خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
خانه بیگ دیتا تحلیل شبکه های اجتماعی، متن کاوی، داده کاوی، اوسینت و داده های حجیم
جنگل تصادفي يا رندم فارست چيست و چگونه و در چه مواردي بايد استفاده شود
جنگل تصادفی یا جنگلهای تصمیم تصادفی (Random forest) یک روش یادگیری ترکیبی برای دستهبندی، رگرسیون میباشد، که بر اساس ساختاری متشکل از شمار بسیاری درخت تصمیم، بر روی زمان آموزش و خروجی کلاسها (کلاسبندی) یا برای پیشبینیهای هر درخت به شکل مجزا، کار میکنند. جنگلهای تصادفی برای درختان تصمیم که در مجموعه آموزشی دچار بیش برازش میشوند، مناسب هستند. عملکرد جنگل تصادفی معمولا بهتر از درخت تصمیم است، اما این بهبود عملکرد تا حدی به نوع داده هم بستگی دارد.
عناوين مطالب: '
تاريخچه جنگل تصادفی
نخستین الگوریتم برای جنگلهای تصمیم تصادفی را «تین کم هو» با بهرهگیری از روش زیرفضاهای تصادفی پدیدآورد. نسخههای بعدی آن توسط لیو بریمن ارتقا یافت. پژوهشهای «بریمن» روی کار «امیت و گمن» اثر گذاشت، کسانی که پژوهش براساس دسته تصادفی که نود را تقسیم میکند (در مبحث بزرگ شدن تک درخت) ارائه کردند در این روش، پیش از این که هر درخت یا هر گره را جاسازی کنند، جنگلی از درختان بزرگ میشود و گزینش از بین گونهای از درختان که برای گزینش تصادفی زیرفضاهایی از داده آموزش دیدهاند، صورت میگیرد.
در پایان ایده بهبود بخشیدن به گرههای تصادفی (که انتخاب هر گره به شکل تصادفی بوده) به جای بهبودی قطعی توسط «دیتریش» بیان شد دستاوردهای درباره جنگل تصادفی نخستین بار به دست «لئو بریمن» مقاله شد. این مقاله روشهایی از چگونگی ساخت جنگل بدون کنترل درختها با بهرهگیری از CART را بیان میکند که با متد بگینگ و بهبودی نود تصادفی ترکیب شدهاست. به علاوه، این مقاله بسیاری از نتایج اولیه به دست آمده که شناخته شده بودند و چه آنهایی که به چاپ رسیده بودند را ترکیب میکرد که این ترکیبات پایه و اساس تمرینات امروزی جنگلهای تصادفی را شامل میشود این الگوریتم توسط «لئو بریمن و عادل کالچر» توسعه یافت که جنگل تصادفی نیز جزو دستاوردهای ایشان بود ایده بگینگ برای ساخت مجموعهای از درختهای تصمیم و انتخاب تصادفی نخست توسط «هو» و سپس «امیت و گمان» کامل شد. این تمرینات امروزی عبارتند از:
۱. بهره گرفتن از نقص خارج از کیسه برای تعمیم نقصهای سازماندهی
۲. اهمیت اندازهگیری گونهها و تنوع از طریق جایگشت
همچنین این گزارش نخستین فرجام تئوری برای جنگلهایی که از راه نقص سازماندهی تعمیم یافته بودند را بیان میکند که بستگی به قدرت درختها و ارتباط آنها دارد. درخت تصمیم روش مشهوری برای انواع مختلفی از وظایف یادگیری ماشین به حساب می آید. با این حال در بسیاری موارد دقیق نیستند. در کل، معمولا درخت تصمیمی که بیش از حد عمیق باشد الگوی دقیق نخواهد داشت: دچار بیش برارزش شده , و دارای سوگیری پایین و واریانس بالا میباشد. جنگل تصادفی روشی است برای میانگین گیری با هدف کاهش واریانس با استفاده از درخت های تصمیم عمیقی که از قسمت های مختلف داده آموزشی ایجاد شده باشند. در این روش معمولا افزایش جزیی سوگیری و از دست رفتن کمی از قابلیت تفسیر اتفاق افتاده اما در کل عملکرد مدل را بسیار افزایش خواهد داد.
