 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
تحلیل احساس و نظرکاوی متون فارسی با یادگیری ماشین و شبکه های عصبی کانولوشنال
داده های متنی یکی از پرمصرف ترینها است که میتواند برای بدست آوردن اطلاعات مهم در موضوعات مختلف مورد استفاده قرار گیرد. رسانه های اجتماعی در اشکال گوناگون خود همانند انجمنها، وبلاگها، میکروبلاگها، سایتهای نظردهی و غیره روزانه منجر به تولید حجم وسیعی از داده ها میشوند. چنین داده هایی در قالب نظرات، نقدها، دیدگاه ها در مورد خدمات، شرکتها، سازمانها، رویدادها، افراد، مسائل و موضوعات میباشد. نظرات ارائه شده کاربران در شبکه های اجتماعی بسیار مهم و کابردی هستند. طبقه بندی و سازماندهی این حجم بسیار عظیم از نظرات در مورد یک موضوع خاص بهصورت دستی کار آسانی نیست. از همینرو، نیاز به یک سیستم خودکار برای جمعآوری نظرات منجر به ظهور یک زمینه تحقیقاتی جدید به نام تحلیل احساس ( analysis sentiment) شد. تحلیل احساسات، زمینه مطالعاتی است که هدف اصلی آن شناسایی، استخراج و طبقهبندی احساسات، نظرات، نگرشها، افکار، قضاوتها، نقدها و دیدگاه ها نسبت به موجودیتها، سازمانها، رویدادها و غیره بدون تعامل انسانی در قالب دسته های مثبت، منفی و یا خنثی میباشد.
عناوين مطالب: '
- راهنمای گام به گام تحلیل احساسات فارسی با یادگیری عمیق بوسیله LSTM و Fasttext
سطوح مختلف نظرکاوی
سطح سند: وظیفه این سطح مشخص کردن مثبت یا منفی بود کل سند است و هر نظر به صورت کامل به عنوان یک سند در نظر گرفته می شود.
سطح جمله: در این سطح مثبت، منفی و یا خنثی بودن هر جمله بررسی میشود. خنثی بودن اغلب به معنای این است که جمله یک دیدگاه نیست.
سطح کلمه یا عبارت: این سطح به تحلیل جزئیتر میپردازد و به انتخاب دقیق کلمات بستگی دارد. در دو سطح قبلی علایق افراد به طور جزئی و دقیق مشخص نمیشود. مسئلهای که در این سطح مطرح میشوند نظرکاوی مبتنی بر ویژگی است. در این سطح نظرات مورد بررسی قرار میگیرند تا ویژگیهایی که افراد دیدگاه خود را در مورد آن بیان کردهاند، شناسایی شوند و در نهایت احساسات افراد نسبت به این ویژگیها مشخص گردد. ویژگی های مهم یک محصول یا خدمت در این جا شناسایی و رتبه بندی می شوند.
رویکردهای تحلیل احساسات
سه رویکرد متفاوتی که محققین برای طبقه بندی احساسات در یک متن استفاده میکنند، 1-رویکردهای مبتنی بر واژگان و 2-رویکردهای مبتنی بر یادگیری ماشین و 3-رویکردهای مبتنی بر یادگیری عمیق میباشد. رویکرد دیگری را هم میتوان ترکیبی از این دو نظر گرفت. رویکرد مبتنی بر واژگان، متمرکز بر استخراج کلمات یا عباراتی است که میتواند فرآیند طبقه بندی را در جهتگیری معنایی خاصی هدایت کند. هر واژه دارای بار معنایی خاصی است که از طریق یک فرهنگ واژه از کلمات با بار احساسی مثبت و منفی که از قبل امتیازبندی شده اند، استخراج میشود. با جمع امتیاز بار احساسی واژه ها یا شمارش تعداد واژه های با بار مثبت و منفی، قطبیت کلی جمله بدست میآید. رویکرد یادگیری ماشین را میتوان در حالتهای مختلفی برای مساله تحلیل احساسات آموزش داد و بکار برد.

در حالت یادگیری بانظارت با یک مجموعه داده آموزشی که پیشتر برچسب خورده است مدل آموزش میبیند تا قادر به یادگیری شود و بتواند در مواجهه با داده های دیده نشده رفتاری مشابه با داده های آموزش دیده از خود نشان دهد. طی سالهای اخیر، به طور گستردهای توسط محققین اثبات شده است که مدلهای بازنمایی مبتنیبر یادگیری عمیق در مساله های مرتبط با طبقه بندی احساسات کارآیی بهتری دارند. اتخاذ رویکردهای یادگیری عمیق در تحلیل احساسات به دلیل توانایی بسیار بالای مدلهای یادگیری عمیق در یادگیری ویژگیها بهصورت خودکار است که میتواند به دقت و عملکرد بهتری دست یابند. در بسیاری از زمینه های پردازش زبان طبیعی، استفاده از یادگیری عمیق سبب شده است نتایج از آنچه که در گذشته توسط روشهای یادگیری ماشین و روشهای آماری مورد استفاده قرار میگرفته است، فراتر رود.
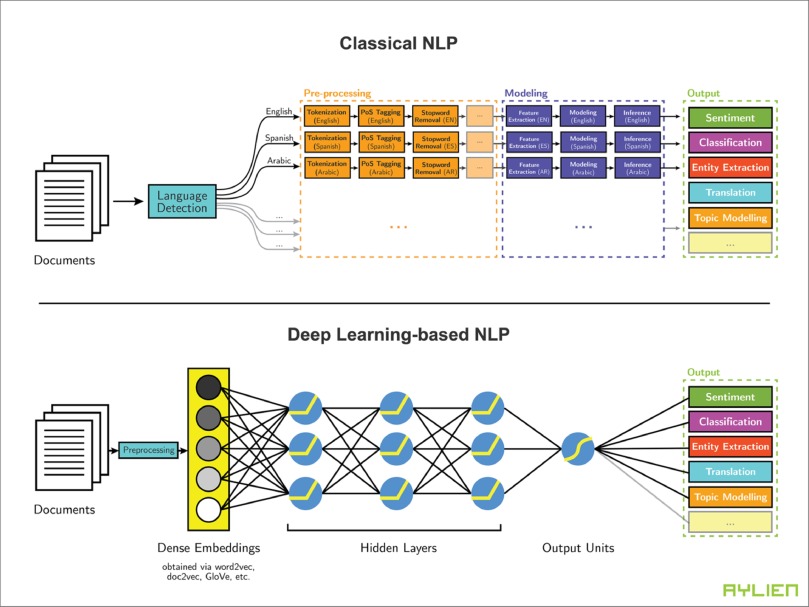
راهنمای گام به گام تحلیل احساسات فارسی با یادگیری عمیق بوسیله LSTM و Fasttext
برای تحلیل احساس متون با روش یاد گیری عمیق 5 مرحله داریم که در ادامه مورد بررسی قرار میدهیم.
