 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
درخت تصمیم چیست و چگونه از الگوريتم هاي آن وضعیت آینده را پیشبینی کنیم
اگر میخواهید تا تصمیم پیچیدهای بگیرید و تصمیم دارید تا مسائل را برای خودتان به بخشهای کوچکتری تقسیم کرده تا به شکل بهتری قادر به حل آنها شوید، میتوانید از درخت تصمیم استفاده کنید. درخت تصمیم نقشهای از نتایج احتمالی یکسری از انتخابها متوالی به منظور کوچک شدن ونهایتا حل صورت مسئله می باشد.
عناوين مطالب: '
مقدمه اي بر درخت تصميم
یکی از پرکاربردترین الگوریتمهای دادهکاوی، الگوریتم درخت تصمیم است. در دادهکاوی، درخت تصمیم یک مدل پیشبینی کننده است به طوری که میتواند برای هر دو مدل رگرسیون و طبقهای مورد استفاده قرار گیرد. زمانی که درخت برای کارهای طبقهبندی استفاده میشود، به عنوان درخت طبقهبندی (Classification Tree) شناخته میشود و هنگامی که برای فعالیتهای رگرسیونی به کار میرود درخت رگرسیون (Regression Decision Tree)نامیده میشود.
درخت تصمیم چگونه کار میکند؟
کسانی که بازی بیست سوالی انجام داده اند به سادگی میتوانند درخت تصمیم گیری را درک کنند. در این بازی یک نفر موضوع خاصی را در ذهن خود در نظر میگیرد و شخص دیگری سعی میکند با پرسش تعدادی سوال که جواب آنها بلی و خیر است موضوع مورد نظر شخص اول را شناسایی کند. در درخت تصمیم(decision tree ) نیز تعدادی پرسش وجود دارد و با مشخص شدن پاسخ هر سوال یک سوال دیگر پرسیده میشود. اگر سوالها درست و سنجیده پرسیده شوند، تعداد کمی از پرسشها برای پیش بینی رکورد جدید کافی می باشد.
عملکرد درخت تصمیم به این صورت است که یک گره ریشه در بالای آن قرار دارد و برگ های آن در پایین می باشند. یک رکورد در گره ریشه وارد میشود و در این گره یک تست صورت می گیرد تا معلوم شود که این رکورد به کدام یک از گره های فرزند (شاخه پایینتر) خواهد رفت.
درخت تصمیم از تعدادی گره و شاخه تشکیل شده است که در آن نمونه ها را به نحوی طبقه بندی میکند که از ریشه به سمت پایین رشد می کند و در نهایت به گره های برگ م یرسد. هر گره داخلی یا غیر برگ با یک ویژگی مشخص می شود. این ویژگی سوالی را در رابطه با مثال ورودی مطرح می کند. در هر گره داخلی به تعداد جواب های ممکن با این سوال شاخه وجود دارد که هریک با مقدار آن جواب مشخص میشوند. برگهای این درخت با یک کلاس و یا یک طبقه از جوابها مشخص میشوند.
مزایا و معایب Decision Tree
- درخت تصمیم بدیهی است و نیاز به توصیف ندارد.
- هر دو مشخصه اسمی و عددی را میتواند مورد توجه قرار دهد.
- نمایش درخت تصمیم به اندازه کافی برای نشان دادن هرگونه طبقهبندی غنی است.
- مجموعه دادههایی که ممکن است دارای خطا باشند را در نظر میگیرد.
- مجموعه دادههایی که دارای مقادیر مفقوده هستند را شامل میشود.
- درختهای تصمیم روشهای ناپارامتری را نیز مورد توجه قرار میدهد.
در میان متخصصین در صنایع مختلف، مدیران و حتی دولوپرها، درختهای تصمیم محبوباند چرا که درک آنها آسان بوده و به دیتای خیلی پیچیده و دقیقی احتیاج ندارند، میتوان در صورت لزوم گزینههای جدیدی را به آنها اضافه کرد، در انتخاب و پیدا کردن بهترین گزینه از میان گزینههای مختلف کارآمد هستند و همچنین با ابزارهای تصمیمگیری دیگر به خوبی سازگاری دارند.
