 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
نقش ریشه یاب (Stemmer) در تحلیل متن و پردازش زبان و تفاوت آن با lemmatizer
در این مبحث مولفه ریشه یاب (Stemmer) در فرایند پردازش متن تشریح میگردند. ریشه یابی عبارت است از حذف پس وندها و پیش وند های کلمات و استخراج ریشه آن ها.
عناوين مطالب: '
ریشه یاب (Stemmer) چیست؟
در هر زبان، واژهها با توجه به نقش معنایی و نحوی خود در جلمه به شکلهای ظاهری متفاوتی حضور مییابند، این شکل ظاهری متفاوت از جهتی نشاندهنده معنای متفاوت این واژههاست، اما با توجه به این که تمامی آنها از یک ریشه مشتق شدهاند، از نظر معنا قرابت نسبتا زیادی خواهند داشت. ازهمین رو در بسیاری از کاربردهای پردازش زبان طبیعی و بازیابی اطلاعات، نیاز داریم تا همه مشتقات یک واژه را به ریشهی آن، که همان شکل ساده واژه میباشد، تبدیل نماییم. ریشه یابی کلمات در سیستم های بازیابی اطلاعات یک امر ناگزیر است.
فرایند پروسه ریشه یابی کلمات
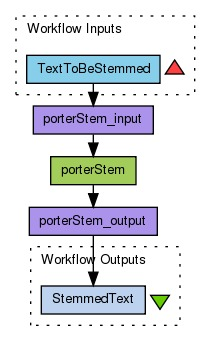
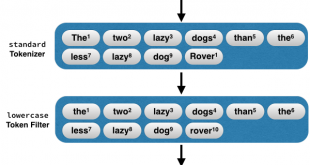
پروسه ریشه یابی کلمات را به صورت عبارت پایه آن در می آورد. برای مثال، کلمه “روش هایم”، “روشی” و “روشمند” هر سه از ریشه روش هستند. روش های ریشه یابی اغلب مبتنی بر زبان هستند. ریشه یابی بعد مرحه جداساز انجام میشود که در مبحث نقش واحدساز (Tokenizer) در پردازش متن به آن اشاه شد. شکل زیر مراحل پردازش و تحلیل متن را به صورت ساده نشان میدهد. این ابزار براي ریشه یابی لغات و تشخیص نوع کلمه ساخته شده از آن ریشه (اسم مکان، اسم زمان، حالت فاعلی، مفعولی و …) استفاده میشود.

روش های ریشه یابی کلمات
ریشه یابی اصطلاحی است که برای تعریف فرآیند کاهش دادن یک کلمه و رسیدن به ریشه آن به کار میرود. منظور از ریشه در این تعریف، ریشه زبانی نیست و هدف این است که فرمت های گوناگون یک کلمه دارای ریشه های یکسان باشند. معمولاً ریشه یابی لغات بر اساس قواعد ساخت واژهای و سپس حذف پسوندها میباشد. تاکنون روش مؤثری برای حذف پیشوندها ارائه نشده است. در تلاشی که در آزمایشگاه فناوری وب انجام شده است، سعی شده تا بر اساس آنالیزهای آماری و داده کاوی پسوندها حذف گردند، که این روش هم می تواند راهی برای تشخیص ریشه باشد. معروفترین الگوریتم ریشه یابی در انگلیسی porter می باشد. برای ریشهیابی به برچسب کلمات نیازی نیست بنابراین برای این مؤلفه برچسبگذاری استفاده نمی شود. معمولا در تحلیل متون از ریشهیاب Snowball استفاده م شود، این ریشهیاب در سیستمهای متن کاوی انگلیسی مختلف و معتبر چون “Gate” و “Statistica” استفاده شدهاست.
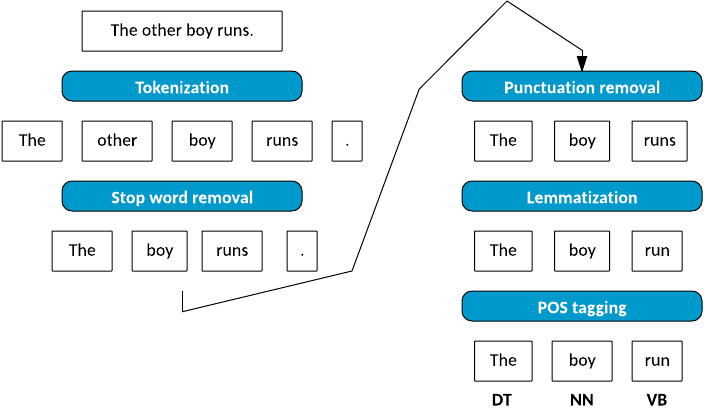
فرق stemmer با lemmatizer
نکته: بنواژهسازی(Lemmatizer) با ریشهیابی متفاوت است. بنواژهسازی عمل حذف وندهای تصریفی از کلمه است ولی در ریشهیابی علاوه بر حذف وندهای تصریفی وندهای اشتقاقی نیز از کلمه حذف میشود. فرآیند Lemmatizing وقت گیر و حرفه ای تر است و نیاز به پردازش های دیگری مانند POS Tagging هم دارد که نقش کلمه در جمله را ابتدا معین کند. در عمل ریشه یاب (Stemmer) به تک واژه ها نگاه می شود و به کلمات اطراف آن لغت، اهمیتی داده نمیشود ولی در Lemmatizing ما بر اساس نوع کلمه و بستری که یک کلمه در آن به کار رفته است به ریشه یابی یک کلمه مبادرت می ورزیم.
به عبارتی دیگر استمینگ فرآیندی است که چند کاراکتر آخر یک کلمه را منشا میگیرد یا حذف میکند، که اغلب منجر به معانی و املای نادرست میشود. Lemmatization، زمینه را در نظر می گیرد و کلمه را به شکل پایه معنی دار خود تبدیل می کند که به آن Lemma می گویند. به مثال زیر توجه کنید

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 4278
برچسبStemmer استمر پردازش زبان طبیعی پردازش متن تحلیل متن ریشه یاب یا استمر ریشه یاب ریشه یاب (Stemmer) ریشه یابی متن کاوی نقش ریشه یاب (Stemmer) در تحلیل متن
نوشته های مرتبط












همچنین ببینید
مجموعه داده اسامی مکان برای تشخیص موجودیت های مکانی در پردازش زبان طبیعی
عناوين مطالب: 'مقدمه ای بر اسامی مکان:کاربردهای (Named-entity recognition) NERروشهای تشخیص اسم مکاندانلود دیتاست اسامی …

دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار …
