 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
روشها و معیارهای ارزیابی الگوریتم یادگیری ماشین، هوش مصنوعی و مدل های داده کاوی
در این مبحث میخواهیم تعدادی از معیارهای ارزیابی هوش مصنوعی را بررسی کنیم. یکی از مهمترین مراحل پس از طراحی و ساخت یک مدل یا یک الگوریتم، ارزیابی کارآیی (performance)، دقت و صحت آن است. در ادامه با روس هایی برای ارزیابی مدل آشنا میشویم.
عناوين مطالب: '
معیارهای ارزیابی مدل یا الگوریتم جهت تشخیص دقت و صحت
معیارهای متنوعی برای ارزیابی کارایی الگوریتم ها وجود دارد. در انتخاب معیارهای ارزیابی کارایی می بایست دلایل قانع کننده وجود داشته باشد چرا که چگونگی اندازه گیری و مقایسه کارایی الگوریتم ها، کاملا به معیارهایی که انتخاب می کنید وابسته است. همچنین چگونگی وزن دادن به اهمیت ویژگی های مختلف در نتایج، کاملا تحت تاثیر معیار هایی است که انتخاب می کنید.
یک مثل معروف وجود دارد که میگوید «چیزی را نتوانی ارزیابی کنی، نمیتوانی بهبود دهی». در بحث الگوریتمهای طبقه بندی هم برای اینکه مشخص شود آیا الگوریتم مدنظر، بر روی دادههای مسئله خوب جواب داده است یا خیر، بایستی کارایی، دقت یا صحت آن ارزیابی شود.
تعریف حساسیت (sensitivity) و تشخیصپذیری (specificity)
حساسیت و تشخیصپذیری دو شاخص مهم برای ارزیابی آماری عملکرد نتایج آزمونهای طبقهبندی باینری (دودویی یا دوحالته) هستند، که در آمار به عنوان توابع طبقهبندی شناخته میشوند. نتایج را بعد از تحلیل می توان به دو گروه داده مثبت و منفی تقسیم کرد. روش های آزمون و ارزیابی، نتایج یک آزمایش را به این دو دسته تقسیم میکند. سپس کیفیت الگوریتم با استفاده از شاخصهای حساسیت و تشخیصپذیری قابل اندازهگیری و توصیف می شوند.
دسته بندی داده ها یعد از تحلیل
۱- مثبت صحیح (True Positive) که یک معیار مثبت است.
۲- مثبت کاذب (False Positive) که یک معیار منفی است.
۳- منفی صحیح (True Negative) که یک معیار مثبت است.
۴- منفی کاذب (False Negative) که یک معیار منفی است.
نکته مهم: پارامتر تشخیصپذیری را نیز اصطلاحا صحت (Precision) در برابر پارامتر (False Positive)، و حساسیت را نیز اصطلاحا صحت (Recall) در برابر پارامتر (False Negative) مینامند.
نکته: یک ترجمه خوب و قابل درک برای مثبت کاذب “اتهام غلط” و یک ترجمه قابل درک برای منفی کاذب “اعتماد غلط” است.
مثال های از “مثبت های کاذب” و “منفی های کاذب”
- بخش امنیت فرودگاه: یک “مثبت کاذب” هنگامی است که اشیاء معمولی مانند کلیدها و یا سکه ها به اشتباه اسلحه تشخیص داده می شوند (و ماشین صدای “بیپ” را ایجاد می کند)
- کنترل کیفیت: یک “مثبت کاذب” هنگامی است که محصول با کیفیت خوب، مردود می شود و یک “منفی کاذب” هنگامی است که محصول بی کیفیت مورد قبول واقع می شود
- نرم افزار ضد ویروس: یک “مثبت کاذب” هنگامی است که یک فایل عادی بعنوان یک ویروس شناخته می شود
- آزمایش پزشکی: گرفتن آزمایش های ارزان قیمت و بررسی آن توسط تعداد زیادی از پزشکان می تواند مثبتهای کاذب زیادی به بار آورد (یعنی جواب تست بگوید که بیمار هستید در حالی که چنین نیست)، و سپس خواسته شود که دوباره آزمایش های با دقت بیشتر بگیرید.
کدام معیارها باید بهتر باشند:
بدیهی است معیار های که تشخیص درست را نمایش میدهند باید بهتر باشند که در زیر با رنگ سبز نشان داده شده است.
۱- مثبت صحیح (True Positive) = درست شناسایی شده است.