مرحله الف) تهیه مدل تعبیه کلمه یا جاسازی کلمه (word embedding)
مرحله ب) آماده سازی dataset
مرحله ج) تهیه مدل LSTM
مرحله د) تهیه تست و ارزیابی مدل
مرحله ه) استفاده از مدل آموزش داده شده
این 5 مرحله را میتوانید در لینک زیر در گیت هاب من به صورت کد پایتون مشاهده کنید: برای درک بیشتر شما من سراسر این کد را کامنت گذاری کردم که حتی افراد مبتدی نیز بتوانند آن را درک کنند.
https://github.com/ithabibi/Persian-Opinion-Mining-and-Sentiment-Analysis/blob/main/Persian-Sentiment.ipynb
مرحله الف) تهیه مدل تعبیه کلمه یا جاسازی کلمه (word embedding)
نکته: قبل از هر چیز بدانید که embedding فقط یک لایه از فرایند یادگیری است. لغت نامه های انسانی بصورت متن ساده هستند اما برای اینکه یک مدل یادگیری ماشینی قادر به فهم و پردازش زبان طبیعی باشد، ما نیازمند تبدیل کلمات از متن ساده به مقادیر عددی هستیم.
مدلسازی زبان بخش اصلی بسیاری از وظایف مرتبط با پردازش زبان طبیعی است. مدلسازی زبان بصورت ساده به عمل پیش بینی کلمه بعدی در یک دنباله داده شده گفته میشود. بعنوان مثال جمله “من در حال نوشتن یک …” را در نظر بگیرید . کلمه بعدی که میتواند در ادامه بیایید میتواند “نامه”، “جمله” یا “پست وبلاگ” و… باشد. بعبارت دیگر به ازای کلمات ارائه شده x(1) و x(2) و… x(t) مدلهای زبانی توزیع احتمالاتی کلمه بعدی (t+1)x را محاسبه میکنند. پایه ای ترین مدل زبانی مدل n-gram است. مدلهای زبانی همچنین به احتمال(likelihood) رخداد یک کلمه ( یا دنباله ای از کلمات) داده شده بعد از دنباله ای از لغات نیز احتمالی را منتسب میکنند.
یک مدل زبانی احتمال رخداد کلمات را بر اساس نمونه های متنی فرا میگیرد. مدلهای ساده تر ممکن است به محتوای حاصل از یک دنباله کوتاه متشکل از چند لغت نگاه کنند در حالی که مدلهای بزرگتر ممکن است در سطح جملات یا پاراگراف ها عمل کنند. عموما مدلهای زبانی در سطح لغات فعالیت(کار؛عمل) میکنند.
- تشخیص حروف نوری (Optical Character Recognition)
- تشخیص دستخط (Handwriting Recognition)
- ترجمه ماشینی (Machine Translation)
- تصحیح املاء (Spelling Correction)
- شرح نویسی تصویر (Image Captioning)
- خلاصه سازی متن (Text Summarization)
- تحلیل احساس (Sentiment-Analysis)
- و…
استفاده از شبکه های عصبی در مدلسازی زبان اغلب به مدلسازی زبانی عصبی یا به اختصار NLM معروف است. روشهای مبتنی بر شبکه عصبی نتایج بهتری نسبت به روش های سنتی در حالات مختلف بدست می آورند. مدلهای شبکه عصبی از طریق پارامتری کردن کلمات در قالب بردارها (word embedding) و استفاده ازآنها بعنوان ورودی به یک شبکه عصبی با مشکل پراکندگی داده در n-gram مقابله میکنند. پارامترها در حین فرایند آموزش فراگرفته میشوند. word embedding های بدست امده از طریق NLM ها شاهد خصائصی اند که در آنها کلمات نزدیک بهم از نظر معنایی در فضای برداری نیز به یکدیگر نزدیک اند.
لغت نامه های انسانی بصورت متن ساده هستند اما برای اینکه یک مدل یادگیری ماشینی قادر به فهم و پردازش زبان طبیعی باشد، ما نیازمند تبدیل کلمات از متن ساده به مقادیر عددی هستیم. درون سازی یا تعبیه کلمه یا اصطلاحا word embedding نامی تجمعی است که به مجموعه ای از تکنیک های یادگیری ویژگی و مدلسازی زبان در پردازش زبان طبیعی اطلاق میشود. در این تکنیک ها، کلمات و عبارات از یک لغت نامه به بردارهای عددی نگاشت میشوند. بطور مفهومی این تکنیک، مستلزم تعبیه سازی ریاضی (mathematical embedding) از فضایی با ابعاد زیاد به ازای هر کلمه به فضای برداری پیوسته با ابعاد بسیار کمتر است.
در کاربردهای مبتنی بر یادگیری ماشین، خصیصه شباهت Word embedding ها برنامه ها را قادر میسازد تا با کلماتی که تا بحال در فاز آموزش با آنها مواجه نشده اند بخوبی کار کنند. چون آن ها را با نزدیک ترین هم معنی های خود نگاشت میکنند. بجای اینکه تنها با استفاده از کلمات به مدلسازی پرداخته شود، مدلهای مبتنی بر یادگیری ماشین از بردار کلمات برای اهداف پیش گویانه استفاده میکنند.
اگر کلماتی که تا بحال در زمان آموزش مشاهده نشده اند، اما در فضای Word embedding شناخته شده هستند، به مدل عرضه شوند، بردار کلمات بخوبی با این مدل به فعالیت خود ادامه خواهد داد . یکی از خصوصیت های جذاب word embedding های آموزش دیده این است که روابط بین کلمات در شیوه سخن گفتن محاوره ای نیز از طریق روابط خطی بین بردارها ثبت و ضبط میشود!
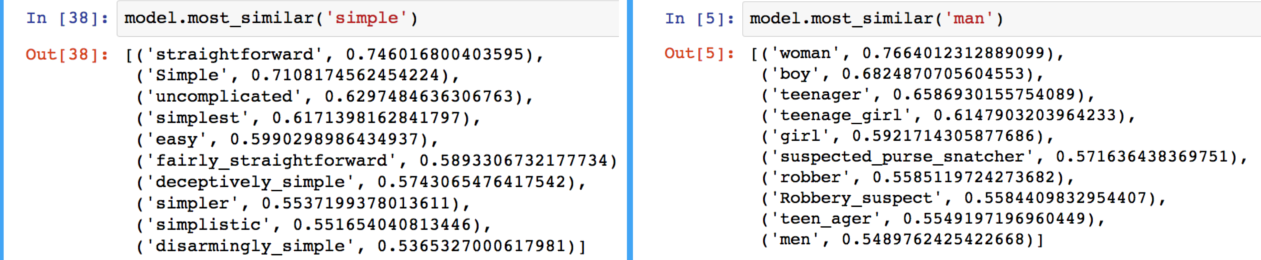
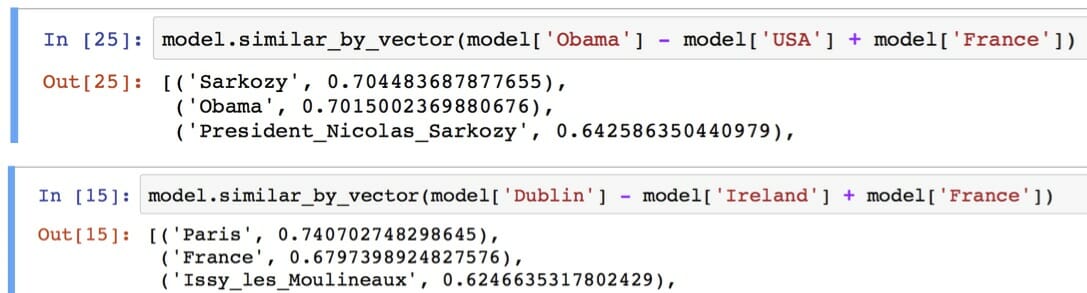
شباهتی که در اینجا از آن صحبت میکنیم را را میتوان توسط فاصله اقلیدسی (فاصله واقعی بین نقاط در فضای N-D بُعدی) و یا شباهت کسینوسی یا اصطلاحا Cosine Similarity (زاویه بین دو بردار در فضای برداری) تعریف نمود. این بردارها در پاسخ دادن به سوالات قیاسی به فرم “الف نسبت به ب همانند ج است نسبت به … ” بسیار خوب عمل میکنند. بعنوان مثال، سوال ” نسبت مرد به زن همانند نسبت عمو است به …. ” در اینجا توسط یک روش مبتنی بر آفست بردار ساده براحتی با استفاده از محاسبه فاصله کسینوسی بسادگی کلمه “زن عمو”، بدست می آید. در شکل زیر با روشهای کاهش ابعاد میتوان آن را در یک ترسیم دوبعدی مشاهده نمود.
