خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
روش انتخاب مدل یادگیری ماشین و داده کاوی بر اساس معیارهای مختلف
انتخاب مدل مناسب برای داده کاوی و یادگیری ماشین همیشه برای افراد تازه کار در حوزه علم داده، موجب سردرگمی آنها می شود. این موضوع حتی برای افراد با تجربه نیز چالش برانگیز است. در این مطلب کوتاه و کاربردی قصد دارم که یک بار برای همیشه این موضوع را در ذهن خوانندگان محترم حل کنم.
عناوين مطالب: '
چگونه روش مناسب داده کاوی را تشخیص دهیم؟
معیارهای زیادی جهت انتخاب مدل وجود دارد که در این مبحث من به چهار تا از مهم ترین معیارها بر اساس تجربه خودم اشاره میکنم.
- انتخاب روش بر اساس هدف از داده کاوی
- انتخاب روش بر اساس بضاعت داده های در دسترس
- انتخاب روش بر اساس میزان سرعت در آموزش و آزمون مدل
- انتخاب روش بر اساس میزان دقت مدل
انتخاب روش بر اساس هدف از داده کاوی
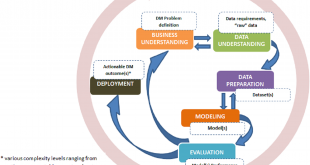
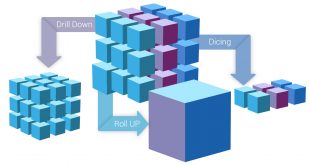
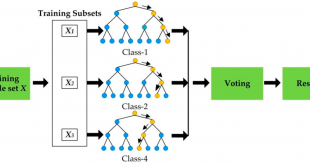
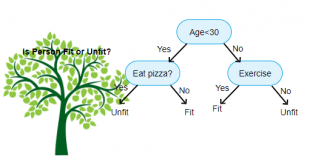
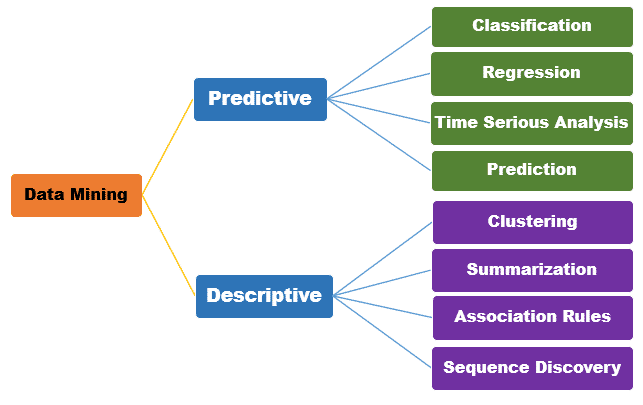
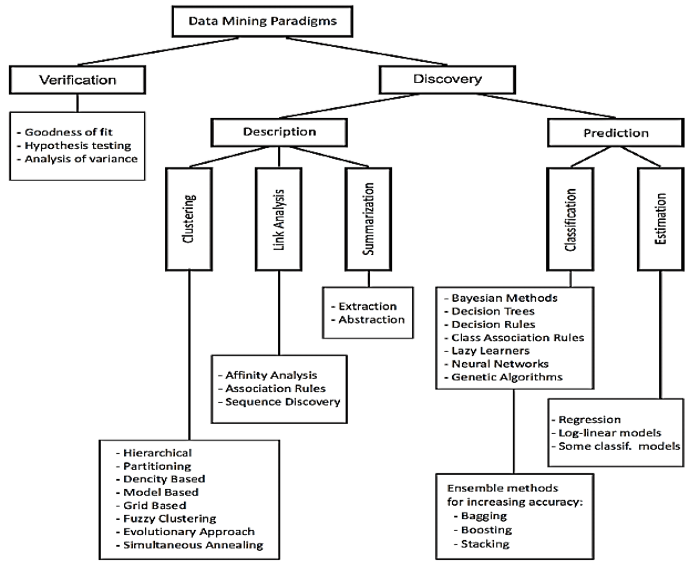
سه تصویر زیر همگی دیدگاهایی رو نمایش میدهند که میبایست بر اساس هدف از داده کاوی یا یادگیری ماشین روش مناسب را تشخیص داد.
