایی ارتباط یک عامل با محیط خارجی به منظور دستیابی به بهترین نتیجه اطلاق میشود. مفهومی که از آن، با عنوان مدل سعی و خطا نیز یاد میشود. این عامل، بر اساس نتایج صحیح یا اشتباهی که به دست میآورد، امتیاز مثبت کسب کرده یا جریمه میشود و در نهایت، مدل قابلیت بهبود از طریق امتیازات مثبت و نتایج مطلوب کسبشده را به دست میآورد. این یادگیری و بهبود ادامه پیدا میکند تا زمانی که سیستم بتواند پیشبینیها و تصمیمات دقیق مورد نیاز در مورد دادههای جدید ورودی را ارائه دهد.
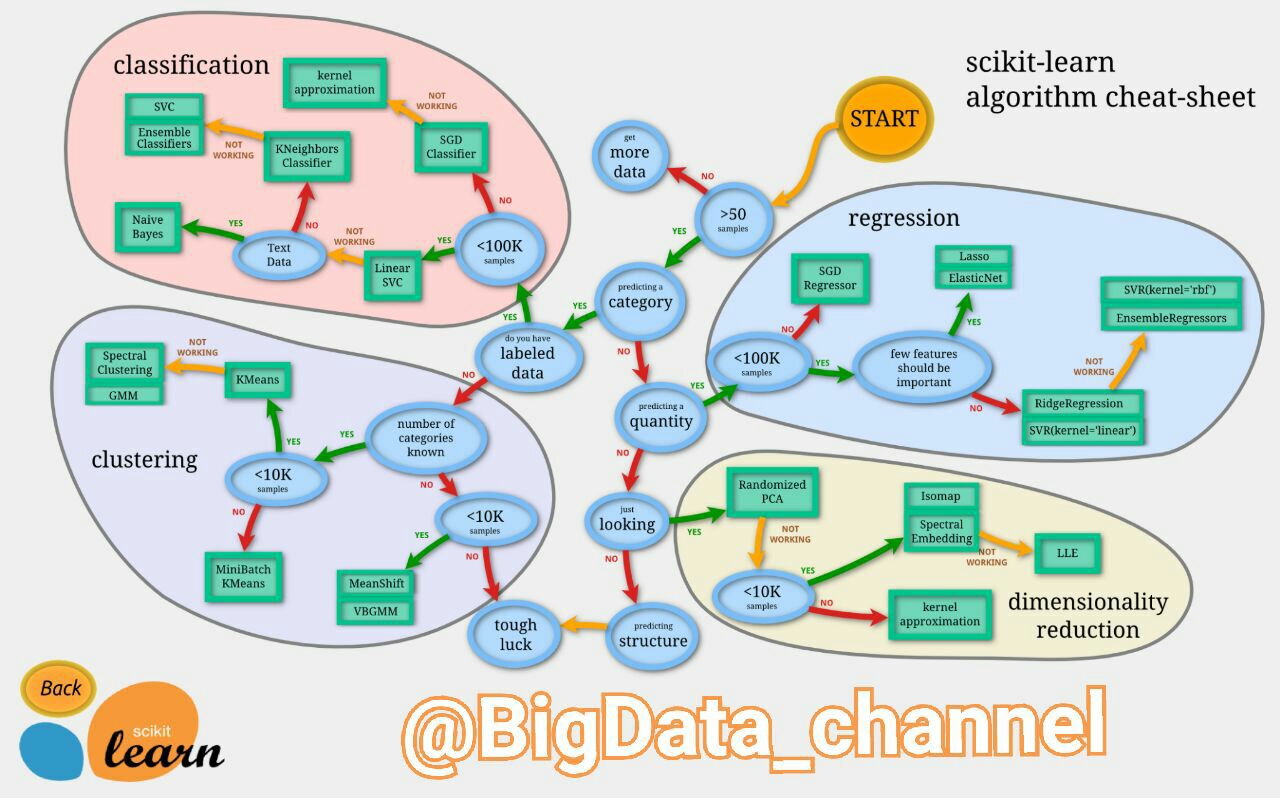
چگونه روش مناسب داده کاوی را تشخیص دهیم؟
تصویر زیر یک فلوچارتِ راهنمایِ بسیار خوب جهت تشخیص الگوریتم های داده کاوی در چهار حوزه طبقه بندی (یادگیری ماشین)، خوشه بندی، کاهش ابعاد و رگرسیون را ارائه میدهد. این تصویر راهنما، بر اساس مقدار دیتاستی که در دسترس است و نوع تحلیلی که قرار است رو آن انجام شود مسیر مطلوب را نمایش میدهد. مربع های سبز رنگ نشان دهنده نام الگوریتم ها و بیضی های آبی رنگ شرایط مورد نظر مبیاشد.
