 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش کامل پلتفرم کلودرا (Cloudera) در هدوپ با رویکرد ساده سازی بیگ دیتا
هدوپ یک پروژه مبتنی بر برنامه نویسی متن باز است که توسط سازمان نرم افزاری آپاچی ایجاد شده است. ایده اولیه هدوپ اولین بار در شرکت گوگل رقم خورد اما خیلی ها باور به پیاده سازی این سیستم نداشتن و در چند سال اول این ایده تنها بصورت تئوری مطرح بود. هدوپ امکان ذخیره سازی اطلاعات را در چندین سرور ( پی سی) با هزینه ای پایین فراهم می آورد. کلودرا شرکتی است که بصورت فعال در این زمینه فعال می باشد و بسته نرم افزاری بی نظیر هدوپ را ایجاد کرده و آن را انتشار داده و پشتیبانی می کند. از تجزیه و تحلیل گرفته تا علم داده، هر کسی می تواند از هر داده و در هر محیطی نتیجه بگیرد. Cloudera Enterprise سریع ترین، ساده ترین و امن ترین پلت فرم داده مدرن است. همه فعالیت ها در یک پلت فرم واحد و مقیاس پذیر در دسترس هست.
چه در حال تقویت حجم کار مهندسی داده و علم داده باشید، چه یک پایگاه داده عملیاتی یا تحلیلی بسازید، یا به دنبال جمع آوری همه آنها در یک مرکز داده سازمانی باشید، Cloudera دارای پلتفرم مناسبی است که متناسب با نیازهای شما باشد.
عناوين مطالب: '
کلودرا چیست؟ شرکت ابر داده های سازمانی
کلودرا Enterprise Bigdata توسط Apache Hadoop پشتیبانی می شود. Cloudera Enterprise سریع ترین، ساده ترین و امن ترین پلت فرم مدرن داده است. از تجزیه و تحلیل گرفته تا علم داده، اکنون هر کسی میتواند از هر داده و در هر محیطی نتیجه بگیردکه همه و همه در یک پلتفرم واحد و مقیاسپذیر به نام کلودرا وجود دارد.
Enterprise Bigdata امکانات بیپایانی را با دادههای شرکت ارائه میدهد. این امکانات شامل تقویت حجم کاری مهندسی داده و علم داده، ساخت یک پایگاه داده عملیاتی یا تحلیلی، یا حتی گردآوری همه آنها در یک مرکز داده سازمانی است. Cloudera پلتفرم مناسبی را برای مطابقت با نیازهای کاربران فراهم می کند، کاربران می توانند مهندسان داده و دانشمندان داده خود را برای ایجاد خطوط لوله داده بلادرنگ، سرعت پردازش داده ها و توسعه و آموزش مدل های داده گرد هم بیاورند.
معماری فناوری اطلاعات شرکت را برای فعال کردن ELT و تجزیه و تحلیل SQL با کارایی بالا برای گزارشدهی، کاوش، و هوش تجاری سلف سرویس، مدرن میکند. پایگاه داده عملیاتی کلودرا Enterprise Bigdata برنامههای کاربردی مبتنی بر داده ایجاد میکند که همچنین بینشهای بیدرنگ را برای نظارت و شناسایی، ارائه میکند.
پخش برنامه های کاربردی مانند اینترنت اشیا و امتیازدهی و سرویس دهی مدل. با راه حل موثر داده کلودرا، ابزارهای مناسبی را برای جذب، پردازش و ارائه داده ها در عین حفظ امنیت ارائه می دهد. اگر یک پیوند ضعیف در هر نقطه از این زنجیره ارزش داده میتواند توانایی سازمان را برای استخراج بینش از دادههای خود از بین ببرد.