۲- مثبت کاذب (False Positive) = اشتباه شناسایی شده است (خطای نوع یک در انجام آزمون). (واژه اتهام غلط ترجمه مناسبی است.)
۳- منفی صحیح (True Negative) = به درستی رد شد.
۴- منفی کاذب (False Negative) = اشتباه رد شد (خطای نوع دوم در انجام آزمون). (واژه اعتماد غلط ترجمه مناسبی است.)
ماتریس اختلاط یا درهم ريختگی (confusion matrix)
به ماتریسی گفته میشود که نتیجه ارزیابیِ عملکردِ الگوریتمها در آن نمیش داده میشود. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. معمولاً به کاربرد این ماتریس در الگوریتمهای بدون ناظر ماتریس تطابق می گویند. هر ستون از ماتریس، نمونهای از مقدار پیشبینی شده را نشان میدهد. در صورتی که هر سطر نمونهای واقعی (درست) را در بر دارد. اسم این ماتریس نیز از آنجا بدست میآید که امکان اشتباه و تداخل بین نتایج را آسان تر قابل مشاهده می کند.
در حوزه الگوریتم های هوش مصنوعی، ماتریس در هم ریختگی به ماتریسی گفته میشود که در آن عملکرد الگوریتمها را نمایش میدهند. معمولاً چنین نمایشی برای الگوریتمهای یادگیری با ناظر استفاده میشود، اگرچه در یادگیری بدون ناظر نیز کاربرد دارد. همان طور که ذکر شد معمولاً به کاربرد این ماتریس در الگوریتمهای بدون ناظر ماتریس تطابق میگویند. هر ستون از ماتریس، نمونهای از مقدار پیشبینیشده را نشان میدهد. درصورتیکه هر سطر نمونهای واقعی (درست) را در بر دارد. در خارج از دنیای هوش مصنوعی این ماتریس معمولاً ماتریس پیشایندی (contingency matrix) یا ماتریس خطا (error matrix) نامیده میشود.
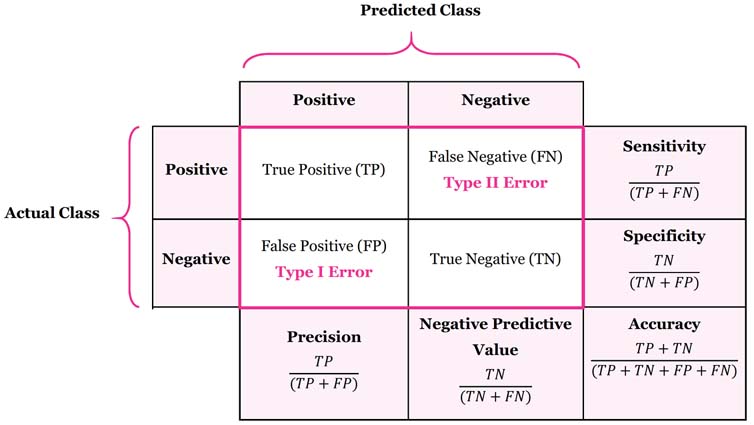
روش های ارزیابی دقت و صحت
درنهایت بعد از هر تحلیلی نتایج بهدستآمده را باید در چهار گروهی که در بالا در ماتریس اختلاط توصیف شد، دسته بندی کرد تا بتوان کیفیت تحلیل را مورد ارزیابی قرار داد. همچنین کارایی الگوریتم را برای موارد استفاده مختلف تفسیر و توصیف نمود. در ارزیابی نتایج معمولا معیارهای زیر متصور است و بیشترین استفاده را نسبت به معیار های ارزیابی دیگر دارد.
- دقت (Accuracy)
- صحت (Precision)
- Recall: زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود.
- معیار (Specificity)
- F1 Score
- ROC AUC:
- MCC: پارامتر دیگری است که برای ارزیابی کارایی الگوریتمهای یادگیری ماشین از آن استفاده میشود. این پارامتر بیانگر کیفیت کلاسبندی برای یک مجموعه باینری میباشد.
دقت (Accuracy):
به طور کلی، دقت به این معناست که مدل تا چه اندازه خروجی را درست پیشبینی میکند. با نگاه کردن به دقت ، بلافاصله میتوان دریافت که آیا مدل درست آموزش دیده است یا خیر و کارآیی مدل به صورت کلی چگونه است. نکته مهم اینکه این معیار اطلاعات جزئی در مورد کارآیی مدل ارائه نمیدهد. بلکه فقط حد آموزش یافتن مدل را به ما نشان می دهد. لذا ارزش زیادی از نظر میزان صحت عملکرد ندارد.
