 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
آموزش کامل آپاچی سولار (Solr) همراه با مثال
در مباحث قبل، در این مورد بحث کردیم که چطور کلان داده برای برآورده کردن نیازهای سازمان های مختلف که با داده های خیلی بزرگ سروکار دارند تکامل یافته است. در این مبحث به معرفی آپاچی سولار می پردازیم.
عناوين مطالب: '
- معرفی آپاچی سولار (تهیه کننده: بهراد دهقانی)
- راه اندازی آپاچی سولار
- پیش نیازهای راه اندازی آپاچی سولار
- اجرای آپاچی سولار بر روی Jetty
- اجرای سولار در سایر کانتینرهای J2EE
- مثال Hello word با آپاچی سولار
- مدیریت آپاچی سولار
- ناوبری سولار
- مشکلات و راه حل های متداول
- معماری آپاچی سولار
- پیکربندی سولار
- ساختار سولار
- تعریف شِما در سولار
- فیلدهای آپاچی سولار
- فیلدهای پویا در سولار
- کپی کردن فیلدها
- پیکربندی فراداده اضافی
- سایر عناصر مهم شِمای سولار
- فایل های پیکربندی آپاچی سولار
- کار با Solr.xml و Solr core
- پیکربندی نمونه با Solr config.xml
- افزونه آپاچی سولار
- سایر تنظیمات
- بارگذاری داده ها در آپاچی سولار
- کنترل کننده درخواست استخراج – solr cell
- معرفی کنترل کننده های ورود داده
- تعامل با سولار از طریق SolrJ
- کار با اسناد غنی ( Apache Tika)
- جستجوی اطلاعات در سولار
- خلاصه
معرفی آپاچی سولار (تهیه کننده: بهراد دهقانی)
مسائل بسیار دیگری در کار با شکل های مختلف داده وجود دارد. برای نمونه، فایل های لاگ سرور برنامه کاربردی یا اسناد Microsoft Word که داده نیمه ساخت یافته هستند، برای ذخیره سازی داده در مخزن رابطه ای سنتی مشکل دارند. مشکل این کلان داده های غیر ساخت یافته صرفاً ذخیره سازی نیست: سوال بزرگ، چگونگی دسترسی به اطلاعات مورد نیاز است. برای رفع این مشکل، موتورهای جستجوی بزرگ طراحی شده اند.
امروزه، یافتن اطلاعات مورد نیاز در یک بازه زمانی مشخص بسیار مهم تر از هر زمان دیگری شده است. سازمان ها بدون قابلیت های بازیابی اطلاعات از مسائلی مانند کاهش بازدهی کارمندان، تصمیمات ضعیف ناشی از اطلاعات خراب/ ناقص، موارد تکراری و مانند آن رنج می برند. با سناریوهای بیان شده، واضح است که جستجوهای سازمانی، در هر سازمانی کاملاً ضروری است.
راه اندازی آپاچی سولار
آپاچی سولار[1] یک سکوی قدرتمند و متن باز جستوجو است که برای رفع این مسائل در یک روش کارآمد و قابل گسترش طراحی شده است. آپاچی سولار بر روی آپاچی لوسین[2] بنا شده است، که یک کتابخانه جستجو و بازیابی اطلاعات متن باز را فراهم میآورد. امروزه، بسیاری از پیشگامان بازار جستجو حرفهای، مانند LucidWorks و PolySpot ، سکوی جستجوی خود را با استفاده از آپاچی سولار ایجاد کردند.
در این مبحث در مورد آپاچی سولار بیشتر یاد خواهیم گرفت و بر ابعاد ذیل از آپاچی سولار اشاره خواهیم کرد:
- تنظیمات آپاچی سولار
- معماری آپاچی سولار
- پیکربندی سولار
- بارگذاری داده در آپاچی سولار
- پرس و جوی اطلاعات در سولار
اکنون آپاچی سولار را بر روی دستگاه های خود نصب می کنیم و در بخش بعدی معماری آپاچی سولار را خواهیم گفت. آپاچی سولار یک برنامه تحت وب جاوا سرولت[3] است که بر روی آپاچی لوسین ، تیکا[4] و سایر کتابخانه های متن باز اجرا می شود. آپاچی سولار با یک سرور آزمایشی بر روی jetty حمل می شود و میتوان آنرا به سادگی از طریق خط فرمان[5] اجرا کرد. این امر به اجرای سریع نمونه سولار کمک می کند. با این حال ، امکان شخصی سازی و استقرار[6] آن بر روی محیط شخصی شما وجود دارد. آپاچی سولار با هر نصب کننده ای حمل نمی شود و باید بعنوان بخشی از برنامه J2EE اجرا شود.
پیش نیازهای راه اندازی آپاچی سولار
آپاچی سولار به نسخه 1.6یا بالاتر جاوا نیاز دارد. لذا مهم است که از نسخه صحیح جاوا با فراخوانی دستور java-version مطمئن شوید، همانطور که در شکل زیر نمایش داده شده است:

{با آخرین نسخه آپاچی سولار (4.0 یا بالاتر)، JDK 1.5 دیگر پشتیبانی نمی شود. آپاچی سولار +4.0 بر روی نسخه JDK 1.6 + اجرا می شود. بجای استفاده از نسخه پیش فرض JDK نصب شده بر روی سیستم عامل، نسخه کامل JDK را دانلود کنید. این نسخه، پشتیبانی کاملی برای کارکترهای بین المللی فعال می نماید. آپاچی سولار 4.10.1 حداقل به JDK 7 نیاز دارد.}
پس از تهیه نسخه صحیح جاوا، به یک کانتینر سرولت[7] مانند Tomcat، Jetty، Resin، Glassfish، یا Weblogic نصب شده بر روی ماشین نیاز دارید، اگر از یک سرور آزمایشی مبتنی بر jetty استفاده کنید به کانتینر نیاز نخواهید داشت.
اجرای آپاچی سولار بر روی Jetty
توزیع آپاچی سولار به صورت یک فایل فشرده است. فایل نصب را از آدرس http://lucene.apache.org/solr/ دانلود کنید. برای ویندوز، فایل zip و برای لینوکس ؛ نسخه .gzip/.tgz را دانلود کنید.
در ویندوز، به سادگی فایلتان را از حالت فشرده خارج کنید و در لینوکس، دستور زیر را اجرا کنید:
$ tar –xvzf solr-<major-minor version>.tgz
روش دیگر ساخت آپاچی سولار از منبع[8] است. در صورتی که بخواهید منبع آپاچی سولار را برای کنترل کننده، افزونه یا دیگران تغییر یا توسعه دهید شما به Java SE 7 JDK(مخفف Java Development Kit) یا JRE (Java Runtime Environment)، توزیع Apache Ant (1.8.2 یا بیشتر) و Apache Ivy (+2.2.0) نیاز دارید. با رفتن به پوشه Solr و اجرای Ant از آنجا، به سادگی می توانید منبع را کامپایل کنید.
وقتی Solr را از حالت فشرده خارج می کنید، پوشه های زیر را مشاهده می کنید.
/Contrib: این پوشه شامل همه کتابخانه هایی است که علاوه بر Solr هستند و در صورت درخواست اضافه می شوند آنها کتابخانه هایی برای کنترل کننده ورود داده[9]، MapReduce، Apache UIMA، الگوی سرعت و غیره فراهم می کنند.
/Dist: این پوشه توزیع هایی از سولار و سایر کتابخانه های مفید مانند SolrJ ، UIMA و MapReduce. ارائه می کنند. در مورد آن در فصل بعدی خواهیم پرداخت.
/Docs: این پوشه شامل مستندات (راهنماهای) آپاچی سولار است.
/Example : این پوشه برنامه های وب Solr مبتنی بر Jetty را که می توانند مستقیماً استفاده شوند را در خود دارد. از این پوشه برای اجرای آپاچی سولار استفاده می کنیم.
/Licenses: این پوشه شامل مجوزهای کتابخانه های مورد استفاده سولار است.