رهبری Cloudera در هر یک از این دستهها به مشتریان در صنایع کمک کرده است تا کسبوکارهای بهتری بسازند. مدیر کلودرا ابزار مدیریت Hadoop است که مورد اعتماد متخصصان است. در حقیقت کلودرا بزرگترین استقرار Hadoop را قدرت میدهد. کلودرا با پیشفرضهای هوشمند و سفارشیسازیهای نظارتی منحصربهفرد، عملیات خوشه را به شدت ساده میکند. با معماری قابل توسعه طراحی شده است، به سرعت و به طور یکپارچه با ابزارهای شخص ثالث و جدیدترین اجزای Hadoop برای عملیات یکپارچه و قابل اعتماد یکپارچه می شود.
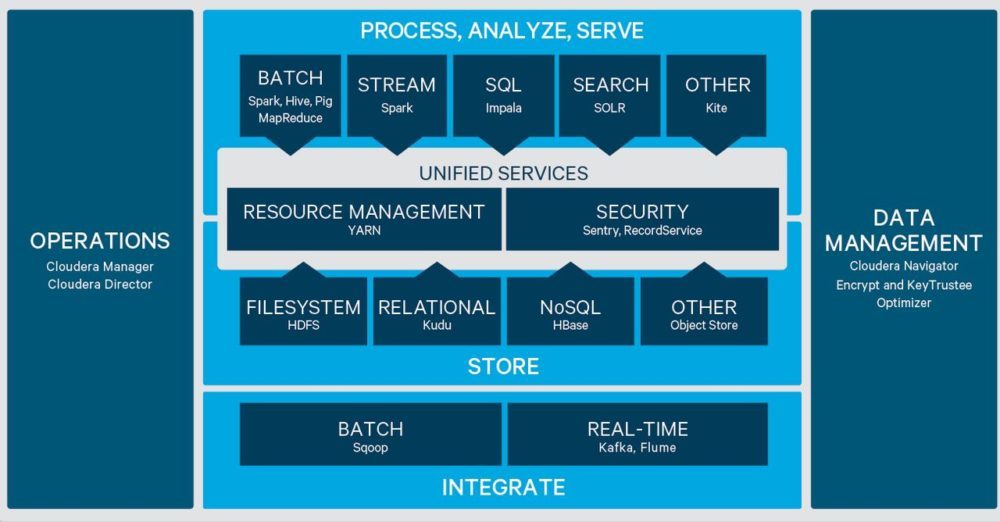
نمونه ای از مورد استفاده کلودرا
LG Uplus به عنوان یکی از اولین ارائه دهندگان مخابراتی که خدمات 5G را تجاری می کند، از سال 2019 بر ارائه خدمات نوآورانه به مشتریان خود و افزایش بازده کاری کارکنان شبکه متمرکز بوده است. با پایه گذاری پلتفرم داده کلودرا، LG Uplus شبکه Real-Real- را تأسیس کرد. بستر تحلیلی زمان (NRAP)، که شامل زیرساختهای لازم برای جمعآوری و تجزیه و تحلیل دادههای بزرگ در مقیاس بزرگ در زمان واقعی، از دستگاههای تلفن همراه تا تجهیزات خدماتی شرکت مخابرات است.
NRAP استفاده از داده ها و دقت تجزیه و تحلیل را با ارائه قابلیت های دریاچه داده و انبار داده که شامل پردازش و انتقال ترابایت داده در عرض چند ثانیه به سیستم مدیریت شبکه یکپارچه (NMS) است، بهبود می بخشد. LG Uplus با قابلیت پردازش بیدرنگ داده NRAP توانسته است به مزایای تجاری مانند بهبود زمان پاسخگویی با کیفیت مشتری مرکز مشتری و افزایش سطح نظارت بر کیفیت شبکه مبتنی بر خدمات تا نزدیک به زمان واقعی دست یابد و در نتیجه رضایت مشتری را بهبود بخشد. و میزان کلی کار میدانی را کاهش می دهد. LG Uplus با یک پلت فرم یکپارچه که از نظارت و تجزیه و تحلیل کیفیت در زمان واقعی خدمات شبکه پشتیبانی می کند، داده ها را بر اساس نوع جمع آوری و دسته بندی می کند و آنها را روی یک داشبورد نظارت می کند تا هزینه های عملیاتی شبکه را کاهش دهد و کارایی کار را بهبود بخشد.