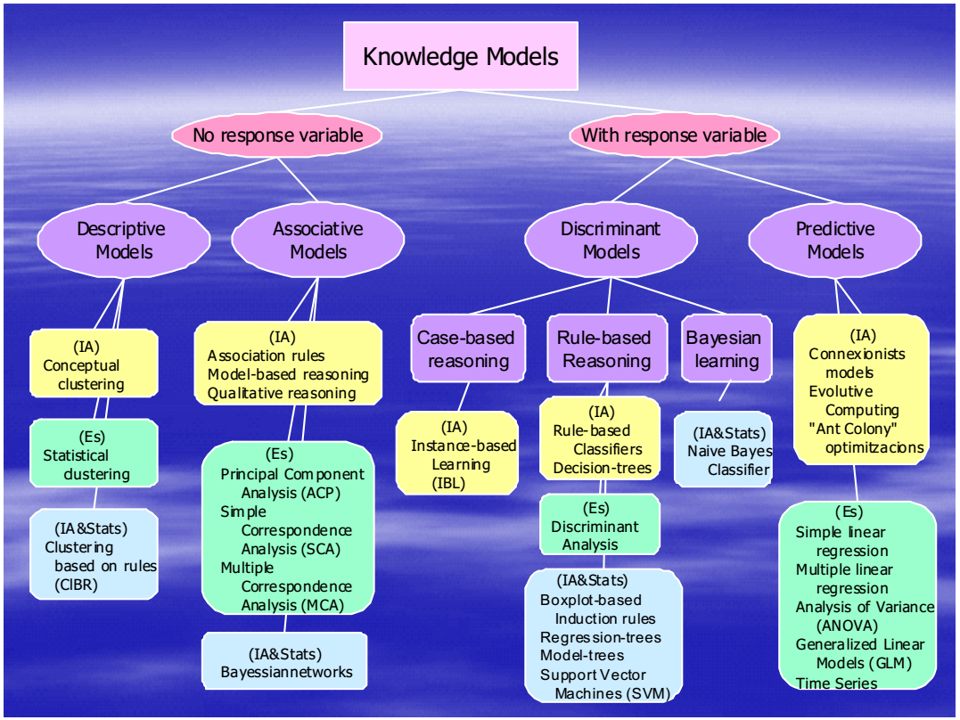
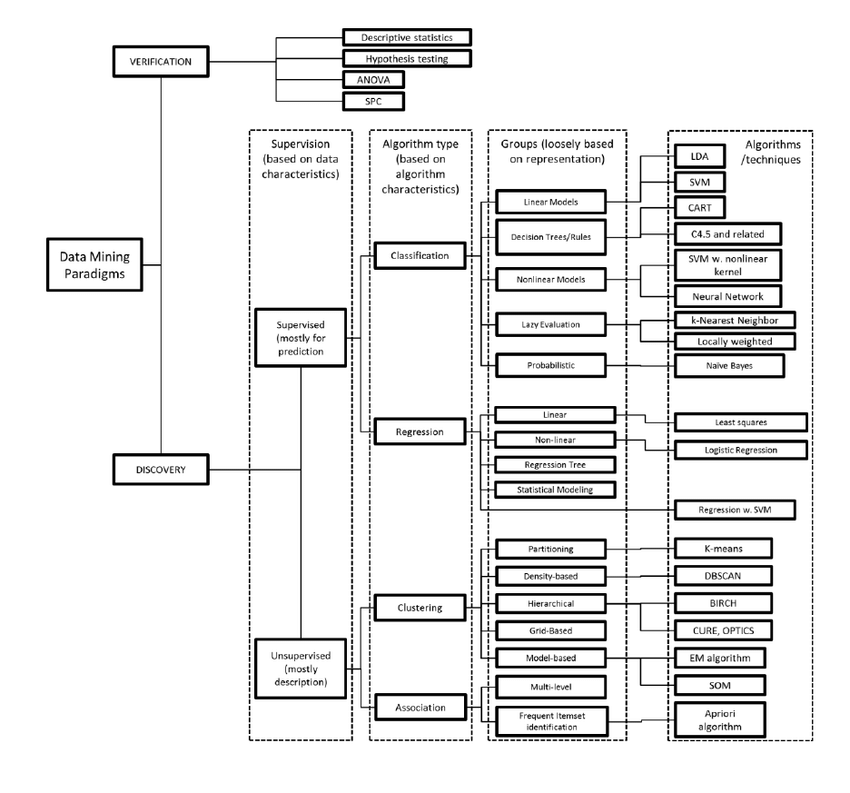
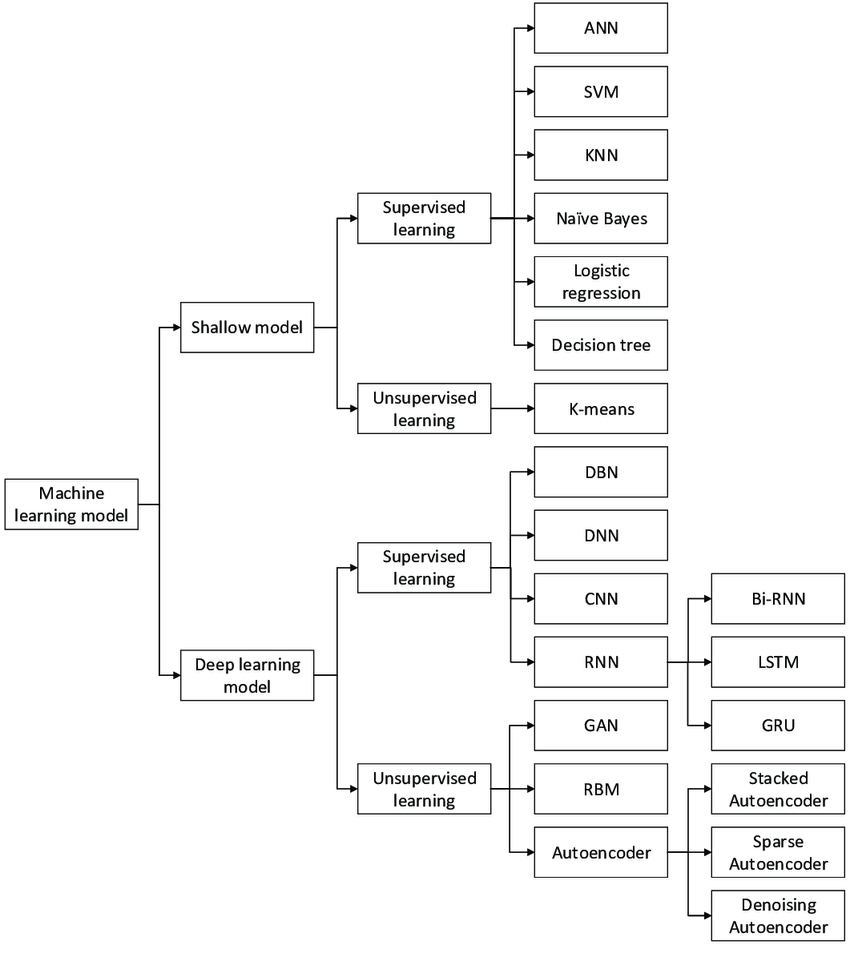
انتخاب روش بر اساس بضاعت داده های در دسترس
تصویر زیر یک فلوچارتِ راهنمایِ بسیار خوب جهت تشخیص الگوریتم های داده کاوی در چهار حوزه طبقه بندی (یادگیری ماشین)، خوشه بندی، کاهش ابعاد و رگرسیون را ارائه میدهد. این تصویر راهنما، بر اساس مقدار و کیفیت مجموعه داده یا دیتاستی که در دسترس است و نوع تحلیلی که قرار است رو آن انجام شود مسیر مطلوب را نمایش میدهد. مربع های سبز رنگ نشان دهنده نام الگوریتم ها و بیضی های آبی رنگ شرایط مورد نظر مبیاشد.