علت عدم اعتبار و کم ارزش بودن این معیار چیست؟ فرض کنید ممکن است داده هایی که برای آموزشِ مدل به کار رفته باشند دارای اشکال بوده و اعتبار لازم را نداشت اند ولی با همان داده های نا معتبر فرایند آموزش را به درستی طی کرده اند. به عبارتی فرایند آموزش درست بوده ولی یادگیریندگی مدل نسبت به داده های واقعی برای آزمون ضعیف خواهد بود. به عبارتی فرایند آموزش درست بوده ولی موضوع آموزش دقیق نبوده است. مثل استادی که توان ارائه و آموزش خوبی دارد ولی مطلب مورد آموزش را اشتباه آموزش میدهد.
Accuracy = (TP+TN) / (TP+FN+FP+TN)
صحت (Precision) :
وقتی که مدل نتیجه را مثبت (positive) پیشبینی میکند، این نتیجه تا چه اندازه درست است؟ زمانی که ارزش false positives بالا باشد، معیار صحت، معیار مناسبی خواهد بود. فرض کنید، مدلی برای تشخیص سرطان داشته باشیم و این مدل Precision پایینی داشته باشد. نتیجه این امر این است که این مدل، بیماری بسیاری از افراد را به اشتباه سرطان تشخیص میدهد. نتیجه این امر استرس زیاد، آزمایشهای فراوان و هزینههای گزافی را برای بیمار به دنبال خواهد داشت.
در واقع نسبت مقداری موارد صحیح طبقهبندیشده توسط الگوریتم از یک کلاس مشخص، به کل تعداد مواردی که الگوریتم چه بهصورت صحیح و چه بهصورت غلط، در آن کلاس طبقهبندی کرده است که بهصورت روش زیر (Precision) محاسبه میشود:
Precision =TP / (TP+FP)
ولی همانگونه که از رابطه قبل (Accuracy) مشخص بود، تعداد افراد سالمی که به اشتباه به عنوان فرد بیمار تشخیص داده شده، هیچ تاثیری در محاسبه این پارامتر نداشت.
تفاوت Accuracy با Precision
فراخوانی یا حساسیت یا Recall یا Sensitivity:
در نقطه مقابل این پارامتر، ممکن است در مواقعی دقت تشخیص کلاس منفی حائز اهمیت باشد. از متداولترین پارامترها که معمولا در کنار حساسیت بررسی میشود، پارامتر خاصیت (Specificity)، است که به آن «نرخ پاسخهای منفی درست» (True Negative Rate) نیز میگویند. خاصیت به معنی نسبتی از موارد منفی است که آزمایش آنها را به درستی به عنوان نمونه منفی تشخیص داده است. این پارامتر به صورت زیر محاسبه میشود.
زمانی که ارزش false negatives بالا باشد، معیار Recall، معیار مناسبی خواهد بود. دوباره فرض کنید، مدلی برای تشخیص سرطان داشته باشیم و این مدل حساسیت پایینی داشته باشد. نتیجه این امر این است که این مدل، بسیاری از افراد بیمار را به اشتباه سالم تشخیص میدهد. نتیجه این امر از بین رفتن بیمار را به دنبال خواهد داشت.در واقع، «حساسیت» معیاری است که مشخص میکند دستهبند، به چه اندازه در تشخیص تمام افراد مبتلا به بیماری موفق بودهاست. در واقع زمانی که پژوشهگر از آن روش به عنوان ارزیابی برای دستهبندی خود استفاده میکند، هدفش دستیابی به کشف حداکثری بیماران است نه صحت در تشخیص درستِ بیماران.