NRAP که در زمانی که خدمات 5G برای اولین بار تجاری شد، به عنوان یک آزمایش راه اندازی شد، اکنون صدها نوع و صدها ترابایت داده تولید شده روزانه از خدمات شبکه مخابراتی را مدیریت می کند و به LG Uplus این امکان را می دهد تا بینش معناداری از داده ها به دست آورد و خدمات را مدیریت کند. در مجموع 20 میلیون کاربر در کره جنوبی.
اجزای پلتفرم داده کلودرا Cloudera Data Platform (CDP)
CDP بهترین فناوریهای Hortonworks و Cloudera را برای ارائه یک ابر داده سازمانی که شامل یک صفحه کنترل یکپارچه برای مدیریت زیرساختها، دادهها و بارهای کاری تحلیلی در سراسر محیط است، ترکیب میکند.
CDP Cloud شامل تعدادی سرویس ابری است که برای رسیدگی به موارد استفاده از ابر داده های سازمانی خاص طراحی شده اند. این شامل Data Hub است که توسط Cloudera Runtime، برنامه های سلف سرویس (Data Warehouse و Machine Learning)، لایه اداری (کنسول مدیریت) و خدمات SDX (Data Lake، کاتالوگ داده، Replication Manager، و Workload Manager) ارائه می شود.
CDP میتواند امنیت، حاکمیت و کنترل دادهها را اعمال کند که میتواند از حریم خصوصی دادهها، انطباق با مقررات محافظت کند و از تهدیدات امنیت سایبری جلوگیری میکند. این یک پلت فرم داده یکپارچه است که به راحتی قابل استقرار، مدیریت و استفاده است. CDP با سادهسازی عملیات، زمان ورود موارد استفاده جدید را در سراسر سازمان کاهش میدهد. از یادگیری ماشینی (ML) استفاده می کند تا به صورت خودکار بارهای کاری را بالا و پایین کند تا از زیرساخت ابری مقرون به صرفه تر استفاده کند.
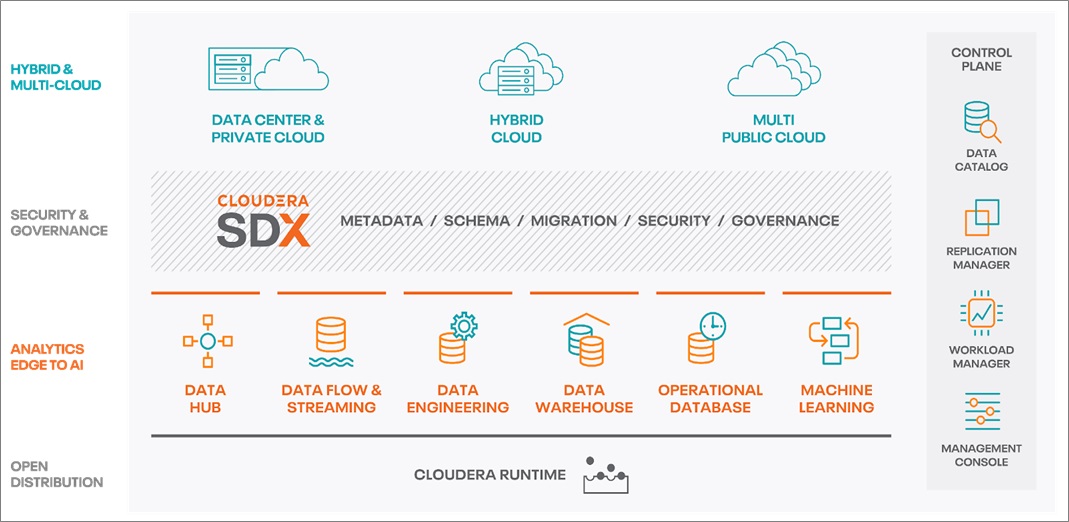
- CDP Data Engineering
- CDP Operational Database
- CDP Data Visualization
CDP Data Engineering: یک سرویس قدرتمند Apache Spark در Kubernetes است و شامل قابلیتهای کلیدی افزایش بهرهوری است که معمولاً با سرویسهای مهندسی داده اولیه در دسترس نیستند. آماده سازی داده ها برای تجزیه و تحلیل و موارد استفاده تولید در طول چرخه عمر داده ها برای تبدیل داده ها به ارزش تجاری بسیار مهم است. CDP Data Engineering یک سرویس مهندسی داده هدفمند برای تسریع خطوط لوله داده های سازمانی از جمع آوری و غنی سازی تا بینش در مقیاس است.
CDP Operational Database: یک سرویس پایگاه داده NoSQL با کارایی بالا است که مقیاس و کارایی را برای برنامه های کاربردی عملیاتی حیاتی کسب و کار فراهم می کند. این پشتیبانی از طرحواره تکاملی را ارائه می دهد تا از قدرت داده ها استفاده کند و در عین حال انعطاف پذیری در طراحی برنامه را با اجازه دادن به تغییرات در مدل های داده های زیربنایی بدون نیاز به ایجاد تغییرات در برنامه حفظ کند. علاوه بر این، مقیاس خودکار را بر اساس استفاده از بار کاری خوشه برای بهینه سازی استفاده از زیرساخت ارائه می دهد.
CDP Data Visualization: تجسم دادههای CDP، مدیریت داشبوردها، گزارشها و نمودارهای غنی و بصری را ساده میکند تا بینش تحلیلی چابکی را به زبان کسبوکار فراهم کند، دسترسی مردمی به دادهها و تجزیه و تحلیلها را در سطح سازمان در مقیاس بزرگ ارائه دهد. این به تیم های فنی اجازه می دهد تا به سرعت مدل های تحلیل و یادگیری ماشین را با استفاده از برنامه های کاربردی تعاملی سفارشی کشیدن و رها کردن به اشتراک بگذارند. این اطلاعات بینش داده ای را برای تیم های تجاری و تصمیم گیرندگان فراهم می کند تا تصمیمات تجاری قابل اعتماد و آگاهانه اتخاذ کنند.
ساختار کلی هدوپ
تکنولوژی هدوپ از دو بخش کلی اچ دی اف اس یا سیستم فایل انتشاری هدوپ (Hadoop Distribition File System) و همچنین تکنیک با کیفیت پردازی اطلاعات به نام مپ ریدیوس (MapReduce) استفاده می کند.
ساختار کلی اطلاعاتی در هدوپ بدینگونه می باشد که اطلاعات توسط سیستم هدوپ شکسته شده و به چندین سرور فرستاده می شود. سرورها بسته به نوع اطلاعات که ممکن است پردازشی یا ذخیره ای باشد اطلاعات را پردازش یا ذخیره سازی می کنند. در هنگام در خواست اطلاعات مجدد سیستم اطلاعات را از سرور های مختلف گرفته ، مونتاژ کرده و در خروجی نمایش می دهد. در ادامه بررسی مختصری از نحوهی عملکرد سرویسهای آن، هم بهطور مجزا و هم در همکاری با یکدیگر میپردازم که میتوان گفت در مجموع اکوسیستم هدوپ را تشکیل میدهند:
- HDFS : سیستم فایل توزیع شدهی هدوپ
- YARN: چارچوبی برای مدیریت منابع و زمانبندی
- MapReduce: موتور پردازش دادهها با استفاده از APIهای زبان برنامهنویسی
- Spark: موتور پردازش دادهها مبتنی بر رویکرد درون حافظه[۱]
- PIG, HIVE : سرویسهای پردازش داده با استفاده از زبانهای پرسوجو نظیر SQL
- HBase: پایگاه دادهی غیر رابطهای
- Mahout, Spark MLlib: چهارچوبهای یادگیری ماشین
- Apache Drill: زبان پرسوجو SQL بروی هدوپ
- Zookeeper: مدیریت خوشه (کلاستر)
- Oozie : زمانبند کار
- Flume, Sqoop : سرویسهای جمعآوری داده
- Solre & Lucene: جستجو و شاخص گذاری
- Ambari: آمادهسازی، نظارت و نگهداری از خوشه
HDFS فایل سیستم توزیع شده هدوپ
هدوپ دو واحد اصلی دارد: حافظه و پردازش. وقتی در مورد بخش حافظهی هدوپ صحبت میکنیم، منظور HDFS است که مخفف عبارت سیستم فایل توزیعشدهی هدوپ است. از همین رو در این پست، HDFS را به شما معرفی خواهم شد.