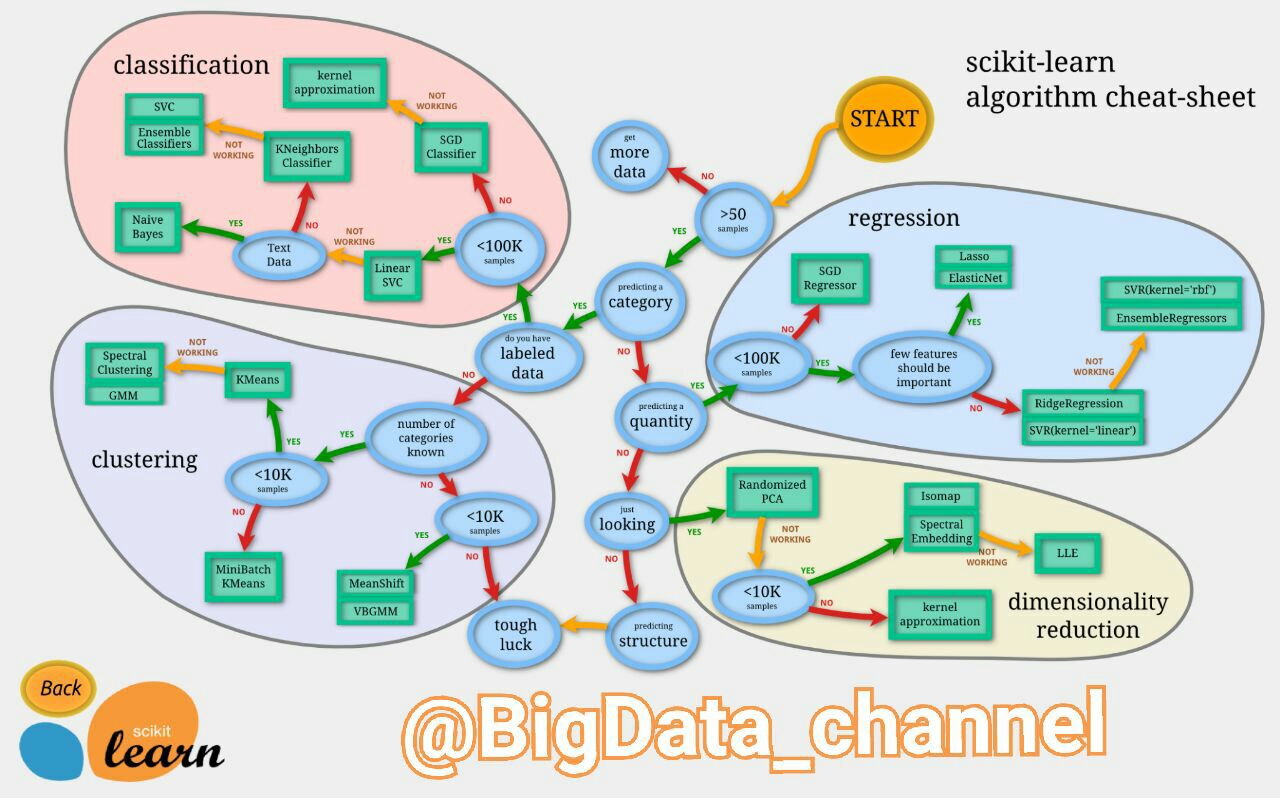
انتخاب روش بر اساس میزان سرعت در آموزش و آزمون مدل
سرعت یاد گیری و سرعت تشخیص و تعداد دفعات آموزش مدل نیز از ویژگی هایی هستن که در تصمیم گیری در انتخاب مدل نقش دارند. به عنوان مثال شکل زیر نمونه ای از این مقایسه ها را برای برخی از روش های یادگیری ماشین نمایش میدهد.
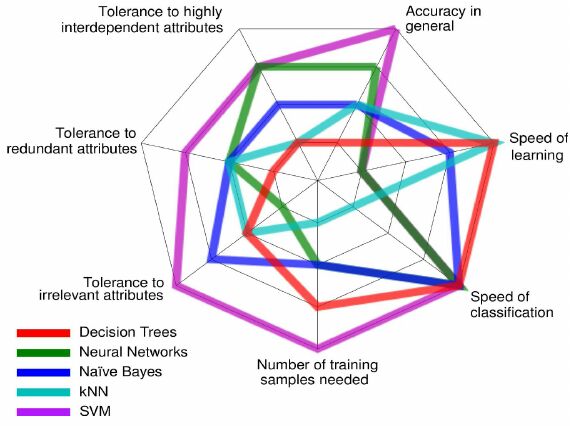
انتخاب روش بر اساس میزان دقت مدل
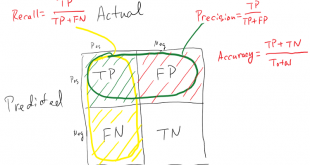
معیارهای متنوعی برای ارزیابی کارایی الگوریتم ها وجود دارد. در انتخاب معیارهای ارزیابی کارایی می بایست دلایل قانع کننده وجود داشته باشد چرا که چگونگی اندازه گیری و مقایسه کارایی الگوریتم ها، کاملا به معیارهایی که انتخاب می کنید وابسته است. همچنین چگونگی وزن دادن به اهمیت ویژگی های مختلف در نتایج، کاملا تحت تاثیر معیار هایی است که انتخاب می کنید.
یک مثل معروف وجود دارد که میگوید «چیزی را نتوانی ارزیابی کنی، نمیتوانی بهبود دهی». در بحث الگوریتمهای طبقه بندی هم برای اینکه مشخص شود آیا الگوریتم مدنظر، بر روی دادههای مسئله خوب جواب داده است یا خیر، بایستی کارایی، دقت یا صخت آن ارزیابی شود.
