 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
فرمت فایل های کلان داده Kudu، Parquet ،Avro و ORC
هدوپ مانند هر سیستم فایل استاندارد، به شما امکان می دهد اطلاعات را در هر قالبی، چه داده های ساختار یافته، نیمه ساختاریافته یا بدون ساختار ذخیره کنید. علاوه براین از فرمت های بهینه برای ذخیره سازی و پردازش در HDFS نیز پشتیبانی می کند. برای ذخیره و پردازش داده ها در هدوپ، انتخاب های زیادی دارید که می توانید بسته به نیازتان از آنها استفاده کنید. در حقیقت هدوپ فرمت فایل پیشفرضی ندارد و انتخاب فرمت مناسب فایل بستگی به استفاده شما دارد. داده ها ممکن است در فرمتی قابل خواندن برای ما مانند JSON ،XML یا به صورت فایل CSV باشند، اما این بدان معنا نیست که این بهترین راه برای ذخیره واقعی داده ها در هدوپ است.
عناوين مطالب: '
فرمت فایل های کلان داده
رایجترین این نوع از فایلها، فایلهای CSV یا فایلهایی هستند که دادههای یک رکورد را درون یک خط به گونهای ذخیره میکنند که بین هر فیلد یک ویرگول (یا یک جداکننده استانداراد) قرار گیرد.
ذخیره متنی دادهها درون فایلها، حتی با وجود ایجاد ساختارهای درختی و پوشه بندی درست درون HDFS، یافتن یک داده خاص یا جستجوی موردی را زمان بر میکند چون هیچ گونه ایندکسی روی دادهها نداریم و باید تک تک رکوردها برای یافتن یک داده خاص جستجو شوند. برای حل مشکل سرعت جستجوی یک داده خاص یا پرس و جوهای موردی (Ad-Hoc)، معمولاً سراغ بانکهای اطلاعاتی توزیع شده و ستون گرا مانند HBase و کاساندرا میرویم. این کار، پردازش انبوه دادهها را تحت الشعاع قرار میدهد و استخراج اطلاعات تحلیلی مانند میانگین فروش ماهیانه و هفتگی، تعداد ویزیتها، سفارشها و کنسلیهای یک محصول، با این دیتابیسها به دلیل ساختار خاص مدلسازی دادهها در آنها، به سرعت امکان پذیر نیست.
مشکل دیگری که ذخیره داده ها در فایل های متنی دارد، حجم بالاییست که آنها اشغال می کنند و اگر بتوان آنها را به نحوی فشرده کرد، حجم عظیمی از دیسک، صرفه جویی خواهد شد. البته منظور ما فشرده سازی معمول متن (که آنهم البته مفید است اما بار اضافی بر دوش استفاده کنندگان از سیستم می گذارد که برای هر کاری، ابتدا باید داده ها را از حالت زیپ خارج کنند و سپس آنها را پردازش کنند) نیست بلکه فشرده سازی بر اساس نوع داده های ذخیره شده است مثلاً اگر بدانیم فیلد دوم داده ها یک فیلد عددیست آنرا به صورت باینری ذخیره می کنیم و اگر بدانیم یک فیلد متنی مانند نام محصول است، از کدگذاریهای بهینه متن برای ذخیره آن استفاده خواهیم کرد.
در واقع ذخیره داده ها به صورت متنی در فرمت JSON یاCSV بسیار ناکارآمد است زیرا این فرمت های فایل را نمی توان به صورت موازی ذخیره کرد و همچنین جستجوی فیلد خاص را زمانبر می کند به دلیل اینکه هیچگونه ایندکسی روی داده ها وجود ندارد و باید تک تک رکوردها برای یافتن یک داده خاص جستجو شوند. علاوه براین اینگونه فایل ها حجم بالایی را اشغال می کنند؛ بنابراین اگر بتوان فایل را به نحوی فشرده کرد، حجم زیادی از دیسک صرفه جویی می شود.
