 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
نصب، راه اندازی و پیکربندی اسپارک (Spark) در ویندوز
بخشی عمده ای از مطالب این قسمت را از وبلاگ دوست محترمم آقای نعمت پور با کمی ا اصلاح و تغییر در این پست کپی نموده ام.
نصب اسپارک در ویندوز:
1. نصب جاوا-برای نصب اسپارک در ویندوز باید ابتدا نسخه 7 یا 8(ترجیحا) jdk-8u92-windows-x64.exe را نصب کنید. در صفحه http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html سایت اوراکل با پروکسی یا فیلترشکن میتونید دانلود کنید. JAVA_HOME را در environment variable ست کنید.
2.اسپارک- فایل فشرده اسپارک را از http://spark.apache.org/downloads.html دانلود کنید(Choose a package type: Pre-built for hadoop 2.6). فایل فشرده را توسط winrar یا برنامه فشرده سازی دیگر extract کنید.
3. اجرا-cmd را باز کنید، برای مثال من اسپارک را در مسیر F:\temp\spark-1.6.1-bin-hadoop2.6 اکسترکت کردم و در cmd ، مسیر جاری را این مسیر قرار میدهم و bin\spark-shell.cmd را اجرا می کنم.
F:\temp\spark-1.6.1-bin-hadoop2.6>bin\spark-shell.cmd
چند لحظه صبر کنید، ابتدای بارگیری کتابخانه ها خطایی مبنی بر اینکه winutils.exe را در مسیر bin هادوپ پیدا نمیکنم رخ میدهد که برای شما در اجرای اسپارک برای یادگیری مشکل ایجاد نمیکند.
نکته:
اگر خواستید هادوپ را نصب کنید و از HDFS استفاده کنید باید winutils.exe را دانلود کرده و در پوشه bin هادوپ کپی کنید. برای خواندن فایل متنی در ویندوز: val l=sc.textFile(“E:\\my projects\\datasets\\ds1.txt”) دابل بک اسلش بخاطر اسکیپ سیمبول است. مشکل خاص دیگری ایجاد نخواهد شد مگر اینکه در نصب جاوا مشکل داشته باشید یا اینکه متغیر JAVA_HOME را در environment variable ست نکرده باشید!
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Visits: 3540
برچسبSpark اسپارک پردازش موازی توزیع شده نصب اسپارک در ویندوز نصب و راه اندازی
نوشته های مرتبط


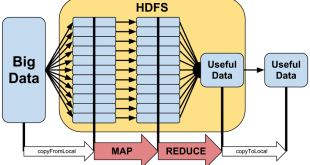
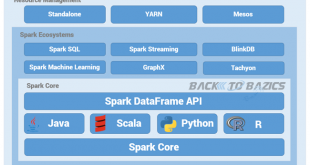
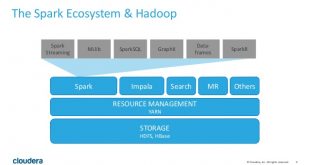
همچنین ببینید
معرفی کامل صف پیشرفته کافکا (Kafka) همراه با نصب و راه اندازی در داکر
در مباحث قبل به ActiveMQ به عنوان یک سیستم صف و کارگزار پیام پرداختیم. آپاچی …

درآمدی بر بانک های اطلاعاتی غیر رابطه ای (NoSql)
پایگاه داده های NoSQL ها در واقع همان بانک های اطلاعاتی غیر رابطه ای و توزیع …
