 خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
روش هاي تشخيص زبان در متن
تشخیص زبان یک متن، یکی از اولین گام ها به سوی متن کاوی است. مخصوصا در فضای بزرگ سایبر که تنوع بسیار زیادی از داده ها وجود دارد. حتی ممکن است گاهی در اسناد سازمانی هم با تنوع متفاوتی از زبان ها در اسناد مواجه شویم. در بیشتر موارد مخصوصا اگر رنج تنوع زبان ها در متون زیاد باشد، حتی قبل از تجزیه کردن (Pars) و ایندکس کردن فایل های متنی ترجیح داده میشود که با یکی از روش هاي تشخيص زبان در متون، نوع زبان شناسایی شود. چرا که از هزینه پارس کردن بی مورد متون که برابر با زبان مورد نظر ما نیست جلوگیری شود. تا کنون ایده های مختلفی برای تشخيص زبان در متن ارائه شده. که در این مبحث دو مورد از روش هاي تشخيص زبان مورد بررسی قرار میگیرد.
- روش شناسايي الگوی زبان بر اساس شباهت ها
- روش اکتشاف از روی عناصر داخل فایل متنی یا از متا دیتا ها
روش شناسايي الگوی زبان بر اساس شباهت ها
از دیگر روش هاي تشخيص زبان میتوان به روش های شناسایی الگو اشاره نمود. در اين روش براي تشخيص زبان صفحات وب، متن موجود در آنها مورد تحليل قرار ميگيرد. روند کلي روشهاي موجود در اين حوزه به اين ترتيب است که ابتدا با استفاده از مجموعهاي از متون متعلق به يک زبان خاص يک مدل بازنمايي از آن زبان ساخته ميشود و اين کار به ازاي مجموعه زبانهايي که سيستم قصد تشخيص آنها را دارد، تکرار ميشود. مشابه با پردازش صورت گرفته بر سندهاي موجود در مجموعه دادهها، پردازشي بر روي هر سند HTML ورودي به سيستم که قصد تشخيص زبان آن را داريم، انجام ميگيرد و يک بازنمايي از سند جاري به دست ميآيد. بر اساس يک معيار شباهت، ميزان تشابه بازنماييهاي زبانهاي موجود با بازنمايي سند جاري محاسبه ميشود. زباني که بيشترين تشابه را با بازنمايي سند جاري داشته باشد و مقدار آن از يک آستانهي از پيش تعيين شده بيشتر باشد، به عنوان زبان سند در نظر گرفته ميشود.
به عنوان نمونه بازنمايي زبانها و سندهاي HTML ورودي ميتواند با استفاده از مدل فضاي بردار VSM یا ( Vector Space Model) انجام شود. اين فضا نيز ميتواند بر اساس مجموعهاي از کلمات کوچک و پرتکرار يک زبان، پسوندها، پيشوندها و يا مجموعهاي از n-gramهاي پرتکرار يک زبان شکل بگيرد. هر يک از کلمات، پسوندها، پيشوندها يا n-gramها يکي از ابعاد فضاي ويژگي را تشکيل ميدهند. استفاده از کلمات کوچک به عنوان ابعاد فضاي ويژگي ميتواند براي تشخيص زبان صفحات بزرگ مورد استفاده قرار گيرد. مقدار هر يک از ابعاد نيز ميتواند بر اساس بسامد ويژگي متناظر با آن بعد در بردار بازنمايي زبان يا سند تعيين گردد.
ميزان شباهت بردار بازنمايي يک سند با بردار بازنمايي هر يک از زبانها ميتواند با استفاده از معيار شباهت کسينوس، فاصله اقليدسي يا هر معيار فاصلهي ديگري محاسبه شود. در ادامه روشي را تشريح ميکنيم که بسياري از ابزارها براي شناسايي زبان متون از آن استفاده نمودهاند.
-
TextCat:دستهبندي متون مبتني برn-gramها
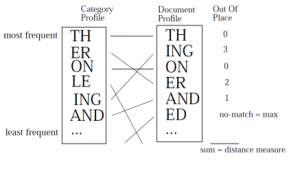
روش ارائه شده که TextCat نام دارد، از مجموعهاي از n-gramها که بيشترين بسامد را در مجموعهاي از متون متعلق به يک زبان داشتهاند، براي بازنمايي يک زبان استفاده ميکند. براي شناسايي زبان هر متن وارد شده به سيستم ابتدا مجموعه n-gramهاي پربسامد آن استخراج ميشود سپس با استفاده از روش سادهاي به نام «خارج از جايگاه» (Out-of-place) فاصله بين بازنمايي زبانها و بازنمايي متن ورودي محاسبه ميشود. اين روش ابتدا n-gramهاي زبان و متن را بر اساس بسامدشان مرتب ميکند. سپس جايگاه هر يک از n-gramها را در زبان و سند با هم مقايسه و اختلاف آنها را محاسبه مينمايد. اگر n-gramي در يکي از بازنماييها وجود داشته باشد و در ديگري واقع نشده باشد، حداکثر اختلاف فاصله براي اين n-gram منظور ميشود.