۵ آموزش مدل یادگیری ماشین براساس دادههای آموزش (Train)
برای آموزش یک مدل ، ابتدا داده ها را به ۳ بخش تقسیم می کنیم که عبارتند از “داده های آموزشی” ، “داده های اعتبارسنجی” و “داده های آزمایش یا تست”.
ما مدل سازی را با استفاده از “مجموعه داده های آموزشی” آموزش می دهیم ، پارامترها را با استفاده از “مجموعه اعتبارسنجی” تنظیم می کنید و سپس عملکرد مدل خود را بر روی “مجموعه داده های آزمون” آزمایش می کنید. نکته مهمی که باید به آن توجه داشته باشید این است که در حین آموزش طبقه بندی کننده فقط مجموعه آموزش و یا اعتبار سنجی در دسترس است. از مجموعه داده های آزمون نباید هنگام آموزش طبقه بندی استفاده شود. مجموعه تست فقط هنگام تست طبقه بندی در دسترس خواهد بود.
مجموعه آموزشی: مجموعه داده ای که برای یادگیری مدل مورد نیاز
اعتبار سنجی: مجموعه داده ای دیده نشده برای اعتبار سنجی و تنظیم بهتر پارامترهای مدل.
مجموعه تست: مجموعهای از دادههای دیده نشده برای ارزیابی عملکرد نهایی مدل
معمولا پس از حذف دیتای تست از دیتای آموزش چندین مرحله برای ساخت مدل استفاده میکنیم. به این نحو که در هر مرحله دیتای باقی مانده را به دوقسمت آموزش و اعتبار سنجی تفکیک میکنیم و کار آمورش را در اندازه کوچک تر انجام میدهیم. تا مدل نهایی ساخته شود.
۶ آزمودن یا تست مدل براساس دادههای آزمون (Test)
پس از آموزش مدل می توانیم از همان مدل آموزش دیده استفاده کنیم تا با استفاده از داده های تست یعنی داده های دیده نشده پیش بینی نهایی انجام شود. هنگامی که این کار انجام شد می توانیم یک ماتریس پراکندگی ایجاد کنیم ، این به ما می گوید که مدل ما چقدر خوب آموزش داده شده است. یک ماتریس پراکندگی دارای 4 پارامتر است که عبارتند از “مثبت صحیح” ، “منفی صحیح” ، “مثبت غلط” و “منفی غلط”. ما ترجیح می دهیم که منفی و مثبت های صحیح بیشتری را کسب کنیم تا یک الگوی دقیق تر دریافت کنیم. که در گام بعد توضیح داده شده است.
۷ ارزیابی دقت و صحت مدل
در این گام میخواهیم تعدادی از معیارهای ارزیابی الگوریتم های یادگیری ماشین را بررسی کنیم. یکی از مهمترین مراحل پس از طراحی و ساخت یک مدل یا یک الگوریتم، ارزیابی کارآیی (performance) آن است. در ادامه با روش هایی برای ارزیابی مدل آشنا میشویم.
