 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
انواع ایندکس یا اندیس در پايگاه داده (Index)
انواع ایندکس: از اندیسها میتوان برای بهبود عملکرد پایگاهداده استفاده کرد. اندیسها به سرویسدهنده پایگاهداده اجازه میدهد تا سطرهای خاص را سریعتر از حالت بدون اندیس بیابد. در مباحث قبل به ایندکس معکوس و ایندکس ثانویه اشاره شده است. اکنون انواع اصلی که مبانی شاخص گذاری هستند مورد بررسی قرار میگیرد.
انواع ایندکس های متداول شامل موارد زیر میشود :
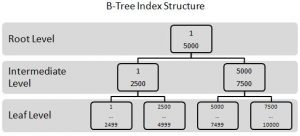
- B-tree: در این روش ساختار استفاده شده یک درخت متوازن میباشد که از آن در جهت افزایش سرعت در مقایسه برابری دادهای یا اجرای پرسوجوهای بازهای استفاده میشود. با توجه به شکل زیر منظور از تعادل در این درخت برابر تقریبی تعداد عناصر در دو طرف درخت میباشد به همین دلیل تعداد سطوحی بررسیشده برای پیدا کردن سطرها متفاوت همواره یک مقدار تقریباً ثابتی است. از سوی به دلیل این که موجودیتهای درخت B مرتب شده میباشند از این ساختار جهت بازیابی سطرها بهصورت مرتب شده نیز استفاده میشود. این ساختار با انواع دادهها سازگار بوده و حتی امکان بازیابی مقادیر خالی (Null) را نیز فراهم میکند.
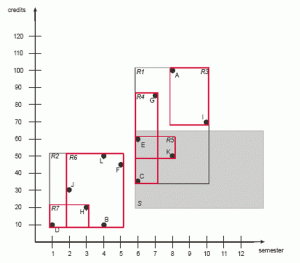
- R-tree: درخت مستطیلی داده ساختاری است که در روشهای دسترسی مکانی مانند فهرست کردن اطلاعات چندبعدی همچون مختصات جغرافیایی، مستطیلها یا چندضلعیها استفاده میشود. ایده اصلی این داده ساختار این است که اشیاء نزدیک هم را در یک گروه قرار میدهد و آنها را با کوچکترین مستطیلی که آنها را احاطه میکند در سطح بالایی درخت نشان میدهد. از آن جایی که همه اشیا در مستطیل احاطهکننده قرار میگیرند، یک جستجو که تداخلی با مستطیل احاطهکننده ندارد پس نمیتواند تداخلی با هیچ یک از اشیاء داخل آن داشته باشد. در سطح برگ هر مستطیل نشاندهنده یک شی است. شکل زیر این ساختار را نمایش میدهد.
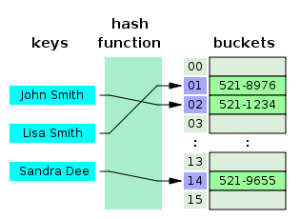
- درهمسازی (Hash): از این ساختار صرفاً در مقایسه برابری میتوان استفاده نمود اما پیچیدگی این مقایسه O(1) میباشد. این ساختار از لحاظ امنیتی بسیار ضعیف بوده زیرا قابلیت replication شدن را ندارد و در صورت خرابی سیستم باید بهصورت دستی از طریق REINDEX بازیابی شود.
- GiST (Generalized Search Tree): یکی دیگر از انواع ایندکس درخت جستجوی تعمیمیافته زیربنایی را فراهم میکند تا طراح بتواند برای دادههای با ساختار جدید و متفاوت یک اندیس گذاری بر پایه درخت متوازن پیادهسازی نماید. GiST مفهومی فراتر از مقیاسه برابری دادهای یا پرسوجوهای بازهای میباشد بهطوری که در استانداردهای PostgreSQL شامل کلاسها و ابزارهای برای انواع داده هندسی و آدرس شبکه, انواع دامنه و حتی جستوجوی متنی در اسناد میباشد.
- SP-GiST (Space Partitioned GiST): درخت جستجوی تعمیمیافته با فضای تقسیمشده نیز بستری را برای اندیس گذاری دادههای جدید فراهم میکند با این تفاوت که بجای درخت متوازن از درخت جستوجوی تقسیم شده (partitioned search trees) استفاده مینماید.
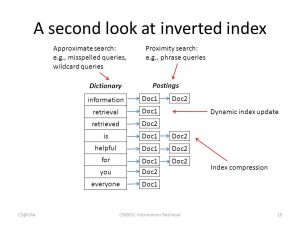
- GIN (Generalized Inverted Indexes): ایندکس معکوس تعمیمیافته برای فهرست کردن ستونها و عباراتی که چند مقداری میباشند بسیار مناسب است. از جمله نمونههای مناسب برای استفاده از این روش ایندکس گذاری میتوان ستونهای آرایهای, جستوجوهای متنی در اسناد و اسناد JSON/B را نام برد.
- BRIN (Block Range Indexes): این روش اندیس گذاری برای جداول بسیار بزرگی که ترتیب طبیعی سطرهای آنها بر مبنای مقدار یک ستون خاصی است مناسب میباشد زیرا اندیسها بهصورت بازهبندی شده ذخیره میشوند. به عنوان مثال جدول log که شامل وقایع اتفاق افتاده میباشد, یک جدول بزرگی است که ترتیب طبیعی آن بر اساس ستون برچسب زمانی اتفاقات میباشد. اگر با این روش ستون برچسب زمانی اندیس گذاری شود, در زمان انجام پرسوجو مقدار بزرگی از جدول نادیده گرفته شده و صرفاً بازهی مربوطه بررسی میشود که سبب میشود سرباری کمتری ایجاد شود.
-