اکنون $JAVA_HOME را تعریف کنید تا به JDK/JRE خودتان اشاره کند. سرور jetty را در پوشه solr<version>/example پیدا خواهید کرد. وقتی solr-<major-minor version>.tgz را از حالت فشرده خارج کنید کافی است به solr<version>/example بروید و دستور زیر را اجرا کنید:
$ $JAVA_HOME/bin/java –jar start.jar
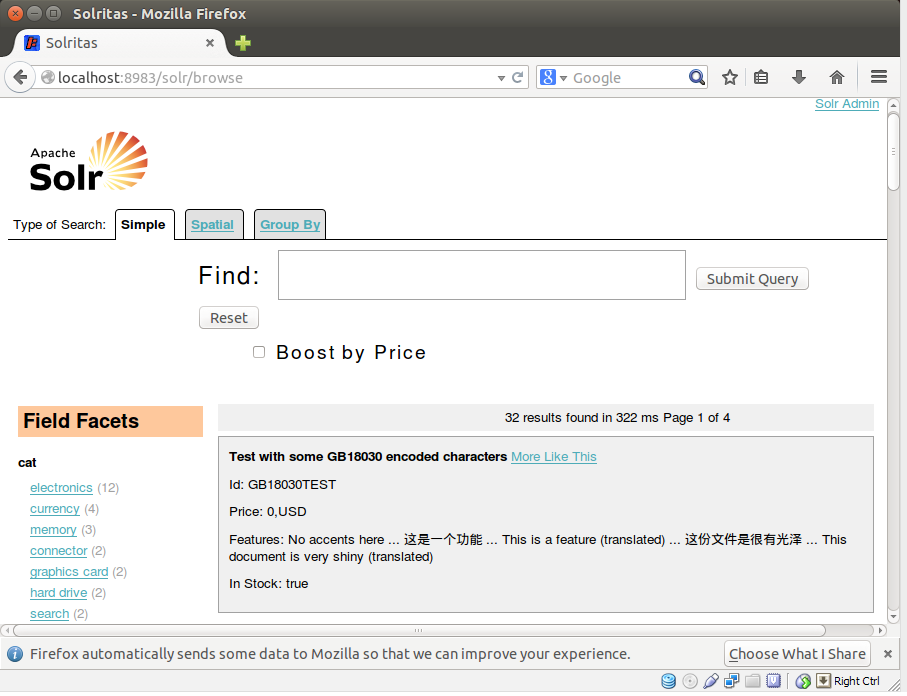
نمونه پیش فرض Jetty در پورت 8983 اجرا می شود. با مشاهدهURL : http://localhost:8983/Solr/browse می توانید به نمونه سولار دسترسی پیدا کنید. صفحه جستجوی پیش فرض در تصویر زیر نشان داده شده است.
اگر پیش فرض سیستم شما مجموعه کاراکتر غیر انگلیسی (en/en-US) است. بخاطر امنیت بیشتر، بهتر است پیش فرض های سیستم را برای سولار با مقدار دهی Duser.language=en –Duser.country=US در jetty رونویسی کنید تا از اجرای بدون اشکال سولار مطمئن شوید.
اجرای سولار در سایر کانتینرهای J2EE
نصب آپاچی سولار در هر کانتینر J2EE نسبتآ آسان است. استقرار فایل war برنامه آپاچی سولار با استقرار برنامه J2EE استاندارد در هر کانتینر امکان پذیر است. گام دیگر برای برنامه آپاچی سولار ، محل پوشه home آپاچی سولار است. این مورد از طریق گزینه های جاوا با تنظیم متغیرهای محیطی زیر یا بروزرسانی اسکریپت راه انداز کانتینر تنظیم می گردد.
$ export JAVA_OPTS=”$JAVA_OPTS -Dsolr.solr.home=/opt/solr/example”
از طرف دیگر، می توانید JNDI را برای منبع java:comp/env/solr/home با اشاره به پوشه home سولار پیکربندی کنید. در تامکت[10]، اینکار را می توان با ایجاد یک فایل متنی XML با نام (context.xml) در مسیر $CATALINA_HOME/conf/Catalina/localhost/context.xml، و اضافه نمودن ورودی های زیر انجام داد.
<?xml version="1.0" encoding="utf-8"?> <Context docBase="<solr-home>/example/solr/solr.war" debug="0" crossContext="true"> <Environment name="solr/home" type="java.lang.String" value="<solr- home>/example/solr" override="true"/> </Context>
مثال Hello word با آپاچی سولار
پس از اتمام نصب آپاچی سولار ، به سادگی می توانید مثال هایی را با رفتن به پوشه examples/exampledocs و دستور زیر اجرا کنید:
java -jar post.jar solr.xml monitor.xml
post.jar ابزاری است که توسط سولار جهت بارگذاری داده ها در آپاچی سولار برای نمایه سازی تهیه شده است. هنگامی که این برنامه اجرا شود، فایل post.jar به سادگی تمام فایل هایی را که به عنوان پارامتر به آپاچی سولار جهت نمایه سازی پاس شده اند را بارگذاری می نماید و سولار این فایل ها را شاخص گذاری گرده و در مخزن خود ذخیره سازی می کند. اکنون با تایپ http://localhost:8983/solr/browse به نمونه خود دسترسی پیدا کنید. شما یک صفحه جستجوی نمونه را با یکسری اطلاعات مشاهده می کنید، همانطور که در شکل زیر نشان داده شده است.
مدیریت آپاچی سولار
آپاچی سولار یک رابط کاربری بسیار خوب برای مدیریت سرور دارد که از طریق آدرس http://localhost:8983/solr قابل دسترس است. آپاچی سولار دو مفهوم هسته[11] و مجموعه ها[12] را دارد. یک مجموعه درآپاچی سولار مجموعه ای از اسناد است که یک شاخص منطقی کامل را نشان می دهد. هسته سولار، یک واحد اجرایی از سولار است که با پیکربندی خود و فراداده های دیگر اجرا می شود. مجموعههای آپاچی سولار می توانند برای هر نمایهی اجرا شوند. بطور مشابه سولار در حالت های چند هسته ای قابل اجرا است.
|
گزینه |
هدف |
|
داشبورد |
اطلاعات مربوطه که، مصرف حافظه JVM و غیره را نشان می دهد |
|
واقعه نگاری[13] |
خروجی های لاگ با آخرین لاگ ها در بالا. |
|
واقعه نگاری/ سطح |
پیکربندی لاگ جاری برای بسته ها را نشان می دهد. یعنی، برای کدام بسته، لاگ ها فعال هستند. |
|
مدیر هسته |
اطلاعات هسته را نشان می دهد و امکان مدیریت هسته را می دهد. |
|
خصوصیات جاوا |
ویژگی های مختلف جاوا را هنگام اجرای سولار را نشان می دهد. |
|
Thread Dump |
وضعیت پشته را با اطلاعاتی درباره cpu زمان کاربر توصیف می کند. همچنین ردیابی دقیق پشته را فعال می کند. |
|
collection1 |
پارامترهای مختلف مجموعه همه فعالیت های قابل انجام مانند پرس وجوهای در حال انجام و وضعیت ping را نشان می دهد. |
ناوبری سولار
در جدول زیر برخی از URLهای مهم آپاچی سولار نشان داده شده است.
|
URL |
هدف |
|
/select |
برای پردازش پرس وجوهای جستجو، کنترل کننده اصلی درخواست در سولار ” SearchHandler” است که یک توالی از مؤلفه های جستجو را نمایندگی می کند |
|
/query |
همان SearchHandler برای درخواست های مبتنی بر JSON |
|
/get |
کنترل کننده بلادرنگ، برگشت آخرین فیلدهای ذخیره شده سند را تضمین می کند، بدون نیاز به تثبیت یا باز نمودن searcherجدید. اجرای فعلی در ویژگی updatelog است که در فرمت JSON فعال شده است. |
|
/browse |
این URLیک جستجوی مبتنی بر وب، رابط اولیه را فراهم می کند. |
|
/update/extract |
سولار پیام های XML ارسال شده را می پذیرد که اضافه، جایگزین، تثبیت، حذف و حذف توسط پرس و جو با استفاده از /update URL (ExtractingRequestHandler) |
|
/update/csv |
این URLمخصوص پیام های CSVاست، CSVRequestHandler |
|
/update/json |
این URL مخصوص پیام ها با فرمت JSON است، JsonUpdateRequestHandler |
|
/analysis/field |
این URL رابطی برای تجزیه و تحلیل فیلدها ارائه می دهد و امکان مشخص نمودن چندین نوع فیلد و نام فیلد در همان درخواست را می دهد و تحلیل زمانی-شاخص و زمان –پرس و جو برای هریک از آنها را می دهد. همچنین از FieldAnalysisRequestHandler داخلی استفاده می کند |
|
/analysis/document |
این URL رابطی برای تجزیه و تحلیل اسناد ارائه می دهد. |
|
/admin |
AdminHandler برای مدیریت سولار، AdminHandler چندین sub-handler دارد. /admin/ping برای بررسی صحت است. |
|
/debug/dump |
DumpRequestHandler- محتوای درخواست را دوباره به کلاینت برمی گرداند |
|
replication/ |
از تکرار نمایه ها بر روی چندین سرور پشتیبانی می کند. توسط رئیس- مرئوسها برای اشتراک گذاری داده ها استفاده می شود. با استفاده از ReplicationHandler |
مشکلات و راه حل های متداول
در این بخش، سعی خواهیم کرد مشکلات متداول که هنگام، اجرای نمونه های سولار رخ می دهد را تشریح نماییم.