دراین راستا فرمت فایل های بهینه ای برای کار با کلان داده توسعه یافته است که عبارتند از:
- فرمت Avro
- فرمت Parquet
- فرمت Optimized Row Columnar) ORC)


باتوجه به اینکه این فرمتهای فایل شباهتهایی با هم دارند، اما هر یک از آنها منحصر به فرد می باشند و ویژگی های خاص خود را دارند. این ویژگی ها عبارتند از:
1. هر سه فرمت برای ذخیره سازی در هدوپ بهینه شده اند و درجاتی از فشرده سازی را ارائه می دهند.
2. برخلاف فرمت فایل CSV یا JSON که قابل خواندن برای ما هستند، سه فرمت مذکور، فرمتهای باینری قابل خواندن توسط ماشین هستند.
3. فایلهای ذخیره شده در فرمتهای Parquet ،Avro و ORC را میتوان در چندین دیسک تقسیم کرد که به مقیاسپذیری و پردازش موازی کمک میکند، درحالیکه فایل های CSV یا JSON این قابلیت را ندارند.
4. هر سه فرمت خود توصیفی(Self-Describing) هستند. به این معنی است که شمای داده را در فایلهای خود دارند. یعنی شما می توانید از یک فایل Parquet ،Avro یا ORC که در یک کلاستر است، استفاده کنید و آن را در سیستم دیگری بارگذاری کنید. در این شرایط سیستم، داده ها را تشخیص داده و قادر به پردازش آنها خواهد بود.
5. بزرگترین تفاوت بین Parquet ،Avro و ORC در نحوه ذخیره داده ها است. Parquet و ORC هر دو داده ها را به صورت ستونی (Column-Base) ذخیره می کنند، درحالیکه Avroداده ها را در فرمت ردیفی (Row-Base) ذخیره می کند.
در یک فرمت ستونی، مقادیر هر ستون از همان نوع در رکوردها با هم ذخیره می شوند. این فرمت ذخیره سازی زمانی مفید است که شما نیاز به پرس و جوی چند ستون از یک جدول دارید. در این صورت فقط ستون های مورد نیاز که در مجاور یکدیگر هستند، خوانده می شوند.
در مثال بالا فرض کنید فقط ستون Name را میخواهیم. در این صورت در فرمت ذخیره سازی ردیفی، هر رکورد در مجموعه داده باید بارگیری شود و فیلدها بررسی شوند تا داده ها برای فیلد Name استخراج شوند. اما فرمت ذخیره سازی ستونی می تواند مستقیماً به ستون Name برود زیرا همه مقادیر آن ستون با هم ذخیره می شوند و نیازی به بررسی کل رکوردها نمی باشد؛ بنابراین فرمت ذخیره سازی ستونی سرعت جستجو را افزایش می دهد زیرا زمان کمتری برای رفتن به ستون های مورد نیاز لازم دارد. علاوه برآن فرمت ستونی زمان مراجعه به دیسک را کاهش می دهد به دلیل اینکه فقط باید ستون هایی را بخواند که داده های آنها مورد نیاز است.