تعریف حساسیت (sensitivity) و تشخیصپذیری (specificity):
حساسیت و تشخیصپذیری دو شاخص مهم برای ارزیابی آماری عملکرد نتایج آزمونهای طبقهبندی باینری (دودویی یا دوحالته) هستند، که در آمار به عنوان توابع طبقهبندی شناخته میشوند. زمانی که بتوان دادهها را به دو گروه مثبت و منفی تقسیم کرد، عملکرد نتایج یک آزمایش که اطلاعات را به این دو دسته تقسیم میکند با استفاده از شاخصهای حساسیت و تشخیصپذیری قابل اندازهگیری و توصیف است.
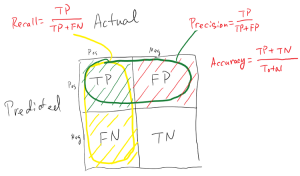
پارامتر تشخیصپذیری را نیز اصطلاحا دقت (Precision)، و حساسیت را نیز اصطلاحا صحت (Recall) مینامند.
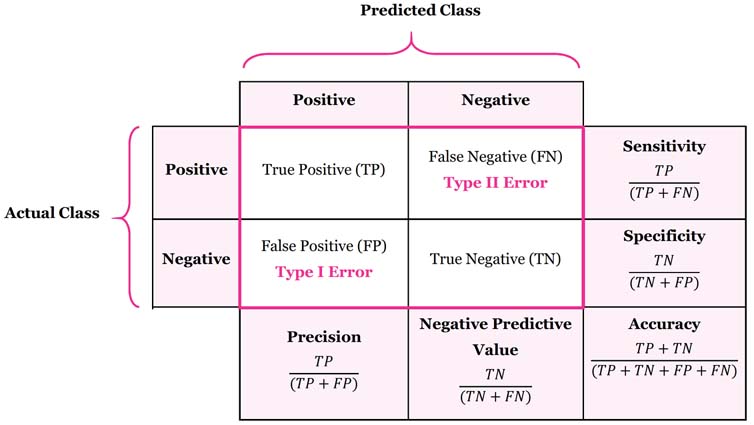
دسته بندی داده ها
۱- مثبت صحیح (True Positive)
۲- مثبت کاذب (False Positive)
۳- منفی صحیح (True Negative)
۴- منفی کاذب (False Negative)
مثال های از “مثبت های کاذب” و “منفی های کاذب”:
- بخش امنیت فرودگاه: یک “مثبت کاذب” هنگامی است که اشیاء معمولی مانند کلیدها و یا سکه ها به اشتباه اسلحه تشخیص داده می شوند (و ماشین صدای “بیپ” را ایجاد می کند)
- کنترل کیفیت: یک “مثبت کاذب” هنگامی است که محصول با کیفیت خوب، مردود می شود و یک “منفی کاذب” هنگامی است که محصول بی کیفیت مورد قبول واقع می شود
- نرم افزار ضد ویروس: یک “مثبت کاذب” هنگامی است که یک فایل عادی بعنوان یک ویروس شناخته می شود
- آزمایش پزشکی: گرفتن آزمایش های ارزان قیمت و بررسی آن توسط تعداد زیادی از پزشکان می تواند مثبتهای کاذب زیادی به بار آورد (یعنی جواب تست بگوید که بیمار هستید در حالی که چنین نیست)، و سپس خواسته شود که دوباره آزمایش های با دقت بیشتر بگیرید.
کدام معیارها باید بهتر باشند:
بدیهی است معیار های که تشخیص درست را نمایش میدهند باید بهتر باشند که در زیر با رنگ سبز نشان داده شده است.
۱- مثبت صحیح (True Positive) = درست شناسایی شده است.
۲- مثبت کاذب (False Positive) = اشتباه شناسایی شده است (خطای نوع یک در انجام آزمون).
۳- منفی صحیح (True Negative) = به درستی رد شد.
۴- منفی کاذب (False Negative) = اشتباه رد شد (خطای نوع دوم در انجام آزمون).
ماتریس اختلاط یا درهم ريختگی (confusion matrix) :
به ماتریسی گفته میشود که در آن عملکرد الگوریتمهای مربوطه را نشان میدهند. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. معمولاً به کاربرد این ماتریس در الگوریتمهای بدون ناظر ماتریس تطابق می گویند. هر ستون از ماتریس، نمونهای از مقدار پیشبینی شده را نشان میدهد. در صورتی که هر سطر نمونهای واقعی (درست) را در بر دارد. اسم این ماتریس نیز از آنجا بدست میآید که امکان این را آسانتر اشتباه و تداخل بین نتایج را مشاهده کرد.