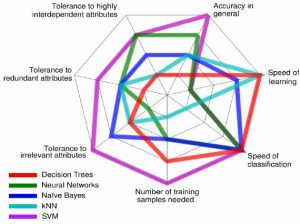
با تمام اینها، درختهای تصمیم ممکن است گاهی به شدت پیچیده شوند! در چنین مواردی یک به اصطلاح Influence Diagram جمع و جورتر میتواند جایگزین بهتری برای درخت تصمیم باشد به طوری که این دست نمودارها توجه را به تصمیمات حساس، اطلاعات ورودی و اهداف محدود میکنند.
ساختار درخت تصمیم
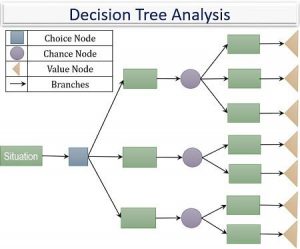
یک درخت تصمیمگیری به طور معمول با یک نُود اولیه شروع میشود که پس از آن پیامدهای احتمالی به صورت شاخههایی از آن منشعب شده و هر کدام از آن پیامدها به نُودهای دیگری منجر شده که آنها هم به نوبهٔ خود شاخههایی از احتمالات دیگر را ایجاد میکنند که این ساختار شاخهشاخه سرانجام به نموداری شبیه به یک درخت مبدل میشود. در درخت تصمیمگیری سه نوع Node (گِره) مختلف وجود دارد که عبارتند از:
- نُودهای تصمیمگیری: که توسط یک مربع نشان داده میشود، تصمیمی که میتوان اتخاذ کرد را نشان میدهد.
- نُودهای شانس يا احتمال: که توسط یک دایره نشان داده میشود، نمایانگر احتمال وقوع یکسری نتایج خاص است.
- نُودهای نتيجه پایانی: نمایانگر پیامد نهایی یک مسیر تصمیمگیری خواهد بود.
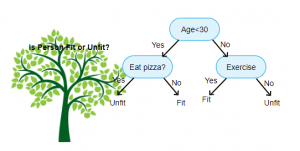
یک مثال خوب از درخت تصمیم (از سایت چیستو)
فرض کنید میخواهید مشخص کنید کدام یک از دانشجوهای این دانشکده میتوانند در آزمون دکتری، قبول شوند (در واقع میخواهید یک پیشبینی انجام دهید). این پیشبینی میتواند باعثِ این شود که شما از این به بعد دانشجویان با پتاسیلِ بالا را پیدا کرده و روی آنها سرمایهگذاری کنید. در واقع میخواهید یک مدلِ طبقهبندی ایجاد کنید تا بتواند توسط دادههای گذشته، یک مدل ساخته و از این به بعد، هر بار که یک دانشجوی جدید را به مدلِ یادگرفته شده دادیم، این مدل بتواند بفهمد که این دانشجو با چه احتمالی میتواند در آزمونِ دکتری قبول شود.
در اولین گام باید یک مجموعه داده (dataset) از دانشجویانِ گذشته که در آزمونِ دکتری قبول شدند یا نشدند ایجاد کنیم تا بتوانیم آن را به الگوریتمِ دادهکاوی بدهیم و این الگوریتم یاد بگیرد. فرض کنید مجموعه داده را به این صورت میسازیم:
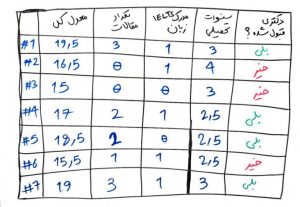
درخت های تصمیم با توجه به دادهها مبادرت به ایجادِ یک ساختارِ درختی میکنند که مانندِ قانونهای IF و ELSE عمل کرده و در نهایت به برچسبهای دلخواهِ ما که از دادههای آموزشی یاد گرفته شدند، میرسند. فرض کنیدمیخواهیم دادههای بالا را به صورت یک درخت بسازیم. شکلِ زیر در واقع یک نمونه درخت تصمیم از روی دادههای بالا است.