به طور کلی، یک سیستم فایل توزیع شده اهدافی یکسان با سیستم فایلی که تابحال در اختیار داشتید (برای مثال NTFS در ویندوز، HFS در مک و یا EX4 در لینوکس) را در پیش میگیرد. تنها تفاوت این است که، در حالت سیستم فایل توزیعشده شما داده را به جای یک دستگاه در چند دستگاه ذخیره میکنید. بااینکه فایلها در شبکه ذخیره میشوند، DFS دادهها را به گونهای سازمان داده و نمایش میدهد که کاربری که مشغول کار با دستگاه است حس میکند که تمام دادهها بصورت واحد و در یک دستگاه ذخیره شدهاند. سیستم فایل توزیعشدهی هدوپ یا HDFS یک سیستم فایل توزیعشده بر اساس جاوا است که شما را قادر میسازد که دادههای حجیم را در چندین گره در یک کلاستر هدوپ ذخیره کنید.
تصور کنید که ۱۰ دستگاه یا ۱۰ کامپیوتر دارید که هر کدام هارد درایوی با ظرفیت ۱ ترابایت دارند. در این حالت، HDFS میگوید که اگر شما هدوپ را به عنوان سکویی بروی این ده ماشین نصب کنید، به HDFS به عنوان سرویس ذخیره دسترسی خواهید داشت. به این معنا است که شما میتوانید یک فایل ۱۰ ترابایتی را طوری ذخیره کنید که در تمام ۱۰ گره (هرکدام ۱ ترابایت) توزیع شود. بنابراین، این روند به محدودیتهای فیزیکی هر یک از گرهها محدود نمیشود. همچنین شما میتوانید از طریق هر کدام از ۱۰ گره موجود در مجموعهی هدوپ به سیستم فایل توزیعشدهی هدوپ دسترسی پیدا میکنید.
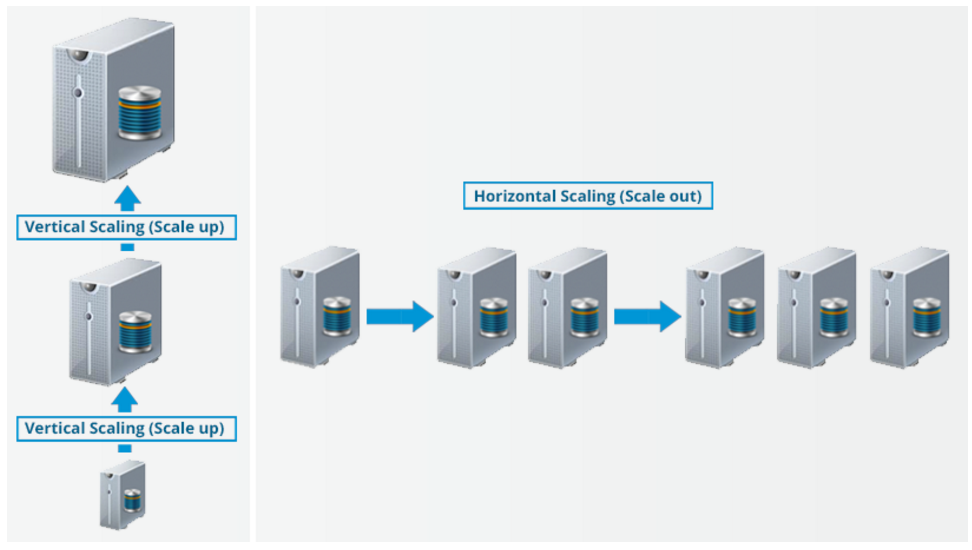
در سیستم فایلهای توزیع شده به منظور افزایش و یا کاهش ظرفیت ذخیره سازی میتوان از دو روش مقیاسپذیری استفاده کرد: مقیاسپذیری عمودی و افقی. در مقیاسپذیری عمودی (scale up)، ظرفیت سختافزاری سیستم را افزایش میدهیم. در حالت مقیاسپذیری افقی (scale out)، به جای افزایش ظرفیت سختافزار هر دستگاه، به کلاستر موجود گرههای بیشتری اضافه میکنید. و مهمتر از همه این است که میتوانید دستگاههای بیشتری که در حال فعالیت هستند را بدون متوقف کردن سیستم اضافه کنید. بنابراین، در حین مقیاسپذیری افقی هیچ زمانی نیاز نیست به منظور افزایش و یا کاهش مقیاس کلاستر، عملکرد آن را متوقف کرد.