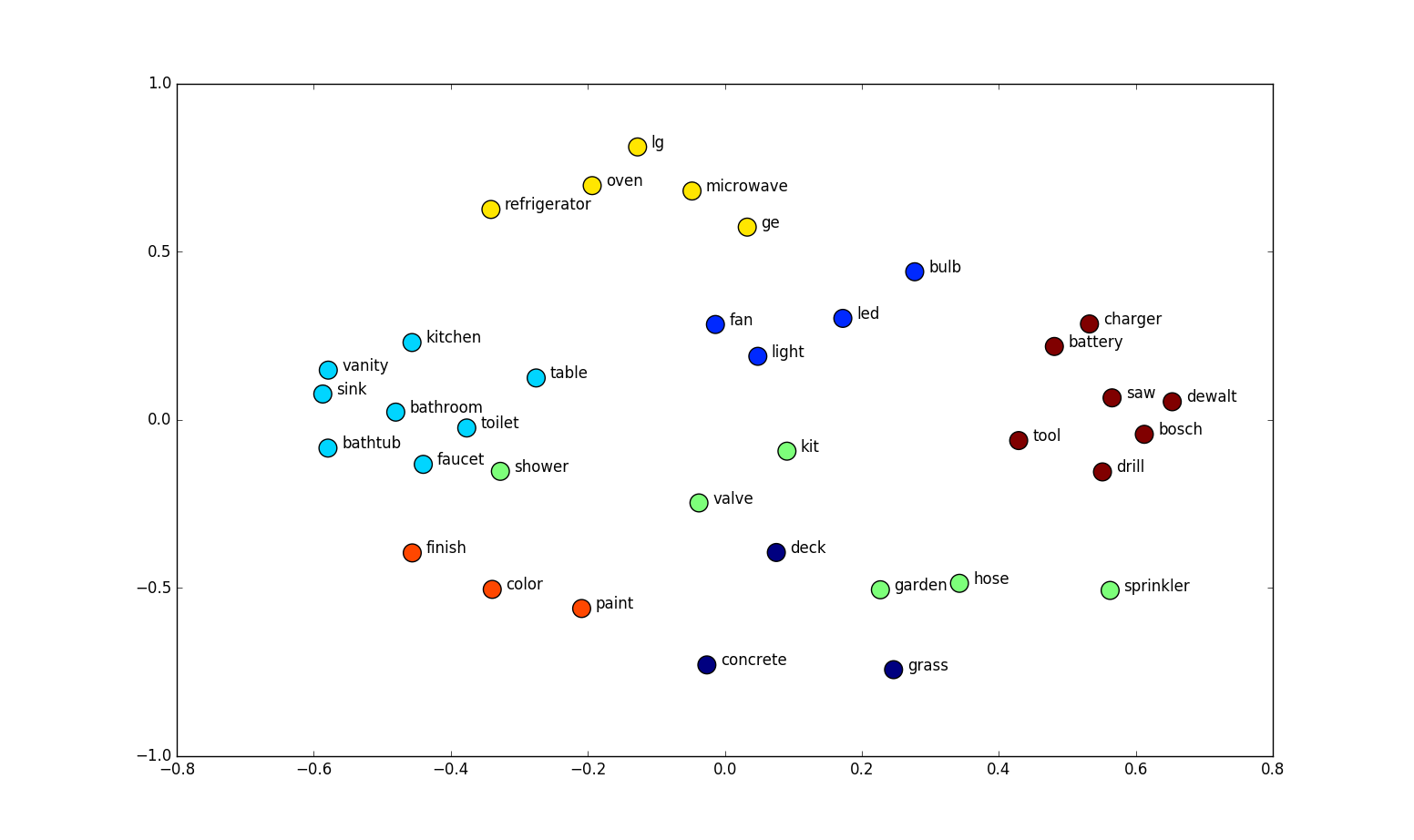
این خصیصه را میتوان با استفاده از کتابخانه Gensim در زبان پایتون مشاهده کرد که در آن، نزدیک ترین کلمات به یک کلمه هدف در فضای برداری را میتوان با استفاده مجموعه ای از Word embedding ها براحتی استخراج نمود.
روابط خطی بین کلمات در فضای embedding موجب ظهور جبر کلمه ای غیرمعمولی میشود که به کلمات اجازه جمع و تفریق داده و نتایج منطقی نیز بدنبال دارد! بردار کلمات با چنین روابط معنایی میتوانند جهت بهبو بسیاری از کاربردهای حوزه پردازش زبان طبیعی، نظیر ترجمه ماشینی، بازیابی اطلاعات و سامانه های پرسش و پاسخ مورد استفاده قرار گیرند و ممکن است کاربردهایی که هنوز اختراع نشده اند را در آینده موجب گردند. لازم به ذکر است کاربردهای مبتنی بر بردار کلمات و بطور خاص Word2vec محدود به تجزیه جملات نبوده و چیزی فراتر از آن است. از آن میتوان بر روی گستره زیادی از داده ها همانند، ژن، سورس کد، پسندها در یک شبکه اجتماعی، playlist ها، گراف های شبکه های اجتماعی و سری های سمبولیک و… که میتوانند حاوی الگوهایی باشد، استفاده کرد.
در زمان آموزش word embedding برای یک لغت نامه بزرگ، تمرکز بر روی بهینه سازی embedding هاست بگونه ای که معنای اصلی و روابط بین کلمات حفظ شود. این ایده اولین بار توسط جان روپرت فرث که بعنوان زبان شناس بر روی الگوهای زبانی در دهه ۱۹۵۰ کار میکرد ارائه شد. شما باید یک کلمه را از اطرافیانش بشناسید!