یا فرض کنیم مدلی برای تشخیص بیماری کشنده ابولا داشته باشیم. اگر این مدل Recall پایینی داشته باشد چه اتفاقی خواهد افتاد؟ این مدل افراد زیادی که آلوده به این بیماری کشنده هستند را سالم در نظر میگیرد و این فاجعه است. نسبت مقداری موارد صحیح طبقهبندی شده توسط الگوریتم از یک کلاس به تعداد واقعی موارد حاضر در کلاس مذکور که بهصورت زیر محاسبه میشود:
Recall = Sensitivity = (TPR) = TP / (TP+FN)
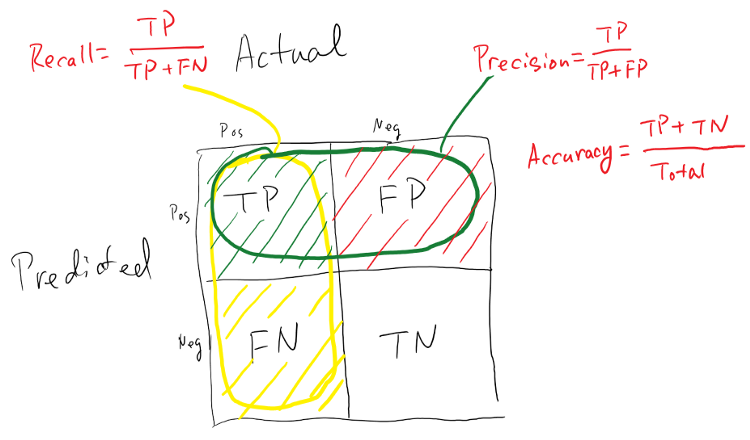
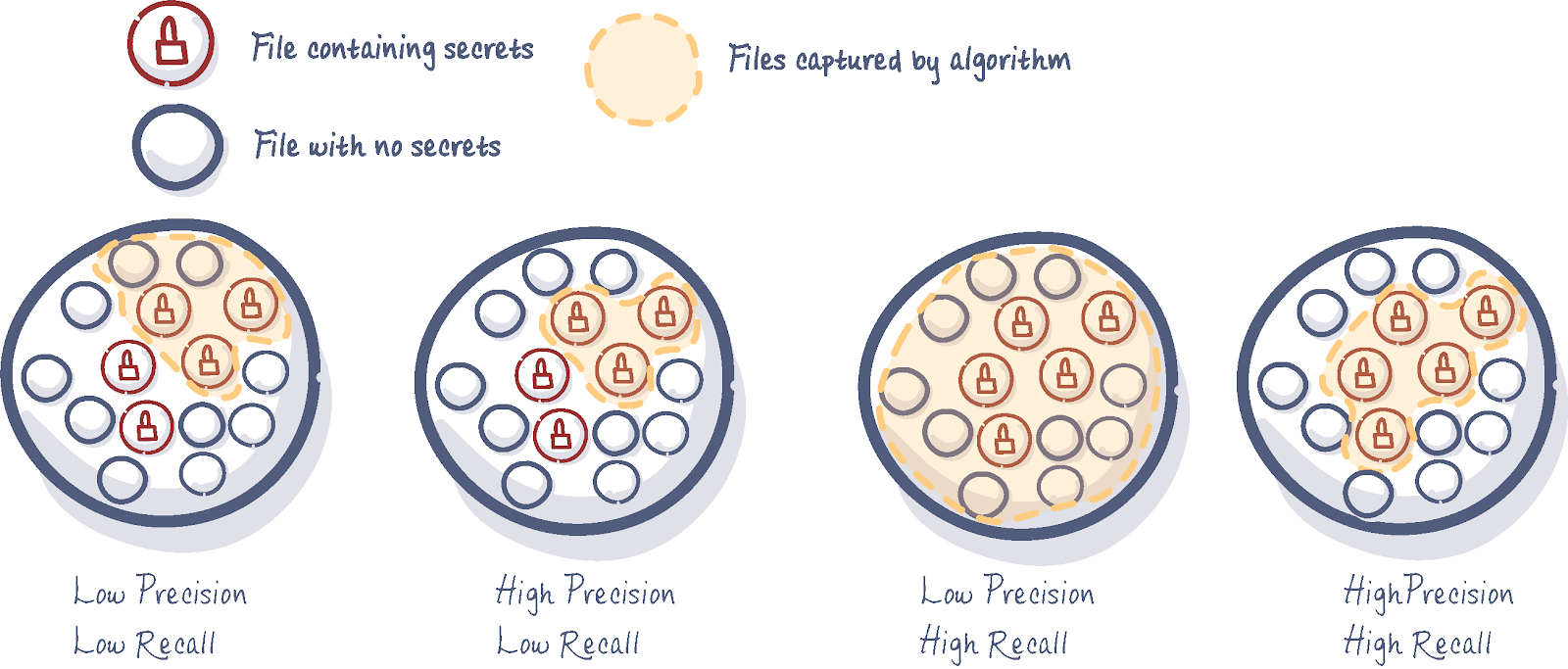
تفاوت Recall با Precision
فرض کنید مدلی برای یافتن فایل های رمز شده آموزش داده شده است. حال تفاوت Recall با Precision در شکل زیر بررسی کنید. بهترین مدل مدلی است که هر دو معیار نام برده شده در ببالاترین وضعیت داشته باشند.