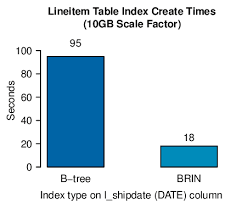
Block Range Indexes
انواع ایندکس گذاری بر روی متون
برای جستجوی در میان دادههای متنی نیاز به شاخص گذاری آنها است. در این قابلیت کلیه دادههای متنی مورد نظر شاخصگذاری میشوند. در این قابلیت بستر لازم برای شاخصگذاری دادههای متنی مهیا میشود.هدف از ایندکس گذاری بهینه تر کردن سرعت و کارایی در پیدا کردن نتایج مربوط به پرس و جوی مورد جستجو قرار گرفته است. بدون ایندکس موتور جستجو بایستی هر سند در پیکره را مورد جستجو قرار دهد و این نیاز به زمان و قدرت محاسباتی بالایی دارد.
انواع ساختارهای دیتا ایندکس:
Inverted index : ذخیره سازی لیستی از رخداد هر یک از ضابطه های جستجو، معمولا به فرم جدول هش و یا درخت باینری
Citation index : ذخیره سازی نقلقولها و یا هایپرلینکهای میان اسناد برای پشتیبانی از تحلیل نقلقولها (Citation Analysis)
Ngram index : ذخیره سازی دنبالهای از طول دیتا برای پشتیبانی از انواع دیگر متن کاوی
Document-term matrix : در تحلیلهای معنایی نهفته استفاده شده و رخداد کلمات در اسناد را در ماتریس اسپارس دو بعدی ذخیره میکند
Suffix tree : ذخیره سازی پسوند کلمات، مورد استفاده برای جستجوی الگوها در دنبالههای DNA و خوشه بندی
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس گروه تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 14749
برچسبB-tree Generalized Inverted Indexes Hash Indexing R-tree Search اندیس انواع اندیس انواع ایندکس انواع ایندکس گذاری انواع ایندیس گذاری ایندکس ایندکس ثانویه ایندکس معکوس جستجو درخت دودویی شاخص گذاری نمایه نمایه گذاری
نوشته های مرتبط













همچنین ببینید
اضافه شدن ویژگی ساسی (SASI) در کاساندرا به منظور Full Search
نمایه گذاری ساسی (SASI): از نسخه 3.4، میتوان از پیاده سازی جدیدی از اندیسهای ثانویه …
ایندکس معکوس (inverted index) چیست؟
در قسمت های قبل روشهای شاخص گذاری بر روی داده ها را بررسی نمودیم. اکنون …
2 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

مقاله خیلی کامل و خوبی بود به من در فهم بیشتر ایندکس ها کمک زیادی کرد
ممنون