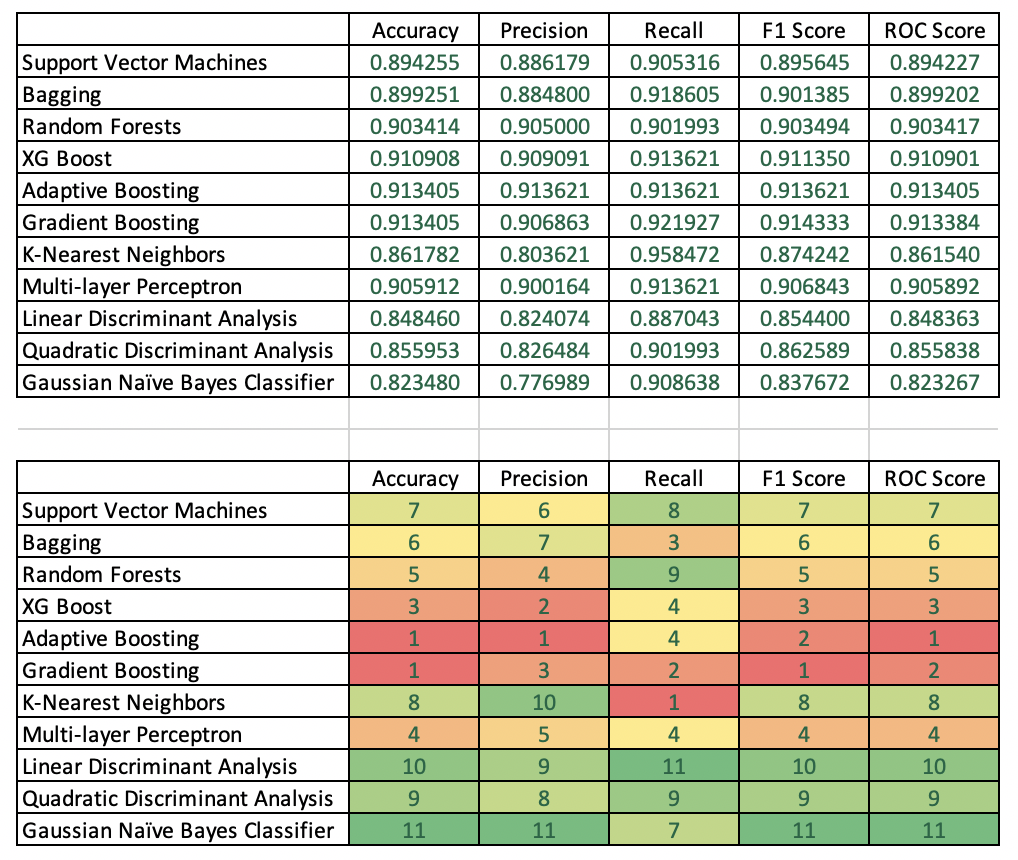
نتایج مقایسه دقت
جدول بالا آمار دقت انواع مدل های مختلف را فهرست می کند. جدول دوم مدل ها را بر اساس ستون رتبه بندی می کند، به عنوان مثال. بهترین مدل ها را بر اساس یکی از پنج معیار دقت شناسایی می کند.
Accuracy: تقویت تطبیقی و Gradient Boosting بهترین دقت آزمون را با نمرات یکسان در 91.34 ایجاد کردند.
Precision صحت: Adaptive Boosting یک برنده واضح بود و پس از آن XG Boost و Gradient Boosting به ترتیب در جایگاه دوم و سوم قرار گرفتند.
Recall: روش K-Nearest Neighbors با امتیاز 95.85 قوی ترین بود. Gradient Boosting دوم شد.
F1 Score: برای Gradient Boost بهترین بود و پس از آن به ترتیب Adaptive Boost و XG Boost قرار گرفتند.
امتیاز ROC: تقویت تطبیقی بهترین امتیاز را به دست آورد و سپس اGradient Boosting و سپس XG Boost به دست آورد.
تصمیم گیری بر اساس میزان دقت مدل
فرض کنید یک سازمان غیر انتفاعی احتمالا مجبور خواهد شد تا حد امکان عاقلانه از بودجه بازاریابی خود استفاده کند: سودآوری کلیدی است. در نتیجه، دقت و امتیاز F1 بسیار مهم است. در نتیجه، adaptive boosting احتمالاً انتخاب بهتری است زیرا همان دقت gradient boosting را ارائه می دهد اما با دقت بهتر. در حالی که gradient boosting امتیاز F1 بهتری نسبت به adaptive boosting دارد، این تفاوت حداقلی است. علاوه بر این، adaptive boosting امتیاز ROC بهتری دارد که به این معنی است که مدل در جداسازی اهداکنندگان از غیر اهداکنندگان بهتر است.