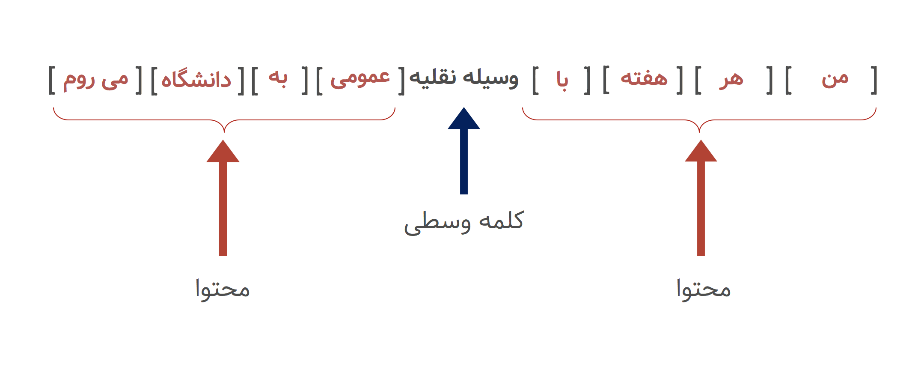
مدل Continuous Bag of Words
اجازه دهید با مدل CBOW شروع کنیم. متنی مثل “من هر هفته با وسیله نقلیه عمومی به دانشگاه میروم.” را در نظر بگیرید. فرض کنید یک پنجره لغزان بر روی این متن وجود دارد و کلمه ای که روی آن تمرکز شده، همان کلمه وسطی باشد که ۴ کلمه قبل و بعد از آن وجود دارد. :
این داده ها همانند متن دارای ماهیت یا عبارت بهتر حالات گسسته اند، و از این جهت ما میتوانیم همانند آنچه با متن انجام دادیم با آنها نیز انجام دهیم. بعنوان مثال ما میتوانیم به گذار احتمالات بین دو حالت دقت کنیم و ببینیم احتمال رخ دادن هریک به چه صورت است. بنابر این gene2vec، like2vec ،follower2vec و… مواردی از این دست همه قابل انجام هستند. این دید، بشما کمک خواهد کرد تا چگونگی ایجاد embedding های عصبی برای انواع مختلف داده را بخوبی درک کنید.
لازم به ذکر است کاربردهای مبتنی بر بردار کلمات و بطور خاص Word2vec محدود به تجزیه جملات نبوده و چیزی فراتر از آن است. از آن میتوان بر روی گستره زیادی از داده ها همانند، ژن، سورس کد، پسندها در یک شبکه اجتماعی، playlist ها، گراف های شبکه های اجتماعی و سری های سمبولیک و… که میتوانند حاوی الگوهایی باشد، استفاده کرد.
word2vec embeddings با آموزش یک شبکه عصبی بر روی مجموعه بسیار بزرگی از جملات مختلف، ایجاد میشوند. وظیفه شبکه، پیشبینی target wordهایی است که در وسط یک پنجره با اندازه ثابت (fixed-size window) قرار دارند.

word2vec دو سناریو مختلف برای آموزش شبکه عصبی و ساخت مدل زبانی ارائه میدهد:
CBOW یا continuous bag-of-words که یک کلمه را باتوجهبه یک context خاص پیشبینی میکند (مانند مثال بالا). این سناریو برای کلمات پرتکرار مناسب است؛ اما برای کلمات کم کاربرد، چندان جالب نیست.
Skip-Gram رویکردی بر خلاف CBOW دارد. یعنی context یک کلمه را پیشبینی میکند. این سناریو برای دیتاستهای آموزشی کوچک و محدود، مناسب است و کلمات یا عباراتی را کاربرد کمی داشته را بهدرستی نشان میدهد.
GloVe چیست؟
GloVe مخفف عبارت Global Vectors است. پروژهای open source که توسط دانشگاه Stanford برای مدل زبانی ارائه شد.
هدف از ساختن GloVe، رمزگذاری اطلاعات معنایی (encoding semantic information) در بردارها است و همچنین میزان ارتباط هر دوکلمه را با سایر کلمات زمینهای (contextual word) متن اندازهگیری میکند.
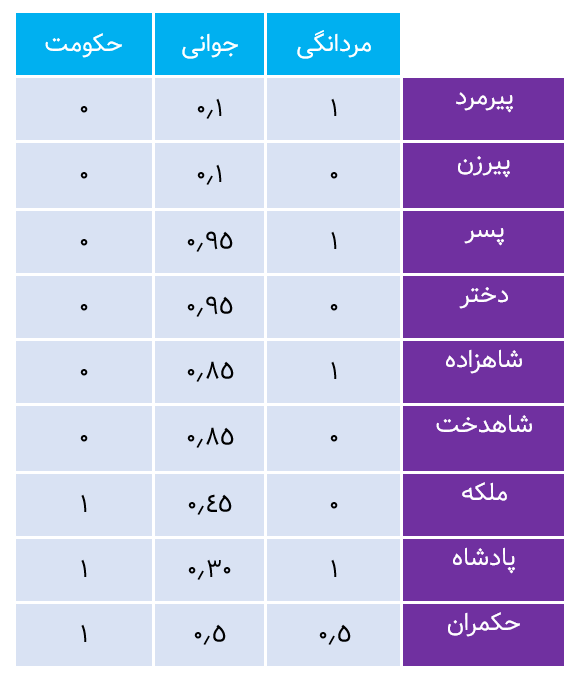
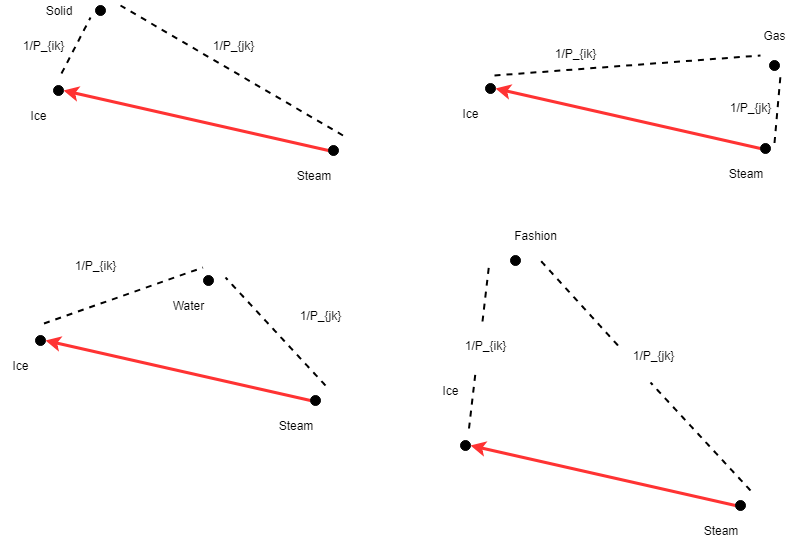
در مدل زبانی، به این کلمات زمینهای، کلمات کاوشگر (probe words) نیز گفته میشود. بهعنوانمثال، احتمال اینکه دوکلمه ice و solid را با هم در یک متن داشته باشیم، بیشتر از آن است که کلمه cat و solid را داشته باشیم. probe words این امکان را به ما میدهند تا انواع contextهایی را که کلمه اصلی در آن استفاده میشود، تعریف کنیم. حال، proximity دوکلمه ice و steam را نسبت به کلمه solid که probe word آن است، به دست میآوریم. اعداد دقیق بر روی دیتاست بزرگی با بیش از 6 میلیارد کلمه محاسبه شدهاند:
این روابط را میتوان با رسم تفاوت برداری بین کلمات اصلی (ice و steam) و probe word مانند: solid، gas، water و fashion نیز نشان داد. میبینید که کلمه solid در مقایسه با steam به ice نزدیکتر است؛ بنابراین این رابطه برقرار است: d(solid, ice) < d(solid|steam)
گامهای بعدی محاسبه GloVe embeddings شامل ریاضیاتی است که فراتر از این مقاله است. اما به طور خلاصه، نویسندگان یک تابع ضرر (loss function) تعریف کردهاند که عملیات تفریق این نسبتها را با log گرفتن از آن نسبت، حفظ میکند. این loss function را میتوان به کمک یکی از معروفترین الگوریتم بهینهسازی کلاسیک به نام stochastic gradient descent (SGD)، به حداقل رساند.
