خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
کتابخانه پایتون برای وب اسکرپ (web scraping)
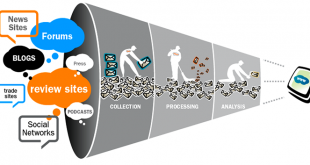
در این مبحث به کتابخانه ی با ارزش پایتون وب اسکرپ (web scraping) به منظور جمع آوری اطلاعات از یک صفحه وب خواهیم پرداخت. همگی میدانیم که یکی از منابع اصلی داده در دنیا امروز، متون و محتوای موجود در سایتهای اینترنتی است. اسکرپ عبارت است از جمع آوری داده از طریق یک برنامه که درخواست خود را به یک سرویس دهنده وب ارسال میکند و پس از دریافت پاسخ، داده بدست آمده را تحلیل و اطلاعات مورد نیاز را استخراج می کند. تولید وب اسکرپ ها به قبل از بوجود آمدن API ها برمیگردد. در آن زمان ناگزیر برای به اشتراک گذاری دادهها بین سرویسها از وب اسکرپینگ استفاده میشد. ولی الان کاربری آن کمی تغییر کرده و به عنوان یکی از مولفه های جمع آوری اطلاعات شناخته می شوند و امروزه در فضای وب شاهد آن هستیم که وب اسکرپر ها پا به پای خزش گر ها به جمع آوری اطلاعات مشغول هستند و از قبل میدانیم که جمع آوری اطلاعات جزئی از ارکان کلان داده محسوب میشود.

نکته: در زبان فارسی گاهی وب اسکرپ را به وب تراش یا وب خراش نیز ترجمه کرده اند.
در این مقاله فرض کردهایم که شما آشنایی کامل با پایتون دارید. در غیر اینصورت لینک های زیر را قبل از خواندن ادامه مقاله مطالعه کنید.
- http://python.coderz.ir/
- https://maktabkhooneh.org/course/66/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%D9%85%D9%82%D8%AF%D9%85%D8%A7%D8%AA%DB%8C-Python/
تذکر بسیار مهم: توجه داشته داشته باشید بعضی از سایتها اجازه اسکرپت کردن را به شما نمی دهند و فضولی کردن در این سایت ها پیگرد قانونی دارد، پس مواظب باشید که چه سایتی را اسکرپت می کنید و برای خودتان دردسر درست نکنید.
معرفی یک کتابخانه پایتون وب اسکرپ (web scraping)
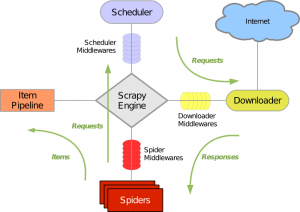
زبان برنامه نویسی پایتون کتابخانههای قدرتمندی در رابطه با این موضوع دارد، که در این مقاله به معرفی یکی از این کتابخانهها می پردازیم. یکی از کتابخانه های معروف پایتون در خواندن و استخراج اطلاعات مفید از صفحات وب ، کتابخانه Scrapy است. Scrapy یک زیرساخت برنامه کاربردی برای خزش وب سایتها و استخراج دادههای مختلف با هدف داده کاوی، پردازش اطلاعات و… است. این کتابخانه علاوه بر توانایی خزش وب، امکان استخراج دادهها ازطریق واسط های برنامه نویسی سرویس های اینترنتی نظیر وب سرویس های شرکت آمازون را هم دارد.
کتابخانه Scrapy به چند دلیل زیر برای استخراج متون و جمع آوری اطلاعات، مناسب است:
- اول اینکه یک کتابخانه کامل برای خزش در وب (Crawling) است و با قابلیت دنبال کردن لینک های موجود در هر صفحه دارد.
- دوم اینکه برای پردازش موازی و همزمان صفحات مختلف و ایجاد خط تولید (pipeline) امکانات مناسب و ساده ای برای افزایش سرعت دارد.
- سوم اینکه کار با آن بسیار ساده است و شما می توانید در چند خط ، یک خزنده وب کامل بسازید.