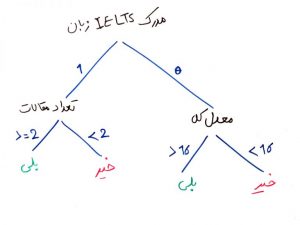
حال فرض کنید این درخت توسط یکی از الگوریتمهای درختهای تصمیم (decision trees) ساخته شده است. در واقع عملیاتِ یادگیری در درختِ تصمیم، همان ساخت عناصر و برگهای یک درخت است.
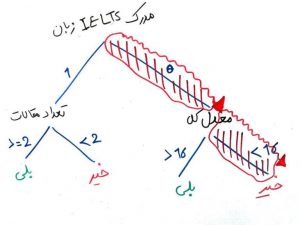
حال میخواهیم یک دانشجوی جدید معدل ۱۵.۵ دارد، تعداد ۵ مقاله ارائه کرده است ولی مدرک IELTS زبان ندارد. همچنین ۳ سال سنوات تحصیلی دارد. میخواهیم بدانیم آیا این شخص در آزمون دکتری قبول میشود یا خیر؟ اگر بخواهیم با توجه به درخت ساخته شده در شکل بالا، این دانشجو را ارزیابی کنیم مانند شکل زیر مسیر را ادامه میدهیم تا به یکی از برگها برسیم (مسیر حاشور خورده قرمز). درخت تصمیمِ ساخته شده به ما میگوید که این دانشجو احتمالاً نمیتواند در آزمون دکتری قبول شود.
الگوریتمهای پرکاربرد برای ساختن درخت تصمیم
-
الگوریتم ID3
یکی از الگوریتمهای بسیار ساده درخت تصمیم که در سال 1986 توسط Quinlan مطرح شده است. اطلاعات به دست آمده به عنوان معیار تفکیک به کار میرود. این الگوریتم هیچ فرایند هرس کردن را به کار نمیبرد و مقادیر اسمی و مفقوده را مورد توجه قرار نمیدهد.
این الگوریتم یکی از ساده ترین الگوریتم های درخت تصمیم(decision-tree) است. در این الگوریتم درخت تصمیم از بالا به پایین ساخته میشود. این الگوریتم با این سوال شروع میشود: کدام ویژگی باید در ریشه درخت مورد آزمایش، قرار بگیرد؟ برای یافتن جواب از معیار بهره اطلاعات استفاده میشود.
با انتخاب این ویژگی، برای هر یک از مقادیر ممکن آن یک شاخه ایجاد شده و نمونه های آموزشی بر اساس ویژگی هر شاخه مرتب میشوند. سپس عملیات فوق برای نمونه های قرار گرفته در هر شاخه تکرار می شوند تا بهترین ویژگی برای گره بعدی انتخاب شود.
-
الگوریتم C4.5
این الگوریتم درخت تصمیم، تکامل یافته ID3 است که در سال 1993 توسط Quinlan مطرح شده است. Gain Ratio به عنوان معیار تفکیک در نظر گرفته میشود. عمل تفکیک زمانی که تمامی نمونهها پایین آستانه مشخصی واقع میشوند، متوقف میشود. پس از فاز رشد درخت، عملِ هرس کردن بر اساس خطا اعمال میشود. این الگوریتم مشخصههای اسمی را نیز در نظر میگیرد.
این الگوریتم یکی از تعمیم های الگوریتم ID3 است که از معیار نسبت بهره(Gain ratio) استفاده می کند. الگوریتم هنگامی متوقف میشود که تعداد نمونه ها کمتر از مقدار مشخص شدهای باشد. این الگوریتم از تکنیک پس هرس استفاده میکند و همانند الگوریتم قبلی دادههای عددی را نیز میپذیرد.
از نقاطِ ضعف الگوریتم ID3 که در C4.5 رفع شده است میتوان به موارد زیر اشاره کرد:
- الگوریتم C4.5 میتواند مقادیر گسسته یا پیوسته را در ویژگیها درک کندو
- الگوریتم C4.5 قادر است با وجود مقادیر گمشده نیز درخت تصمیم(decision tree) خود را بسازد، در حالی که الگوریتمی مانند ID3 و بسیاری دیگر از الگوریتمهای طبقهبندی نمیتوانند با وجود مقادیر گمشده، مدلِ خود را بسازند.