در عمل، GloVe در حین آموزش مدل زبانی، فارغ از اندازه پیکرۀ متنی (کوچک یا بزرگ)، از یک الگوریتم بهینهسازی قوی به نام (SGD) استفاده میشود که GloVe را در مقایسه با word2vec صاحب چنین مزایایی میکند:
- آموزش سریعتر مدل زبانی
- کارایی بیشتر RAM/CPU (میتوان داکیومنتهای بزرگتر را مدیریت کرد)
- استفاده کارآمدتر از دادهها (مخصوصاً برای دیتاستهای کوچکتر)
- عملکرد دقیقتر مدل زبانی با داشتن دیتاست یکسان
معایب روش Word Embeddings چیست؟
مدلهایی که به دادههای آموزشی خود وابسته هستند، میتوانند دو عیب مهم داشته باشند: سوگیری فرهنگی (cultural bias) و واژگان جدیدی که در vocabulary مدلها نیستند (اصطلاحاً به این کلمات out-of-vocabulary یا OOV گفته میشود).
سوگیری فرهنگی
مدل word2vec بر روی دیتای حجیم Google News که شامل اخبار ایالات متحده است، آموزشدادهشده است. بهاینترتیب خبرهایی که داخل Google ایندکس شدهاند، در نظر گرفته شده و روابط بین کلمات آنها به مدل آموزشدادهشده است. آموزش بر روی چنین دادۀ حجیمی باعث میشود که مدل خواهناخواه، مقداری سوگیری فرهنگی داشته باشد.
Out-of-Vocabulary Words (OOV) چیست؟
یکی دیگر از مشکلات مدلهای GloVe و word2vec محدود بودن واژگان مدل است. در بخش word2vec vocabulary دیدیم که لیست توکنهای آن متنوع (heterogeneous) و پیچیده است. اما حتی با وجود داشتن بیش از 3 میلیون کلمه بهعنوان ورودی، یک سری کلمات خاصی وجود دارند که مدل word2vec نمیتواند آنها را شناسایی کند. به عبارتی دیگر، اینها کلماتی هستند که بردار مرتبطی برای آنها وجود ندارد. مانند:
- Covid (و همه عبارتهایی که شامل آن میشوند. با یا بدون “19-“)
- Word2vec (بله، word2vec اطلاعاتی از نام خودش ندارد).
این موضوع کاملاً طبیعی است؛ زیرا مدل word2vec در سالهای 2013/2014، چند سال پیش از دوران Covid، آموزشدادهشده است.
اگر میخواهید بیشتر بدانید، مقاله زیررا از توماس ولف بخوانید، اما اکنون ما از Fasttext استفاده میکنیم زیرا توسط فیسبوک از قبل آموزش داده شده است و میتوانیم از آن استفاده کنیم (در مورد این مدل هیچ نگرانی وجود ندارد، آموزش آن توسط خودتان یا corpus بسیار آسان است. فیس بوک از ویکی پدیای فارسی و تعدادی دیگر از مجموعه داده برای این مدل استفاده کرده است، بنابراستفاده از آن برای ما بسیار ساده تر است.
https://medium.com/huggingface/universal-word-sentence-embeddings-ce48ddc8fc3a
FastText چیست؟
برای حل مشکل OOV یا out-of-vocabulary، روش fastText از یک استراتژی توکنسازی مبتنی بر کاراکتر n-gram برای ساخت مدل زبانی استفاده میکند. یک کاراکتر n-gram در واقع دنبالهای از n حرف است. علاوه بر داشتن استراتژی توکنسازی انعطافپذیر و مبتنی بر کاراکتر n-gram، fastText میتواند سریع و ساده word2vec را با هر دو سناریو CBOW یا skip-gram پیادهسازی کند. برخی از دیگر ویژگیهای کلیدی fastText عبارتاند از:
- حدوداً 300 زبان را پشتیبانی میکند (میتوانید لیست این زبانها را در این صفحه fastText documentation ببینید).
- قابلاستفاده در زبان برنامهنویسی پایتون
- سادهسازی train مدلهای text classifier
- دارای یک مدل خاص برای تشخیص زبان (language detection) (برای اطلاعات بیشتر در مورد تشخیص زبان، به fastText documentation مراجعه کنید). این ویژگی برای فیلتر دیتای مربوط به شبکههای اجتماعی که به چندین زبان هستند، مفید است.
نکته مهم: تنها fastText بهصورت رسمی نسخه مخصوص به زبان فارسی ارائه داده است.
در این مرحله قصد داریم مدل word embedding را آماده کنیم. راه های زیادی برای آموزش یک مدل word embedding وجود دارد. به عنوان مثال:
- الگوریتم
fasttextشرکت فیس بوک سال 2016 (پیش آموزش دیده در وب خزیدن انگلیسی و ویکی پدیا) و بردار کلمات چند زبانه (مدل های آموزش دیده برای 157 زبان مختلف) - ELMo Embeddings from Language Models
- Universal Sentence Encoder برای گوگل
- الگوریتم word2vec-google-news-300 شرکت گوگل سال 2013
- الگوریتم GloVe دانشگاه استنفورد سال 2014:
- …
word embeddings بر روی ابردیتاستها آموزش داده میشوند. بهعنوانمثال، Word2vec بر روی دیتاست Google News شامل 100 میلیارد کلمه، GloVe بر روی دیتاستی متشکل از 6 میلیارد کلمه و fastText بر روی 16 میلیارد توکن، آموزش داده شدهاند. بهاینترتیب، این مدلها کلمات زیادی را پوشش داده و برای هر کلمه بردار ایجاد میکنند. word2vec دارای 3 میلیون کلمه، GloVe دارای 400 هزار کلمه و fastText دارای 1 میلیون کلمه است.

مرحله ب) آماده سازی opinion dataset
در این مرحله میخواهیم مجموعه دادهای را جمع آوری کنیم که توسط اکانت @minasmz در گیت هاب خزیدش شده است. این مجموعه داده خیلی خوب نیست و من فقط از 460 کامنت مثبت و 460 نقد منفی از آن استفاده کردم. (من Train and Test را ایجاد کردم و سپس آن را با داده پر کردم).
