 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
فایل دیکشنری فارسی با فرمت csv (قابل بارگذاری بر روی تمامی دیتابیس ها)
فایل دیکشنری با فرمت csv:
معمولا خیلی ار محققان برای برخی از مباحث تحلیل به فرهنگ لغات نیاز پیدا میکنند. به همین منظور یک فایل دیکشنری فارسی به انگلیسی (و حتما انگلیسی به فارسی) با بیش از هفتاد هزار لغت برای استفاده پژوهشگران آماده کرده ایم. جهت قابل استفاده بودن در همه ساختارهای داده ای و پایگاه داده های مختلف این فایل دیکشنری به فرمت csv ارائه شده است. جهت بهم نخوردن یونیکد فایل پیشنهاد میشود که این فایل را با برنامه notepad++ باز نمایید. در ادامه میتوانید فایل دیکشنری مذکور را دانلود کنید.
دانلود فایل دیکشنری با فرمت csv (قابل بارگذاری بر روی تمامی دیتابیس ها)

توضیح در مورد فایل های CSV:
مخفف عبارت «Comma Separated Values» و به معنای «مقادیر جدا شده با ویرگول» است. اینگونه فایلها در واقع نوعی فایل خام متنی هستند که شامل لیستی از دادهها میشوند. به صورت رایج فایلهای یاد شده برای جابهجایی دادهها بین نرمافزارهای متفاوت مورد استفاده قرار میگیرند. برای مثال، پایگاههای داده و نرمافزارهای مربوط به مدیریت مخاطبین معمولا از فایلهای CSV پشتیبانی میکنند. در برخی جاها از این فایل با نام «Character Separated Values» (مقادیر جدا شده با کاراکتر خاص) یا «Comma Delimited» (محدود شده با ویرگول) نیز یاد میشود. این فایلها معمولا از ویرگول برای جداسازی یا محدودسازی دادهها استفاده میکنند، ولی در برخی اوقات از سایر کاراکترها نظیر نقطه ویرگول نیز استفاده میشود. هدف اصلی این فایلها این است که بتوانید اطلاعات خود را از یک نرمافزار وارد یک فایل CSV کرده و سپس آن فایل CSV را در یک نرمافزار دیگر مورد استفاده قرار دهید.
برای CSV هیچ استاندارد واحدی وجود ندارد. حتی RFC 4180 هم به صورت Informational ارائه شده است یعنی استاندارد واحدی را مشخص نکرده و صرفا قالبی که در بیشتر پیادهسازیها مورد استفاده قرار گرفته را معرفی میکند. این یعنی اینکه CSV که از اکسل میگیرید لزوما با CSV که ممکن است از Gmail Contacts یا MySQL بگیرید یکی نخواهد بود. مثلا در یکی از header استفاده شده و در دیگری نه و یا مقدار فیلدها در یکی با double qution محصور شده و در دیگری نه. بدترین قسمت این ماجرا این است که در بیشتر پیاده سازی هیچ اهمیتی به Enocding داده نشده و فرض همه به ASCII بودن فایل است و بدتر از این از آنجا که به نظر میرسد CSV از Byte Order استفاده نمیکند،در نتیجه فایل آن حتما باید تک بایتی باشد مثل ASCII و UTF-8 و باز هم در نتیجه نمیتوان از قالبهای ۲ بایتی (یعنی هر کاراکتر در ۲ بایت ذخیره شود) مثل فایلهای متنی یونیکد ویندوز در آن استفاده کرد. البته در حال تک بایتی هم Encoding را خود استفاده کننده باید بفهمد و نوع Encoding مورد استفاده از هیچ جای یک فایل CSV قابل استخراج نیست. در بعضی جاهای خاص مثل وقتی که قرار است فایل CSV به عنوان یک MIME TYPE به اسم text/csv رد و بدل شود یک header به نام charset هست که میتوان Encoding را در آن معرفی نمود. فراموش نشود که این header خارج از خود فایل CSV قرار دارد.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 52825
برچسبcsv data set dataset dic sql پایگاه داده دیکشنری دانلود رایگان فایل دیکشنری دانلود فایل دیکشنری دیتا ست دیتابیس دیکشنری دیتاست فایل دیکشنری فرهنگ لغت مجموعه داده
نوشته های مرتبط
















همچنین ببینید
دیتاست بیش از دویست و هفتاد هزار لینک فایل متنی
دیتاست فایل متنی: در این پست مجموعه داده ای شامل بر دویست و هفتاد هزار …
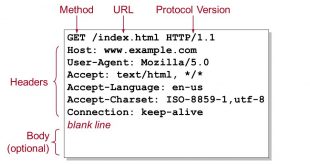
انواع User Agent برای خزش در وب به صورت مودبانه (politeness)
پروتکل HTTP یک پروتکل درخواست و پاسخ است که بین یک کلاینت و یک سرور …
5 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

بررسی شد لینک مشکلی نداره
لینک دانلود خرابه.
فقط انگلیسی به فارسیه. فارسی به انگلیسی ندارین؟
با سلام
باید روی ویرایشگراتان UTF8 فعال باشد
سلام… نوشته های فارسی بهم ریخته هستند.