اجزای HDFS
HDFS هر فایل را به صورت یک دنباله از بلوکها ذخیره میکند، که تمام بلوکهای موجود در یک فایل به غیر از آخرین بلوک هم اندازه هستند. از بلوکهای متعلق به یک فایل برای تحملپذیری در برابر خطا، نسخه کپی تهیه میشود (replication). اندازه بلوک و فاکتور تهیه کپی، در هر فایل قابل تنظیم است. فایلهای موجود در HDFS همه “wrire once” هستند و تنها یک نویسنده در هر زمان دارند. توپولوژی مورد استفاده در HDFS به صورت معماری Master/Slave است. مولفه هایی که در خصوص معماری سیستم فایل HDFS در آپاچی هدوپ شامل موارد زیر هستند:
- NameNode : گره ای که از همه متا دیتا ها و اطلاعات رک ها و خوشه ها با خبر است که کعکولا باید کامپوتری قوی تر نسبت به بقیه باشد.
- DataNode : گره های slave برای نگهداری بلوکهای داده با کامپوترهای ضعیف تر
- NameNode Secondary: یک گره سینک شده با گره NameNode
- بلاک دادهها در HDFS: بخشبندی های داده که معمولا خیلی بزرگ از تر بلوک ها در فایل سیستم های معمولی است.
- مدیریت تکرارها: بر اساس فاکتور تکرار (مثلا سه) معمولا بلوک های داده را در دو DataNode در یک رک و یک DataNode در رک دیگر نگهداری میکند.
- قابلیت آگاهی از رک در HDFS