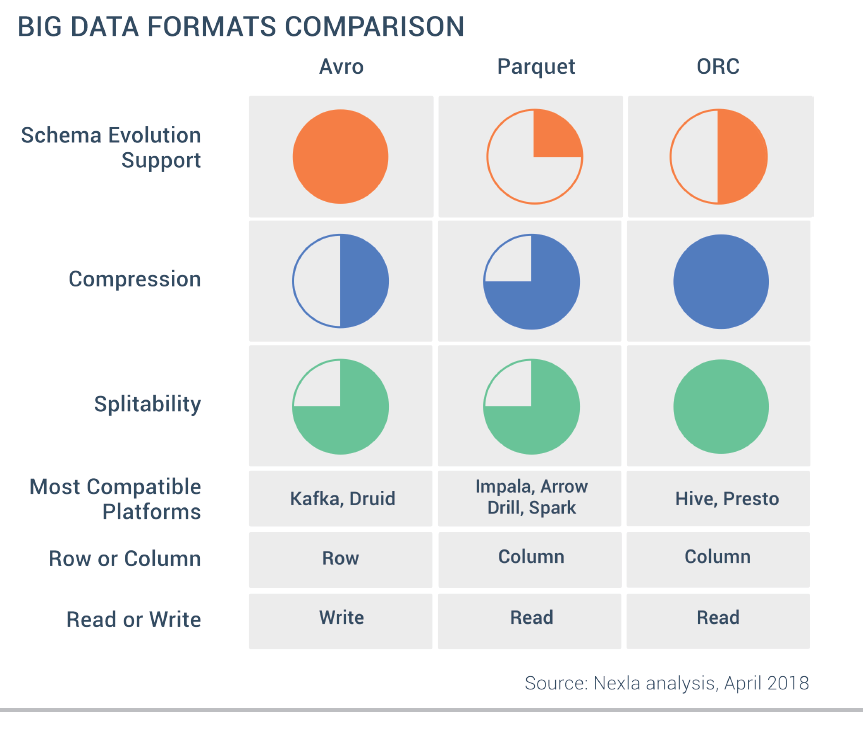
فرمت فایل Avro:
- یک فرمت ذخیره سازی ردیفی که قادر به فشرده سازی داده ها به طور کارآمد می باشد.
- فرمت Avro یک پروتکل ذخیره باینری داده هاست که خدمات سریال سازی (Data Serialization) و انتقال داده را ارائه می دهد.
- داده ها را در فرمت JSON ذخیره می کند تا داده ها به راحتی خوانده و تفسیر شوند.
- یکی از ویژگی های کلیدی فرمت Avro پشتیبانی قوی از شمای(schema) داده است که در طول زمان تغییر می کند. Avro تغییرات شمای داده مانند فیلدهای از دست رفته، فیلدهای اضافه شده و فیلدهای تغییر یافته را کنترل می کند.
- این فرمت فایل قابلیت انعطاف پذیری بالایی دارد اما در مقایسه با فرمت های فایل ستونی، میزان فشرده سازی آن کمتر است.
- به دلیل فرمت ذخیره سازی ردیفی آن برای جستجوی سریع در فایل، بهینه نمی باشد.
- با این حال اگر قصد دارید داده های خود را به صورت JSON در هدوپ ذخیره کنید که بعدها به راحتی بتوانید داده ها را تغییر دهید، Avro برای این کار مناسب است.
فرمت فایل Parquet:
- این فرمت فایل توسط کلودرا و توییتر در سال 2013 ایجاد شد.
- از ویژگی های منحصر به فرد Parquet این است که می تواند داده ها را با ساختارهای تو در تو به صورت ستونی ذخیره کند. با این وجود فیلدهای تودرتو را می توان به صورت جداگانه و بدون خواندن تمام فیلدهای ساختار تودرتو خواند.
- این فرمت برای کار با حجم عظیمی از داده های پیچیده مناسب است و گزینه های فشرده سازی و رمزگذاری(Encoding) داده های مختلفی را ارائه می دهد.
- این فرمت فایل برای خواندن ستونهای خاص از جداول بزرگ بسیار مفید است، زیرا تنها میتواند ستونهای مورد نیاز را به جای کل جدول بخواند. این امر منجر به پردازش سریعتر دادهها میشود و زمان مراجعه به I/O را کاهش می دهد.
- قابلیت ذخیره سازی ستونی موجب می شود، داده های غیر مرتبط را به سرعت در حین پرس و جو فیلتر کند.
- کدکهای مختلفی برای فشردهسازی دادهها وجود دارد و فایلهای داده میتوانند انواع فشردهسازی متفاوتی داشته باشند.
فرمت فایل ORC:
- این فرمت برای خواندن، نوشتن و پردازش داده ها در Hive بهینه شده است و توسط Hortonworks در سال 2013 برای افزایش سرعت Hive ایجاد شد.