- وقتی آپاچی سولار را اجرا می کنیم، با خطای زیر مواجه می شویم:
Java.lang.UnsupportedClassError: org.apache.solr.servlet.
SolrDispatchFilter : Org.eclipse.jetty.Unsupported Major-Minor
version 51
این خطا بدلیل عدم مطابقت نسخه جاوا با نسخه جاوای کامپایل شده با آپاچی سولار مشاهده می شود. در این حالت به جاوای نسخه 7 یا بالاتر نیاز دارید.
مقادیر زیر نسخه های جاوا با نسخه کلاس متناظر هستند.
J2SE 8 = 52,
J2SE 7 = 51,
J2SE 6.0 = 50,
J2SE 5.0 = 49,
JDK 1.4 = 48,
JDK 1.3 = 47,
JDK 1.2 = 46,
JDK 1.1 = 45
لذا، برای اجرای آپاچی سولار باید از جاوای نسخه 7 استفاده کنید. اگر تنظیمات جاوا run-time دیگری را بر روی ماشین برای برنامه های موجود خود دارید و نمی خواهید آنرا مختل کنید، به سادگی JRE را در یک پوشه دانلود کنید و با فراخوانی جاوا از JRE جدید، با فرمان Solr start آنرا اجرا کنید( همانطور که در بخش قبلی توضیح داده شد).
- هنگام اجرای سولار، پیغام java.lang.OutOfMemoryError می دهد. چگونه آنرا برطرف کنید؟
خطای خارج از حافظه توسط ماشین مجازی جاوا JVM)) در هنگام اجرای آپاچی سولار هنگامی رخ میدهد که حافظه کافی برای پشته یا PermGen ( فضای تولید دائمی برای نگهداری فراداده طبق کلاس ها و متدهای کاربر) موجود نباشد. وقتی با چنین خطایی مواجه شدید، لازم است کانتینر را مجدداً راه اندازی کنید. با این حال، هنگام راه اندازی مجدد کانتینر، از افزایش حافظه JVM مطمئن شوید. این کار با اضافه کردن آرگومان های JVM به PermGen انجام می شود:
export JVM_ARGS="-Xmx1024m -XX:MaxPermSize=256m"
برای تصحیح خطای حافظه پشته، بایستی آرگومان های JVM زیر مشخص شوند.
export JVM_ARGS="-Xms1024m -Xmx1024m"
توجه داشته باشید که اندازه حافظه باید توسط کاربر مشخص شود. آدرس http://jvmmemory.com/ را برای ایجاد این آرگومان های JVM برای تنظیم درست متغیرهای JVM مشاهده کنید.
معماری آپاچی سولار
یک نمونه آپاچی سولار در دو حالت تک هسته[14] و چند هسته[15] اجرا می شود؛ که این یک مدل کلاینت سرور[16] است. هسته سولار به تنهایی چیزی نیست اما نمونه اجرای شاخص سولار از طریق پیکربندی آن انجام می شود پیش از این، آپاچی سولار تک هسته ای بود که مشتریان را برای اجرای سولار در یک برنامه از طریق یک فایل شِما[17] (الگو) و پیکربندی محدود میکرد. سپس، امکان ایجاد چندین هسته اضافه شد با این امکان، اکنون می توان یک نمونه سولار را برای چندین شِما و پیکربندی با مدیریت های یکپارچه اجرا نمود. از دستور زیر برای اجرای سولار در چند هسته ای استفاده می شود.
java -Dsolr.solr.home=multicore -jar start.jar
آپاچی سولار از چندین ماژول تشکیل شده است که برخی از آنها، برای خودشان پروژه های جداگانهای بودند. اجزای مختلف معماری آپاچی سولار را بررسی خواهیم کرد. نمودار زیر معماری مفهومی آپاچی سولار را به تصویر می کشد.
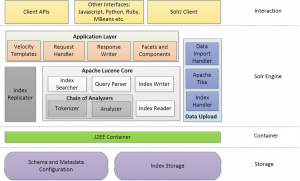
آپاچی سولار به صورت رئیس/مرئوس[18] اجرا می شود. Index replicator وظیفه توزیع نمایهها بر روی چندین فرعی را بر عهده دارد. سرور رئیس، بروزرسانی نمایهها را انجام میدهد، و مرئوسها وظیفه دارند با رئیس صحبت کنند تا آنها را برای دسترس پذیری بالا تکرار کند. Apache Lucene core بستههایی را به عنوان یک کتابخانه با برنامه آپاچی سولار دریافت میکند و قابلیت های هسته های سولار مانند نمایه، پردازش پرس و جو، جستجوی داده ها و رتبه بندی نتایج همسان و بازگشت آنها را انجام می دهد.
آپاچی لوسین دارای چندین پیادهسازی پرس و جو است. Query Parser مسئول تجزیه پرس و جو های پاس شده در پایان جستجو به عنوان رشته جستجو است. لوسین TermQuery ، BooleanQuery ، PhraseQuery ، PrefixQuery ، RangeQuery ، MultiTermQuery ، FilteredQuery ، SpanQuery و غیره را به عنوان پیاده سازیهای پرس و جو فراهم می کند.
Index Searcher یک مولفه اساسی سولار است که با کلاس جستجوگر پایه پیش فرض جستجو میکند. این کلاس طبق امتیاز محاسبه شده، نتایج مرتب همسان را از کلمه کلیدی جستجوی رتبه بندی شده برمیگرداند. Index Reader، دسترسی به شاخص های ذخیره شده در سیستم فایل را فراهم میکند و برای جستجوی شاخص استفاده میشود. مشابه به جستجوگر شاخص، Index Writer به شما امکان میدهد شاخصها را در آپاچی لوسین ایجاد و نگهداری کنید.
پیکربندی سولار
آپاچی سولار پیکربندی گسترده ای برای پاسخگویی به نیازهای مصرف کننده در اختیار می گذارد. پیکربندی نمونه به حول موارد زیر می چرخد.
- تعریف شِما
- پیکربندی پارامترهای سولار
ابتدا، ساختار آپاچی سولار ارائه می شود و سپس، همه مراحل پیکربندی آپاچی سولار اشاره می شود.
ساختار سولار
پوشه آپاچی سولار عمدتأ شامل پیکربندی داده های مربوط به نمایه است. موارد زیر پوشه های اصلی در مجموعه سولار هستند.
|
پوشه |
هدف |
|
Conf/ |
این پوشه شامل کلیه فایل های پیکربندی آپاچی سولار می باشد و اجباری است. در میان آن ها، solrconfig.xml و schema.xml مهم ترین فایل های پیکربندی هستند. |
|
Date/ |
این پوشه اطلاعات مربوط به نمایه های ایجاد شده توسط سولار را ذخیره می کند. مثل پیش فرض سولار برای ذخیره این اطلاعات است. این محل می تواند با تغییر conf/solrconfig.xml بازنویسی شود. |
|
Lib/ |
این پوشه اختیاری است، در صورت وجود، سولار Jar های موجود در این پوشه را بارگذاری خواهد کرد و از آنها برای حل “افزونه ها” که در solrconfig.xml (Analyzers، RequestHandlersو غیره. ) ارائه شده استفاده می کند. در روش دیگر، از عبارت <lib> در conf/solrconfig.xml برای هدایت سولار به افزونه ها استفاده کنید. |
تعریف شِما در سولار
در یک سازمان، داده از کلیه سیستم های نرم افزاری که در عملیات روزانه شرکت دارند، تولید می شوند. این داده ها، فرمت های مختلفی دارند و این موضوع در مورد این داده ها مطرح است که پردازش داده های بزرگ به یک سیستم ذخیره سازی انعطاف پذیر نیاز دارد که بتواند داده ها با مدل های داده ای مختلف را متناسب سازی کند. بانک های اطلاعاتی سنتی امکان تعریف ساختار داده دقیق و مکانیزم پرس و جوهای مبتنی بر SQL را می دهد.