تفاوت بین درخت تصمیم و جنگل تصادفی
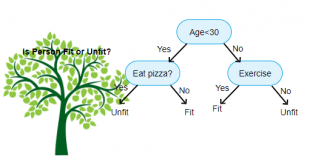
چنانکه پیشتر بیان شد، جنگل تصادفی مجموعهای از درختهای تصمیم است. اما تفاوتهایی میان آنها وجود دارد. اگر یک مجموعه داده ورودی با ویژگیها و برچسبهای آن به عنوان ورودی به الگوریتم داده شود، برخی از مجموعه قوانین را به گونهای فرموله میکند که برای انجام پیشبینی مورد استفاده قرار میگیرند. برای مثال، اگر کاربر قصد داشته باشد پیشبینی کند که «آیا فرد روی یک تبلیغ آنلاین کلیک میکند یا نه»، میتواند تبلیغاتی که فرد در گذشته روی آنها کلیک کرده و ویژگیهایی که تصمیمات او را توصیف میکنند گردآوری کند. سپس، با استفاده از آنها میتواند پیشبینی کند که یک تبلیغ مشخص توسط یک فرد خاص کلیک میشود یا خیر.
منطق عملکرد جنگل تصادفی
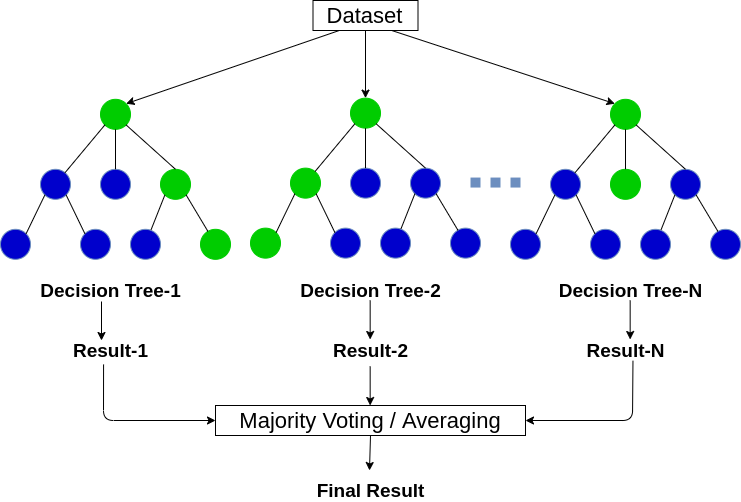
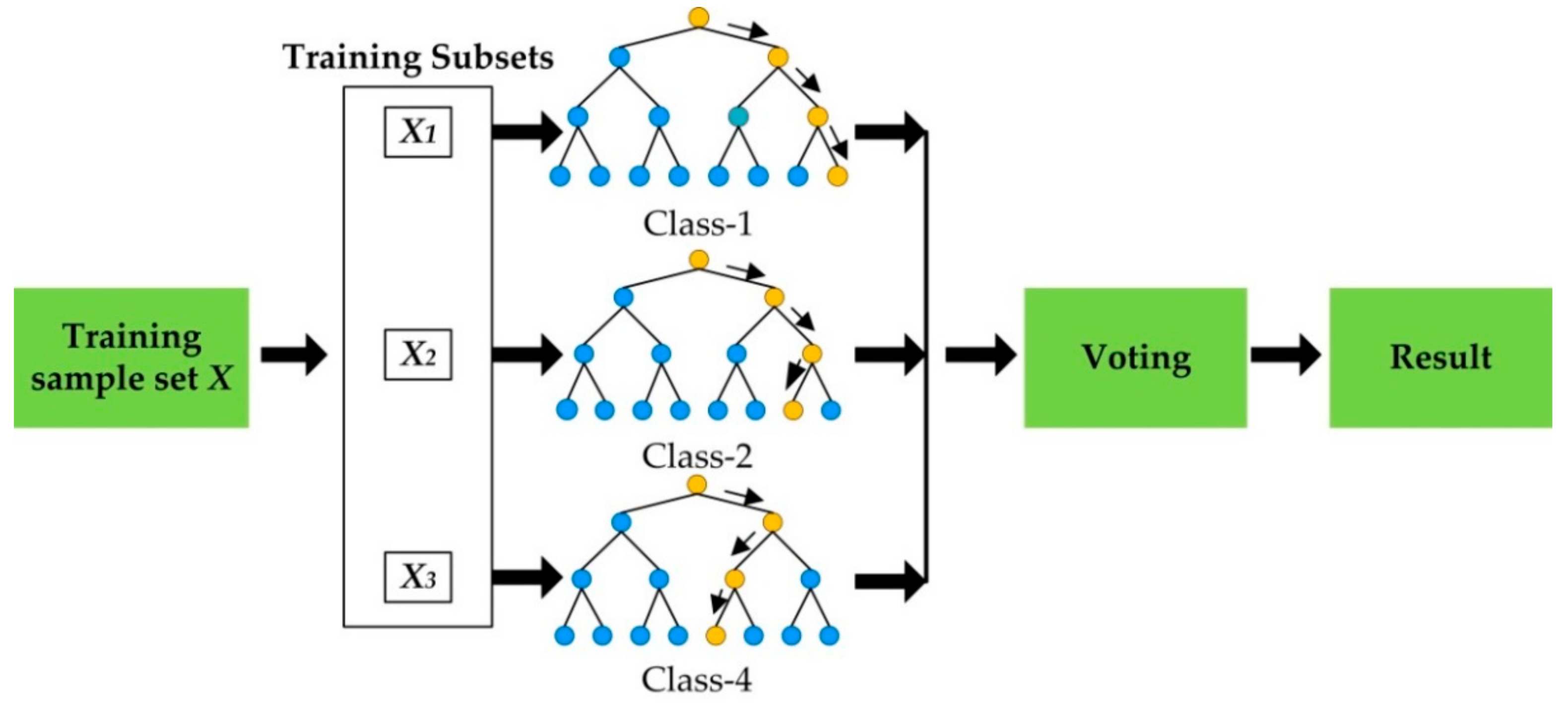
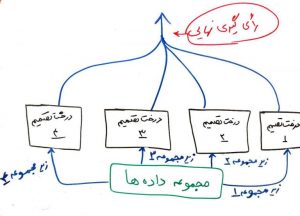