نصب Scrapy
مشابه سایر برنامه های پایتون کافیست با دستور
pip install scrapy
این کتابخانه را نصب کنید . برای اجرای آن نیاز به نصب بعضی کتابخانه ها و نرم افزارهای موردنیاز آنرا هم داریم که اکثر آنها با دستور فوق به صورت اتومات نصب خواهند شد و تنها چیزی که باقی می ماند نرم افزار PyWin32 است که بعضی امکانات خاص ویندوز را برای برنامه های پایتون، فراهم می کند. آنرا از این آدرس، دانلود و نصب کنید (برای اکثر شما نسخه ۳۲ بیتی نرم افزار مناسب خواهد بود) . اکنون آماده استخراج اطلاعات هستید.
پس از نصب کتابخانه با استفاده از ابزاری که کتابخانه در اختیار ما قرار میدهد میتوانیم برنامه ی خود را اجرا کنیم. برنامه ساده زیر بخشی از اطلاعات بخش موبایل سایت دیجی کالا را استخراج می کند.
import scrapy import json class DigiKalaMobileSpider(scrapy.Spider): name = "DigiMobile" allowed_domains = "digikala.com" start_urls = ["http://search.digikala.com/api/search/?category=c1&pageno=1&sortBy=2&status=2"] def parse(self, response): print"######################parse#########################" ds = json.loads(response.body, 'utf-8') for item in ds['hits']['hits']: print item['_source']['EnTitle'],item['_source']['MaxPrice']
متغیر start_urls دربرنامه، مسیری را که خزش از آنجا شروع میشود مشخص می کند. پس از اینکه برنامه اجرا شد و اتصال با سایت برقرار گردید، شیء response که حاوی محتوای بدست آمده است بعنوان ورودی به تابع parse منتقل می شود. از آنجا که خروجی بدست آمده در قالب json بازگردانده می شود. با استفاده از کتابخانه json خروجی مورد نظر را میتوان بدست آورد. داده بدست آمده در متغیر ds (Data Set) ذخیره می شود. با استفاده از یک حلقه ساده، داده موجود در ds را در خروجی چاپ می کنیم.
برای اجرا کردن برنامه فوق در خط فرمان سیستم عامل ویندوز لازم است مسیر C:\Python27\Scripts را به متغیر محیطی Path اضافه کنید. سپس دستور زیر را در محل ذخیره شدن فایل برنامه وارد کنید.
scrapy runspider DigikalaMobileSpider.py
خروجی برنامه فوق بصورت زیر است:
######################parse######## Jabra Wave Bluetooth Handsfree 1660 Sony Xperia Z1 Magnetic Charging Do Jabra Mini Bluetooth Headset 159000 Jabra Supreme Plus Handsfree 394000 Portable Mini 16 LEDs Flash And Fil Yunteng YT-228 Monopod Holder Tripo Yunteng YT-188 Monopod 190000 Adata PT100 10000mAh Power Bank 650 Samsung Galaxy SIII I9300 Battery 4 Totu Bumper For Apple iPhone 6 350 Leather Cover For Apple iPhone 6 Pl BlackBerry Leap Mobile Phone 545000 MiPOW VoxTube 500 Handsfree 1550000 Apple iPhone 5/5s Ozaki Jelly Cove Jabra Sport Pulse Handsfree 3990000 Samsung Model HS330 Handsfree 45000 HuntKey 10W Car Charger 235000 Jabra Storm Bluetooth Headset 22900 Philips SHB1100 Handsfree 890000 Philips Toch Screen cleaner svc3250 HuntKey Carmate D203 USB Car Charge MHL To HDMI Media Adaptor 1.8m 2900 Rock Royce Cover For Apple iPhone 6 Philips SHB 1200 Handsfree 890000
در انتهای مبحث پایتون وب اسکرپ (web scraping) کتاب زیر را از انتشارات معروف اورالی در باب این موضوع معرفی می کنیم.

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 10989
برچسبpaython web scraping scrapy اسکرایپ اسکرپر چیست پایتون scraping پایتون web scraping پایتون اسکرپ پایتون اسکرپینگ پایتون وب اسکرپ جمع آوری اطلاعات از صفحه وب کتاب خانه scrapy مثال وب اسکرایپ وب اسکرپ وب اسکرپینگ وب تراش وب خراش