معیار (Specificity):
در نقطه مقابل این پارامتر، ممکن است در مواقعی دقت تشخیص کلاس منفی حائز اهمیت باشد. از متداولترین پارامترها که معمولا در کنار حساسیت بررسی میشود، پارامتر خاصیت (Specificity)، است که به آن «نرخ پاسخهای منفی درست» (True Negative Rate) نیز میگویند. خاصیت به معنی نسبتی از موارد منفی است که آزمایش آنها را به درستی به عنوان نمونه منفی تشخیص داده است. این پارامتر به صورت زیر محاسبه میشود.
Specificity (TNR) = TN / (TN+FP)
معیارهای ارزیابی F1 Score یا F-measure
معیار F1، یک معیار مناسب برای ارزیابی دقت یک آزمایش است. این معیار Precision و Recall را با هم در نظر میگیرد. معیار F1 در بهترین حالت، یک و در بدترین حالت صفر است.
F-measure= 2 * (Recall * Precision) / (Recall + Precision)
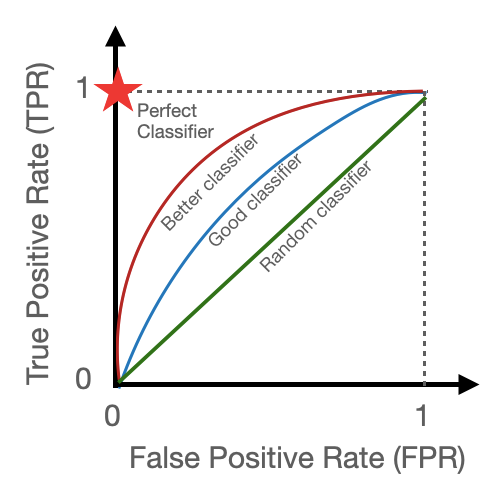
ROC AUC:
ROC مخفف Receiver Operating Characteristic است که یک اصطلاح جنگ جهانی دوم برای ارزیابی عملکرد رادار است. ما specificity و sensitivity را قبلاً مورد بحث قرار دادیم، اما برای یادآوری: حساسیت نسبت رویدادهای (موارد) به درستی پیشبینیشده است، در حالی که specificity، نسبت عدم رویدادها (موارد) به درستی شناساییشده است.
ROC یک روش برای ارزیابی عملکرد یک سیستم تشخیصی یا تصمیمگیری است. در این روش، عملکرد سیستم با استفاده از دو معیار، یعنی نرخ تشخیص درست (True Positive Rate) و نرخ تشخیص غلط (False Positive Rate) بررسی میشود. سپس با تغییر آستانه تصمیمگیری، نقاط مختلفی در فضای دو بعدی ایجاد میشود که به عنوان منحنی ROC شناخته میشود. این منحنی نشان میدهد که با تغییر آستانه تصمیمگیری، چگونه نرخ تشخیص درست و نرخ تشخیص غلط تغییر میکنند و به عنوان یک ابزار مفید برای انتخاب بهترین آستانه تصمیمگیری در سیستمهای تشخیصی و تصمیمگیری استفاده میشود.
در حالت ایده آل، هم specificity و هم sensitivity باید بالا باشد. منحنی ROC مبادله بین دو سازه را نشان می دهد. امتیاز ROC-AUC اطلاعاتی را در مورد اینکه یک مدل کار خود در جداسازی موارد را به خوبی انجام میدهد به ما ارائه میدهد: در مورد ما، تمایز اهداکنندگان از کسانی که اهدا نمیکنند. نمره 0.91 به این معنی است که 91٪ احتمال دارد که یک مدل بتواند اهداکنندگان را از غیر اهداکنندگان تشخیص دهد.