انتخابِ روش استخراج ویژگی (Feature extraction)
با توجه بع توضیحات فوق اولین قدم بدست آوردن تمام وییژگی های داده ی مورد نظر است. تا بتوان در مراحل بعدی ویژگی های برتر را گل چین نمود. روشهای استخراج ویژگی با ترکیب ویژگیهای اصلی به کاهش ابعاد دست مییابند. از این رو، قادر به ساخت مجموعهای از ویژگیهای جدید هستند که معمولا فشردهتر و دارای خاصیت متمایزکنندگی بیشتری است.

انتخاب ویژگی (Feature Selection)
شاید مهمترین بخش برای عملیاتِ دادهکاویْ عملیاتِ انتخابِ ویژگی است. در گام انتخاب ویژگی با حذف ویژگیهای غیر مرتبط و تکراری میتوان ابعاد مسئله را کاهش داد. در مباحثِ آکادمیک معمولا ویژگیها در مسئله در اختیار کاربران قرار دارند ولی در مباحث عملی یک متخصص علومداده بایستی خود ویژگیهای مورد نیاز را از میان دادگان استخراج کند. انتخاب ویژگی که با عناوین دیگری همانند Variable Selection و Attribute Selection و نیز Variable Subset Selection شناخته می شود. انتخاب ویژگی را میتوان به عنوان فرآیند شناسایی ویژگیهای مرتبط و حذف ویژگیهای غیر مرتبط و تکراری با هدف مشاهده زیرمجموعهای از ویژگیها که مساله را به خوبی تشریح میکنند تعریف کرد.
کل مجموعه ویژگی میتواند به طور مفهومی به چهار بخش مجزا تقسیم شود که عبارتند از:
- ویژگیهای نامرتبط
- ویژگیهای به طور ضعیف مرتبط و ویژگیهای دارای افزونگی
- ویژگیهای به طور ضعیف مرتبط ولی فاقد افزونگی
- ویژگیهای به شدت قدرتمند
لازم به ذکر است که مجموعه بهینه حاوی همه ویژگیهای موجود در بخشهای 3و 4میشود.
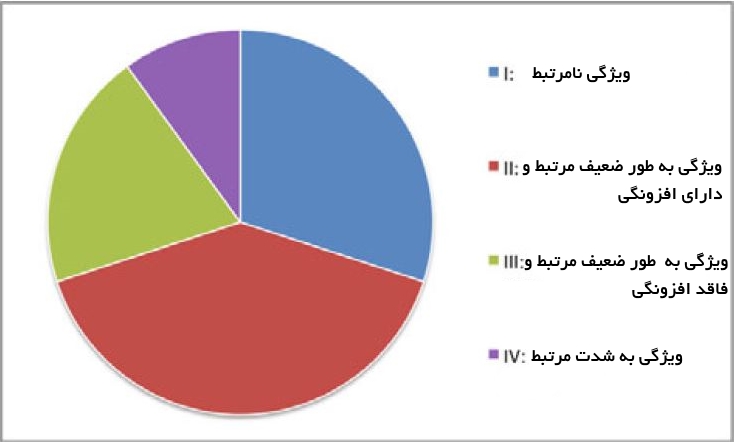
روش های انتخاب ویژگی (Feature Selection)
سه رویکرد کلی انتخاب ویژگی با توجه به ارتباط بین الگوریتمهای انتخاب ویژگی و روش یادگیری مورد استفاده قرار میگیرند. این موارد در ادامه بیان شدهاند.