- فرمت فایل ORC مجموعهای از ردیفها را در یک فایل ذخیره میکند به این صورت که هر ردیف از داده فرمت ستونی دارد.
- دادهها را به صورت فشرده ذخیره میکند و امکان پرش از قسمتهای غیر مرتبط را بدون نیاز به ایندکسگذارهای پیچیده یا دستی فراهم میآورد.
- از انوع داده اعشاری، تاریخ و انواع پیچیده (struct ،list ،map و union) پشتیبانی میکند.
- قابلیت خواندن همزمان از یک فایل با استفاده از RecordReaderهای جداگانه را ممکن می سازد.
به طورکلی در فرمت فایل های ستونی، سرعت خواندن داده ها بالا است؛ بنابراین برای کارهای تحلیلی مناسب می باشند، در حالی که در فرمت فایل های ردیفی، سرعت نوشتن داده ها زیاد است؛ بنابراین برای کارهای تراکنش سنگین نوشتن مناسب می باشند.
در پردازش های انبوه و همچنین هنگام نیاز به تحلیل های آماری داده ها، معمولاً به یک فیلد خواص از داده ها نیاز داریم به عنوان مثال اگر یک شرکت بزرگ با یک میلیون کارمند را در نظر بگیرید که در آن مدیر اجرایی می خواهد حقوق پرداختی به کارمندان را به تفکیک هر مکان جستجو کند، در این صورت اگر مجموعه دادههای حقوق و موقعیت مکانی به صورت ستونی ذخیره شوند، به یک پرس و جو نسبتاً ساده نیاز است که فقط باید دادههای آن دو ستون واکشی شوند. اما اگر این کار به صورت ردیفی انجام شود، باید میلیونها ردیف واکشی شود و عملیات را روی هر یک از ردیفها انجام داد.
با این حال در شرایطی که میخواهید روی تعداد کمی از ستونها از کل مجموعه دادههای خود تحلیل کنید، فرمت ستونی در مقایسه با فرمت های مبتنی بر ردیف بسیار بهتر است.
حال فرض کنید می خواهید پروازهای هواپیمایی موجود را در یک صفحه وب به کاربر نمایش دهید. در این صورت بهتر است از فرمت ذخیره سازی ردیفی استفاده کنید، زیرا میخواهید اطلاعات زیادی در مورد هر ورودی خاص دریافت کنید. به طور مثال تمام اطلاعات پرواز از ساعت 9 صبح تا ساعت 1 بعد از ظهر امروز.
معرفی Apache Kudu
آپاچی Kudu یک موتور ذخیره سازی منبع باز است که تحت نظارت بنیاد نرم افزار آپاچی اداره می شود. این فناوری برای پر کردن شکاف بین سیستمهای ذخیرهسازی با دسترسی متوالی با توان عملیاتی بالا مانند HDFS و سیستمهای دسترسی تصادفی با تاخیر کم مانند HBase یا Cassandra طراحی و اجرا شده است.
آپاچی Kudu به گونه ای طراحی شده که با اکوسیستم هدوپ سازگار است و با سایر چارچوب های پردازش داده مانند Spark، Impala و MapReduce به راحتی ادغام می شود.
آپاچی Kudu از نقاط مثبت HBase و Parquet استفاده می کند. در دریافت داده ها به همان سرعت HBase است و وقتی صحبت از پرس و جوهای تحلیلی به میان می آید تقریباً به سرعت Parquet است.
این موتور ذخیره سازی برای کار با داده های ساخت یافته در نظر گرفته شده است که از دسترسی تصادفی داده ها با تاخیر کم پشتیبانی می کند.
در Kudu داده ها به صورت جدولی با شمای مشخصی ذخیره می شوند. در واقع مدل داده در Kudu، مدل رابطهای است. این فناوری به کاربران اجازه میدهد تا دادهها را به همان روشی که در یک پایگاه داده رابطهای دستکاری می کنند مانند درج، بهروزرسانی و حذف داده ها، عمل کنند. علاوه بر این جستجوی سریع داده ها را امکان پذیر می کند به همین خاطر بیشتر برای کارهای تحلیلی مورد استفاده قرار می گیرد.