در حوزه هوش مصنوعی، ماتریس در هم ریختگی به ماتریسی گفته میشود که در آن عملکرد الگوریتمهای مربوطه را نشان میدهند. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. معمولاً به کاربرد این ماتریس در الگوریتمهای بدون ناظر ماتریس تطابق میگویند. هر ستون از ماتریس، نمونهای از مقدار پیشبینیشده را نشان میدهد. درصورتیکه هر سطر نمونهای واقعی (درست) را در بر دارد. اسم این ماتریس نیز ازآنجا بدست میآید که امکان این را آسانتر اشتباه و تداخل بین نتایج را مشاهده کرد. در خارج از هوش مصنوعی این ماتریس معمولاً ماتریس پیشایندی (contingency matrix) یا ماتریس خطا (error matrix) نامیده میشود.
درنهایت نتایج بهدستآمده مورد ارزیابی قرارگرفته و برای موارد مختلف تفسیر و استفاده میشود. در ارزیابی معمولا معیارهای زیر متصور است.
- تشکیل ماتریس اختلاط (confusion matrix)
- دقت (Accuracy)
- صحت (Precision)
- Recall: زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود.
- F1 Score
- MCC: پارامتر دیگری است که برای ارزیابی کارایی الگوریتمهای یادگیری ماشین از آن استفاده میشود. این پارامتر بیانگر کیفیت کلاسبندی برای یک مجموعه باینری میباشد.
دقت (Accuracy):
به طور کلی، دقت به این معناست که مدل تا چه اندازه خروجی را درست پیشبینی میکند. با نگاه کردن به دقت ، بلافاصله میتوان دریافت که آیا مدل درست آموزش دیده است یا خیر و کارآیی آن به طور کلی چگونه است. اما این معیار اطلاعات جزئی در مورد کارآیی مدل ارائه نمیدهد.
Accuracy = (TP+TN) / (TP+FN+FP+TN)
صحت (Precision) :
وقتی که مدل نتیجه را مثبت (positive) پیشبینی میکند، این نتیجه تا چه اندازه درست است؟ زمانی که ارزش false positives بالا باشد، معیار صحت، معیار مناسبی خواهد بود. فرض کنید، مدلی برای تشخیص سرطان داشته باشیم و این مدل Precision پایینی داشته باشد. نتیجه این امر این است که این مدل، بیماری بسیاری از افراد را به اشتباه سرطان تشخیص میدهد. نتیجه این امر استرس زیاد، آزمایشهای فراوان و هزینههای گزافی را برای بیمار به دنبال خواهد داشت.
در واقع، «حساسیت» معیاری است که مشخص میکند دستهبند، به چه اندازه در تشخیص تمام افراد مبتلا به بیماری موفق بودهاست. همانگونه که از رابطه فوق مشخص است، تعداد افراد سالمی که توسط دستهبند به اشتباه به عنوان فرد بیمار تشخیص داده شدهاند، هیچ تاثیری در محاسبه این پارامتر ندارد و در واقع زمانی که پژوشهگر از این پارامتر به عنوان پارامتر ارزیابی برای دستهبند خود استفاده میکند، هدفش دستیابی به نهایت دقت در تشخیص نمونههای کلاس مثبت است.
در واقع نسبت مقداری موارد صحیح طبقهبندیشده توسط الگوریتم از یک کلاس مشخص، به کل تعداد مواردی که الگوریتم چه بهصورت صحیح و چه بهصورت غلط، در آن کلاس طبقهبندی کرده است که بهصورت زیر محاسبه میشود:
Precision =TP / (TP+FP)
فراخوانی یا حساسیت یا Recall :
در نقطه مقابل این پارامتر، ممکن است در مواقعی دقت تشخیص کلاس منفی حائز اهمیت باشد. از متداولترین پارامترها که معمولا در کنار حساسیت بررسی میشود، پارامتر خاصیت (Specificity)، است که به آن «نرخ پاسخهای منفی درست» (True Negative Rate) نیز میگویند. خاصیت به معنی نسبتی از موارد منفی است که آزمایش آنها را به درستی به عنوان نمونه منفی تشخیص داده است. این پارامتر به صورت زیر محاسبه میشود.
زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود. فرض کنیم مدلی برای تشخیص بیماری کشنده ابولا داشته باشیم. اگر این مدل Recall پایینی داشته باشد چه اتفاقی خواهد افتاد؟ این مدل افراد زیادی که آلوده به این بیماری کشنده هستند را سالم در نظر میگیرد و این فاجعه است. نسبت مقداری موارد صحیح طبقهبندی شده توسط الگوریتم از یک کلاس به تعداد موارد حاضر در کلاس مذکور که بهصورت زیر محاسبه میشود:
Recall = Sensitivity = (TPR) = TP / (TP+FN)
F1 Score یا F-measure
معیار F1، یک معیار مناسب برای ارزیابی دقت یک آزمایش است. این معیار Precision و Recall را با هم در نظر میگیرد. معیار F1 در بهترین حالت، یک و در بدترین حالت صفر است.
F-measure= 2 * (Recall * Precision) / (Recall + Precision)
معیار (Specificity):
در نقطه مقابل این پارامتر، ممکن است در مواقعی دقت تشخیص کلاس منفی حائز اهمیت باشد. از متداولترین پارامترها که معمولا در کنار حساسیت بررسی میشود، پارامتر خاصیت (Specificity)، است که به آن «نرخ پاسخهای منفی درست» (True Negative Rate) نیز میگویند. خاصیت به معنی نسبتی از موارد منفی است که آزمایش آنها را به درستی به عنوان نمونه منفی تشخیص داده است. این پارامتر به صورت زیر محاسبه میشود.
Specificity (TNR) = TN / (TN+FP)
MCC:
پارامتر دیگری است که برای ارزیابی کارایی الگوریتمهای یادگیری ماشین از آن استفاده میشود. این پارامتر بیانگر کیفیت کلاسبندی برای یک مجموعه باینری میباشد. (MCC (Matthews correlation coefficient، سنجهای است که بیانگر بستگی مابین مقادیر مشاهده شده از کلاس باینری و مقادیر پیشبینی شده از آن میباشد. مقادیر مورد انتظار برای این کمیت در بازه 1- و 1 متغیر میباشد. مقدار 1+، نشان دهنده پیشبینی دقیق و بدون خطای الگوریتم یادگیر از کلاس باینری میباشد. مقدار 0، نشان دهنده پیشبینی تصادفی الگوریتم یادگیر از کلاس باینری میباشد. مقدار 1-، نشان دهنده عدم تطابق کامل مابین موارد پیشبینی شده از کلاس باینری و موارد مشاهده شده از آن میباشد.
8 بکارگیری مدل در محیط عملیاتی
ادامه مطلب به زودی…
9 ارزیابی نهایی مدل در محیط واقعی
پس از تجزیه و تحلیل داده و خلق بینش و بصیرت ، زمان آن رسیده است که این خروجی ارایه و توزیع گردد . ارایه نتایج به افراد ذیصلاح ، در زمان مناسب و با بهره گیری از روش های مدرن شرایطی را فراهم می آورد که بتوان قبل از تصمیم گیری به انجام هر کاری از مخزن با ارزش بینش استفاده کرد . مخزنی که اگر به درستی پر گردد و به درستی از آن برداشت شود می تواند بهبود عملکرد را در یک سازمان به دنبال داشته باشد . امروزه از روش های مختلفی جهت ارایه داده استفاده می گردد . در این راستا ابزارهای متعددی نیز طراحی و پیاده سازی شده است که می توان از آنها به منظور ارایه و توزیع بینش استفاده کرد.