علت انتخاب عدد 460 این بود که تعداد کامنت های منفی در دیتاستِ من 460 عدد بود برای همین مجبور شدم که از کامنت های مثبت هم 460 نمونه انتخاب کنم. هنگامی که ما روی مسائل طبقه بندی کار می کنیم، تعادل طبقاتی یک معیار مهم است. ضروری است اطمینان حاصل شود که کلاس ها خیلی پرت نیستند. و عدم تعادل طبقاتی منجر به نتایج مغرضانه می شود.
من داده ها را از دیجی کالا اسکرپ کرده ام و بر اساس ستاره هایی که افرادی که محصولات را به آنها خریده اند، برچسب گذاری کرده ام. من همچنین از برچسب دیگری از همان وب سایت استفاده کرده ام که نشان می دهد مردم به دیگران پیشنهاد می دهند آن محصول را بخرند یا نه.
از آنجا که بسیاری از نظرات نویز هستند و داده های تمیزی را برای ما ارائه نمی دهند و منبع قابل اعتمادی نیست با افزودن برچسب دوم به داده ها می توانیم از دقت بالاتر داده های آموزشی خود اطمینان حاصل کنیم. برای توضیح بیشتر برچسب ها: 1 نشان دهنده پیشنهاد خرید به دیگران و 2 به معنای غیر این است، 3 نشان دهنده یک نظر خنثی در مورد محصول است و 4 به این معنی است که شخص به محصول امتیاز داده است، اما پیشنهاد خرید یا عدم خرید را ندارد. و عدد دو یا سه رقمی نشان دهنده درصد رضایت مصرف کننده از نظر قبلی است. می توانید در فایل ” Tutorial_Dataset.csv” به این داده ها دسترسی پیدا کنید.
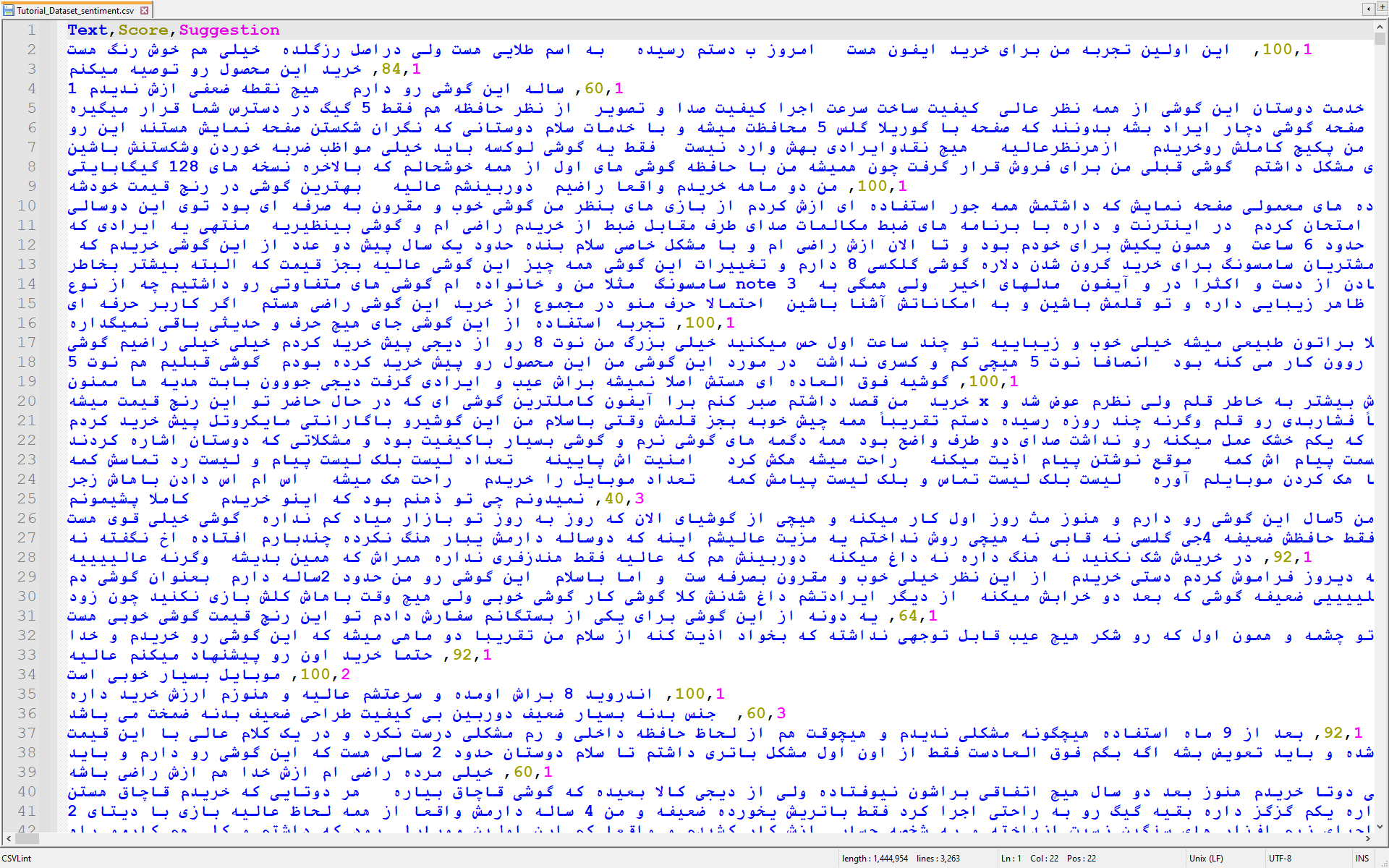
آماده سازی داده ها
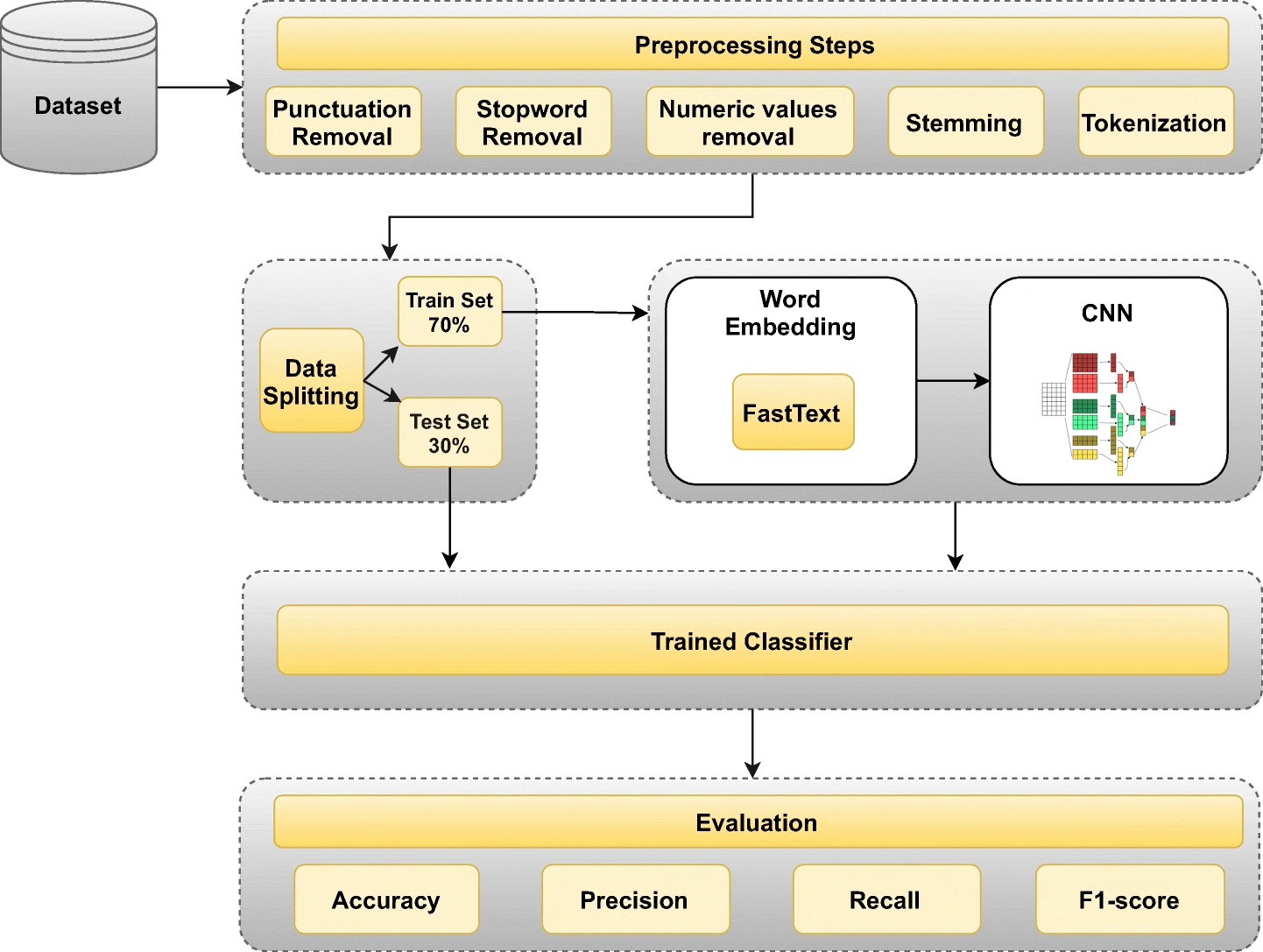
در این مرحله من اطلاعات خود را با کتابخانه Hazm و سایر تغییراتی که در کد منبع من نظر داده شده است، clean کردم. سپس، من مجموعه داده های خود را برای آموزش و آزمایش به بخش هایی تقسیم کردم. نویز زیادی در داده های متن خام وجود دارد. دو بخش مهم تمیز کردن متن برای تجزیه و تحلیل احساسات عبارتند از: حذف کلمه توقف و ریشه کردن.
علائم نقطه گذاری وجود دارد، نمادهایی که چندان به مدل ما کمک نمی کنند. همچنین کلمات توقفی وجود دارد که باید حذف شوند. کلمات توقف به کلمات پیوند دهنده ای مانند “the”، “و” “بود” اشاره دارد که هیچ معنای خاصی ارائه نمی دهد، که به تحلیل ما کمک نمی کند. بنابراین، ما اینها را حذف کرده و داده ها را پاک می کنیم. کتابخانه Hazm یک بسته پایتون که با استفاده از کتابخانه NLTK میکنم. Hazm برای وظایف NLP استفاده می شود. با استفاده از این بسته می توانیم به سرعت تمام کلمات توقف را به زبان انگلیسی دریافت کنیم. به قطعه زیر نگاهی بیندازید.