الگوریتمِ جنگلِ تصادفی یا همان Random Forest هم یک الگوریتمِ ترکیبی (ensemble) بوده که از درختهای تصمیم، برای الگوریتمهای ساده و ضعیفِ خود استفاده میکند. یک الگوریتمِ درختِ تصمیم، میتواند به راحتی عملیاتِ طبقهبندی را بر روی دادهها انجام دهد. حال در الگوریتمِ جنگل تصادفی از چندین درختِ تصمیم (برای مثال ۱۰۰ درخت تصمیم) استفاده میشود. در واقع مجموعهای از درختهای تصمیم، با هم یک جنگل را تولید میکنند و این جنگل میتواند تصمیمهای بهتری را (نسبت به یک درخت) اتخاذ نماید.
در الگوریتم جنگل تصادفی به هر کدام از درختها، یک زیرمجموعهای از دادهها تزریق میشود. برای مثال اگر مجموعه دادهی شما دارای ۱۰۰۰ سطر (یعنی ۱۰۰۰ نمونه) و ۵۰ ستون (یعنی ۵۰ ویژگی) بود، الگوریتمِ جنگلِ تصادفی به هر کدام از درختها، ۱۰۰ سطر و ۲۰ ستون، که به صورت تصادفی انتخاب شدهاند و زیر مجموعهای از مجموعهی دادهها هست، میدهد. این درختها با همین دیتاستِ زیر مجموعه، میتوانند تصمیم بگیرند و مدلِ طبقهبندِ خود را بسازند. برای نمونه شکل زیر را در نظر بگیرید. در نهایت بین خروجی تمامی درخت های آموزش داده شده فرایند رای گیری انجام خواهد شد تا مدل ایجاد شده با بهترین برازش کار کند.