- مکانیسم خواندن و نوشتن داده در HDFS
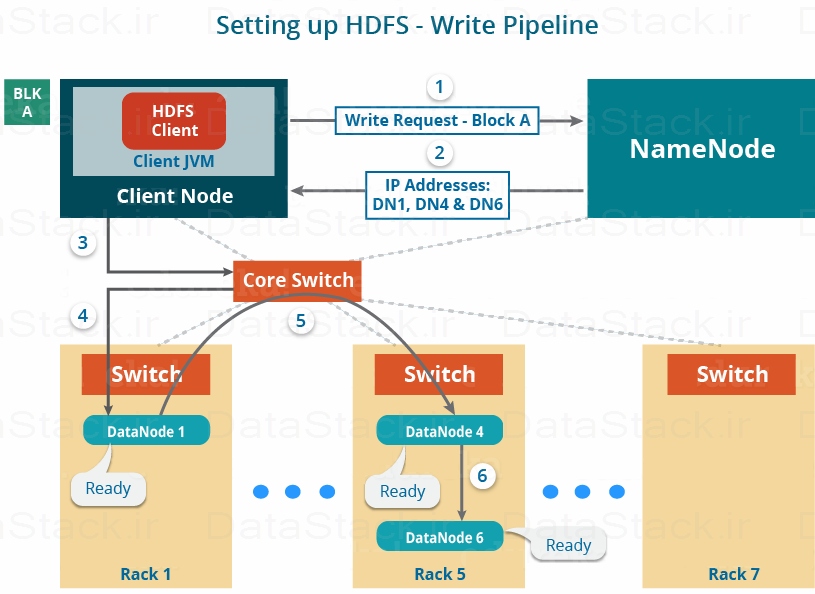
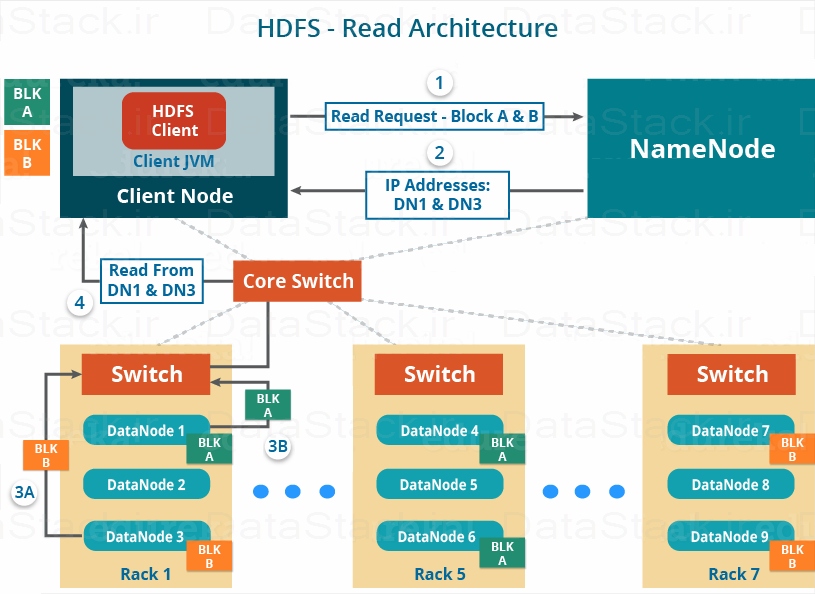
ویژگیهای HDFS
در بخشهای دیگر با تفصیل بیشتری در مورد ویژگیهای هدوپ صحبت شده است. اما در حال حاضر، نگاهی اجمالی بر ویژگیهای HDFS خواهیم داشت داشت.
- هزینه: به طور کلی، HDFS میتواند بر روی یک سختافزار ارزان قیمت مانند دسکتاپ/لپتاپ که هر روز از آن استفاده میکنید تا سرورهای ویژه و گران قیمت اجرا شود. بنابراین راه حل بسیار مقرون به صرفهایی برای ذخیرهسازی دادهها در مقیاس بالا است. چون ما از سختافزار مناسب ارزانقیمت استفاده میکنیم، نیازی ندارید که برای مقیاسپذیری افقی کلاستر هدوپ هزینهی زیادی صرف کنید. به بیان دیگر، اضافه کردن گرههای بیشتر به HDFS (مقیاسپذیری افقی) از نظر اقتصادی نسبت به تهیه سختافزار قویتر مقرون به صرفهتر است.
- تنوع و حجم داده: تنوع و حجم دو مورد از ویژگیهای محیط کلان داده می باشند که میتوان براحتی این موارد را در HDFS مدیریت کرد. در HDFS، میتوان دادههای حجیمی مانند چندین ترابایت و یا پتابایت را در انواع مختلف داده ذخیره کرد. بنابراین میتوانید هر نوع دادهای اعم از ساختاریافته، غیرساختاریافته یا نیمهساختاریافته را در آن ذخیره کنید.