مرحله ج) آماده سازی شبکه عصبی CNN و مدل LSTM
توکن سازی به تقسیم جمله داده شده به لیستی از نشانه ها، نمایه شده یا بردار اشاره دارد. ما از TensorFlow و Keras برای مدل سازی استفاده خواهیم کرد. Keras یک ماژول پیش پردازش برای متن دارد که tf را به ما ارائه می دهد . کراس پیش پردازش . متن کلاس Tokenizer()`. می توانید آن را مطابق شکل زیر مقداردهی اولیه کنید. همچنین می توانید معیارهای تقسیم، حداکثر تعداد کلمات و غیره را مشخص کنید.
اکنون مدل LSTM خود را ایجاد می کنیم و سپس مجموعه داده های آموزشی خود را به آن تغذیه می کنیم و توسعه میدهیم! شبکه LSTM مخفف عبارت Long Short Term Memory است. احتمالا حالا برای شما معنی Long Term Memory مشخص شده است. یعنی حافظه بلندمدت دارد و دقیقا نقطه مقابل شبکه RNN است که از این مشکل رنج میبرد. این یک معماری اصلاح شده و پیشرفته از RNN ها (شبکه های عصبی بازگشتی) است. این عمدتاً در مسائل متوالی NLP مفید است، جایی که RNN به دلیل ناپدید شدن و انفجار گرادیان ها از کار می افتد. LSTMها قادرند وابستگی های مدل سازی دوربرد را با دقت بهتری نسبت به شبکه های معمولی انجام دهند. اگر در یادگیری عمیق تازه کار هستید، ممکن است بخواهید این مقاله را برای درک عمیق تر از نحوه عملکرد LSTM بررسی کنید.
ما یک مدل توالی را برای این داده ها اعمال خواهیم کرد. برای این کار باید ورودی های هم اندازه را ارسال کنیم. با این کار دنباله هایی با اندازه ثابت به ما باز می گردند که می توانند به عنوان پارامتر ارسال شوند. به قطعه کد نگاهی بیندازید. طول دنباله را در این مورد 20 قرار داده ایم.
در این مشکل، معماری ما از چهار بخش اصلی تشکیل شده است. ما با لایه embedding که قبلا تعریف شده است شروع می کنیم و دنباله ها را وارد می کند و embedding های کلمه را می دهد. این تعبیهها سپس به لایه پیچیدگی منتقل میشوند، که آنها را به بردارهای ویژگی کوچک تبدیل میکند. بعد، لایه LSTM دو طرفه را داریم. بعد از لایههای LSTM، چند لایه متراکم (لایههای کاملاً متصل) برای اهداف طبقهبندی داریم. ما از یک تابع فعال سازی سیگموئید قبل از خروجی نهایی استفاده می کنیم.
شما باید اندازه دسته و تعداد دوره هایی را که برای آنها تمرین خواهید کرد تصمیم بگیرید. به طور کلی آموزش برای 100-200 دوره کافی است.