معماری شبکه Kudu:
- همانند مدلهای سنتی پایگاه داده رابطهای، در Kudu نیز هر جدول از تعدادی سطر تشکیل شده است که هر سطر یک کلید دستیابی منحصر به فرد دارد. ستون ها نیز نوع داده مشخصی دارند. یک جدول با کلید اصلی به بخش هایی به نام تبلت (Tablet) تقسیم می شود.
- هر Tablet یک بخش پیوسته از یک جدول است که برای انعطاف پذیری بیشتر بر روی چندین Tablet Server تکثیر می شود. در حقیقت واحد توزیع و بازیابی داده ها درTablet ،Kudu می باشد.
- در معماری Kudu یکی از نسخه ها به عنوان Leader Tablet در نظر گرفته می شود. عملیات خواندن و نوشتن داده ها توسط Leader Tablet ها انجام میشود اما نسخه های دیگر فقط میتوانند عملیات خواندن داده ها را انجام دهند.
- هرTablet Server وظیفه ذخیره و بازیابی Tabletها را بر عهده دارد. در واقع یک Tablet Server میتواند چندین Tablet را ارائه کند و یک Tabletمیتواند توسط چندین Tablet Server ارائه شود.
- فرآیند Master وظیفه هماهنگی بین Tablet Server ها و مباحث تحمل خطا را برعهده دارد و تمام Tablet ها، Tablet Serverها، جداول و سایر موارد را کنترل و مدیریت می کند.
به طور کلی برای اینکه داده ها همیشه در دسترس باشند، Kudu از الگوریتم Raft Consensus برای تکرار عملیات استفاده می کند. این الگوریتم تضمین می کند که هیچ داده ای به دلیل خرابی دستگاه از بین نمی رود؛ بنابراین وقتی ماشینی از کار میافتد، کپیها در عرض چند ثانیه خود را مجدداً پیکربندی میکنند تا دسترسی پذیری داده ها حفظ شود.
داده ها در Kudu به صورت ستونی (Columnar) ذخیره می شوند. ذخیره سازی ستونی امکان رمزگذاری و فشرده سازی هر یک از ستون ها را به صورت کارآمد فراهم می کند. علاوه بر این عمل جستجو بر اساس مقادیر یک ستون می تواند با سرعت بسیار بالایی انجام شود و همچنین مدل ذخیره سازی ستونی به طور چشمگیری زمان مراجعه به دیسک را برای پرس و جوهای تحلیلی کاهش می دهد.
به طور کلی Kudu برای انجام عملیات سریع در خواندن/نوشتن، دسترسی انبوه و تصادفی ایجاد شده است و سازگاری آن با موتورهای استاندارد SQL، استفاده از آن را به همراه بقیه اکوسیستم هدوپ آسان می کند.
منابع:
https://virgool.io/@saharahsani/%D9%85%D8%B9%D8%B1%D9%81%DB%8C-apache-kudu-cssl2tmcu7xz
https://virgool.io/@saharahsani/%D9%81%D8%B1%D9%85%D8%AA-%D9%87%D8%A7%DB%8C-%D9%81%D8%A7%DB%8C%D9%84-%D8%AF%D8%B1-%D9%87%D8%AF%D9%88%D9%BE-parquet-avro-%D9%88-orc-osyxt2dxxvdx
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 459
برچسبAVRO Kudu ORC Parquet فرمت فایل فرمت های فایل
نوشته های مرتبط













همچنین ببینید

محصولات و تکنولوژی های آپاچی (Apache) در حوزه کلان داده و داده کاوی
یکی از موسسات مطرح در زمینه پشتیبانی از داده های حجیم، بنیاد آپاچی می باشد. …