10 کسب بینش ناشی از تحلیلهای دادهمحور
در نهایت می بایست از بینش تولید شده جهت تصمیم گیری استفاده کرد و تصمیماتی گرفت که کسب و کار را متحول نماید . بدیهی است هر گونه اقدام می بایست به پشتوانه این چنین تصمیماتی انجام شود تا بتوان مزایای ملموس و غیرملموس تصمیم گیری مبتنی بر داده را در کسب و کار خود مشاهده کرد . به جرات می توان گفت با ارزش ترین بخش کار مشاهده عینی اثرات تحلیل داده و تولید بینش و بصیرت در تصمیم گیری های استراتژیک و متعاقب آن اقدامات مرتبط با آن می باشد .
ابزارهای یادگیری ماشین:
ابزارهای متفاوتی در رابطه با یادگیری ماشین تاکنون تولید و توسعه یافته است این ابزار ها در دسته های زیر قابل تقسیم بندی هستند:
۱ ابزار های برچسب گذاری داده
۲ ابزارهای نسخه گذاری داده ها
۳ ابزار های مقیاس پذیری سخت افزار
۴ ابزارهای طراحی مدل
۵ ابزارهای یادگیری مدل
۶ ابزارهای ارزیابی مدل
۷ ابزارهای نسخه گذاری مدل
۸ ابزارهای بکارگیری مدل
۹ ابزارهای مانیتور کردن و پیش بینی
تفاوت یادگیری ماشین با یادگیری عمیق:
تفاوت عمده بین یادگیری ماشین و روش مدرن آن یادگیری عمیق وجود دارد. عملاً در یادگیری عمیق جزئیات کوچک در یک فرایند یادگیری مورد توجه است. در یادگیری عمیق به خاطر تکرار زیادِ مراحلِ یادگیری جزئیات یک الگو حتی شناخته می شود. به همین دلیل یادگیری عمیق با میزان اختلاف قابل توجهی در دقت نسبت به یادگیری ماشین دقیقتر عمل می کند. البته این نکته یک نکته کلی است و لزوما برای هر نوع فرایند یادگیری یا هر نوع مجموعه داده ای نمیتوان به صورت قطعی این تفاوت را مطرح نمود. لیکن در موارد زیادی یادگیری عمیق از لحاظ دقت و صحت نسبت به روش های یادگیری سنتی ارجحیت دارد. البته این نکته به این معنی نیست که در همه موارد یادگیری عمیق می تواند گزینه ی مناسب باشد.
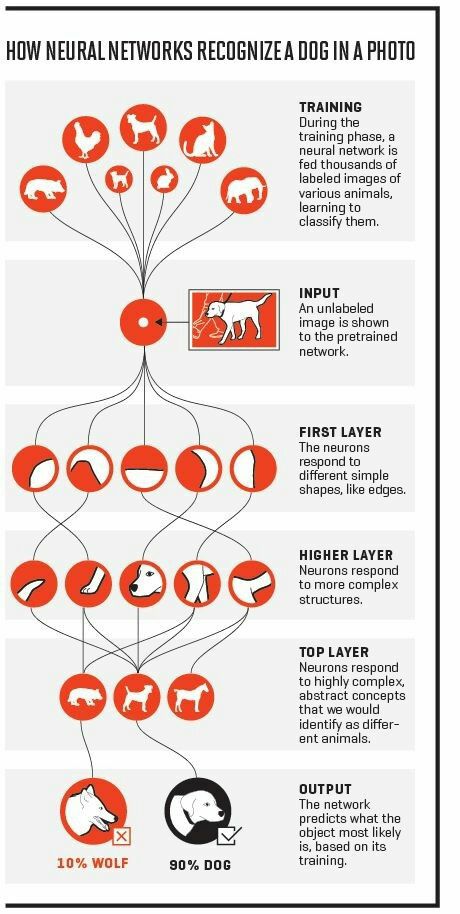
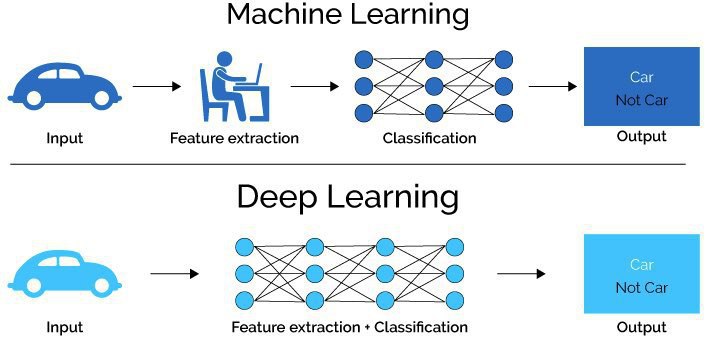
یکی دیگر از اشکالات بزرگ یادگیری عمیق نیازمندی آن به مجموعه داده های بسیار زیاد و برچسب خورده به صورت خاص است که همین دلیل موجب شده است که در موارد زیادی یادگیری عمیق از گزینه اصلی روی میز حذف شود.