برازش بیش از اندازه و کم برازش
برازش از کلمه برازندگی گرفته شده است. به عبارتی بیش یرازش یعنی برازندگی بیش از حد. بیشبرازش (به انگلیسی: Overfitting) به پدیدهٔ نامطلوبی در آمار گفته میشود که در آن درجه آزادی مدل بسیار بیشتر از درجه آزادی واقعی انتخاب شده و در نتیجه اگرچه مدل روی داده استفاده شده برای یادگیری بسیار خوب نتیجه میدهد، اما بر روی داده جدید دارای خطای زیاد است. به عبارتی مدل قابلیت تعمیم یا Generalization ندارد و برای دیتاسِت هایی که در فرایند آموزش وجود نداشتند نمیتواند به خوبی کار کند. انتخاب درجه آزادی مناسب به کمک وارسی اعتبار (Cross-validation) و تنظیمکردن (Regularization) از راههای مقابله با این پدیدهاست. اگر در درخت تصمیم با بیش برازش مواجه شدیم یک راه حل آن استفاده از جنگی تصادفی است.

احتمال بیش برازش به این دلیل وجود دارد که معیار برازش مدل با معیاری که برای ارزیابی آن به کار میرود یکسان نیست. به این مفهوم که معمولاً برای برازش مدل کارایی آن بر روی یک مجموعه نمونههای برازش بیشینه میشود. در صورتی که برای سنجش مؤثر بودن مدل نه تنها کارایی آن بر روی نمونههای برازش را می سنجند بلکه توانایی مدل بر روی نمونههایی دیده نشده نیز در نظر گرفته میشود. بیش برازش زمانی اتفاق می افتد که مدل در هنگام برازش به جای “یادگیری” دادهها شروع به “حفظ کردن” آنها میکند.
مزایا و معایب
همانطور که پیش از این بیان شد، یکی از مزایای جنگل تصادفی آن است که هم برای رگرسیون و هم برای دستهبندی قابل استفاده است و راهکاری مناسب برای مشاهده اهمیت نسبی که به ویژگیهای ورودی تخصیص داده میشود است. جنگل تصادفی الگوریتمی بسیار مفید و با استفاده آسان محسوب میشود، زیرا هایپرپارامترهای پیشفرض آن اغلب نتایج پیشبینی خوبی را تولید میکنند. همچنین، تعداد هایپرپارامترهای آن بالا نیست و درک آنها آسان است.
یکی از بزرگترین مشکلات در یادگیری ماشین، بیشبرازش است، اما اغلب اوقات این مساله به آن آسانی که برای دستهبند جنگل تصادفی به وقوع میپیوندد، اتفاق نمیافتد. محدودیت اصلی جنگل تصادفی آن است که تعداد زیاد درختها میتوانند الگوریتم را برای پیشبینیهای جهان واقعی کند و غیر موثر کنند.
به طور کلی، آموزش دادن این الگوریتمها سریع انجام میشود، اما پیشبینی کردن پس از آنکه مدل آموزش دید، اندکی کند به وقوع میپیوندد. یک پیشبینی صحیحتر نیازمند درختان بیشتری است که منجر به کندتر شدن مدل نیز میشود. در اغلب کاربردهای جهان واقعی، الگوریتم جنگل تصادفی به اندازه کافی سریع عمل میکند، اما امکان دارد شرایطهایی نیز وجود داشته باشد که در آن کارایی زمان اجرا حائز اهمیت است و دیگر رویکردها ترجیح داده میشوند. البته، جنگل تصادفی یک ابزار مدلسازی پیشبین و نه یک ابزار توصیفی است. این یعنی، اگر کاربر به دنبال ارائه توصیفی از دادههای خود است، استفاده از رویکردهای دیگر ترجیح داده میشوند.
منبع:
.https://blog.faradars.org/random-forest-algorithm/
www.chistio.ir/الگوریتم-جنگل-تصادفی-random-forest/
www.shabakeh-mag.com/workshop/18473/آشنایی-با-درخت-تصمیم%E2%80%8Cگیری-decision-tree،-جنگل-تصادفی-random-forest-و-بازشناسی-الگوها
https://knowledge.dataiku.com/latest/courses/intro-to-ml/classification/classification-summary.html
آدرس کانال تلگرام سایت بیگ دیتا:
آدرس کانال سروش ما:
https://sapp.ir/bigdata_channel
جهت دیدن سرفصل های دوره های آموزشی بر روی اینجا کلیک کنید.
جهت ثبت نام در دوره های آموزشی بر روی اینجا کلیک کنید.
بازدیدها: 2529
برچسبRandom Forest ابزارهای داده کاوی بیش یرازش جنگل تصادفی داده کاوي يادگيري ماشين