- قابلیت اطمینان و مقاومت در برابر خطا: وقتی دادهها را بر روی HDFS ذخیره میکنید، به صورت خودکار دادههای ورودی به بلاکهای دادهای تقسیم میشود و آنها به سبک توزیعشده در کلاستر هدوپ ذخیره میشود. اطلاعات مربوط به اینکه چه بلاک دادهای در کدام گره داده قرار گرفته، بصورت فرادادهای برای آن داده ذخیره میشود. NameNode فرادادهها را مدیریت میکند و DataNodeها مسئول ذخیرهی دادهها هستند. NameNode همچنین مدیریت تکرار دادهها را برعهده دارد. یعنی چندین کپی از دادهها را نگهداری میکند. این تولید مجدد دادهها HDFS را برابر خرابی گره بسیار ایمن میکند. بنابراین، حتی اگر هر کدام گرهها از کار بیفتند، میتوانیم دادهها را از طریق نسخههای دیگر موجود بر سایر گرهها بازیابی کنیم. به صورت پیشفرض، ضریب تکرار ۳ است. بنابراین اگر شما ۱ گیگابایت فایل در HDFS ذخیره کنید، در نهایت آن ۳ گیگابایت از ظرفیت فایل سیستم را اشغال خواهد کرد. NameNode به صورت تناوبی فراداده را بهروزرسانی میکند و ضریب تکرار را ثابت نگه میدارد.
- جامعیت داده: تمامیت داده دربارهی این است که آیا دادهی ذخیرهشده در HDFS من صحیح است یا خیر. HDFS به طور مداوم تمامیت دادههای ذخیرهشده را بر حسب دادهی جمعکنترلی بررسی میکند. اگر هر اشتباهی در صحت دادهها رخ دهد، NameNode از این موضوع اطلاع پیدا میکند. در این حالت، NameNode کپی جدید اضافی ایجاد میکند و کپیهای خراب را حذف میکند.
- توان عملیاتی بالا: توان عملیاتی، مقدار کاری است که در واحد زمان انجام میشود. این ویژگی دربارهی این موضوع است که با چه سرعتی میتوانید به دادههای سیستم دسترسی داشته باشید. به طور کلی، به شما دیدی دربارهی عملکرد سیستم میدهد. همانطور که در مثال بالا مشاهده کردید ما برای بهبود محاسبات جمعاً از ۱۰ گره استفاده کردیم. بنابراین توانستیم وقتی که تمام گرهها به صورت موازی در حال کار بودند، زمان پردازش را بطور چشمگیری کاهش دهیم. در نتیجه، با پردازش دادهها به صورت موازی، زمان پردازش را فوقالعاده کاهش دادیم و بنابراین به توان عملیاتی بالایی رسیدیم.
- محلی بودن محاسبات: این ویژگی مربوط به انتقال پردازش به سمت داده به جای انتقال داده به سمت پردازش است. در سیستمهای سنتی، همیشه داده را به لایه برنامه منتقل میکنیم و سپس آن را پردازش میکنیم. اما در هدوپ، به علت معماری و حجم بالای داده، انتقال داده به لایه برنامه عملکرد شبکه را به حد قابل توجهی کند خواهد کرد و باعث ایجاد گلوگاه در انتقال دادهها خواهد شد. بنابراین، در HDFS، بخش پردازشی را به گره های داده یعنی جایی که دادهها قرار دارند منتقل میکنیم. بنابراین دادهها را حرکت نمیدهید و برنامه یا واحد پردازش را به محل داده انتقال میدهید.
ادامه مطلب به زودی ان شا الله
منابع
https://www.prnewswire.com/news-releases/lg-uplus-taps-on-cloudera-to-build-real-time-big-data-analytics-platform-to-deliver-5g-network-service-excellence-301353240.html
Cloudera Introduces Analytic Experiences for Cloudera Data Platform
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
Views: 902
برچسبCloudera Hadoop HDFS کلودرا هدوپ
نوشته های مرتبط












همچنین ببینید

محصولات و تکنولوژی های آپاچی (Apache) در حوزه کلان داده و داده کاوی
یکی از موسسات مطرح در زمینه پشتیبانی از داده های حجیم، بنیاد آپاچی می باشد. …