معیارهای ارزیابی MCC:
پارامتر دیگری است که برای ارزیابی کارایی الگوریتمهای یادگیری ماشین از آن استفاده میشود. این پارامتر بیانگر کیفیت کلاسبندی برای یک مجموعه باینری میباشد. (MCC (Matthews correlation coefficient، سنجهای است که بیانگر بستگی مابین مقادیر مشاهده شده از کلاس باینری و مقادیر پیشبینی شده از آن میباشد. مقادیر مورد انتظار برای این کمیت در بازه 1- و 1 متغیر میباشد. مقدار 1+، نشان دهنده پیشبینی دقیق و بدون خطای الگوریتم یادگیر از کلاس باینری میباشد. مقدار 0، نشان دهنده پیشبینی تصادفی الگوریتم یادگیر از کلاس باینری میباشد. مقدار 1-، نشان دهنده عدم تطابق کامل مابین موارد پیشبینی شده از کلاس باینری و موارد مشاهده شده از آن میباشد. مقدار این پارامتر را بهطور صریح، با توجه به مقادیر ماتریس آشفتگی به شرح زیر، میتوان محاسبه نمود:
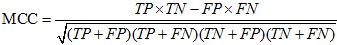
مقایسه برخی از الگوریتم های یادگیری با معیارهای مختلف
در جدول زیر مقایسه برخی از روش ها با معیارهای مختلف به عنوان نمونه ارائه شده است. دانستن این نکته مهم است که با داده های مختلف و تعداد ویژگیهایی که برای آموزش استفاده میکنیم عدد این معیارها تغییر خواهد کرد. ولی برای انتخاب روش بر اساس میزان دقت مدل تشکیل این نوع جداول برای تصمیم گیری یسیار موثر است.
معیارهای متنوعی برای ارزیابی کارایی الگوریتم ها وجود دارد. در انتخاب معیارهای ارزیابی کارایی می بایست دلایل قانع کننده وجود داشته باشد چرا که چگونگی اندازه گیری و مقایسه کارایی الگوریتم ها، کاملا به معیارهایی که انتخاب می کنید وابسته است. همچنین چگونگی وزن دادن به اهمیت ویژگی های مختلف در نتایج، کاملا تحت تاثیر معیار هایی است که انتخاب می کنید.
یک مثل معروف وجود دارد که میگوید «چیزی را نتوانی ارزیابی کنی، نمیتوانی بهبود دهی». در بحث الگوریتمهای طبقه بندی هم برای اینکه مشخص شود آیا الگوریتم مدنظر، بر روی دادههای مسئله خوب جواب داده است یا خیر، بایستی کارایی، دقت یا صخت آن ارزیابی شود.
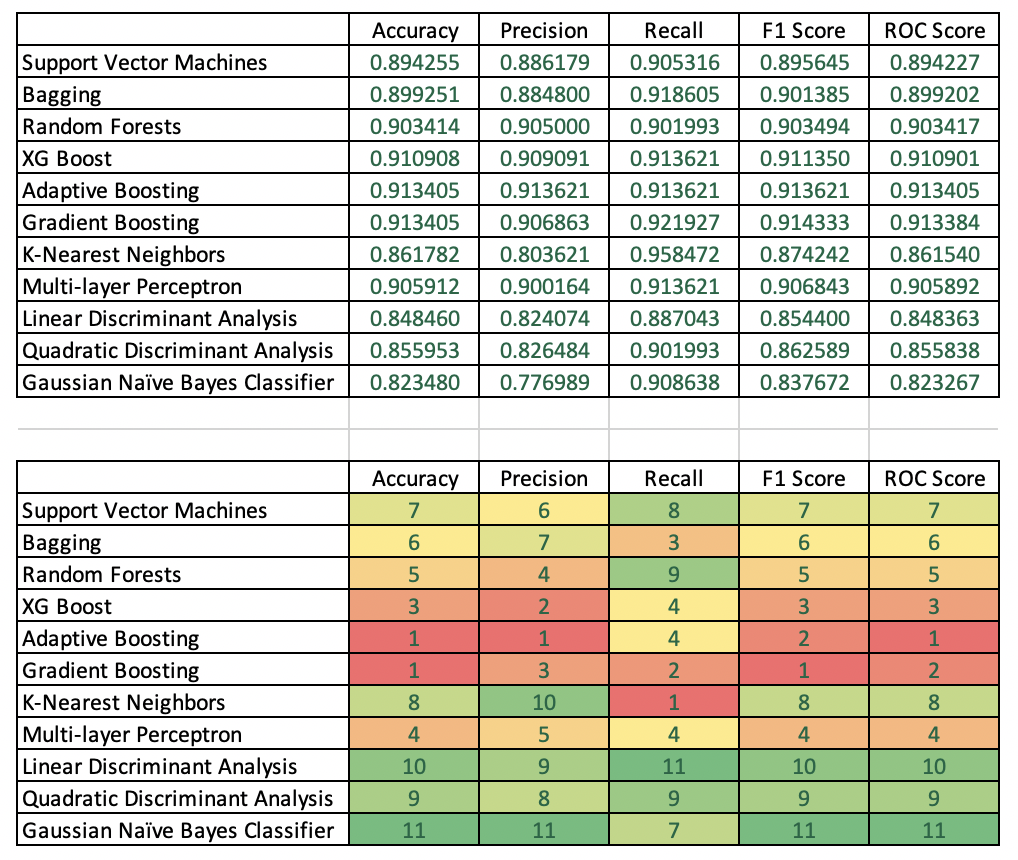
نتایج مقایسه دقت
جدول بالا آمار دقت انواع مدل های مختلف را فهرست می کند. جدول دوم مدل ها را بر اساس ستون رتبه بندی می کند، به عنوان مثال. بهترین مدل ها را بر اساس یکی از پنج معیار دقت شناسایی می کند.