طراحی سولار به گونهای است که امکان بارگذاری هرگونه داده در موتور جست و جو را از طریق کنترل کنندههای مختلف می دهد و آنرا مستقل از فرمت داده می کند.
سولار به راحتی میتواند روی سخت افزارهای عادی گسترده شود؛ از این رو، آنرا به یکی از کارآمدترین گزینههای برنامه های جست و جو مبتنی بر NOSQL که امروزه در دسترس اند، تبدیل می کند. داده ها در نمایه های سولار ذخیره می شوند و از طریق API های جستجوی Lucenceقابل پرس و جو هستند. سولار بدلیل عدم تغییر شکل داده ها، امکان انجام پیوند دارد. فایل کلی شِما schema.xml)) دارای ساختاری به ترتیب زیر است:
<schema>
ddd>
</schema>
فیلدهای آپاچی سولار
واحد اصلی اطلاعات سولار، سند است، که مجموعه ای از داده هاست که چیزی را توصیف می کند. هر سند در سولار از تعدادی فیلد تشکیل شده است. آپاچی سولار امکان تعریف ساختار داده ها را می دهد تا جستجوی کلید واژه سنتی را پشتیبانی کند.
سولار ساختار داده ها (از منابع مختلف) را از طریق تعریف فیلدها در فایل تعریف شِما متوجه می شود. این فیلدها، پس از تعریف، در زمان ورود یا آپلود داده ها در دسترس خواهند بود. شِما در فایل schema.xml در پوشه /conf آپاچی سولار ذخیره می شود.
آپاچی سولار فایل پیش فرض دارد، که شما باید آنرا متناسب با نیازتان تغییر دهید.
{ اگر schema.xml را در یک نمونه سولار که روی یکسری داده اجرا می شود، تغییر دهید تأثیر این تغییر نیاز به بازسازی نمایه سولار با شِما جدید است.}
در پیکربندی شِما ، می توانید انواع فیلد (مثلأ، رشته ای، عدد صحیح و تاریخ) را تعریف و آنها را به کلاسهای جاوای مربوطه نگاشت کنید.
<field name=”id” type=”integer” indexed=”true” stored=”true”
required=”true”/>
این کار کاربران را قادر می سازد تا در صورت تمایل، نوع دلخواه خود را تعریف کنند پس می توانید فیلد ها را با نام و نوع مشخص کنید که به یکی از انواع تعریف شده اشاره دارد.
یک فیلد در سولار دارای خصوصیات اصلی زیر است:
|
نام |
شرح |
|
Default |
اگر هنگام ورود سند خوانده نشود این مقدار پیش فرض را تعیین می کند. |
|
Indexed |
وقتی درست است، فیلد نمایه خواهد شد ( یعنی قابل جستجو و ذخیره سازی است و facetها ایجاد شده اند). |
|
Stored |
وقتی درست است فیلد در مخزن نمایه ذخیره می شود و هنگام نمایش نتایج در دسترس خواهد بود |
|
compressed |
وقتی درست است فیلد فشرده سازی خواهد شد ( با استفاده از gzip) برای فیلدهای متنی قابل استفاده است. |
|
multiValued |
اگر یک فیلد حاوی مقادیر متعددی در همان چرخه ورود سند/ردیف باشد. |
|
omitNorms |
وقتی درست است. معیارهای مرتبط با فیلد را حذف می کند( مانند نرمال سازی طول و افزایش نمایه). به همین ترتیب omitTermFreqAndPositions ( در صورت درست بودن، تعداد تکرار کلمه، موقعیت ها و بارهای ارسال شده برای این فیلد را حذف میکند. برای فیلدهایی که این اطلاعات را نیاز ندارند، باعث افزایش عملکرد میشود. همینطور فضای ذخیره سازی مورد نیاز برای نمایه را کاهش می دهد) و omitPositions |
|
termVectors |
در صورت درستی، فراداده مربوط به یک سند را ذخیره و هنگام پرس و جو بر می گرداند. |
Solr 4.2 ویژگی جدیدی تحت عنوان DocValue برای فیلدها معرفی کرده است. DocValue ها روشی برای ایجاد نمایهای با کارآیی بالاتر برای اهدافی مانند مرتب سازی و زمینه (facet) است. در حالی که آپاچی سولار بر روی مکانیزم نمایه معکوس تکیه دارد، ذخیره سازی DocValue بر نمایه سازی کارآمد اسناد تمرکز دارد، به منظور نمایه سازی، مکانیزم ذخیره سازی با استفاده از ساختار فیلد ستونگرا از نگاشت سند- به – مقدار ساخته شده در زمان نمایه استفاده می کند. این رویکرد (فیلد ستون گرا) منجر به کاهش مصرف حافظه و سرعت کلی جستجو می شود. DocValue در فیلدهای مشخص در سولار به روش زیر فعال می شود:
<field name=”test_outcome” type=”string” indexed=”false”
stored=”false” docValues=”true” />
اگر داده ها قبل از اعمال DocValue نمایه سازی شوند، برای استفاده از مزایای DocValue باید مجدداً نمایه شوند.
فیلدهای پویا در سولار
علاوه بر فیلدهای استاتیک، می توانید از فیلدهای پویای سولار برای بدست آوردن انعطاف پذیری استفاده کنید، در صورتی که شِمای مقدماتی را نمی دانید. تعریف <dynamicField> برای ایجاد قاعده فیلدی که سولار تشخیص دهد کدام نوع داده را استفاده کند، بکار می رود. در نمونه زیر، هر فیلد ورودی که پیشوند *_no داشته باشد، ( برای مثال: id_no و vehicle_no) توسط سولار به عنوان یک عدد صحیح خوانده می شود. در این مورد، * یک نویسه جایگزین پذیر است.
قطعه کد زیر نحوه ایجاد فیلد پویا را نشان می دهد.
<dynamicField name=”*_no” type=”integer” indexed=”true”
stored=”true”/>
{اگر چه شرط اجباری نیست، اما توصیه می شود هر نمونه سولار یک فیلد شناسایی واحد برای داده ها داشته باشد. بطور مشابه، کلید منحصر به فرد مشخص شده با نام ID، نباید چند مقداری باشد. }
کپی کردن فیلدها
با استفاده از <copyField> می توانید داده های مشابه را در چندین فیلد، نمایه کنید. این کار بطور معمول برای داشتن چندین نمایه برای نوع داده یکسان مورد نیاز است. بعنوان مثال، اگر داده ای برای یخچال با نام شرکت و به دنبال آن شماره مدل (WHIRLPOOL-1000LTR, SAMSUNG-980LTR و مانند آن) دارید، اینها را جداگانه با نشانهگذار[19] خودتان در فیلدهای مختلف نمایه سازی کنید. می توانید نمایه هایی برای دو فیلد مختلف نام شرکت و شماره مدل ایجاد کنید و نشانهگذارهای مخصوص به نوع فیلدتان را تعریف کنید. در اینجا نمونه copyField از schema.xml آورده شده است:
<copyField source=”cat” dest=”text”/>
<copyField source=”name” dest=”text”/>
<copyField source=”manu” dest=”text”/>
<copyField source=”features” dest=”text”/>
- پرداختن به انواع فیلد
انواع فیلد را در آپاچی سولار می توانید تعریف کنید که نیازمندی های شما برای پردازش داده ها را پاسخ می دهد. نوع داده شامل چهار نوع از اطلاعات است:
- نام
- نام کلاس پیاده سازی ( در org.apache.solr.schema.FieldType پیاده سازی شده است)
- اگر نوع فیلد TextField است. توضیحی از تحلیل فیلد برای نوع فیلد است.
- خصیصه های فیلد
قطعه XML زیر نوع فیلد نمونه را نشان می دهد.