شبکه عصبی کانولوشنال (CNN):
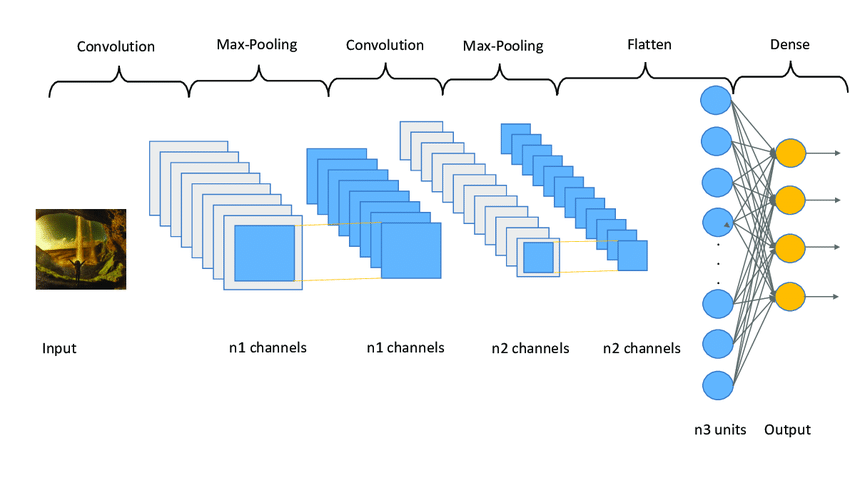
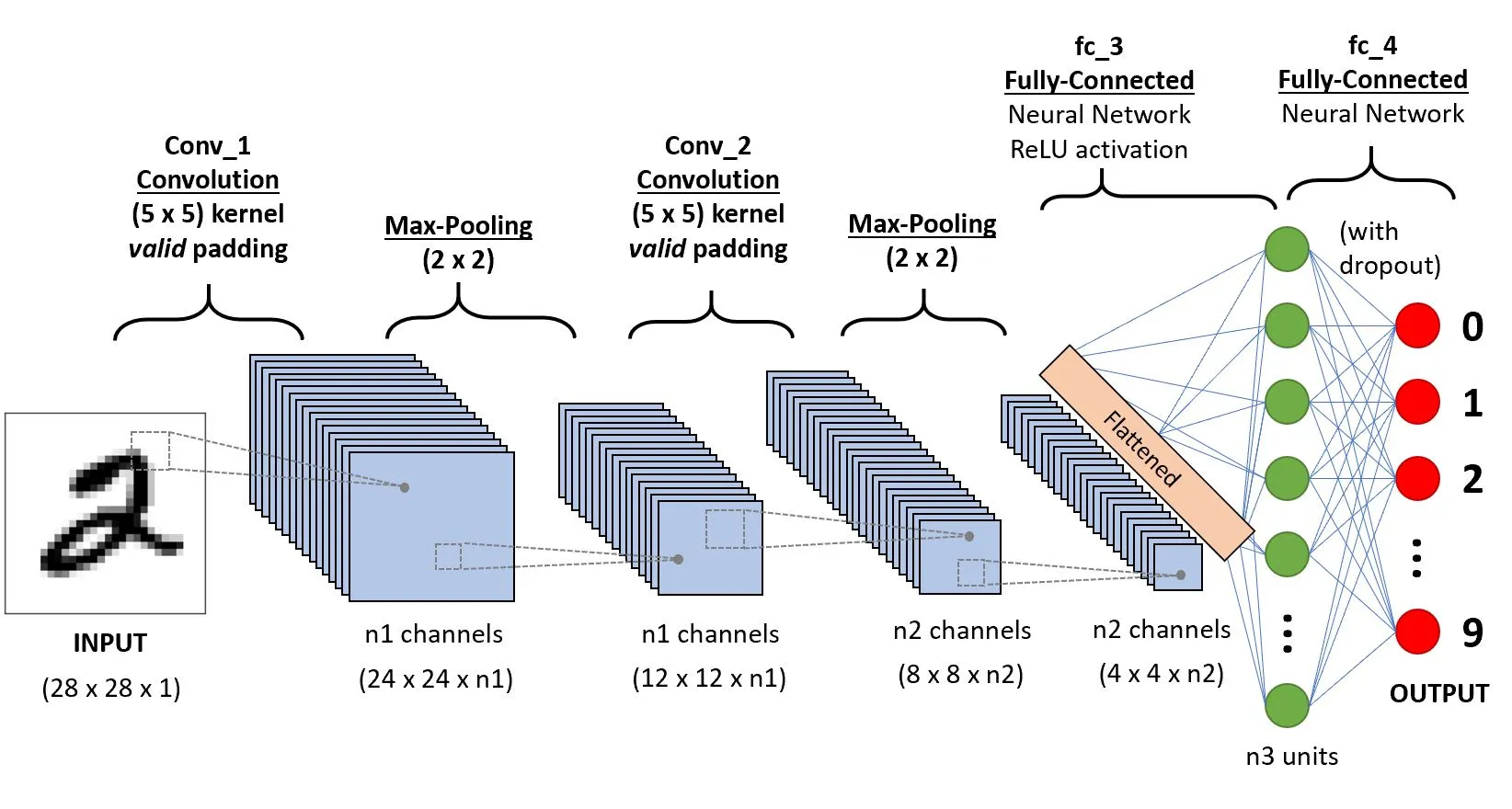
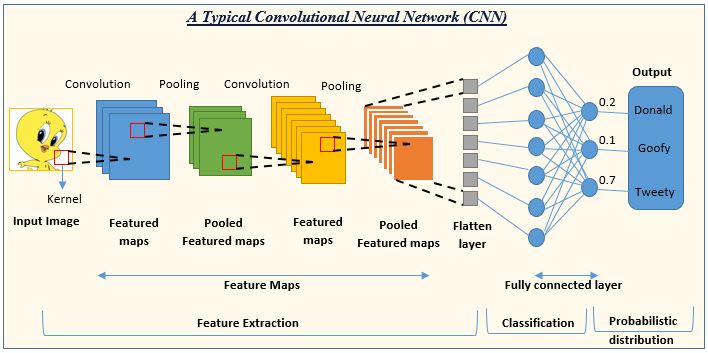
مرحله د) تهیه تست و ارزیابی مدل
معماری مدل کامل است. اجازه دهید به آموزش مدل روی مجموعه داده ادامه دهیم. ما از بهینه ساز Adam استفاده خواهیم کرد. از آنجایی که این یک وظیفه طبقه بندی باینری است (احساس مثبت یا منفی)، می توانیم از تابع خطا باینری متقاطع آنتروپی استفاده کنیم.
به طور کلی، تغییر نرخ یادگیری در طول آموزش برای مشکلات جزئی آموزش مجموعه داده مفید است. برای این کار میتوانیم از Learning rate Schedulers استفاده کنیم. ReduceLROnPlateau نرخ یادگیری را با ضریب 0.1 کاهش می دهد (می توان آن را مشخص کرد) اگر افت اعتبار سنجی کاهش نیابد. در اینجا، مانیتور مورد استفاده در ReduceOnPlateau از دست دادن اعتبارسنجی است. AUC همچنین می تواند به جای آن استفاده شود.
مرحله ه) استفاده از مدل آموزش داده شده
منابع:
https://howsam.org/lstm-neural-network/
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 287
برچسبتحلیل احساس تحلیل نیت طبقه بندی احساسات نظرکاوی
نوشته های مرتبط










همچنین ببینید

دیتاست برای تحلیل احساس و تحلیل نیت فارسی (Persian Sentiment Analysis)
وقتی می خواهیم در مورد مسئله ای تصمیم بگیریم، نظر دیگران را درباره ی مسئله …