Accuracy: تقویت تطبیقی و Gradient Boosting بهترین دقت آزمون را با نمرات یکسان در 91.34 ایجاد کردند.
Precision صحت: Adaptive Boosting یک برنده واضح بود و پس از آن XG Boost و Gradient Boosting به ترتیب در جایگاه دوم و سوم قرار گرفتند.
Recall: روش K-Nearest Neighbors با امتیاز 95.85 قوی ترین بود. Gradient Boosting دوم شد.
F1 Score: برای Gradient Boost بهترین بود و پس از آن به ترتیب Adaptive Boost و XG Boost قرار گرفتند.
امتیاز ROC: تقویت تطبیقی بهترین امتیاز را به دست آورد و سپس اGradient Boosting و سپس XG Boost به دست آورد.
تصمیم گیری بر اساس میزان دقت مدل
فرض کنید یک سازمان غیر انتفاعی احتمالا مجبور خواهد شد تا حد امکان عاقلانه از بودجه بازاریابی خود استفاده کند: سودآوری کلیدی است. در نتیجه، دقت و امتیاز F1 بسیار مهم است. در نتیجه، adaptive boosting احتمالاً انتخاب بهتری است زیرا همان دقت gradient boosting را ارائه می دهد اما با دقت بهتر. در حالی که gradient boosting امتیاز F1 بهتری نسبت به adaptive boosting دارد، این تفاوت حداقلی است. علاوه بر این، adaptive boosting امتیاز ROC بهتری دارد که به این معنی است که مدل در جداسازی اهداکنندگان از غیر اهداکنندگان بهتر است.
منابع:
https://www.datasklr.com/select-classification-methods/model-selection
خلاصه ای از معیار های مختلف
-
sensitivity, recall, hit rate, or true positive rate (TPR): (TP / (TP + FN))
-
specificity, selectivity or true negative rate (TNR): (TN / (TN + FP))
-
precision or positive predictive value (PPV): (TP / (TP + FP))
-
negative predictive value (NPV): (TN / (TN + FN))
-
miss rate or false negative rate (FNR): (FN / (FN + TP))
-
fall-out or false positive rate (FPR): (FP / (FP + TN))
-
false discovery rate (FDR): (FP / (FP + TP))
-
false omission rate (FOR): (FN / (FN + TN))
-
threat score (TS) or Critical Success Index (CSI): (TP / (TP + FN + FP))
-
accuracy (ACC): (TP+TN) / (TP+FP+FN + TN))
-
F1: 2*TP/(2*TP+FP+FN)
انتخاب متریکهای مناسب
انتخاب متریکهای مناسب برای ارزیابی مدلهای یادگیری ماشین و به ویژه مدلهای شبکه عصبی مانند LSTM بستگی به نوع مسئله (طبقهبندی، رگرسیون، و غیره) و اهداف خاص شما دارد. در ادامه، برخی از متریکهای رایج و مهم که میتوانید به مدلهای خود اضافه کنید را معرفی میکنم:
1. برای مسائل طبقهبندی:
• Accuracy (دقت): نسبت پیشبینیهای صحیح به کل پیشبینیها.
• Precision (دقت): نسبت پیشبینیهای مثبت صحیح به کل پیشبینیهای مثبت.
• Recall (حساسیت): نسبت پیشبینیهای مثبت صحیح به کل نمونههای مثبت واقعی.