<fieldType name=”text_ws” class=”solr.TextField”
positionIncrementGap=”100″>
<analyzer>
<tokenizer class=”solr.WhitespaceTokenizerFactory”/>
</analyzer>
</fieldType>
خصیصه کلاس نشان می دهد کدام کلاس جاوا با نوع فیلد داده شده مرتبط است. PositionIncrementGap فاصله بین دو کلمه را تعیین می کند. این خصیصه برای فیلدهای چند مقداری است که فضای بین مقادیر مختلف فیلد مشخص است. به عنوان مثال، اگر فیلد نویسنده مقادیر”John Doe ” و”Jack Williams” داشته باشد، وقتی PositionIncrementGap صفر است، جستجوی Doe Jack با این فیلدها مطابقت خواهد داشت زیرا سولار با این فیلد مانند John Doe Jack Williams رفتار می کند. برای جدا کردن این فیلدهای چند مقداری، مقدار بالایی برای PositionIncrementGap تعیین کنید. نام خصیصه، نام نوع فیلد را نشان می دهد بعدا وقتی یک فیلد تعریف می شود از نوع خصیصه برای مشخص کردن نوع فیلد مربوطه استفاده خواهد شد همانطور که قطعه کد زیر نشان می دهد:
<field name=”name” type=”text_ws” indexed=”true” stored=”true”/>
پیکربندی فراداده اضافی
فایل های دیگری وجود دارند که در آن میتوان فرا داده را مشخص کرد. این فایل ها نیز دوباره در پوشه conf دیده می شوند این فایل ها در جدول زیر آورده شده است:
|
نام فایل |
توضیحات |
|
Protwords.txt |
در این فایل، کلمات محافظت شده ای را که نمی خواهید ریشه یابی شوند را مشخص کنید .به عنوان مثال یک ریشه یاب ممکن است کلمه catfish را به cat و fish ریشه یابی کند. |
|
Currency.txt |
نگاشت فعلی از نرخهای ارز بین کشورهای مختلف را ذخیره می کند. این کار هنگامی مفید است که در برنامه شما افرادی از کشورهای مختلف دسترسی پیدا می کنند. |
|
Elevate.txt |
با استفاده از این فایل می توانید نتایج جستجو را تحت تاثیر قرار داده و نتایج خود را در بین نتایج برتر رتبه بندی کنید. این فایل شِمای رتبه بندی استاندارد لوسین را بازنویسی می کند. |
|
Spellings.txt |
این فایل، پیشنهادات املائی را به کاربر نهایی ارائه می دهد |
|
Synonyms.txt |
با استفاده از این فایل، مترادف ها را مشخص کنید. مثلا، هزینه => پول ، پول => دلارها |
|
Stopwords.txt |
ایست واژهها، کلماتی هستند که نمایه سازی نمی شوند و توسط سولار در برنامه ها مورد استفاده قرار می گیرند؛ بخصوص هنگامی که واقعأ می خواهید از کلمات خارجی رها شوید؛ بعنوان مثال: در رشته “Jamie and Joseph ” کلمه “and” به عنوان ایست واژه نشانه گذاری می شود. |
سایر عناصر مهم شِمای سولار
در جدول زیر، عناصر مختلف موجود در schema.xml شرح داده شده است.
|
نام |
توضیحات |
نمونه |
|
Unique key |
عنصر Unique.key مشخص می کند کدام فیلد شناسه منحصر به اسناد است.مثلاً، Unique.key باید برای بروزرسانی سند در نمایه استفاده شود. |
<uniqueKey>id</uniqueKey> |
|
Default search field |
اگر از پارسر جست و جوی لوسین استفاده می کنید پرس و جوهای بدون نام فیلد از defaultSearchField استفاده می کنند. استفاده از جست و جوی پیش فرض از آپاچی سولار 3.6 یا بالاتر کاهش یافته است. |
<defaultSearchField></defaultSearchField> |
|
Similarity |
Similarity یک کلاس لوسین برای امتیاز دهی نتایج یافته شده است. با تعریف <similarity> می تواند رفتار Similarity پیش فرض سولار را بازنویسی کنید. Similarity را می توان در سطح سراسری پیکربندی کرد. اگرچه solr 4.0 ، Similarity را برای تنظیم در سطح فیلد گسترش می دهد. |
<similarity class=”solr. DFRSimilarityFactory”> <str name=”basicModel”>P</str> <str name=”afterEffect”>L</str> <str name=”normalization”>H2</ str> <float name=”c”>7</ float> </similarity> |
فایل های پیکربندی آپاچی سولار
مخزن آپاچی سولار به طور عمده برای ذخیره سازی فراداده و اطلاعات نمایه واقعی استفاده می شود.
و معمولاً فایلی است که بطور محلی ذخیره شده و در پیکربندی آپاچی سولار پیکربندی می شود. بسته نصب پیش فرض سولار، با سرور jetty همراه است، پیکربندی در پوشه solr.home/conf از نصب solr قرار دارد سه فایل اصلی پیکربندی در سولار وجود دارد:
Solrconfig.xml: این فایل اصلی پیکربندی نصب سولار است. با استفاده از این، می توانید همه چیز را کنترل کنید. ازحافظه نهان[20] و مشخص کردن کنترل کنندههای مشتری تا کدها و گزینه های تثبیت (commit).
Schema.xml: این فایل وظیفه تعیین شِمای سولار برای برنامه شما را دارد. بعنوان مثال: اجرای سولار برای مدیریت لاگ یک شِما با خصیصه های مرتبط با لاگ خواهد داشت. یعنی، سطوح لاگ، نوع پیام، نام کانتینر، نام برنامه و غیره.
Solr.xml: با استفاده از Solr.xml ، می توانید هسته های سولار را برای راه اندازی پیکربندی کنید.(یک یا چند هسته ای). همچنین پارامترهای دیگری مانند وقفه zookeeper و اندازه حافظه نهان ناپایدار.
نمایه آپاچی سولار (زیر بنای لوسین)، یک ساختار داده ویژه طراحی کرده است، در سیستم فایل به عنوان مجموعه ای از فایل های نمایه ذخیره می شود. نمایه با قالب خاصی طراحی شده است به گونه ای که عملکرد پرس و جو را به حداکثر برساند. پس از پیکربندی شِما مرحله ضروری بعدی پیکربندی نمونه برای کار با سازمان شما است. دو پیکربندی اصلی وجود دارد که تنظیمات سولار شامل آنهاست، بنام solrconfig.xml و solr.xml. بیایید تک تک آنها را مرور کنیم.
کار با Solr.xml و Solr core
فایل پیکربندی solr.xml در پوشه $SOLR_HOME قرار دارد و عمدتاً بر نگهداری پیکربندی برای لاگ، نصب ابر و هسته solr متمرکز است. خط کد solr 4.X از Solr.xml برای شناسایی هسته های تعریف شده توسط کاربران استفاده می کنند. در نسخه های جدید تر solr 5.x (جاری)، ساختار فعلی Solr.xml(حاوی عنصر <core>و غیره) پشتیبانی نمی شود و ساختار جایگزین توسط solr استفاده خواهد شد.
پیکربندی نمونه با Solr config.xml
فایل Solr config.xml ، در درجه اول دسترسی به کنترلکنندههای درخواست، Listener ها، توزیع کننده های درخواست را فراهم میآورد. به فایل solrconfig.xml نگاهی بیندازیم و تمام اعلان های مهم که مکرراً استفاده می شوند را اشاره می کنیم.