- سومین موردی که باعث بهینه شدن الگوریتم C4.5 نسبت به ID3 میشود، عملیاتِ هرس کردن جهت جلوگیری از بیش برازش میباشد. الگوریتمهایی مانند ID3 به خاطر اینکه سعی دارند تا حد امکان شاخه و برگ داشته باشند (تا به نتیجه مورد نظر برسند) با احتمال بالاتری دارای پیچیدگی در ساخت مدل و این پیچیدگی در بسیاری از موارد الگوریتم را دچار بیش برازش و خطای بالا میکند.اما باعملیات هرس کردن درخت که در الگوریتم 5 انجام میشود، میتوان مدل را به یک نقطه بهینه رساند که زیاد پیچیده نباشد (و البته زیاد هم ساده نباشد) و بیش برازش یا کم برازش(Underfitting) رخ ندهد.
- الگوریتم C4.5 این قابلیت را دارد که وزنهای مختلف و غیر یکسانی را به برخی از ویژگیها بدهد.
-
الگوریتم CART
برای برقراری درختهای رگرسیون و دستهبندی از این الگوریتم استفاده میشود. در سال 1984توسط Breiman و همکارانش ارائه شده است. نکته حائز اهمیت این است که این الگوریتم درختهای باینری ایجاد میکند به طوری که از هر گره داخلی دو لبه از آن خارج میشود و درختهای بدست آمده توسط روش اثربخشی هزینه، هرس میشوند.
یکی از ویژگیهای این الگوریتم، توانایی در تولید درختهای رگرسیون است. در این نوع از درختها برگها به جای کلاس مقدار واقعی را پیشبینی میکنند. الگوریتم برای تفکیک کنندهها، میزان مینیمم مربع خطا را جستجو میکند. در هر برگ، مقدار پیشبینی بر اساس میانگین خطای گرهها میباشد.
-
الگوریتم CHID
این الگوریتم درخت تصمیم به جهت در نظرگرفتن مشخصههای اسمی در سال 1981 توسط Kass طراحی شده است. الگوریتم برای هر مشخصه ورودی یک جفت مقدار که حداقل تفاوت را با مشخصه هدف داشته باشد، پیدا میکند.
محققان آمار کاربردی، الگوریتمهایی را جهت تولید و ساخت درخت تصمیم توسعه دادند. الگوریتم CHAID در ابتدا برای متغیرهای اسمی طراحی شده بود. این الگوریتم با توجه به نوع برچسب کلاس از آزمونهای مختلف آماری استفاده میکند. این الگوریتم هرگاه به حداکثر عمق تعریف شدهای برسد و یا تعداد نمونهها در گره جاری از مقدار تعریف شدهای کمتر باشد، متوقف میشود. الگوریتم CHAID هیچگونه روش هرسی را اجرا نمیکند.
نرم افزارهای مورد استفاده برای انجام الگوریتم درخت تصمیم
زمانیکه بخواهید از نرمافزار برای دستهبندی نمونهها به روش الگوریتم درخت تصمیم استفاده کنید میتوانید از نرمافزارهای زیر بهرهمند شوید.
- R
- SPSS Modeler
- MATLAB
- SAS JMP
- Clementine
- Python
منبع:
https://sokanacademy.com/blog/decision-tree-%D8%AF%D8%B1%D8%AE%D8%AA-%D8%AA%D8%B5%D9%85%DB%8C%D9%85-%DA%86%DB%8C%D8%B3%D8%AA
https://amarpishro.com/data-analysis/decision-tree/
.https://chistio.ir/%d8%af%d8%b1%d8%ae%d8%aa-%d9%87%d8%a7%db%8c-%d8%aa%d8%b5%d9%85%db%8c%d9%85-%d8%b7%d8%a8%d9%82%d9%87-%d8%a8%d9%86%d8%af%db%8c-decision-trees/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 1595
برچسبDecision Tree الگوریتم پیش بینی پیشبینی داده کاوی درخت تصمیم علم داده یادگیری ماشین
نوشته های مرتبط












همچنین ببینید

دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار …
مراحل پیشپردازش متن خبر فارسی
پیشپردازش متن فارسی برای پردازش زبان طبیعی و انجام عمليات خودکار بر روي متن مانند …