• F1 Score: میانگین هارمونیک دقت و حساسیت، مناسب برای دادههای نامتعادل.
• AUC-ROC: مساحت زیر منحنی ROC که عملکرد مدل را در سطوح مختلف آستانه اندازهگیری میکند.
2. برای مسائل رگرسیون:
• Mean Absolute Error (MAE): میانگین قدر مطلق خطاها.
• Mean Squared Error (MSE): میانگین مربعات خطاها، حساس به خطاهای بزرگ.
• Root Mean Squared Error (RMSE): ریشه مربع میانگین مربعات خطاها، مشابه MSE اما با مقیاس اصلی.
• R-squared (R²): نسبت واریانس توضیح داده شده توسط مدل، نشاندهنده کیفیت برازش مدل.
3. متریکهای اضافی:
• Mean Absolute Percentage Error (MAPE): درصد میانگین خطاها، مناسب برای مقایسه بین مدلها با مقیاسهای مختلف.
• Log Loss: مناسب برای مسائل طبقهبندی چندکلاسه و پیشبینی احتمالها.
4. متریکهای خاص:
• Kappa: برای ارزیابی توافق بین پیشبینیها و واقعیت، به ویژه در مسائل طبقهبندی.
• Confusion Matrix: برای تجزیه و تحلیل دقیقتر عملکرد مدل در طبقهبندی.
5. متریکهای خاص برای زمانسنجی:
• Mean Absolute Scaled Error (MASE): برای ارزیابی پیشبینیها در زمان، مقیاسگذاری شده بر اساس خطای مطلق.
انتخاب متریک:
در نهایت، انتخاب متریک مناسب بستگی به هدف شما و ویژگیهای دادهها دارد. اگر دادههای شما نامتعادل هستند، ممکن است متریکهایی مانند F1 Score یا AUC-ROC مفیدتر باشند. برای مسائل رگرسیونی، MAE و RMSE معمولاً انتخابهای خوبی هستند.
به یاد داشته باشید که بهتر است چندین متریک را بررسی کنید تا بتوانید یک ارزیابی جامع از عملکرد مدل خود داشته باشید.
ادامه مطلب به زودی…
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 115379
برچسبAccuracy F-measure F1 F1 Score MCC Precision Recall Specificity ارزیابی الگوریتم یادگیری ماشین ارزیابی مدل تشخیص دقت و صحت تعریف حساسیت حساسیت داده کاوی دقت روش هاای ارزیابی صحت مدل های داده کاوی معیار معیار ارزیابی معیارهای ارزیابی معیارهای ارزیابی مدل یادگیری ماشین
نوشته های مرتبط












همچنین ببینید

شناسایی خودکار حیوانات در تحقیقات حیات وحش با یادگیری ماشین
شناسایی خودکار حیوانات در تحقیقات حیات وحش یک برنامه جدید که توسط محققان از ایالت …

دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار …
8 دیدگاه
-
بازتاب ها: پرورش و تکثیر حرفه ای عروس هلندی در خانه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام ببخشید معیارهای precision و recall فقط در مسائل طبقه بندی باینری کاربرد دارند یا برای مسائل چند کلاس هم قابل تعریفند؟
سلام وقت بخیر
ببینید خواهرم هر دو پارامتر مربوط به صحت است. متنها پارامتر تشخیصپذیری را اصطلاحا صحت(Precision) در برابر پارامتر (False Positive)، و حساسیت را نیز اصطلاحا صحت(Recall) در برابر پارامتر (False Negative) مینامند. یعنی هر دو صحت را نشان میدهند ولی یکی صحت دربرابر مثبت کاذب و دیگری صحت دربرابر منفی کاذب را نشان میدهد.
در متن هم اصلاح کردم.
ممنون سوال خوبی بود
سلام ببخشید شما در یکجا precision رو دقت ترجمه کردید ویکجای دیگه صحت. recall هم صحت ترجمه کرده بودید که به نظر با توجه به فرمولش درست بود. ممنون اگر شفافش کنید.
سلام میشه لینک داخل مطلبو چک کنید.برای من مشکل داشت.ممنون
مطلب بسیار خوبی بود.ممنون
سلام.خواستم بابت وبسایت خوبتون ازتون
تشکر کنم و امیدوارم باعث ایجاد انگیزه
براتون بشه
اقا لینک مطلبو من پیدا نکردم.میشه راهنماییم کنید؟