|
دستور |
شرح |
|
luceneMatchVersion |
برای کدام نسخه از لوسین/ سولار فایل پیکربندی تنظیم شده است. هنگام بروز رسانی نمونه های سولار این خصیصه باید تغییر یابد. |
|
Lib |
در صورت ایجاد افزونه برای سولار، لازم است مرجع کتابخانه را اینجا به طوری که برداشت می شود قرار دهید. کتابخانه ها، در توالی یکسانی به ترتیب پیکربندی بارگذاری می شوند. مسیرها نسبی هستند؛ همچنین می توانید از عبارات منظم استفاده کنید. برای نمونه: <lib dir=”…/../../contrib/velocity/lib” regex=”.*\.jar” />. |
|
dataDir |
به طور پیش فرض، سولار از پوشه /data. برای ذخیره سازی نمایه ها استفاده می کند؛ با این حال، با تغییر پوشه داده ها با استفاده از این دستورالعمل، باز نویسی می شود. |
|
indexConfig |
این دستور از نوع پیچیده است، و برای تغییر تنظیمات برخی از پیکربندی نمایه داخلی سولار بکار می رود. |
|
Filter |
فیلتر های مختلفی در زمان ایجاد نمایه اعمال میکند. |
|
writeLockTimeout |
حداکثر زمان انتظار نوشتن قفل برای IndexWriter را مشخص میکند |
|
maxIndexingThreads |
حداکثر تعداد نمایه ها و نخ ها که می تواند در IndexWriter اجرا شود را مشخص می کند؛ اگر تعداد نخ بیشتری وارد شوند، باید منتظر بمانند. مقدار پیش فرض 8 است. |
|
ramBufferSizeMB |
حداکثر RAM مورد نیاز در بافر در زمان ایجاد نمایه، قبل از اینکه فایلها به سیستم فایل متصل شوند. |
|
maxBufferedDocs |
تعداد اسناد بافر شده را محدود می کند. |
|
lockType |
هنگامی که نمایه ها در فایل ایجاد و ذخیره می شوند، این ساز و کار تصمیم می گیرد کدام مکانیزم قفل گذاری-فایل باید برای مدیریت همزمان خواندن – نوشتن ها استفاده شود. سه نوع مکانیزم قفل گذاری فایل وجود دارد: تک (یک فرآیند در یک زمان)، بومی (سیستم عامل بومی)، و ساده (قفل با استفاده از فایل های ساده) |
|
unlockOnStartup |
در صورت درستی (true) ، تمام قفل های نوشتن در گذشته آزاد می شوند. |
|
Jmx |
سولار، آمار زمان اجرا را از طریق MBeans نشان می دهد، از طریق این دستور العمل فعال/غیر فعال می شود. |
|
updateHandler |
کنترل کننده بروز رسانی وظیفه مدیریت بروز رسانی ها را برای سولار دارد. کل پیکر بندی برای Updatehandler ، بخشی از این دستورالعمل ها را شکل می دهد. |
|
updateLog |
پوشه و سایر تنظیمات لاگ های تراکنش را در حالی که نمایه بروز رسانی می شود را مشخص می نماید. |
|
autoCommit |
تثبیت خودکار را هنگام وقوع بروز رسانی ها فعال می کند. می تواند بر اساس اسناد یا زمان باشد قبل از اینکه یک تثبیت خودکار رخ دهد |
|
Listener |
با استفاده از این دستورالعمل میتوانید برای بروز رسانی رخدادها وقتی IndexWriters ، نمایه را بروز رسانی می کند، مشترک شوید.Listener می تواند در زمان اجرای “postCommit”یا ” postOptimize ” اجرا شود. |
|
Query |
این دستورالعمل عمدتاً وظیفه کنترل پارامترهای مختلف در زمان پرس و جوها را دارد. |
|
requestDispatcher |
با تنظیم پارامترهای موجود در این دستور، می توانید نحوه پردازش یک درخواست توسط SolrDispatchFilter را کنترل کنید. |
|
requestHandler |
کنترلکنندههای درخواست وظیفه اداره انواع مختلف از درخواست ها با منطق مشخصی برای آپاچی سولار را دارند. اینها در یک بخش جداگانه توضیح داده شده است. |
|
searchComponent |
مؤلفه های جستجو در سولار منطق بیشتری فعال می کنند که می تواند توسط کنترلکننده جستجو برای ارائه تجربه جستجوی بهتر استفاده شود. این موارد در ضمیمه، موارد کاری جستجوی کلان داده توضیح داده شده است. |
|
updateRequestProcessorChain |
زنجیره پردازنده درخواست بروزرسانی، نحوه پردازش درخواست های بروز رسانی را مشخص می کند؛ می توانید updateRequestProcessor خودتان را برای انجام کارهایی مانند تمیز کردن داده و بهینه سازی فیلدهای متنی تعریف کنید. |
|
queryResponseWriter |
هر درخواست پرس و جو قالب بندی شده و از طریق queryResponseWriter به کاربر ارسال می شود. نمونه سولار خود را می توانید برای پاسخ هایی برای XML ، JSON ، PHP، Ruby، Python، csvs و غیره با فعال کردن writerهای از پیش تعریف شده مربوطه گسترش دهید. اگر شما نیاز سفارشی برای نوع خاصی از پاسخ دارید، به راحتی می توانید آن را گسترش دهید. |
|
queryParser |
دستورالعمل تجزیه کننده پرس و جو برای آپاچی سولار مشخص می کند کدام تجزیه کننده پرس وجو برای تجزیه پرس و جو ایجاد Lucene Query Objects استفاده گردد. آپاچی سولار تجزیه کننده های پرس و جو پیش تعریف مانند لوسین (پیش فرض) ، DisMax (مبتنی بر وزن فیلد ها)، edismax (مشابه dismax با برخی ویژگی های اضافی) و غیره را شامل میشود. |
افزونه آپاچی سولار
آپاچی سولار از طریق افزونه های سولار وصله های ساده ای به معماری فعلی خود فراهم می آورد. با استفاده از افزونه های سولار، می توانید کُد خود را برای انجام کارهای مختلفی درون سولار، بارگذاری کنید: از کنترلکنندههای درخواست سفارشی برای پردازش جستجوها، تا آنالیزورهای سفارشی و فیلترهای توکنی برای فیلد متنی. بطور معمول، افزونه ها در سولار با استفاده از هر IDE با وارد کردن apache-solr*.jar به عنوان کتابخانه توسعه داده می شوند.
انواع افزونه های زیر می توانند با آپاچی سولار ایجاد شوند:
مؤلفه های جستجو: این افزونه ها در مجموعه نتایج پرس و جو عمل می کنند. نتایجی که آنها تولید می کنند به طور معمول در انتهای درخواست جست و جو ظاهر می شوند.
کنترل کننده درخواست[21]: از کنترل کننده های درخواست برای ارائه یک نقطه پایانی REST از نمونه سولار برای انجام برخی کارها استفاده می شود.
فیلترها: فیلترها، زنجیره ای از عامل ها هستند که متن را برای معیارهای مختلف فیلتر، مانند حروف کوچک و ریشه یابی تجزیه و تحلیل می کند. حالا می توانید فیلتر خود را معرفی کنید و آنرا با افزونه فایل jar بسته بندی کنید.
پس از توسعه، افزونه باید به عنوان بخشی از solrconfig.xml با اشاره کتابخانه به فایل jar تعریف شود.
سایر تنظیمات
کنترل کننده های درخواست در سولار، وظیفه کنترل درخواست ها را دارند. هر کنترل کننده درخواست می تواند با یک URL نسبی مرتبط باشد. به عنوان مثال، search/، select/ ، یک کنترل کننده درخواست که قابلیت جستجو را فراهم می کند، کنترلکننده درخواست نامیده می شود. بیش از 25 کنترلکننده درخواست به طور پیش فرض با سولار موجود است و می توانید لیست کامل را در اینجا مشاهده کنید: http://lucene.apache.org/solr/api/org/apache/solr/request/SolrRequestHandler.html
کنترلکنندههای جستجو وجود دارند که قابلیت جستجو را در نمایه مبتنی بر سولار ارائه می دهند. (برای نمونه، DisMaxRequestHandler و SearchHandler …)؛ به طور مشابه، کنترلکنندههای آپدیت وجود دارد که بارگذاری اسناد در سولار را پشتیبانی می کند.(برای نمونه، DataImportHandler و CSVUpdateRequestHandler) RealTimeGetHandler آخرین فیلدهای ذخیره شده یک سند را ارائه می دهد. UpdateRequestHandlers مسئول پردازش بروز رسانی یک نمایه است. به همین ترتیب CSVRequestHandler و JsonUpdateRequestHandler وظیفه بروزرسانی نمایه ها را با قالب های CSV و JSON دارند. ExtractingRequestHandler از Apache Tika برای استخراج متن از قالب های مختلف فایل استفاده می کند.
بارگذاری داده ها در آپاچی سولار
پس از پیکربندی آپاچی سولار، مرحله بعدی بارگذاری داده در آپاچی سولار و اجرای پرس و جوها است. روش های مختلفی برای بارگذاری داده در آپاچی سولار وجود دارد. نمودار زیر موارد بیشتر بکار گرفته شده را نشان می دهد.
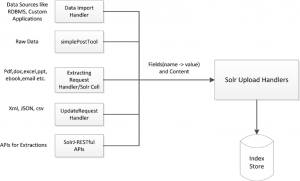
پیش از این ابراز پست ساده را هنگام تنظیم آپاچی سولار دیدهایم. در ادامه به کنترل کننده درخواست استخراج[22] اشاره می کنیم.
