 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
نقش برچسب گذار (POS tagger) در پردازش متن
یکی از بخش های کلیدی در پردازش متن تعیین نقش کلمه در جمله است. در واقع با ابزار برچسب گذار (POS tagger) نقش کلمه از نظر فعل، فاعل، نوع اسم و غیره مشخص میشود. برچسبگذاری در پردازش زبان بعد از بخش های واحدساز و ریشه یاب و حذف پسوندهای خاص قرار میگیرد. برای بنواژهسازی کلمات فارسی اگر برچسب واژگانی کلمه (مواردی از قبیل اسم، صفت و فعل) از قبل مشخص باشد دقت بسیار افزایش مییابد. برچسب گذاری واژگانی عملی اساسی برای بسیاری از حوزه های دیگر پردازش زبان طبیعی (NLP) از قبیل ترجمه ماشینی، خطایاب و تبدیل متن به گفتار می باشد. در فرایند متن کاوی برچسبگذاری، بعد مراحلی مثل تشخیص زبان، واحدساز و ریشه یابی کلمات انجام می گیرد. در شکل زیر به مراحل ذکر شده توجه کنید.
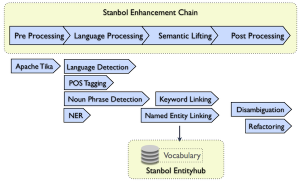
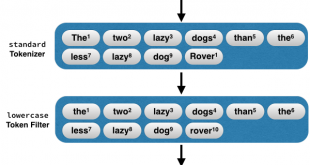
برچسب گذار (POS tagger) اجزاي کلام، عمل انتساب برچسبهاي واژگاني به کلمات و نشانههاي تشکيل دهنده متن را به صورتي که اين برچسبها نشاندهنده نقش کلمات و نشانهها در جلمه باشد، انجام می دهد. برچسبگذارهاي اجزاي واژگاني کلام و پيکرههاي برچسب خورده با اين برچسبها در بسياري از حوزههاي ديگر پردازش زبان طبيعي مورد استفاده قرار ميگيرند که از بين آنها ميتوان به تبديل متن به گفتار، سيستمهاي تشخيص خودکار گفتار، خطاياب و ترجمه ماشيني اشاره کرد. از نمونه های انگلیسی آن میتوان به Illinois Part Of Speech Tagger و Stanford POS Tagger اشاره کرد. در شکل های زیر مراحل کار را ببینید متن اولیه که به عنوان ورودی به pos tagger داده شده و سپس با توجه به کلید برچسب گذاری شده است.



در سالهای اخیر، کارهای زیادی در زمینه برچسبگذاری متون فارسی انجام شده است. در سال 2000، عاصی و عبدالحسینی [2] یکی از اولین برچسبگذارهای ادات سخن برای زبان فارسی را تولید کردند. این برچسبگذار که بر اساس سیستم عامل Dos نوشته است، قادر است برچسبهای مختلفی از عدد، فعل و اسم را با دقتی بین 69 تا 83 درصد بهدرستی مشخص نماید. در سری کارهای انجام شده در این زمینه، در سال 2004، بی جن خان[1]پیکرهای با بیش از 2.6 میلیون کلمه برچسب خورده را برای این کار فراهم نمود. این پیکره دارای 40 برچسب متفاوت است و برچسبگذارهای مختلفی نیز بر روی آن ارائه شده است. یکی از برچسبگذارهای شکل گرفته بر اساس این پیکره، توسط امیری و همکارانش در سال 2007 ارائه شده است. نتایج آزمایشهای این مقاله در بهترین حالت، دقت 93.16% را نشان داده است[3].
تا کنون مدل ها و روش های زیادی برای برچسب گذار (POS tagger) در زبان های مختلف استفاده شده است. روش های آماری که از پیکره های برچسب خورده(tagged corpora) باستفاده میکنند و روش های غیر آماری و مبتنی بر قانون (Rule) که خود بر دودسته هستند. (1)یادگیری ماشینی (Machine Learning) و (2)دانش بشری (Human Knowledge). بعضی از این روش ها عبارتند از:بعضی از این روش ها عبارتند از:
- مدل مخفی مارکوف (Markov Hidden Model)
استفاده از مدل مخفی مارکوف جهت برچسبگذاری گونههای کلام را میتوان به عنوان یک برداشت از تئوریهای احتمالی دانست. این فرآیند به شرحی که در ادامه میآید، اجراء میگردد: سؤال این است که برای یک رشته از کلمات گرفته شده، چه ترتیب برچسبی بهترین ترتیب برچسب برای آن رشته کلمات است؟ اگر ما متن ورودی را (ترتیبی از واحدهای صرفی در کار ما) به صورت نمایش دهیم و یک ترتیب از برچسبهای مجموعه برچسب را با مشخص کنیم، هدف ما این است که محتملترین دنباله برچسبها را به ازای متن ورودی محاسبه کنیم. این فرایند، به معنای یافتن Tای است که P(T|W) را بیشینه نماید. احتمال رخداد ترتیب برچسبها و احتمالهای مربوط به رخداد کلمهها نشاندهنده پارامترهای مدل مخفی مارکوف هستند؛ یعنی احتمالهای انتقال و صدور (مشاهده) در این مدل. برای یک بار تمامی پارامترها (احتمالهای یک گرمی، دو گرمی و سه گرمی) مقدار میگیرند و سپس به کمک مدل مخفی مارکوف میتوان بهترین ترتیب برچسبها را برای ترتیب کلماتگرفته شده محاسبه کرد.
- برچسب گذاری مبتنی بر تبدیل یا قانون (Transformation/Rule -based tagger)
- سیستم های مبتنی بر حافظه (Memory-basedSystem
- سیستم های ماکزیمم آنتروپی (Maximum Entropy System)
در شکل زیر یک دسته بندی دیگر از روش های برچسب گذاری را مشاهده میکنید.

آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 4371
برچسبPOS tagging برچسب گذار (POS tagger) برچسب گذار اجزای کلام برچسب گذار متن تحلیل متن متن کاوی
نوشته های مرتبط












همچنین ببینید

دانلود مجموعه داده اخبار با طبقه بندی موضوعی (classification)
به منظور استفاده دانشجوبان عزیز در انجام پایان نامه حدود بیست هراز مجموعه داده اخبار …