شکل پایین مثالي از محاسبه فاصله n-gramها براي بازنمايي يک زبان با بازنمايي يک سند را نشان ميدهد. مثلا ING در بازنمايي زبان در جايگاه پنجم و در بازنمايي سند ورودي در جايگاه دوم قرار گرفته است بنابر اين فاصلهي «خارج از جايگاه» آن برابر با 3 خواهد بود.
در استفاده از n-gramها بايد نکاتي را مد نظر قرار داد. مثلاً زبانهايي نظير فارسي، عربي و اردو داراي n-gramهاي شبيه به يکديگر هستند که عدم توجه به اين موضوع، مي تواند منجر به تشخيص نادرست زبان يک واحد اطلاعاتي گردد. نحوه کدگذاري صفحه نيز در تشخيص زبان بر اساس n-gram اهميت دارد. زيرا مثلاً اگر UTF-8 به عنوان Arabic در نظر گرفته شود، تشخيص زبان به کمک n-gram صحيح نخواهد بود.
اکتشاف از روی عناصر داخل فایل متنی یا از متا دیتا ها از روش هاي تشخيص زبان
در اين تکنیک از روش هاي تشخيص زبان سعي ميشود با استفاده از اطلاعات موجود در صفتهاي برچسبهاي (tag) يک سند مثلا یک صفحه وب زبان آن شناسايي شود. برچسبهايي مانند meta با صفتهايي نظير
- http-equiv=”Content-Language”
- name=”dc.language”
- name=”Content-Language”
در شناسايي زبان قابل استفاده هستند. در استفاده از اين برچسبها بايد به نکاتي توجه داشت:
- ممکن است زبان صفحه متفاوت از زبان مشخص شده در برچسبها باشد. اين در مورد صفحاتي غير انگليسي امري رايج است.
- ممکن است صفحه چند زبانه باشد.
در ذيل مثالهايي از برچسبهاي HTML که مي توانند براي شناسايي زبان استفاده شوند، آورده شده است:
- <meta http-equiv=”Content-Language” content=”en” />
- <meta name=”dc.language” content=”en” />
- <meta name=”dc.language” content=”de, fr, it” />
صفت هاي ديگري lang نيز در تشخيص زبان قابل استفاده هستند. در زمان استفاده از برچسبهاي HTML بايد به نکات گوناگوني توجه داشت. يکي ديگر از نکات اين است که زبان صفحه در برچسبهاي HTML به شکلهاي گوناگوني ظاهر ميشود. مثلاً براي زبان فارسي از نامهاي «Persian» يا «per» استفاده ميشود. اين در حالي است که نمايش استاندارد زبان فارسي طبق کنسرسيوم وب به صورت «fa» است.
يکي ديگر از نکات اين است که از طريق CSS و DOCTYPE نميتوان زبان را صفحه را تشخيص داد. زيرا مثلاً در DOCTYPE زبان مشخص شده مرتبط با محتواي صفحه نيست و به شماي صفحه ارتباط دارد.
روش هاي تشخيص زبان فارسی
ابزارهای متنوعی و بسیاری برای تشخیص زبان متن وجود دارند، اما این تعداد کمی از این ابزارها قادر به تشخیص زبان فارسی هستند. ابزار كد باز تشخيصگر زبان متن Langdetect قادر به تشخیص 52 زبان از جمله فارسي، عربی، اردو، روسی و انگلیسی میباشد. اساس كار اين ابزار شكست كلمات بر اساس N-gram با سه مقدار متفاوت يك ، دو و سه gram است، سپس برای هر یک از شکستها ترکیبات مختلف حروف را درنظر گرفته و فرکانس پراکندگی آن ترکیب را در متن مورد نظر محاسبه میکند و يك هيستوگرام تهيه ميكند سپس با مقایسهی این فرکانسها با هيستوگرامهاي اصلي (كه براي هر زبان هیستوگرامهای اصلی قبلاً از روی پیکرههای زبانی ساخته شدهاست، پیکرهی مورد استفاده در این ابزار سایت Wikipedia است)، زبان هر متن تشخیص داده میشود. دقت این ابزار برای زبان فارسی با استفاده از پیکرهی همشهری 0.9997% محاسبه شده است. تعداد حداقل کلمهی لازم برای تشخیص صحیح زبان یک متن در انگلیسی 5 کلمه و در فارسی حدود 8 کلمه برآورد شده است.
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 3734
برچسبLanguage Detection n-gram NLP پردازش زبان طبیعی تحلیل متن تشخيص زبان تشخيص زبان در متن تشخيص زبان متون روش هاي تشخيص زبان روش هاي تشخيص زبان در متن متن کاوی
نوشته های مرتبط













همچنین ببینید

مجموعه داده وسایل و تجهیزات (appliances) جهت متن کاوی
برای تشخیص اینکه یک کلمه اسم است، راه های مختلفی وجود دارد که از جمله …

آشنایی با پردازش زبان طبیعی استنفورد (Stanford CoreNLP)
Stanford CoreNLP مجموعه ای از ابزارهای آنالیز زبان طبیعی را فراهم می آورد. این نرم …
2 دیدگاه
دیدگاهتان را بنویسید
برای نوشتن دیدگاه باید وارد بشوید.

سلام
از ان-گرم استفاده کردم اما روش خارج از جایگاه برای خیلی از زبانهاجواب نداد، از روش دیگهای استفاده کردم. الان زبان پرتغالی و پرتغالی برزیلی رو هم با اون همه شباهت از هم تشخیص میده…
ادرس رو گذاشتم اگر خواستین ببینین…