کنترل کننده درخواست استخراج – solr cell
Solr Cell یکی از قدرتمند ترین کنترل گرها برای بارگذاری هر نوع داده است. اگر می خواهید سولار را بر روی مجموعه ای از فایل ها/داده های بدون ساختار حاوی قالب های مختلفی از مجموعه office، pdf,ebook، emails و text اجرا کنید، میتواند بسیار مفید باشد. در Apache Tika ، استخراج متن صرفاً براساس نوع فایل و محتوا است. لذا، اگر pdf از تصاویر اسکن شده حاوی متن دارید، آپاچی Tika قادر به استخراج هیچ متنی از آن نخواهد بود. در چنین مواردی لازم است از نرم افزار OCR استفاده کنید تا چنین قابلیتی را برای سولار مهیا کند. این کار را به راحتی می توانید با دانلود ابزار curl و سپس اجرای آن در سندتان انجام دهید.
curl ‘http://localhost:8983/solr/update/extract?literal.
id=doc1&commit=true’ -F “myfile=@<your document name with extension>”
کنترل کننده های نمایه[23] مانند Simple Post Tool، Update Request Handler و SolrJ امکان اضافه کردن، بروز رسانی و حذفِ اسناد برای نمایه گذاری فرمت های XML، JSON و CSV را فراهم می آورد. کنترل کننده درخواست بروزرسانی url وبی برای آپلود اسناد ارائه می دهد. این مورد می تواند با استفاده از ابزار curl انجام شود.
{ ابزارها یcurl/ wget را می توان برای بارگذاری داده ها در سولار در محیط خود استفاده کرد. آنها مبتنی بر خط فرمان هستند؛ از افزونه FireCURL در مرورگر فایر فاکس نیز می توانید برای بارگذاری داده ها استفاده کنید.}
ابزار ارسال ساده یک ابزار خط فرمان برای بارگذاری داده های خام در آپاچی سولار است. به سادگی می توانید آن را روی هر فایل یا نوع ورود از طریق STIDIN ( مخفف جریان ورودی استاندارد است یعنی از طریق صفحه کلید) اجرا کنید. تا در آپاچی سولار بارگذاری نمایید.
معرفی کنترل کننده های ورود داده
آپاچی سولار برای این نوع، منبع داده ای DataImportHandler را ارائه می کند. با استفاده از DataImportHandler ، می توانید بجای مجموعه داده کامل فقط دلتاها را بارگذاری می کنید. اغلب، این می تواند به عنوان یک فعالیت کاری برنامه ریزی خارج از زمان تنظیم شود تا تاثیر نمایه گذاری بر کارهای روزانه را به حداقل برسانید. در مورد بروزرسانی های بلادرنگ، این فعالیت با دوره های زمانی ثابت برنامه ریزی می شود. یکی از مراحل مهم قبل از وارد کردن داده ها از یک پایگاه داده به آپاچی سولار پیکربندی منبع داده است. منبع داده به مکانی که داده ها هستند اشاره می کند. در این حالت می تواند، یک پایگاه داده رابطه ای مانند Oracle، MySQL، SQLServerو HTTP URL باشد.
یک منبع داده را می توان در solrconfig.xml تعریف کرد یا می توان به سادگی به فایل دیگر حاوی پیکربندی ( در این مورد، data-config.xml) اشاره نمود.
هر پیکربندی داده عناصر <dataSource> و <document> را دارد. <dataSource> غالباً بر برقراری تماس با داده از طریق پروتکل های مختلف مانند JNDI، JDBC و HTTP تمرکز دارد. هر <document> دارای <entity> است. هر موجودیتی یک مجموعه داده را نشان می دهد. هر موجودیتی می تواند شامل موجودیت ها یا فیلدهای مختلفی باشد. وقتی کنترل کننده ورود اجرا می شود، مجموعه ای از اسناد را ایجاد می کند، مشتمل بر چندین فیلد، که ( پس از تغییر اختیاری به روش های مختلف) برای شاخص گذاری به سولار ارسال می شوند. برای یک منبع داده RDBMS، موجودیت دید یا جدول است، که توسط یک یا چند عبارت SQL برای ایجاد مجموعه ای از ردیف ها (اسناد) ، یک یا چند ستون (فیلد)، پردازش خواهند شد.
با نوشتن کلاسی که org.apache.solr.handler.dataimport.DataSource را توسعه می دهد می توانید یک منبع داده سفارشی را ایجاد کنید. عملیات ورود از طریق URL زیر شروع می شود:
http://<host>:<port>/solr/ dataimport?command=full-import
{ دو حالت مختلف برای وارد نمودن داده از یک پایگاه داده از طریق DataImportHandler وجود دارد. مکانیزم واردات کامل در جایی مفید است که خواندن تصاویر لحظه ای منبع داده ای در زمان مشخص مدنظر است. واردات دلتا شبیه به واردات کامل است. با این تفاوت که تغییر وضعیت منبع داده ای شما را برای بازتاب به آپاچی سولار ارائه می دهد. این واردات به بروز رسانی های افزایشی و تشخیص تغییر تمرکز دارد.}
تعامل با سولار از طریق SolrJ
آپاچی سولار یک برنامه وب است ؛ که می تواند مستقیمآ توسط مشتریان برای جستجو استفاده شود. رابطه کاربری جستجو می تواند اصلاح و بهبود یابد تا به عنوان ابزار جستجوی کاربر نهایی برای جستجو در یک سازمان کار کند. کلاینت های سولار می توانند به طور مستقیم به URL سولار از طریق HTTP برای جستجو و خواندن داده ها در فرمت های مختلفی مانند JSON و XML دسترسی یابند. علاوه بر آن، آپاچی سولار امکان مدیریت از طریق این سرویس های مبتنی بر HTTP را می دهد. پرس وجوها با ایجاد URL ای که سولار درک خواهد کرد، اجرا می شوند.
SolrJ یا SolrJava ابزاری است که توسط برنامه مبتنی بر جاوا برای ارتباط به آپاچی سولارجهت نمایه گذاری استفاده می شود. SolrJ به پوشانندهها[24] و آداپتورهای[25] جاوا امکان می دهد تا با سولار ارتباط برقرار کرده و نتایج آن را به اشیا جاوا ترجمه کنند. بکارگیری SolrJ بسیار راحت تر از استفاده از HTTP خام و JSON است. SolrJ از آپاچی HttpClient برای ارسال درخواست های HTTP استفاده می کند. این ابزار یک رابط کاربر پسند فراهم می کند و جزئیات ارتباطات را از برنامه های مصرف کننده مخفی می کند. با استفاده از SolrJ ، قادر خواهید بود اسناد خود را نمایه گذاری کنید و پرس وجوها را اجرا کنید.
دو روش اصلی برای انجام این کار وجود دارد؛ یکی استفاده از رابط EmbeddedSolrServer است. اگر از سولار در یک برنامه توکار استفاده می کنید، این رابط توصیه می شود. این رابط از ارتباط مبتنی بر HTTP استفاده نمی کند. در اینجا کد نمونه آمده است:
System.setProperty(“solr.solr.home”, “/home/hrishi/work/scaling-solr/
example/solr”);
CoreContainer.Initializer initializer = new CoreContainer.
Initializer();
CoreContainer coreContainer = initializer.initialize();
EmbeddedSolrServer server = new EmbeddedSolrServer(coreContainer, “”);
ModifiableSolrParams params = new ModifiableSolrParams();
params.set(“q”, “Scaling”);
QueryResponse response = server.query(params);
System.out.println(“response = ” + response);
روش دیگر استفاده ار رابط HTTPSolrServer است، که با سرور سولار از طریق پروتکل HTTP صحبت میکند؛ این برای زمانی که برنامه مبتنی بر کلاینت- سرور دارید مناسب است. آپاچی از کلاینت HTTP برای ارتباط به سولار استفاده می کند. این نمونه کد مربوط به همین موارد است:
String url = “http://localhost:8983/solr”;
SolrServer server = new HttpSolrServer( url );
ModifiableSolrParams params = new ModifiableSolrParams();
params.set(“q”, “Scaling”);
QueryResponse response = server.query(params);
System.out.println(“response = ” + response);
برای آپلودهای انبوه از ConcurrentUpdateSolrServer استفاده کنید، که CloudSolrServer با نمونه اجرا شده در ابر ارتباط برقرار می کند. SolrJ در مخزن رسمی Mavenموجود است. میتوانید به سادگی با اضافه کردن وابستگی زیر به pom.xml از SolrJ استفاده کنید:
<dependency>
<artifactId>solr-solrj</artifactId>
<groupId>org.apache.solr</groupId>
<version>1.4.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
برای استفاده از EmbeddedSolrServer، باید وابستگی Solr-core را نیز اضافه کنید:
<dependency>
<artifactId>Solr-core</artifactId>
<groupId>org.apache.Solr</groupId>
<version>1.4.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
آپاچی سولار همچنین امکان دسترسی به سرویس های خود را برای تکنولوژی های مختلف، مانند JavaScript، Python، و Ruby فراهم می آورد، در زیر تکنولوژی ها و تعامل با سولار آورده شده است.