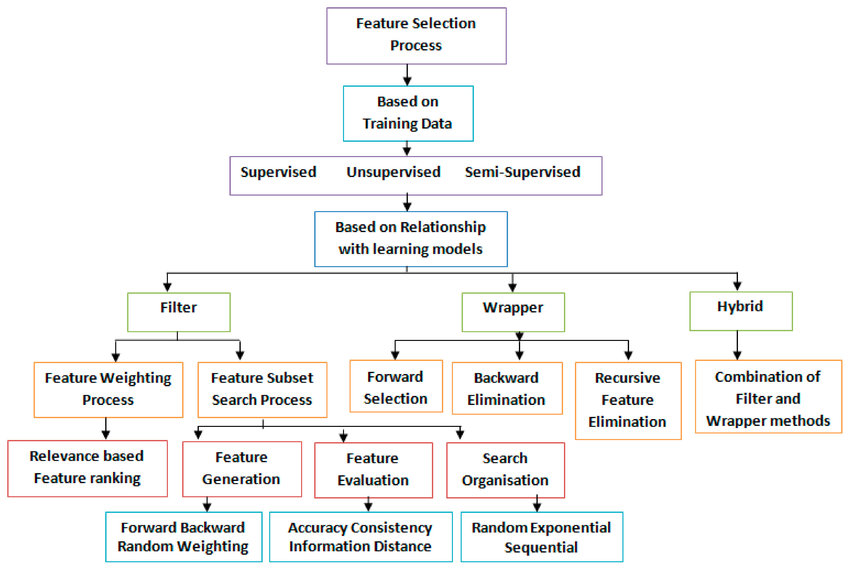
«فیلترها» (Filters) بر ویژگیهای کلی مجموعه داده آموزش تکیه دارند و فرآیند انتخاب ویژگی را به عنوان یک گام پیش پردازش با استقلال از الگوریتم استقرایی انجام میدهند. مزیت این مدلها هزینه محاسباتی پایین و توانایی تعمیم خوب آنها محسوب میشود.
«بستهبندها» (Wrappers) شامل یک الگوریتم یادگیری به عنوان جعبه سیاه هستند و از کارایی پیشبینی آن برای ارزیابی مفید بودن زیرمجموعهای از متغیرها استفاده میکنند. به عبارت دیگر، الگوریتم انتخاب ویژگی از روش یادگیری به عنوان یک زیرمجموعه با بار محاسباتی استفاده میکند که از فراخوانی الگوریتم برای ارزیابی هر زیرمجموعه از ویژگیها نشات میگیرد. با این حال، این تعامل با دستهبند منجر به نتایج کارایی بهتری نسبت به فیلترها میشود.
«روشهای توکار» (Embedded) انتخاب ویژگی را در فرآیند آموزش انجام میدهند و معمولا برای ماشینهای یادگیری خاصی مورد استفاده قرار میگیرند. در این روشها، جستوجو برای یک زیرمجموعه بهینه از ویژگیها در مرحله ساخت دستهبند انجام میشود و میتوان آن را به عنوان جستوجویی در فضای ترکیبی از زیر مجموعهها و فرضیهها دید. این روشها قادر به ثبت وابستگیها با هزینههای محاسباتی پایینتر نسبت به بستهبندها هستند.
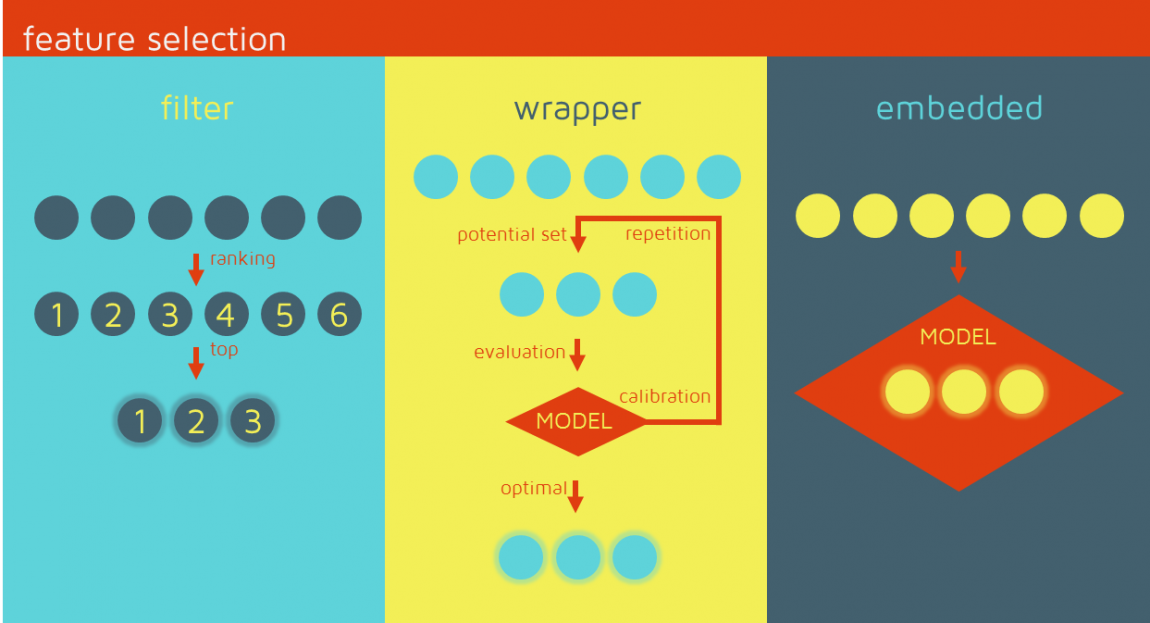
عناوین روش های انتخاب ویژگی (Feature Selection)
سه رویکرد کلی انتخاب ویژگی با توجه به ارتباط بین الگوریتمهای انتخاب ویژگی و روش یادگیری مورد استفاده قرار میگیرند. این موارد در ادامه بیان شدهاند. همراه با اسامی آنها در شکل زیر آورده شده است.