ضمن آنکه باید در نظر داشت که ما در دنیا با مسائلی روبرو هستیم که به راحتی توسط روشهای یادگیری سنتی قابل حل هستند و انجام این دسته کارها یا راه حل ها با تکنیک های یادگیری عمیق هدر دادن منابع می باشد چرا که به طور قطع یادگیری عمیق فرایند پچیدهتری نسبت به یادگیری سنتی دارد و این موضوع موجب می شود که فرایند یادگیری در یادگیری عمیق بسیار طولانی تر از یادگیری به روش کلاسیک یا سنتی باشد. ولی نکته با اهمیت دیگری وجود دارد و آن این است که در یادگیری عمیق استخراج ویژگی ها به صورت خودکار انجام می شود و این موضوع را میتوان مهم ترین تفاوت یادگیری عمیق با یادگیری ماشین دانست. یکی از قابلیت های اصلی مدل های مبتنی بر یادگیری عمیق Automatic Feature Extraction یا مفهومی به نام Feature Learning هست. به صورت کلی در روش های مبتنی بر یادگیری عمیق دو گام Feature Extraction و Classification توسط مدل و لایه های پنهان شبکه عصبی انجام میشود
تشخیص شی: یکی از کاربردهای بسیار مهم یادگیری عمیق تشخیص تصاویر است. تشخیص تصاویر می تواند حوزههای مختلفی را شامل شود. شود تشخیص اشیا و تشخیص چهره نمونههایی از شناخت شده ترین کاربردها در این این حوزه است. امروزه با تکنیکهای یادگیری عمیق این روش ها به دقت های فزایندهای رسیدهاند.

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 20951
برچسبAutomatic classification Feature Learning Feature Selection ma ارزیابی ارزیابی مدل یادگیری استخراج ویژگی انتخاب ویژگی بدون ناظر تشخیص شی تفاوت یادگیری ماشین داده کاوی رده بندی روش های یادگیری ماشین شبکه عصبی کاربردهای یادگیری ماشین گام های یادگیری ماشین مدل های یادگیری مراحل یادگیری ماشین یادگیری با ناظر یادگیری عمیق یادگیری ماشین یادگیری ماشین چیست
نوشته های مرتبط






همچنین ببینید

ایجاد انبارداده(DWH)، دریاچه داده(Data Lake)، بازار داده(Data Mart) و مکعب داده(Data Cube)
داده ها با توجه به حجم و کاربرد آنها در منطق هاي مختلف ذخيره سازي …
روش های داده کاوی (Data Mining) به زبان ساده
امروزه داده کاوی به عنوان پایه و مبنای تصمیم های مهم محسوب میشود. داده کاوی …
یک دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام من موضوع پایان نامه م در مورد تشخیص سکته قلبی با استفاده از روش های یادگیری عمیق هست ولی متاسفانه مدل lstm خیلی در این مورد overfitting داره توی نت گشتم گفته بودن که باید داده ها رو پیش پردازش کنی ولی در این مورد نمی دونم چکار باید بکنم ممنون میشم در این مورد راهنماییم کنید خیلی کارم گیره