JavaScript: آپاچی سولار با JavaScript در یک مدل کلاینت – سرور از طریق XMLHTTP / رابط وب استاندارد کار می کند؛ از کتابخانه هایی نظیر ajax-Solr و solrj برای این تعامل استفاده کنید.
Ruby: برای روبی، پروژه ای بنام sunspot (http://sunspot.github.io) وجود دارد که جستجوی با قدرت سولار را برای اشیا روبی امکانپذیر می کند. همچنین از طریق APIها و کتابخانه های SolrRuby از DelRuby استفاده کنید.
PHP: PHP می تواند از راه های مختلفی با سولار صحبت کند. به عنوان مثال: PHP می تواند سرویس های سولار را از طریق کنترلکنندههای خودش استفاده کند.
Java: جاوا مستقیماً از طریق API های solrJ صحبت می کند. با توجه به پشتیبانی سولار از رابط HTTP، از طریق تماس های استاندارد HTTP نیز میتواند این کار را انجام دهد.
Python: پایتون کتابخانه Solr-Python Client API را برای تماس با سولار جهت جستجو ارائه می دهد.
Perl: CPAN کتابخانه های سولار (http://search.cpan org/~garafola/Solr-0.03/. ) را برای استفاده از جستجوی سولار ارائه می دهد. با این حال، همچنین می توانید از کلاینت سبک وزن مبتنی بر HTTP برای گفتگو با سولار استفاده کنید.
.NET : تعداد زیادی پیاده سازی برای بکارگیری سولار در برنامه مبتنی بر NET. SolrNET (https://github.com/mausch/ SolrNet ) یا Solr Contrib در CodePlex (http://solrcontrib. codeplex.com) وجود دارد.
کار با اسناد غنی ( Apache Tika)
آپاچی تیکا یک تجزیه کننده مبتنی بر SAX برای استخراج فراداده از انواع مختلف اسناد است.
اپاچی تیکا برای استخراج فراداده و محتوای متن ساختاریافته از اسناد مختلف، با استفاده از کتابخانه های تجزیه کننده موجود، از رابط org.apache.tika.parser.Parser استفاده می کند. آپاچی تیکا یک روش تجزیه واحدی با امضای زیر ارائه می دهد.
void parse(InputStream stream, ContentHandler handler, Metadata
metadata)
throws IOException, SAXException, TikaException;
این روش، جریان اسناد را بعنوان ورودی می پذیرد و رویداد XHTML SAX را بعنوان خروجی تولید می کند. لذا، تیکا رابط کاربری ساده و در عین حال قدرتمند را در برخورد با انواع مختلف اسناد فراهم می کند.
آپاچی تیکا انواع فرمت های سند را پشتیبانی می کند. Rich Text format(RTF)، HTML، XHTML، فرمت هایMicrosoft Office (Excel،Word، PowePoint، Visio و Outlook)، Portable Document format (PDF) انواع فایل های متنی، انواع مختلف فرمت های فشرده سازی (zip، gzip، bzip، bzip2، tarball و غیره)، فرمت های صوتی (MP3، MIDI و فرمت های wave). اشعار، عنوان و موضوع از این فرمت ها قابل استخراج است.
آپاچی تیکا به طور خودکار نوع سند ورودی را تعیین میکند( Word ، PDF و غیره ) و متناسب با آن محتوایش را استخراج می کند. از طرف دیگر، میتوانید نوع MIME را برای تیکا با پارامتر stream.type مشخص کنید. آپاچی تیکا جریان XHTMLرا از طریق تجزیه کننده SAXتولید می کند. سپس آپاچی سولار، با ایجاد فیلدهایی برای نمایه سازی، به رویدادهای SAX واکنش نشان می دهد. تیکا اطلاعات فراداده، از قبیل عنوان، موضوع و نویسنده را برای اسناد تجزیه شده تولید می کند.
جستجوی اطلاعات در سولار
ما قبلاً دیده ایم که چگونه آپاچی سولار به طور مؤثری از کنترل کننده های درخواست مختلف استفاده می کند تا با روش های گسترده ای دریافت نتایج جستجو به مصرف کنندگان را ارئه دهد. هر کنترل کننده درخواست، تجزیه کننده پرس و جوی خودش را استفاده می کند، که پارامترها و مقادیر آنها را از رشته پرس و جو استخراج می کند و اشیا پرس و جوی لوسین (Lucene Query Objects) را تشکیل می دهد.
تجزیه کننده های پرس و جوی استاندارد دقت بیشتری نسبت به داده های جستجو فراهم می کند؛ DisMaxQueryParser، Extended DisMaxQueryParser نَحو[26] مشابه جستجوی گوگل را ارائه می دهند. بسته به اینکه کدام کنترل کننده درخواست فراخوانی شده، نحو پرس و جو تغییر می یابد. بیایید برخی از عبارات مهم را مرور کنیم.
|
معنی |
عبارت |
|
رشته پرس و جو مجموعه کلمات را پشتیبانی می کند. مانند title:Scaling* |
q?<string> |
|
لیست فیلدی که پاسخ جستجو باز می گرداند. |
fl=id,book-name |
|
نتایج/ facet هایی که توسط نویسندگان به ترتیب صعودی مرتب می شوند. |
sort=author asc |
|
به دنبال قیمت بین 10 و 100 می گردد؛ نتیجه را به 10 ردیف در یک بار محدود می کند، با شروع از پنجمین نتیجه منطبق |
price[* TO 100]&rows=10&start=5 |
|
پررنگ کردن نام لیست فیلد و ویژگی هایش را فعال می کند. |
hl=true&hl.fl=name,features |
|
جستجوی facet با فیلد year را فعال می کند. |
&q=*:*&facet=true&facet. field=year |
|
تاریخ انتشار بین سال گذشته ( همان روز) و امروز |
Publish-date:[NOW-1YEAR/DAY TO NOW/DAY] |
|
به این جستجوی مجاورتی گفته می شود. توضیحات حاوی javaو SQL در یک تک سند را با مجاورت حداکثر 10 کلمه جستجو می کند |
description:”Java sql”~10 |
|
عبارت Open JDk را در سند جستجو می کند. |
“open jdk” NOT “Sun JDK” |
|
شناسه مشخص و نتایج مشابه را جستجو می کند |
&q=id:938099893&mlt=true |
خلاصه
این فصل به آشنایی با پروژه موتور جستجوی آپاچی سولار متمرکز بود. با راه اندازی آپاچی سولار شروع گردید، در ادامه مشکلات و راه حل های متداول و به دنبال آن معماری و پیکربندی آپاچی سولارتشریح شد. همچنین به بارگذاری داده ها درآپاچی سولار از طریق کنترل کننده های مختلف اشاره کردیم.
چگونگی استفاده از solrJ برای تعامل با آپاچی سولار را بیان کردیم. اکنون که درک خوبی از آپاچی هدوپ و آپاچی سولار داریم، مرحله بعدی این است که بفهمیم برای جستجوی توزیع شده چگونه آپاچی سولار و هدوپ با یکدیگر کار میکنند. در فصل بعد خواهیم دید چگونه آپاچی هدوپ و سولار یکدیگر را تکمیل می کنند.
-
Apache Solr ↑
-
Apache lucene ↑
-
Java servlet ↑
-
Tika ↑
-
command line ↑
-
Deploy ↑
-
source ↑
-
data import handler ↑
-
Tomcat ↑
-
core ↑
-
collection ↑
-
logging ↑
-
single core ↑
-
multicore ↑
-
client server ↑
-
schema ↑
-
master-slave ↑
-
Tokenizers ↑
-
caching ↑
-
Request handler ↑
-
Extracting Request Handler ↑
-
Index handlers ↑
-
wrappers ↑
-
adaptors ↑
-
syntax ↑
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 1944
برچسبapache solr soler Solr آپاچی سولار آپاچی سولار (Solr) آپاچی سولر جستجو با solr سلر موتور جستجو موتور جستجوی Solr
نوشته های مرتبط













همچنین ببینید
خزشگر crawler4j و مقایسه با دیگر خزشگرها
در این نوشتار سعی داریم راه اندازی یک خزشگر وب قدرتمند را به همراه امکان …
آموزش الستیک سرچ (Elastic Search) نصب و اجرا
در این مبحث به آموزش الستیک سرچ (Elastic Search) میپردازیم. ElasticSearch یا (ES) یک موتور …