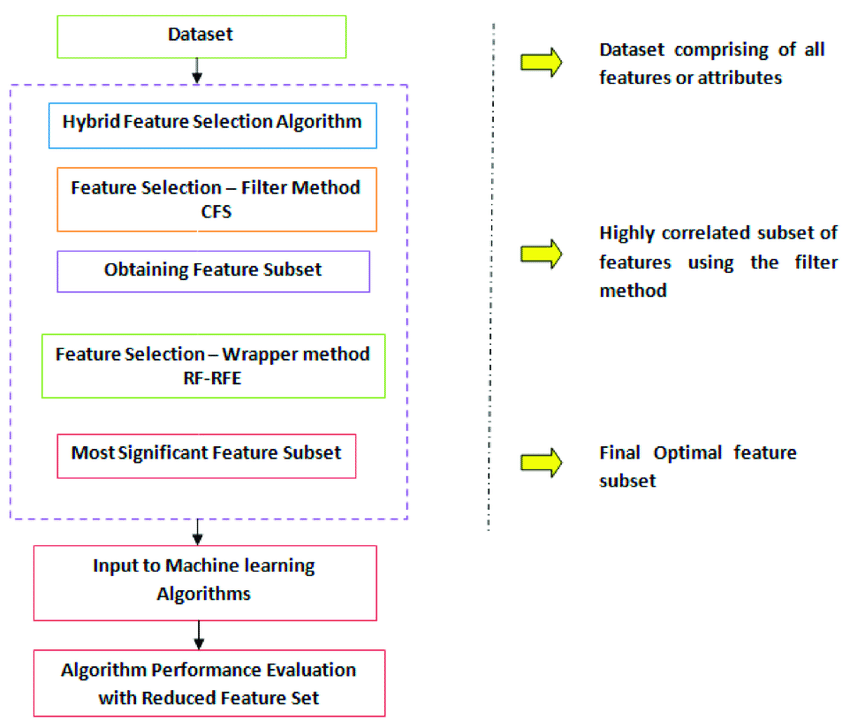
نمونه ای از بکارگیری روش های ترکیبی برای آشنایی بیشتر در شکل زیر نمایش داده شده است.
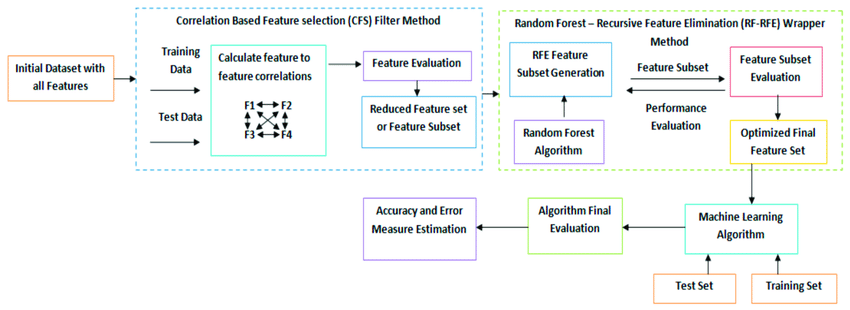
منابع:
https://www.datasklr.com/select-classification-methods/model-selection
برای دیدن فلیم های سینماییِ مهیج و جذاب”در حوزه فناوری اطلاعات، اوسینت و هوش مصنوعی“، بر روی اینجا کلیک کنید.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
یادگیری ماشین
بازدیدها: 1067
برچسبآزمون مدل انتخاب مدل بر اساس میزان دقت بر اساس میزان سرعت بضاعت داده داده های در دسترس روش مناسب داده کاوی سرعت در آموزش میزان دقت مدل هدف از داده کاوی